一种机器人深度强化学习运动规划方法及计算机可读介质
本发明属于移动机器人运动规划领域,尤其涉及一种机器人深度强化学习运动规划方法及计算机可读介质。
背景技术:
1、近年来,移动机器人产业蓬勃发展,信息感知与导航技术作为机器人核心技术,是移动机器人安全顺利完成各项任务的基础,已经成为产学研联合攻关的主要目标之一。伴随着机器人应用场景的多样化和复杂化,机器人的工作环境也由结构化的特定场景延伸到动态的、时变的、与人共存的日常生活场景。这对移动机器人导航技术的泛化性、自主性和动态避障能力提出了更高的要求。由于传统的针对固定环境的导航技术难以适用于非结构化、非确定性的动态环境,因此,近年来学界的研究工作主要是围绕在此类未知环境或部分可知环境下的自主导航与动态避障技术。
2、深度强化学习(deep reinforcement learning,drl)相关领域的突破性进展为解决未知的复杂动态场景下的路径规划与避障问题提供了新的方案,其不需要提前针对环境建模,可以直接端到端进行运动规划的特性能够很好的解决传统算法带来的弊端。然而,基于drl的机器人导航方法具有奖励稀疏、缺乏原理可解释性等问题,模型收敛依赖于大量的环境交互训练,难以实现稳定、鲁棒的模型效果。因此,基于深度强化学习技术进行移动机器人的运动规划仍然是一项具有挑战性的工作。
技术实现思路
1、针对现有技术方法的不足,本发明提出了一种机器人深度强化学习运动规划方法及计算机可读介质。
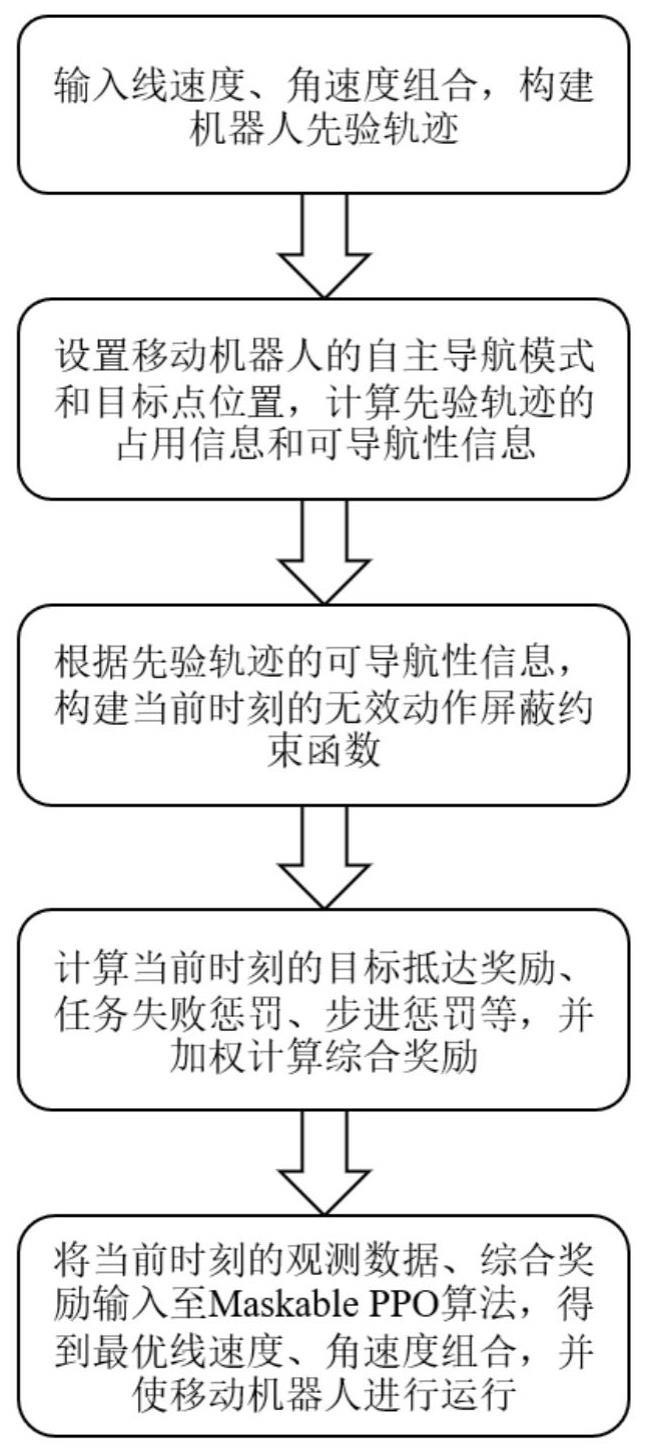
2、本发明方法所采用的技术方案是一种机器人深度强化学习运动规划方法,其特征在于:
3、移动机器人通过octomap方法构建当前时刻的3d体素局部占用地图、3d体素局部占用地图中每个体素的占用信息;结合tentabot导航框架进行计算,得到当前时刻每对线速度、角速度组合对应的机器人坐标系下先验轨迹的占用信息和可导航性信息;
4、构建当前时刻的观测数据、当前时刻的动作空间、当前时刻的无效动作屏蔽约束函数;
5、加权计算当前时刻的综合奖励;
6、将当前时刻的观测数据输入至maskable ppo算法,将当前时刻的综合奖励反馈至maskable ppo算法,根据当前时刻的无效动作屏蔽约束条件,maskable ppo算法当前时刻的动作空间中优化求解得到最优的线速度、角速度组合,作为当前时刻的线速度、角速度,并输入至移动机器人进行运行。
7、本发明具体包括以下步骤:
8、步骤1:输入多对线速度、角速度组合,根据每对线速度、角速度组合设定移动机器人的线速度、角速度,移动机器人根据设定的线速度、角速度前进一定时间,基于运动学模型计算得到机器人坐标系下多个采样点位置,构建每对线速度、角速度组合对应的机器人坐标系下的先验轨迹;
9、步骤2:设置移动机器人在自主导航模式下进行运动,并设置目标点位置,通过移动机器人的深度相机采集当前时刻的深度图像,通过2d激光雷达采集当前时刻的环境点云数据,将当前时刻的深度图像、当前时刻的环境点云数据在机器人坐标系下通过octomap方法构建当前时刻的3d体素局部占用地图、并得到当前时刻的3d体素局部占用地图中每个体素的占用信息;将每对线速度、角速度组合对应的机器人坐标系下先验轨迹的采样点投影在当前时刻的3d体素局部占用地图中,以每个采样点一定距离半径内的体素作为当前时刻的邻近体素,得到当前时刻每对线速度、角速度组合对应的机器人坐标系下先验轨迹中每个采样点的多个邻近体素的位置与占用信息;将当前时刻每对线速度、角速度组合对应的机器人坐标系下先验轨迹中所有采样点的多个邻近体素的占用信息输入给tentabot导航框架进行计算,得到当前时刻每对线速度、角速度组合对应的机器人坐标系下先验轨迹的占用信息和可导航性信息;
10、步骤3:将当前时刻每对线速度、角速度组合对应的机器人坐标系下先验轨迹的占用信息、目标点位置、当前时刻移动机器人距离目标点位置的距离、当前时刻移动机器人的偏航角、上一时刻的线速度、角速度组合作为当前时刻的观测数据,将输入的多对线速度、角速度组合作为当前时刻的动作空间,利用当前时刻每对线速度、角速度组合对应的机器人坐标系下先验轨迹的可导航性信息构建当前时刻的无效动作屏蔽约束函数;
11、步骤4:依次计算当前时刻的目标抵达奖励、当前时刻的任务失败惩罚、当前时刻的步进惩罚、当前时刻的目标接近奖励、当前时刻的安全保持惩罚、当前时刻的速度变化惩罚,进一步加权计算当前时刻的综合奖励;
12、步骤5:将当前时刻的观测数据输入至maskable ppo算法,将当前时刻的综合奖励反馈至maskable ppo算法,根据当前时刻的无效动作屏蔽约束条件,maskable ppo算法当前时刻的动作空间中优化求解得到最优的线速度、角速度组合,作为当前时刻的线速度、角速度,并输入至移动机器人进行运行。
13、作为优选,步骤3所述当前时刻的无效动作屏蔽约束函数,具体定义如下:
14、无效动作屏蔽函数是指在机器人行进过程中,以当前时刻每对线速度、角速度组合对应的机器人坐标系下先验轨迹的可导航性信息作为条件,约束动作空间选取的函数;
15、若在当前时刻,存在可导航与暂时可导航的先验轨迹,则将不可导航轨迹视为无效动作:
16、
17、其中,为当前时刻动作组合;为轨迹可导航性,false表示错误,true表示真实,将先验轨迹分为可导航、不可导航与暂时可导航三类;对于所有先验轨迹均不可导航时,则将所有动作设置为有效,促使机器人学习自救动作:
18、。
19、作为优选,步骤4所述计算当前时刻的目标抵达奖励,具体定义如下:
20、目标抵达奖励设定为,表示若机器人与目标点的距离小于阈值则进行奖励,并且结束当前回合;
21、步骤4所述计算当前时刻的任务失败惩罚,具体定义如下:
22、任务失败惩罚设定为,表示若机器人在当前回合达到最大时间步数或碰撞到障碍物,则进行惩罚,并且结束当前回合;
23、步骤4所述计算当前时刻的步进惩罚,具体定义如下:
24、步进惩罚是一个常量,旨在惩罚未抵达目标点的机器人,每多走一步则惩罚增加:
25、
26、其中,为当前时刻的步进惩罚,为步进惩罚参数;为每回合最大时间步数;
27、步骤4所述计算当前时刻的目标接近奖励,具体定义如下:
28、目标接近奖励的大小随目标距离差值的大小而变化,且相同距离差值的接近奖励大于远离惩罚;
29、
30、其中,为当前时刻的目标接近奖励;为目标接近奖励参数;、分别为当前时刻和上一时刻目标距离;
31、步骤4所述计算当前时刻的安全保持惩罚,具体定义如下:
32、安全保持惩罚是指机器人未与障碍物保持安全距离的惩罚,若机器人与障碍物的检测距离处于安全距离阈值和碰撞阈值,则对机器人进行惩罚,计算公式如下:
33、
34、其中,为当前时刻的安全保持惩罚;为安全保持惩罚参数;为当前时刻的机器人与障碍物的检测距离;为安全距离保持阈值;为碰撞阈值;
35、步骤4所述计算当前时刻的速度变化惩罚,具体定义如下:
36、速度变化惩罚是针对机器人速度剧变的惩罚,通过计算当前时刻和上一时刻的线速度和角速度差值的绝对值之和,若小于速度变化阈值,则对机器人奖励,否则进行惩罚,该惩罚值的大小随速度变化的程度而变化,计算公式如下:
37、
38、其中,为当前时刻的速度变化惩罚;为速度变化惩罚参数;分别为当前时刻和上一时刻的线速度;分别为当前时刻和上一时刻的角速度;为速度最小变化阈值。
39、步骤4所述计算当前时刻的综合奖励,具体定义如下:
40、训练过程中,奖励函数旨在规范机器人每一步的行为,使其学习如何高效、快速、安全地完成导航任务,公式如下:
41、
42、其中,为目标抵达奖励;为任务失败惩罚;为当前时刻的步长奖励,包括当前时刻的步进惩罚、当前时刻的目标接近奖励、当前时刻的安全保持惩罚和当前时刻的速度变化惩罚。
43、本发明还提供了一种计算机可读介质,所述计算机可读介质存储电子设备执行的计算机程序,当所述计算机程序在电子设备上运行时,使得所述电子设备执行所述机器人深度强化学习运动规划方法的步骤。
44、本发明优点在于,本发明显式地利用先验轨迹的占用信息和可导航性信息对机器人的环境观测与动作选择过程进行改进,并完善奖励函数设计,有效提高了移动机器人导航的安全性和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!