一种改进DDPG算法的多无人水面舰艇追捕自适应决策方法
本发明涉及一种改进ddpg算法的多无人水面舰艇追捕自适应决策方法,属于无人系统智能决策。
背景技术:
1、近年来,无人艇被广泛用于执行多种军事及非军事任务,代替作业人员执行危险或耗时耗力的任务,在港口防护及舰船兵力保护、海上侦察监视、反潜作战、水上搜救、后勤补给、水质监测、水文采样、海洋环境测绘、水域生态保护等方面发挥着重要作用,提高工作效能的同时也降低了作业人员的伤亡。同时随着无人水面艇控制技术的成熟以及人工智能决策领域近年来不断取得的突破,使得基于强化学习的水面无人艇决策的实现成为可能,而利用强化学习来解决无人水面艇智能决策有着重要的意义。
技术实现思路
1、本发明提供了一种改进ddpg算法的多无人水面舰艇追捕自适应决策方法,通过融合深度强化学习算法改进ddpg以及阿波罗尼奥斯圆几何特性,设置了不同于常规全连接神经网络输入、输出结构,同时设置了三种有效的奖励机制在围捕逃逸问题中增强逃逸艇的自主自适应决策决策能力,提高了逃逸艇的生存能力和逃逸能力。
2、本发明的技术方案是:
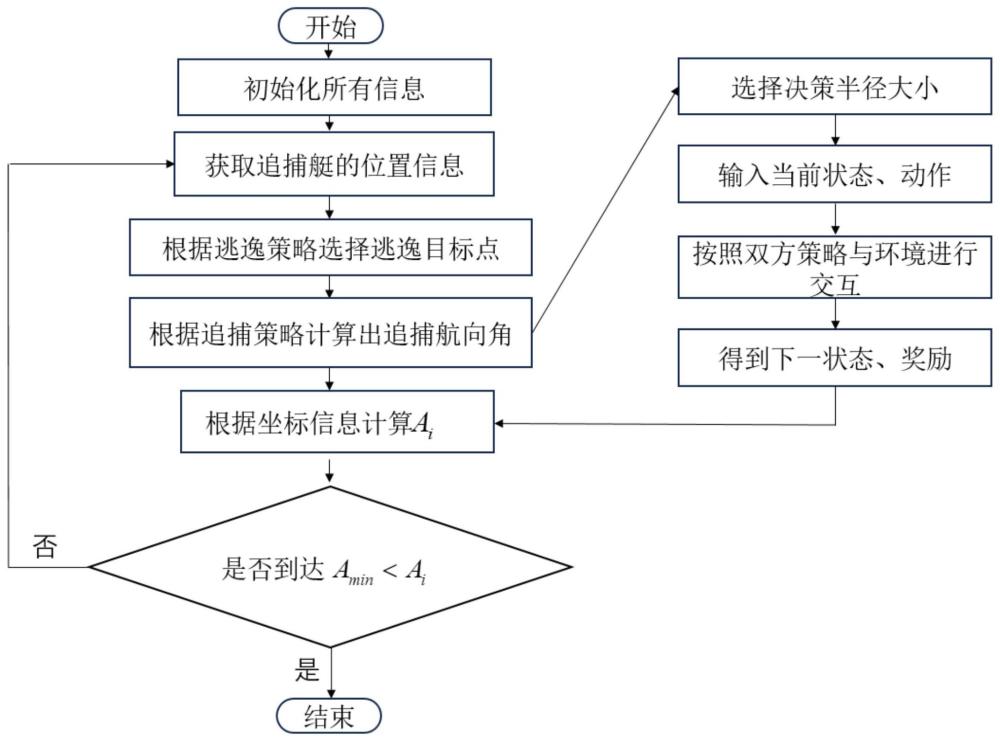
3、根据本发明的第一方面,提供了一种改进ddpg算法的多无人水面舰艇追捕自适应决策方法,包括:建立逃逸艇和追捕艇运动学方程;建立基于阿波罗尼奥斯圆几何特性下的追捕策略和逃逸策略;提出无人水面逃逸艇的动态决策半径概念以及捕获条件;基于马尔科夫决策过程设置改进ddpg算法中的动作集合、状态集合以及加权奖励机制;通过设置改进ddpg算法中策略网络采用的双层全连接神经网络的输入、输出,不断调节拟合双层全连接神经网络参数直到追捕艇平均奖励到达收敛条件,获得逃逸艇最优逃逸决策策略。
4、所述建立逃逸艇和追捕艇运动学方程,包括:
5、追捕艇运动学方程:
6、
7、逃逸艇运动学方程:
8、
9、其中,vp、ve分别表示追捕艇速度和逃逸艇速度;分别表示第i个追捕艇在t时刻x方向上的坐标和y方向上的坐标;分别表示逃逸艇在t时刻x方向上的坐标和y方向上的坐标;表示第i个追捕艇在t时刻的航向角;表示t时刻逃逸艇的航向角;xt、yt分别表示逃逸艇逃逸目标点的横纵坐标值,即逃逸点的横纵坐标值。
10、所述建立基于阿波罗尼奥斯圆几何特性下的逃逸艇逃逸策略:
11、
12、
13、其中,表示可选择逃逸点的横、纵坐标,逃逸艇选择各个追捕艇与逃逸艇连线的中垂线交点中最远处作为逃逸点;分别表示逃逸艇在t时刻x方向上的坐标和y方向上的坐标;ki表示第i个追捕艇位置坐标与逃逸艇艇位置坐标之间连线的斜率;kj表示第j个追捕艇位置坐标与逃逸艇位置坐标之间连线的斜率;表示t时刻逃逸艇航向角;
14、所述建立基于阿波罗尼奥斯圆几何特性下的追捕艇追捕策略:
15、
16、其中,n表示实际追捕艇的序列号,也就是距离逃逸点最近的追捕艇;xt,yt表示逃逸点的横纵坐标值;表示实际追捕艇n的横纵坐标值;分别表示在t时刻实际追捕艇的航向角和逃逸艇的航向角;表示在t时刻辅助追捕艇的航向角。
17、所述捕获条件,具体为:设置第一判断条件,获得当前逃逸艇与追捕艇之间的最小距离;依据当前逃逸艇与追捕艇之间的最小距离,设置第二判断条件;依据第二判断条件,确定围捕逃逸是否终止。
18、所述第一判断条件为:
19、
20、其中,ai表示逃逸艇与第i个追捕艇之间的欧式距离;分别表示逃逸艇在t时刻x方向上的坐标和y方向上的坐标;分别表示第i个追捕艇在t时刻x方向上的坐标和y方向上的坐标;amin表示ai集合中数值最小的那一个,即当前逃逸艇与追捕艇之间的最小距离。
21、所述第二判断条件为:
22、
23、其中,ab表示追捕半径;b(amin)是一个决策函数,如果b(amin)=1,说明围捕逃逸任务终止,否则围捕逃逸任务继续。
24、基于马尔科夫决策过程设置改进ddpg算法中的动作集合和状态集合,使逃逸者的累积折扣奖励最大化:
25、
26、其中,rt表示智能体在强化学习中所获得的长时奖励;γ表示累积折扣奖励衰减因子;r1+k表示智能体下一状态可能获得的奖励;k表示当前迭代回合数,tmax表示一次与环境交互中最大迭代次数。
27、所述加权奖励机制,包括:
28、
29、其中,amin表示ai集合中数值最小的那一个,即当前逃逸艇与追捕艇之间的最小距离;ai表示逃逸艇与第i个追捕艇之间的欧式距离;ab表示追捕半径;在满足amin≤ab情况下,表示当围捕逃逸任务结束时,智能体会获得一次性奖励rc,否则就会获得单步奖励rs,具体的单步奖励rs表达如下:
30、
31、其中,分别表示单步奖励的权重系数,rs1表示逃逸艇的逃逸奖励,rs2表示逃逸的逃逸时间奖励,rs3表示智能体动作选择奖励。
32、所述逃逸艇的逃逸奖励、逃逸的逃逸时间奖励、智能体动作选择奖励,表达式为:
33、rs1=-w1de(t);
34、
35、
36、其中,w1、w2、w3表示步长奖励的权重系数,de(t)表示逃逸艇的逃逸距离;rd表示选择出来的决策半径。
37、以逃逸艇决策到的与追捕艇之间的态势、追捕艇坐标、航向角、双方的速度四种状态作为输入,输出为动作策略。
38、根据本发明的第二方面,提供了一种改进ddpg算法的多无人水面舰艇追捕自适应决策系统,包括:用于建立逃逸艇和追捕艇运动学方程的模块;用于建立基于阿波罗尼奥斯圆几何特性下的追捕策略和逃逸策略的模块;用于提出无人水面逃逸艇的动态决策半径概念以及捕获条件的模块;用于基于马尔科夫决策过程设置改进ddpg算法中的动作集合、状态集合以及加权奖励机制的模块;用于通过设置改进ddpg算法中策略网络采用的双层全连接神经网络的输入、输出,不断调节拟合双层全连接神经网络参数直到追捕艇平均奖励到达收敛条件,获得逃逸艇最优逃逸决策策略的模块。
39、根据本发明的第三方面,提供了一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行上述中任意一项所述的改进ddpg算法的多无人水面舰艇追捕自适应决策方法。
40、根据本发明的第四方面,提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的程序,其中,在所述程序运行时控制所述计算机可读存储介质所在设备执行上述中任意一项所述的改进ddpg算法的多无人水面舰艇追捕自适应决策方法。
41、本发明的有益效果是:
42、1、本发明能够提升围捕逃逸博弈问题中逃逸者的逃逸能力,更好地保护自身安全。
43、2、本发明具有强泛化性,可适用不同数量的追捕者情况和初始位置随机的情况下。
44、3、本发明与阿波罗尼奥斯圆逃逸策略方法和sac、trpo深度强化学习算法相比,可以显著提高逃逸者的逃逸距离和逃逸实际。
- 还没有人留言评论。精彩留言会获得点赞!