一种结合强化学习与博弈论的无人机空战决策方法及系统
本发明属于无人机控制,涉及一种结合强化学习与博弈论的无人机空战决策方法及系统。
背景技术:
1、无人机在空战时将面临高度复杂和动态变化的作战环境,包括不断变化的地形、气象条件、敌对目标和战术,传统的规则和预定义策略难以涵盖所有可能的情况。因此需要借助人工智能、优化算法以及博弈论等方法构建自主决策系统,从而摆脱敌人攻击、逐渐积累自身优势,并完成对敌方无人机的打击。
2、无人机在空战时需要做出大量实时决策,在面临大规模连续状态及策略空间时,现有的一系列优化算法难以保证决策的实时性要求。深度强化学习技术能够充分表征并处理高维度的状态和策略空间,并通过训练从历史经验中提取出最优的决策策略。空战是一种多智能体博弈的场景,涉及到多个无人机之间的博弈交互关系。传统的基于强化学习的空战决策方法往往缺乏对对手动态行为的深刻理解,经过训练学习到的策略也不具备可解释性。
技术实现思路
1、本发明的目的在于解决现有技术中的问题,提供一种结合强化学习与博弈论的无人机空战决策方法及系统。
2、为达到上述目的,本发明采用以下技术方案予以实现:
3、一种结合强化学习与博弈论的无人机空战决策方法,包括以下步骤:
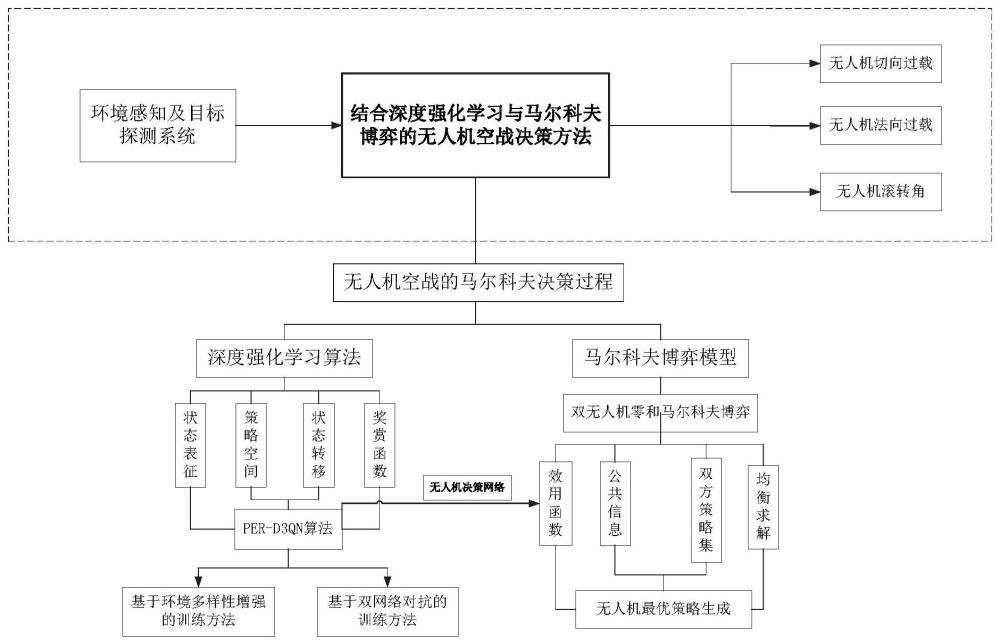
4、构建无人机的状态空间、策略空间、状态转移和奖赏函数,基于状态空间、策略空间、状态转移和奖赏函数通过强化学习训练获取决策网络;
5、分别获取博弈时,双方无人机任意时刻的状态,基于双方无人机任意时刻的状态和决策网络获取无人机当前时刻状态下所有动作对应的价值,基于获取所有动作的价值,构建双方无人机的候选策略集,基于双方无人机的候选策略集构建博弈模型;
6、基于博弈模型求解双方无人机的混合策略纳什均衡,基于混合策略纳什均衡获取无人机空战优化策略。
7、本发明的进一步改进在于:
8、所述博弈模型的构建还包括以下步骤:
9、在状态s下,通过决策网络可计算出双方无人机所有动作的价值,选择价值最大的前d个动作作为双方的候选策略集;
10、考虑每一组双方的动作对(ai,aj),通过决策网络每组动作队对应的价值,并计算其效用值,通过获取的所有动作对的效用值形成效用矩阵,得到双无人机零和马尔科夫博弈模型。
11、所述双无人机零和马尔科夫博弈模型通过公式(1)表达:
12、
13、其中,其中n={1,2},表示参与博弈的双方无人机,1表示我方无人机,2表示敌方无人机;分别表示双方无人机的策略集,u表示效用矩阵,可记作
14、所述效用值通过公式以下表示:
15、当采用纯策略时,u(ai,aj)表示当我方无人机采取动作ai而敌方无人机采取动作aj时,我方无人机得到的效用值通过公式(2)计算:
16、u(ai,aj)=vm(ai,aj)-ve(aj,ai) (2)
17、其中,vm(ai,aj)表示在st+1状态下我方无人机可获得的最大未来期望奖赏,ve(ai,aj)则表示敌方无人机在st+1状态下可获得的最大未来期望奖赏;
18、当采用混合策略时,效用值通过公式(3)计算:
19、
20、其中,x=(x1,x2,...xd),y=(y1,y2,...yd),
21、混合策略纳什均衡通过以下过程求解:
22、设定我方战斗机的安全策略为敌方战斗机的安全策略为若(x*,y*)为g的一个混合策略纳什均衡,则有:
23、
24、结合线性规划对公式(20)进行线行拆解:
25、我方无人机的优化问题lpm:
26、
27、敌方无人机的优化问题lpe:
28、
29、若求解结果满足z*=w*,则得到该博弈模型的混合策略纳什均衡(x*,y*),即为双方无人机的最优策略。
30、所述奖赏函数的定义:
31、追击状态:
32、
33、逃逸状态:
34、
35、正面交战状态:
36、
37、相互远离状态:
38、
39、在不同状态下定义如下的态势奖赏函数:
40、
41、无人机的策略空间通过以下步骤构建:
42、建立无人机的策略机动方程:
43、
44、其中,v表示无人机的速度;γ,ψ分别表示无人机的俯仰角和滚转角;ηx表示无人机的切向过载;ηy表示无人机的法向过载;μ表示无人机的滚转角;三元组(ηx,ηz,μ)构成了无人机的控制量;
45、对公式(8)进行改写:
46、
47、基于runge-kutta法将原方程改写为如下的差分形式,便于进行迭代计算:
48、
49、其中,k表示第k次迭代计算;h表示求解的步长。
50、一种结合强化学习与博弈论的无人机空战决策系统,包括:
51、决策网络获取模块,用于构建无人机的状态空间、策略空间、状态转移和奖赏函数,基于状态空间、策略空间、状态转移和奖赏函数通过强化学习训练获取决策网络;
52、博弈模型构建模块,用于分别获取博弈时,双方无人机任意时刻的状态,基于双方无人机任意时刻的状态和决策网络获取无人机当前时刻状态下所有动作对应的价值,基于获取所有动作的价值,构建双方无人机的候选策略集,基于双方无人机的候选策略集构建博弈模型;
53、优化策略获取模块,用于基于博弈模型求解双方无人机的混合策略纳什均衡,基于混合策略纳什均衡获取无人机空战优化策略。
54、一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明任一项所述方法的步骤。
55、一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现本发明任一项所述方法的步骤。
56、与现有技术相比,本发明具有以下有益效果:
57、本发明公开了一种结合强化学习与博弈论的无人机空战决策方法,通过深度强化学习实现对无人机高维、连续状态及策略空间的非线性建模,展现出强大的适应性,能够实时响应复杂、动态的环境;在进行决策网络的训练构建过程中,根据空战双方无人机的视线角对空战态势进行了划分,设计了基于空战态势划分的强化学习奖赏函数,使得无人机可以更快、更准确地识别出当前的空战态势,并针对性地完成机动决策,通过强化学习训练获取决策网络,增加了训练时的环境多样性,使得训练出的模型针对不同的初始状态以及不同的敌机机动方式具备较好的泛化能力。同时设计了无人机双网络对抗训练,令敌方无人机使用先前训练好的模型进行决策,这使得无人机的决策性能进一步提升,本发明将双方无人机的空战过程视为一个二人零和马尔科夫博弈模型,以博弈的纳什均衡解作为双方的最优机动策略,增强了策略的可解释性、为无人机的空战决策提供了理论支撑。
- 还没有人留言评论。精彩留言会获得点赞!