一种室内物品飞行搬运机器人目标跟踪方法和装置与流程
本发明涉及飞行机器人控制,具体涉及一种室内物品飞行搬运机器人目标跟踪方法和装置、计算机可读存储介质。
背景技术:
1、随着人工智能基础理论的快速发展,基于人工智能技术的应用也越来越广泛。计算机视觉是人工智能领域最活跃方向之一,基于计算机视觉技术的三维重建,vr、ar技术也得到了大力发展,充分表明了计算机视觉技术的广阔应用前景。计算机视觉研究的本质是让机器也能像人一样能够理解图像信息,并根据这些信息得到一定的判断。飞行机器人结构简单、价格便宜、维护方便,在室内巡检、物品搬运等领域得到了越来越多的关注,将飞行机器人应用场景与计算机视觉结合起来,可以加快飞行机器人领域和计算机视觉领域的发展速度,提升技术发展水平。
2、目标跟踪技术是计算机视觉领域研究的热点,目标跟踪是计算机视觉中的一个经典问题,它的任务就是从图像序列中判断出是否有目标,给出目标的类别和位置并且跟踪其运动过程。在民用方面,目标跟踪技术是整个安防领域智能监控的基础,可以对特定目标进行持续的跟踪运动,是室内环境监测与安防的关键技术手段。此外,目标跟踪技术也是飞行机器人搬运任务的基础,通过跟踪待搬运的目标,引导飞行机器人向目标飞行。传统的目标跟踪技术常常依赖手工设计的目标特征来实现,无法满足复杂场景下的任务需求,随着深度学习技术的快速发展,基于深度学习的目标跟踪算法由于其良好的性能受到越来越多的关注,通过深度卷积神经网络来提取的目标特征比传统的手工特征有更好的鲁棒性,在精度方面有着质的提升。近年来,基于深度学习的目标跟踪算法逐渐向轻量化发展,随着计算硬件的迭代更新,深度学习对高计算力的需求也逐渐得到解决,基于深度学习的目标跟踪方法在嵌入式终端设备上有了落地的可能。但是,现阶段的深度学习算法泛化能力较差,仅适用于有限的数据样本,同时生成的数据样本信息高度相关,会导致训练时目标跟踪算法局部收敛,使得难以准确跟踪目标。
技术实现思路
1、本发明主要解决现有的基于深度学习的飞行机器人目标跟踪算法生成的数据样本信息高度相关,会导致训练时目标跟踪算法局部收敛的技术问题。
2、根据第一方面,一种实施例中提供一种室内物品飞行搬运机器人目标跟踪方法,所述室内物品飞行搬运机器人有多个,且均处于相同的室内环境中,所述室内物品飞行搬运机器人目标跟踪方法包括:
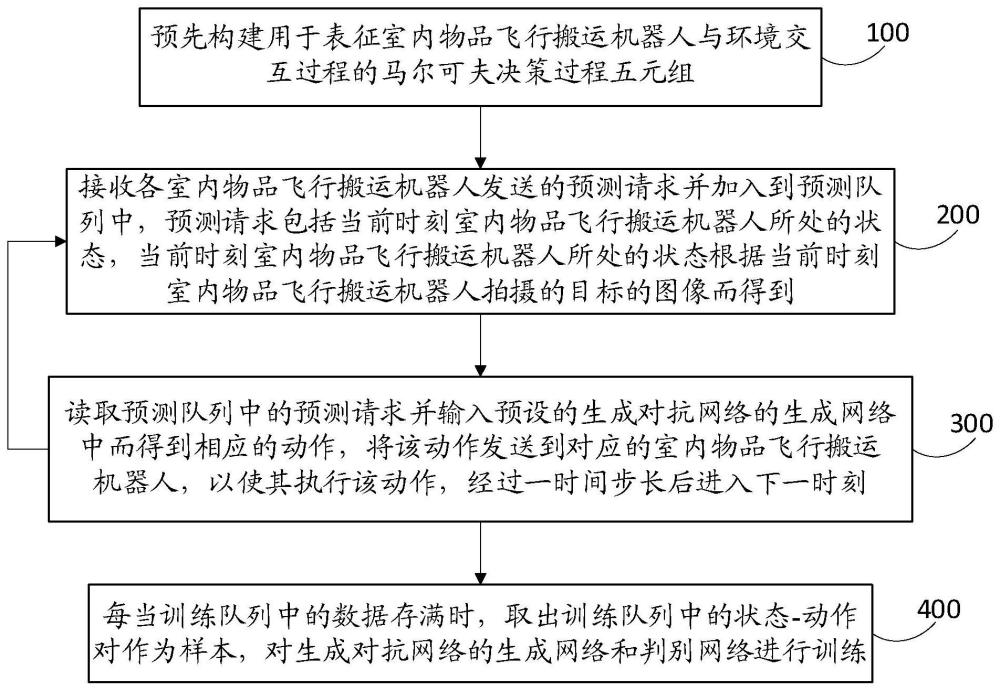
3、预先构建用于表征所述室内物品飞行搬运机器人与环境交互过程的马尔可夫决策过程五元组(s,a,t,r,γ),其中s是马尔可夫决策过程的状态空间,a是马尔可夫决策过程的动作空间,t是状态转换模型,具体形式为t(s′|s,a),表示所述室内物品飞行搬运机器人在状态s′而忽略状态s时,执行动作a的概率,r是深度强化学习的奖励函数,γ是贴现因子;
4、状态获取步骤,接收各所述室内物品飞行搬运机器人发送的预测请求并加入到预测队列中,所述预测请求包括当前时刻所述室内物品飞行搬运机器人所处的状态s,其中当前时刻所述室内物品飞行搬运机器人所处的状态s根据当前时刻所述室内物品飞行搬运机器人拍摄的目标的图像而得到,s∈s;
5、动作执行步骤,读取预测队列中的预测请求并输入预设的生成对抗网络的生成网络gθ中而得到相应的动作a,将动作a发送到对应的室内物品飞行搬运机器人,以使其执行动作a,经过时间步长δt后进入下一时刻;其中状态-动作对(s,a)被存储到训练队列中,θ表示生成网络的参数,a∈a;
6、重复执行所述状态获取步骤和所述动作执行步骤;
7、每当训练队列中的数据存满时,取出训练队列中的状态-动作对(s,a)作为样本,对所述生成对抗网络的生成网络gθ和判别网络dψ进行训练,其中ψ表示判别网络的参数。
8、一些实施例中,所述对所述生成对抗网络的生成网络gθ和判别网络dψ进行训练包括:
9、分别将训练队列中的各个状态-动作对(s,a)输入判别网络dψ以得到对应的判别分数dψ(s,a);
10、根据判别分数dψ(s,a)和第一优化目标,采用近端策略优化对生成网络gθ进行参数更新,根据判别分数dψ(s,a)和第二优化目标对判别网络dψ进行参数更新;
11、其中生成网络gθ作为策略网络,用于模仿专家策略,所述第一优化目标为使判别网络dψ对生成网络gθ的状态-动作对(s,a)输出的判别分数趋近判别网络dψ对专家策略的状态-动作对(s,a)的判别分数;
12、判别网络dψ用于区分训练队列中的状态-动作对(s,a)形成的轨迹是否由专家策略形成,所述第二优化目标为使判别网络dψ对生成网络gθ的状态-动作对(s,a)输出相对更低的判别分数,对专家策略的状态-动作对(s,a)输出相对更高的判别分数。
13、一些实施例中,所述的室内物品飞行搬运机器人目标跟踪方法还包括:根据所述奖励函数计算得到训练队列中的各个状态-动作对(s,a)对应的奖励值,计算奖励值的方差,当奖励值的方差大于预设的方差阈值时更新时间步长δt。
14、一些实施例中,所述奖励函数与判别分数dψ(s,a)正相关。
15、一些实施例中,所述第一优化目标的目标函数为:
16、
17、其中πθ表示生成网络gθ的策略,表示参数更新前的策略,表示参数更新后的策略,表示累积奖励值,表示采用参数更新前的策略在状态s下采取动作a的概率,表示采用参数更新后的策略在状态s下采取动作a的概率,aθ(s,a)是策略πθ的优势函数,是参数更新前后的策略的kl散度。
18、一些实施例中,其中δ是kl散度的约束参数。
19、一些实施例中,所述第二优化目标的目标函数为:
20、
21、其中πe表示专家策略,e表示期望算子。
22、根据第二方面,一种实施例中提供一种室内物品飞行搬运机器人目标跟踪装置,包括:
23、交互过程预构建模块,用于预先构建用于表征所述室内物品飞行搬运机器人与环境交互过程的马尔可夫决策过程五元组(s,a,t,r,γ),其中s是马尔可夫决策过程的状态空间,a是马尔可夫决策过程的动作空间,t是状态转换模型,具体形式为t(s′|s,a),表示所述室内物品飞行搬运机器人在状态s′而忽略状态s时,执行动作a的概率,r是深度强化学习的奖励函数,γ是贴现因子;
24、状态获取模块,用于实现状态获取步骤,所述状态获取步骤包括:接收各所述室内物品飞行搬运机器人发送的预测请求并加入到预测队列中,所述预测请求包括当前时刻所述室内物品飞行搬运机器人所处的状态s,其中当前时刻所述室内物品飞行搬运机器人所处的状态s根据当前时刻所述室内物品飞行搬运机器人拍摄的目标的图像而得到,s∈s;
25、动作执行模块,用于实现动作执行步骤,所述动作执行步骤包括:读取预测队列中的预测请求并输入预设的生成对抗网络的生成网络gθ中而得到相应的动作a,将动作a发送到对应的室内物品飞行搬运机器人,以使其执行动作a,经过时间步长δt后进入下一时刻;其中状态-动作对(s,a)被存储到训练队列中,θ表示生成网络的参数,a∈a;
26、其中,所述状态获取步骤和所述动作执行步骤重复执行;
27、网络更新模块,用于每当训练队列中的数据存满时,取出训练队列中的状态-动作对(s,a)作为样本,对所述生成对抗网络的生成网络gθ和判别网络dψ进行训练,其中ψ表示判别网络的参数。
28、一些实施例中,网络更新模块对所述生成对抗网络的生成网络gθ和判别网络dψ进行训练包括:
29、分别将训练队列中的各个状态-动作对(s,a)输入判别网络dψ以得到对应的判别分数dψ(s,a);
30、根据判别分数dψ(s,a)和第一优化目标,采用近端策略优化对生成网络gθ进行参数更新,根据判别分数dψ(s,a)和第二优化目标对判别网络dψ进行参数更新;
31、其中生成网络gθ作为策略网络,用于模仿专家策略,所述第一优化目标为使判别网络dψ对生成网络gθ的状态-动作对(s,a)输出的判别分数趋近判别网络dψ对专家策略的状态-动作对(s,a)的判别分数;
32、判别网络dψ用于区分训练队列中的状态-动作对(s,a)形成的轨迹是否由专家策略形成,所述第二优化目标为使判别网络dψ对生成网络gθ的状态-动作对(s,a)输出相对更低的判别分数,对专家策略的状态-动作对(s,a)输出相对更高的判别分数。
33、根据第三方面,一种实施例中提供一种计算机可读存储介质,所述介质上存储有程序,所述程序能够被处理器执行以实现上述第一方面中任一实施例所述的室内物品飞行搬运机器人目标跟踪方法。
34、依据上述实施例的室内物品飞行搬运机器人目标跟踪方法/装置,通过构建马尔可夫决策过程五元组(s,a,y,r,γ)来表征室内物品飞行搬运机器人与环境的交互过程,从而与复杂室内环境进行数据交互,适用于室内物品飞行搬运机器人复杂环境下的决策问题,特别是在面对大规模状态空间和动态变化的环境时,可以通过与环境的交互来学习优异策略,不需要先验知识。并且,本发明通过处于相同的室内环境中的多个室内物品飞行搬运机器人收集训练样本,这些室内物品飞行搬运机器人使用同一深度强化学习网络进行决策,各自与环境交互,进行目标跟踪,将收集到的数据样本存入训练队列,用于对网络进行训练,相当于分别在多个相同的环境中收集样本,减少了样本之间的相关性,从而避免了深度强化学习网络训练过程中的局部收敛,使得室内物品飞行搬运机器人能更准确地跟踪目标。
- 还没有人留言评论。精彩留言会获得点赞!