一种挖掘具有相似需求的查询的方法及装置与流程
一种挖掘具有相似需求的查询的方法及装置【技术领域】本发明涉及自然语言处理技术,特别涉及一种挖掘具有相似需求的查询的方法及装置。
背景技术:
随着搜索引擎的广泛使用,搜索引擎技术得到了长足发展。如今的搜索引擎,已经不仅仅停留在为用户提供与检索词匹配的检索结果上,而是越来越关注如何才能更好地满足用户需求。假如用户输入“qq个性签名”,搜索引擎不仅给出与用户输入的查询一致的结果,还给出与用户的查询需求相似的检索结果,如给出“qq个性签名伤感”、“qq个性签名搞笑”、“qq个性签名幸福”、“qq个性签名可爱”等具有相似需求的查询所对应的检索结果,搜索引擎就可以为用户在搜索结果的筛选与获得上提供最直接的参考,从而减少用户的检索次数,提升用户的搜索体验。而要让搜索引擎能够根据用户输入的查询,返回所有与用户输入的查询具有相似需求的检索结果,就需要对用户具有相似需求的查询进行挖掘。此外,对具有相似需求的查询进行挖掘,还可以为搜索引擎的其他应用提供资源,例如为生成与检索需求相关的查询模板提供语料,或者将相似需求的查询作为训练语料,训练与需求类型相关的分类器,还可以将相似需求查询以搜索建议的形式提供给用户,帮助及引导用户更快地找到与自己搜索意图接近的查询,从而获得更准确的搜索结果等等。
技术实现要素:
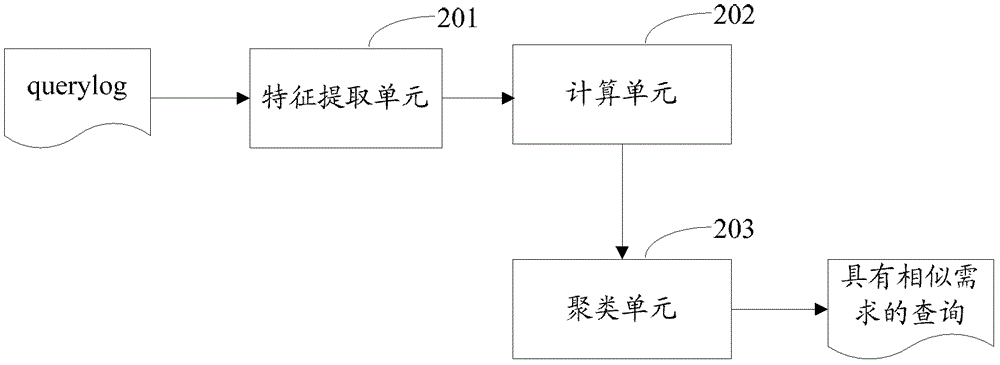
本发明所要解决的技术问题是提供一种挖掘具有相似需求的查询的方法及装置,以提高搜索引擎满足用户需求的能力,从而减少用户的检索次数,减少检索系统的开销。本发明为解决技术问题而采用的技术方案是提供一种挖掘具有相似需求的查询的方法,包括:为多个查询对提取会话共现特征、点击重合度特征或点击相互满足特征中的至少一个特征,其中一个查询对由搜索日志中的任意两个查询构成,所述会话共现特征用于表征一个查询对中的两个查询在相同会话中共同出现的可能性,所述点击重合度特征用于表征一个查询对中的两个查询各自引起的点击页面的重合度,所述点击相互满足特征用于表征一个查询对中的两个查询各自得到的满足度达到预设要求的页面满足该查询对中的另一个查询的程度;根据提取的每个特征及每个特征的权重计算各查询对中的两个查询之间的相似度;选取两个查询之间的相似度大于设定值的查询对,并在选取的查询对中将相互之间有交集的查询对聚为一类,将属于同一类的查询对中的查询作为具有相似需求的查询。根据本发明之一优选实施例,一个查询对的会话共现特征采用下列方式计算:其中coOccurScore(query1,query2)表示由查询query1和查询query2构成的查询对的会话共现特征,coOccurCount(query1,query2)表示query1与query2在搜索日志的相同会话中共同出现的次数,count(query1)表示query1在搜索日志中出现的总次数,count(query2)表示query2在搜索日志中出现的总次数。根据本发明之一优选实施例,一个查询对的点击重合度特征采用下列方式计算:其中urlRatioScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击重合度特征,coCount(url1,url2)表示query1与query2各自在搜索日志里引起的点击页面中相同页面的数量,count(url1)表示query1在搜索日志里引起的所有点击页面的数量,count(url2)表示query2在搜索日志里引起的所有点击页面的数量。根据本发明之一优选实施例,一个查询对的点击相互满足特征采用下列方式计算:其中satisScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击相互满足特征,表示query1得到的各个满足度达到预设要求的页面对query2的满足度之和,表示query1得到的各个满足度达到预设要求的页面对query1自身的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query1的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query2的满足度之和,其中一个页面对一个查询的满足度由该查询在一次搜索过程中以该页面作为最后一个点击页面的情况记录在搜索日志中的总次数决定。根据本发明之一优选实施例,一个页面对一个查询的满足度采用下列方式进行计算:其中satis(URL,query)表示页面URL对查询query的满足度,one2one(URL,query)表示query在一次搜索过程中仅点击一个页面且该页面为URL的情况记录在搜索日志中的总次数,last(URL,query)表示query在一次搜索过程中点击了多个页面且以URL作为最后一个点击页面的情况记录在搜索日志中的总次数,notlast(URL,query)表示query在一次搜索过程中点击了多个页面且URL不是最后一个点击页面的情况记录在搜索日志中的总次数,α、β、χ表示权重且1≥α,β,χ≥0,clickcount(URL,query)表示在query的搜索过程中点击了URL的情况记录在搜索日志中的总次数。根据本发明之一优选实施例,该方法还包括确定所述每个特征的权重的步骤,具体包括:从所述多个查询对中选取标准查询对集合;利用所述标准查询对集合训练提取的各特征对应的参数,将训练中使得所述标准查询对集合中的查询对在所述多个查询对中的排名无法更靠前时的参数值作为对应特征的权重。根据本发明之一优选实施例,从所述多个查询对中选取标准查询对集合的步骤包括:针对提取的每个特征分别基于特征值对所述多个查询对进行排序,分别针对每个特征取排列在前N位的查询对作为对应特征的查询对集合,其中N为正整数;取各特征的查询对集合之间的交集作为标准查询对集合。本发明还提供了一种挖掘具有相似需求的查询的装置,包括:特征提取单元,用于为多个查询对提取会话共现特征、点击重合度特征或点击相互满足特征中的至少一个特征,其中一个查询对由搜索日志中的任意两个查询构成,所述会话共现特征用于表征一个查询对中的两个查询在相同会话中共同出现的可能性,所述点击重合度特征用于表征一个查询对中的两个查询各自引起的点击页面的重合度,所述点击相互满足特征用于表征一个查询对中的两个查询各自得到的满足度达到预设要求的页面满足该查询对中的另一个查询的程度;计算单元,用于根据提取的每个特征及每个特征的权重计算各查询对中的两个查询之间的相似度;聚类单元,用于选取两个查询之间的相似度大于设定值的查询对,并在选取的查询对中将相互之间有交集的查询对聚为一类,将属于同一类的查询对中的查询作为具有相似需求的查询。根据本发明之一优选实施例,所述特征提取单元提取一个查询对的会话共现特征时,采用下列方式计算该查询对的会话共现特征:其中coOccurScore(query1,query2)表示由查询query1和查询query2构成的查询对的会话共现特征,coOccurCount(query1,query2)表示query1与query2在搜索日志的相同会话中共同出现的次数,count(query1)表示query1在搜索日志中出现的总次数,count(query2)表示query2在搜索日志中出现的总次数。根据本发明之一优选实施例,所述特征提取单元在提取一个查询对的点击重合度特征时,采用下列方式计算该查询对的点击重合度特征:其中urlRatioScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击重合度特征,coCount(url1,url2)表示query1与query2各自在搜索日志里引起的点击页面中相同页面的数量,count(url1)表示query1在搜索日志里引起的所有点击页面的数量,count(url2)表示query2在搜索日志里引起的所有点击页面的数量。根据本发明之一优选实施例,所述特征提取单元在提取一个查询对的点击相互满足特征时,采用下列方式计算该查询对的点击相互满足特征:其中satisScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击相互满足特征,表示query1得到的各个满足度达到预设要求的页面对query2的满足度之和,表示query1得到的各个满足度达到预设要求的页面对query1自身的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query1的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query2的满足度之和,其中一个页面对一个查询的满足度由该查询在一次搜索过程中以该页面作为最后一个点击页面的情况记录在搜索日志中的总次数决定。根据本发明之一优选实施例,所述特征提取单元在提取一个查询对的点击相互满足特征时,采用下列方式计算一个页面对一个查询的满足度:其中satis(URL,query)表示页面URL对查询query的满足度,one2one(URL,query)表示query在一次搜索过程中仅点击一个页面且该页面为URL的情况记录在搜索日志中的总次数,last(URL,query)表示query在一次搜索过程中点击了多个页面且以URL作为最后一个点击页面的情况记录在搜索日志中的总次数,notlast(URL,query)表示query在一次搜索过程中点击了多个页面且URL不是最后一个点击页面的情况被记录在搜索日志中的总次数,α、β、χ表示权重且1≥α,β,χ≥0,clickcount(URL,query)表示在query的搜索过程中点击了URL的情况记录在搜索日志中的总次数。根据本发明之一优选实施例,该装置还包括权重确定单元,用于为提取的每个特征确定相应的权重;所述权重确定单元包括:标准选取单元,用于从所述多个查询对中选取标准查询对集合;训练单元,用于利用所述标准查询对集合训练提取的各特征对应的参数,将训练中使得所述标准查询对集合中的查询对在所述多个查询对中的排名无法更靠前时的参数值作为对应特征的权重。根据本发明之一优选实施例,所述标准选取单元包括:排序单元,用于针对提取的每个特征分别基于特征值对所述多个查询对进行排序,分别针对每个特征取排列在前N位的查询对作为对应特征的查询对集合,其中N为正整数;交集单元,用于取各特征的查询对集合之间的交集作为标准查询对集合。由以上技术方案可以看出,通过为搜索日志里由任意两个查询构成的查询对提取会话共现特征、点击重合度特征或点击相互满足特征中的至少一个特征,能够很好地判断搜索日志中任意两个查询的相似度,通过将相似度高的查询聚为一类,就可以从搜索日志中挖掘出具有相似需求的查询,从而为搜索引擎更好地满足用户需求提供了保障,可以减少用户的检索次数,减少搜索引擎的系统开销。【附图说明】图1为本发明中挖掘具有相似需求的查询的方法的实施例的流程示意图;图2为本发明中挖掘具有相似需求的查询的装置的一个实施例的结构示意框图;图3为本发明中挖掘具有相似需求的查询的装置的又一实施例的结构示意框图;图4为本发明中权重确定单元的实施例的结构示意框图。【具体实施方式】为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。请参考图1,图1为本发明中挖掘具有相似需求的查询的方法的实施例的流程示意图。如图1所示,该方法包括:步骤S101:为多个查询对提取特征。步骤S102:根据提取的每个特征及每个特征的权重计算各查询对中的两个查询之间的相似度。步骤S103:选取两个查询之间的相似度大于设定值的查询对,并在选取的查询对中将相互之间有交集的查询对聚为一类,将属于同一类的查询对中的查询作为具有相似需求的查询。下面对上述步骤进行具体介绍。本发明基于搜索日志(querylog)挖掘具有相似需求的查询(query),搜索日志是一个记录了用户在搜索时输入的多个查询以及用户在输入每个查询时对应点击的一个或多个页面地址的文件。步骤S101中,一个查询对由搜索日志中记录的任意两个查询构成。为查询对提取的特征至少包括以下特征中的一个:会话(session)共现特征、点击重合度特征及点击相互满足特征。查询对的会话共现特征用于表征该查询对中的两个查询在相同会话中共同出现的可能性。查询对的点击重合度特征用于表征该查询对中的两个查询各自引起的点击页面的重合度。查询对的点击相互满足特征用于表征该查询对中的两个查询各自得到的满足度达到预设要求的页面满足该查询对中的另一个查询的程度。具体地,一个查询对的会话共现特征可采用公式(1)进行计算:其中coOccurScore(query1,query2)表示由查询query1和查询query2构成的查询对的会话共现特征,coOccurCount(query1,query2)表示query1与query2在搜索日志的相同会话中共同出现的次数,count(query1)表示query1在搜索日志中出现的总次数,count(query2)表示query2在搜索日志中出现的总次数。一个会话指的是同一个用户执行各种操作的一段时间。例如同一个用户打开搜索引擎网页、发出各个查询请求、点击各个搜索结果页面、关闭浏览器窗口的一段时间就可以形成一个会话。搜索日志中记录了在各个会话中用户点击的查询及该查询对应点击的页面地址,由于在一个会话中记录的是同一个用户执行的各种操作,可以理解,在同一个会话中用户发出的各个查询请求,很可能具有相似的需求。例如在一个会话中用户搜索了“德乙积分榜”、“德甲积分榜”、“意甲排行榜”,这些查询之间就有相似的需求。通过公式(1)的方式计算查询对的会话共现特征,可以衡量搜索日志中任意两个查询之间的接近程度。显然,如果两个查询总是在相同的会话中出现,也就是说用户在搜索这两个查询中的一个时,也会接着搜索这两个查询中的另一个,则说明这两个查询之间有相似需求的可能性很大。例如“意甲积分榜”与“意甲积分榜是”在相同的会话中出现过1900次,“意甲积分榜”与“意甲德甲积分榜”在相同的会话中出现过2000次,而“意甲积分榜”、“意甲积分榜是”、“意甲德甲积分榜”在搜索日志中分别单独出现过2100次、2150次和2200次,则说明这两个查询对中的查询共现的频率是非常高的,也就说明这几个查询之间有非常相似的需求。具体地,一个查询对的点击重合度特征可采用公式(2)进行计算:其中urlRatioScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击重合度特征,coCount(url1,url2)表示query1与query2各自在搜索日志里引起的点击页面中相同页面的数量,count(url1)表示query1在搜索日志里引起的所有点击页面的数量,count(url2)表示query2在搜索日志里引起的所有点击页面的数量。由于每个页面都会描述一个主题,因此,点击了相同页面的不同查询之间有可能存在相似的需求(即这个相同页面的内容)。通过这个特点,采用公式(2)可以很好得获得两个查询之间点击页面的重合度。例如下面是三个查询及其分别引起的点击页面:query1:QQ签名引起的点击页面有:http://app.baidu.com/QQ签名http://www.51gxqm.com/http://www.77hh.net/http://app.baidu.com/非主流QQ签名http://www.qqgxzlw.cn/http://app.baidu.com/qq签名大全http://www.qqgxm.com/http://www.ksij.cn/query2:qq个性签名引起的点击页面有:http://www.77hh.net/http://www.qqwangming.org/article/QQGeRenQianMing/http://app.baidu.com/个性QQ签名http://www.ksij.cn/query3:穿越火线一键改QQ签名引起的点击页面有:http://cf.qq.com/act/a20110608-3rd/qm.shtmlhttp://game.shangdu.com/news/xygl/2011-08-09/358457.htmlhttp://cf.qq.com/act/a20110608-3rd/qm.shtml可见,在query1、query2引起的点击页面中,存在两个相同的点击页面(http://www.77hh.net/与http://www.ksij.cn/),因此计算由query1与query2构成的查询对的点击重合度特征为:而query1与query3或query2与query3之间没有相同的点击页面,因此query1与query3构成的查询对的点击重合度特征为:query2与query3构成的查询对的点击重合度特征为:可以看出,根据查询对的点击重合度特征,query1和query2在搜索意图上比较相似,而query3则与quey1和query2都不太相似。具体地,一个查询对的点击相互满足特征采用公式(3)进行计算:其中satisScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击相互满足特征,表示query1得到的各个满足度达到预设要求的页面对query2的满足度之和,表示query1得到的各个满足度达到预设要求的页面对query1自身的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query1的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query2自身的满足度之和,其中一个页面对一个查询的满足度由该查询在一次搜索过程中以该页面作为最后一个点击页面的情况记录在搜索日志中的总次数决定。用户在一次搜索过程中,针对一个查询,有可能点击一个页面,也有可能点击多个页面。可以认为,当用户在搜索一个查询时最后一个点击页面对用户的满足程度较好(用户在最后一个点击页面中获得了需要的信息从而不再点击其他页面),而一个页面在一个查询的一次搜索过程中作为最后一个点击页面的情况又可以分为两种:一种是用户检索该查询时,仅点击了一个页面,点击的第一个也是最后一个页面就是该页面;另一种是用户检索该查询时,点击了多个页面,但是点击的最后一个页面是该页面。很显然,对于上述的第一种情况,这个在查询的检索过程中唯一被点击的页面对该查询的满足度是最高的(用户点击该页面即已获得所有需要的信息),因此在计算一个页面对一个查询的满足度的时候,根据上述两种细分的情况,可以采用公式(4)进行计算:其中satis(URL,query)表示页面URL对查询query的满足度,one2one(URL,query)表示query在一次搜索过程中仅点击一个页面且该页面为URL的情况记录在搜索日志中的总次数,last(URL,query)表示query在一次搜索过程中点击了多个页面且以URL作为最后一个点击页面的情况记录在搜索日志中的总次数,notlast(URL,query)表示query在一次搜索过程中点击了多个页面且URL不是最后一个点击页面的情况记录在搜索日志中的总次数,clickcount(URL,query)表示在query的搜索过程中点击了URL的情况记录在搜索日志中的总次数,α、β、χ表示权重且1≥α,β,χ≥0,优选地,可以设为1≥α>β>χ≥0。通过公式(4),可以计算一个页面对一个查询的满足度。对由查询1和查询2组成的查询对,分别计算其中的查询1与查询2各自引起的点击页面对各自的满足度,从查询1引起的所有点击页面中选取满足度大于预设要求的各个页面,并计算选取的这些页面对查询2的满足程度,从查询2引起的所有点击页面中选取满足度大于预设要求的各个页面,并计算选取的这些页面对查询1的满足程度,就可以按照公式(3)得到查询1和查询2构成的查询对的点击相互满足特征。对一个查询对提取了上述几个特征后,可对提取的这几个特征进行融合。具体地,可按照公式(5)计算该查询对中的两个查询之间的相似度:Sim(query1,query2)=λ1coOccurScore(query1,query2)+(5)λ2urlRatioScore(query1,query2)+λ3satisScore(query1,query2)其中Sim(query1,query2)表示查询query1和查询query2在搜索意图上的相似度,λ1、λ2、λ3分别为上面提取的几个特征对应的权重,该权重值可以采用预先设置的值,也可以采用机器学习的方法自动学习出来,即在步骤S102前,确定每个特征相应的权重(即确定λ1、λ2、λ3的值是多少)。具体地,利用机器学习的方法自动为提取的每个特征确定相应权重的过程包括:S1011:从步骤S101中提取了特征的多个查询对中选取标准查询对集合。S1012:利用标准查询对集合训练提取的各特征对应的参数,将训练中使得标准查询对集合中的查询对在步骤S101中提取了特征的多个查询对中的排名无法更靠前时的参数值作为对应特征的权重。步骤S1012中的训练过程可采用梯度下降的方法,由于该方法属于现有算法,在此不做更多的说明。步骤S1011包括:S10111:针对提取的每个特征分别基于特征值对步骤S101中提取了特征的多个查询对进行排序,分别针对每个特征取排列在前N位的查询对作为对应特征的查询对集合,其中N为正整数。S10112:取各特征的查询对集合之间的交集作为标准查询对集合。请参考表1,表1为基于每个特征对多个查询对进行排序的示意表格。表1假设步骤S10111中的N是5,则表1中的三个特征对应的查询对集合之间的交集就是查询对7和查询对10,也就是标准查询对集合由查询7和查询10构成。在确定了权重λ1、λ2、λ3以后,在步骤S102中就可以按照公式(5)计算搜索日志中任意两个查询之间的相似度了。应该理解,在本实施例中为了说明的方便,在确定各特征的权重时,是以提取了上述三种特征为例进行说明的,如果只对查询对提取了上述三种特征中的两种特征,本领域技术人员应该理解训练过程与上述说明是类似的,如果只对查询提取了上述三种特征中的一种特征,很显然,确定提取的这一种特征的权重时得到的值就是1。步骤S103是为了按照预设的相似度值对查询对进行选取,例如设定值为0.9,则相似度大于0.9的查询对就被挑选出来了,接着在这些挑选出来的查询对中根据查询对相互之间是否存在交集进行聚类。例如相似度大于0.9的查询对有查询对A(包括查询1和查询5)、查询对B(包括查询2和查询3)、查询对C(包括查询1和查询6)、查询对D(包括查询5和查询10)、查询对E(包括查询10和查询7)、查询对F(包括查询10和查询12)、查询对G(包括查询3和查询8)。可以看出,查询对A与查询对C之间有交集,所以查询对A与查询对C是一类,又因为查询对A与查询对D之间有交集,所以查询对A与查询对D也是一类,从而查询对A、C、D属于一类,同样的道理可知查询对A、C、D、E、F是一类,查询对B与查询对G是一类。所以可以得知,查询1、5、6、7、10、12是具有相似需求的查询,查询2、3、8是具有相似需求的查询。请参考图2。图2为本发明中挖掘具有相似需求的查询的装置的一个实施例的结构示意框图。如图2所示,该装置包括:特征提取单元201、计算单元203及聚类单元204。其中,特征提取单元201用于为多个查询对提取会话共现特征、点击重合度特征或点击相互满足特征中的至少一个特征,其中一个查询对由搜索日志中的任意两个查询构成,所述会话共现特征用于表征一个查询对中的两个查询在相同会话中共同出现的可能性,所述点击重合度特征用于表征一个查询对中的两个查询各自引起的点击页面的重合度,所述点击相互满足特征用于表征一个查询对中的两个查询各自得到的满足度达到预设要求的页面满足该查询对中的另一个查询的程度。计算单元202用于根据提取的每个特征及每个特征的权重计算各查询对中的两个查询之间的相似度。聚类单元203用于选取两个查询之间的相似度大于设定值的查询对,并在选取的查询对中将相互之间有交集的查询对聚为一类,将属于同一类的查询对中的查询作为具有相似需求的查询。具体地,特征提取单元201在提取一个查询对的会话共现特征时,采用下列公式计算该查询对的会话共现特征:其中coOccurScore(query1,query2)表示由查询query1和查询query2构成的查询对的会话共现特征,coOccurCount(query1,query2)表示query1与query2在搜索日志的相同会话中共同出现的次数,count(query1)表示query1在搜索日志中出现的总次数,count(query2)表示query2在搜索日志中出现的总次数。具体地,特征提取单元201在提取一个查询对的点击重合度特征时,采用下列公式计算该查询对的点击重合度特征:其中urlRatioScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击重合度特征,coCount(url1,url2)表示query1与query2各自在搜索日志里引起的点击页面中相同页面的数量,count(url1)表示query1在搜索日志里引起的所有点击页面的数量,count(url2)表示query2在搜索日志里引起的所有点击页面的数量。具体地,特征提取单元201在提取一个查询对的点击相互满足特征时,采用下列公式计算该查询对的点击相互满足特征:其中satisScore(query1,query2)表示由查询query1和查询query2构成的查询对的点击相互满足特征,表示query1得到的各个满足度达到预设要求的页面对query2的满足度之和,表示query1得到的各个满足度达到预设要求的页面对query1自身的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query1的满足度之和,表示query2得到的各个满足度达到预设要求的页面对query2的满足度之和,其中一个页面对一个查询的满足度由该查询在一次搜索过程中以该页面作为最后一个点击页面的情况记录在搜索日志中的总次数决定。具体地,一个页面对一个查询的满足度可采用下列公式进行计算:其中satis(URL,query)表示页面URL对查询query的满足度,one2one(URL,query)表示query在一次搜索过程中仅点击一个页面且该页面为URL的情况记录在搜索日志中的总次数,last(URL,query)表示query在一次搜索过程中点击了多个页面且以URL作为最后一个点击页面的情况记录在搜索日志中的总次数,notlast(URL,query)表示query在一次搜索过程中点击了多个页面且URL不是最后一个点击页面的情况被记录在搜索日志中的总次数,α、β、χ表示权重且1≥α,β,χ≥0,clickcount(URL,query)表示在query的搜索过程中点击了URL的情况记录在搜索日志中的总次数。计算单元202计算各查询对中的两个查询之间的相似度时,每个特征的权重可以是预先设置的值,也可以采用机器学习的方法自动学习得到。请参考图3,图3为挖掘具有相似需求的查询的装置的又一实施例的结构示意框图。在该实施例中,该装置还进一步包括权重确定单元204,用于为提取的每个特征确定相应的权重。请参考图4,图4为本发明中权重确定单元的实施例的结构示意框图。如图3所示,权重确定单元204包括标准选取单元2041及训练单元2042。其中标准选取单元2041,用于从特征提取单元201提取了特征的多个查询中选取标准查询对集合。训练单元2042,用于利用标准查询对集合训练提取的各特征对应的参数,将训练中使得标准查询对集合中的查询对在特征提取单元201提取了特征的多个查询对中的排名无法更靠前时的参数值作为对应特征的权重。如图4所示,标准选取单元2041包括排序单元20411和交集单元20412。其中排序单元20411用于针对提取的每个特征分别基于特征值对特征提取单元201提取了特征的多个查询对进行排序,分别针对每个特征取排列在前N位的查询对作为对应特征的查询对集合,其中N为正整数。交集单元20412用于取各特征的查询对集合之间的交集作为标准查询对集合。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1