声音数据检索系统及用于该系统的程序的制作方法与工艺
本发明涉及检索声音数据的系统。
背景技术:
随着近年来的存储设备的大容量化,能够储存大量的声音数据。在以往的许多声音数据库中,为了管理声音数据而赋予对声音进行录音的时刻的信息,并基于该信息检索希望的声音数据。但是,在基于时刻信息的检索中,需要预先知道讲出希望的声音的时刻,不适合于检索讲话中包含指定的关键字的声音的用途。在检索讲话中包含指定的关键字的声音的情况下,需要将声音从头到尾进行听取。所以,开发了自动地检测讲出声音数据库中的指定的关键字的时刻的技术。在作为代表性的方法之一的子字检索法中,首先通过子字识别(Sub-wordrecognition)处理将声音数据变换为子字串。这里,所谓子字,是指音素(Phoneme)或音节(Syllable)等比单词更小的单位的名称。如果输入关键字,则将该关键字的子字表现与声音数据的子字识别结果进行比较,检测子字的一致度高的部分,由此在声音数据中检测讲出该关键字的时刻(专利文献1、非专利文献1)。此外,在非专利文献2所示出的字定位(wordspotting)法中,通过将音素单位的声学模型(Acousticmodel)组合而生成该关键字的声学模型,通过进行该关键字声学模型与声音数据的对照,在声音数据中检测讲出该关键字的时刻。但是,哪种技术都受到讲话的变动(方言或说话者不同等)或噪声的影响,检索结果中包含错误,有时实际上没有讲出该关键字的时刻会出现在检索结果中。因此,用户为了将错误的检索结果去除,需要从通过检索得到的关键字的讲话时刻起将声音数据再现、通过听取来判断该关键字是否真正被讲出。还提出了用来辅助如上所述的正解/非正解判断的技术。在专利文献2 中公开了为了通过听取来判断该关键字是否真正被讲出而强调该关键字的检测时刻来进行再现的技术。专利文献1:特开2002-221984号公报专利文献2:特开2005-38014号公报非专利文献1:岩田耕平等,“語彙フリー音声文書検索手法における新しいサブワードモデルとサブワード音響距離の有効性の検証(无词汇约束的声音文件检索方法中的新子字模型和子字声学距离的有效性的验证)”信息处理学会论文杂志,Vol.48,No.5,2007非专利文献2:河原达也,宗续敏彦,堂下修司,“ヒューリスティックな言語モデルを用いた会話音声中の単語スポッティング(使用启发式语言模型的会话声音中的单词定位)”,信学论.D-II,信息系统,II-信息处理,vol.78,no.7,pp.1013-1020,1995.在专利文献2中公开了为了通过听取来判断该关键字是否真正被讲出而强调该关键字的检测时刻来进行再现的技术。但是,在用户不能充分理解作为检索对象的声音数据的语言的状况下,经常有难以通过听取来进行如上所述的正解/非正解的判断的问题。例如,用户用“play”这样的关键字进行检索的结果,有时会检测出实际上讲出“pray”的时刻。在此情况下,不充分理解英语的日本人用户有可能将其判断为说了“play”。通过如专利文献2提出的将该关键字的检测位置强调再现的技术不能解决上述问题。
技术实现要素:
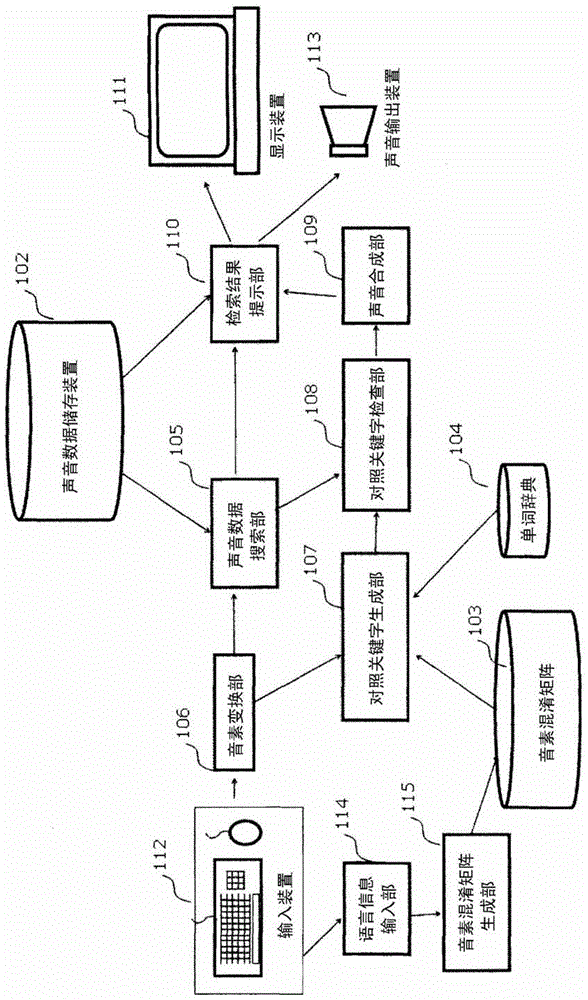
本发明的目的是解决这样的问题,使得在声音数据检索系统中能够容易地进行检索结果的正解/非正解的判断。本发明为了解决上述问题,例如采用技术方案中所记载的结构。如果举出本发明的声音数据检索系统的一例,则是一种声音数据检索系统,具备:输入装置,输入关键字;音素变换部,将输入的上述关键字变换为音素标音;声音数据搜索部,基于音素标音的关键字,在声音数据中检索讲出该关键字的部分;对照关键字生成部,基于音素标音的关键字,生成用户有可能听取混淆的与该关键字不同的对照关键字的集合;以及检 索结果提示部,向用户提示来自上述声音数据搜索部的检索结果及来自上述对照关键字生成部的上述对照关键字。此外,如果举出本发明的程序的一例,则是一种用来使计算机作为声音数据检索系统发挥功能的程序,所述声音数据检索系统具备:音素变换部,将输入的上述关键字变换为音素标音;声音数据搜索部,基于音素标音的关键字,在声音数据中检索讲出该关键字的部分;对照关键字生成部,基于音素标音的关键字,生成用户有可能听取混淆的与该关键字不同的对照关键字的集合;以及检索结果提示部,向用户提示来自上述声音数据搜索部的检索结果及来自上述对照关键字生成部的上述对照关键字。根据本发明,在声音数据检索系统中,基于用户输入的关键字,生成用户有可能听取混淆的对照关键字集合并向用户提示,由此能够容易地进行检索结果的正解/非正解的判断。附图说明图1是表示采用本发明的计算机系统的结构的模块图。图2是将本发明的构成要素按照处理的流程配置的图。图3是表示本发明的处理的流程的流程图。图4是表示生成对照关键字候选的处理的流程的流程图。图5是表示单词辞典的一例的图。图6是表示音素混淆矩阵的一例的图。图7是表示对照关键字候选的检查的处理的流程的流程图。图8是表示向用户提示信息的画面的一例的图。图9是表示音素混淆矩阵的其他例的图。图10是表示编辑距离的计算过程的一例的图。图11是表示编辑距离的计算过程的其他例的图。图12是表示用户能够理解多种语言的情况下的音素混淆矩阵的一例的图。图13是表示编辑距离计算的伪代码的图。附图标记说明101计算机102声音数据储存装置103音素混淆矩阵104单词辞典105声音数据搜索部106音素变换部107对照关键字生成部108对照关键字检查部109声音合成部110检索结果提示部111显示装置112输入装置113声音输出装置114语言信息输入部115音素混淆矩阵生成部具体实施方式以下,基于附图说明本发明的实施方式。[实施例1]图1表示第1实施方式,是表示采用本发明的计算机系统的结构的模块图。此外,图2是将图1的构成要素按照处理的流程配置的图。本实施方式的计算机系统包括计算机101、显示装置111、输入装置112及声音输出装置113。在计算机101的内部中具有声音数据储存装置102、音素混淆矩阵(phonemeconfusionmatrix)103、单词辞典104,此外,具有声音数据搜索部105、音素变换部106、对照关键字(comparisonkeyword)生成部107、对照关键字检查部108、声音合成部109、检索结果提示部110、语言信息输入部114及音素混淆矩阵生成部115。声音数据检索系统可以通过在计算机(computer)中由CPU将规定的程序装载到存储器上、并且由CPU执行装载到存储器上的规定的程序来实现。该规定的程序虽然没有图示,但只要经由读取装置从存储该程序的存储介质、或者经由通信装置从网络输入而直接装载到存储器上、或者先保 存到外部存储装置中后装载到存储器上就可以。本发明的程序的发明是如此装入到计算机中并使计算机作为声音数据检索系统动作的程序。通过将本发明的程序装入到计算机中,构成图1及图2的模块图所示的声音数据检索系统。以下,对各构成要素的处理的流程进行记述。在图3中表示处理的流程图。[关键字输入及向音素表现的变换]如果用户从输入装置112以文本输入关键字(处理301),则首先音素变换部106将该关键字变换为音素表现(处理302)。例如,在用户作为输入而输入了关键字“play”的情况下,将其变换为“pleI”。该变换作为词素解析处理是已知的,对本领域的技术人员是周知的,所以省略说明。此外,也可以作为输入装置而使用麦克风,通过由用户对麦克风用声音讲出关键字,来进行关键字的输入。在此情况下,作为音素变换部而利用声音识别技术,从而能够将该声音波形变换为音素表现。[声音数据搜索]接着,声音数据搜索部105在储存在声音数据储存装置102中的声音数据中,检测讲出该关键字的时刻(处理303)。在该处理中,例如可以使用在非专利文献2中提示的字定位处理。或者,也可以利用专利文献1或非专利文献1等预先将声音数据储存装置进行预处理的方法。业者只要选择它们中的某一种方法就可以。[对照关键字候选的生成]接着,对照关键字生成部107生成用户有可能听取混淆的对照关键字集合(处理304)。在以下的说明中,假设将关键字用英语输入,而用户以日语为母语。但是,关键字的语言及用户的母语并不限定于英语和日语,在任何语言的组合下都能够实施。图4中表示处理的流程。首先,将对照关键字集合C初始化为空集合(处理401)。接着,对登录在英语的单词辞典中的全部的单词Wi,计算其音素标音(phonemictranscription,日文:音素表記)与用户输入的关键字K的音素标音之间的编辑距离(EditDistance)Ed(K,Wi)(处理403)。如果相对于该单词Wi的编辑距离是阈值以下,则将该单词追加到对照关键 字集合C中(处理404)。最后,输出对照关键字集合C。图5中表示单词辞典的例子。如图5所示,单词辞典记载有许多单词501与该音素表现502的组。图6中表示日语说话者用的音素混淆矩阵的例子。在音素混淆矩阵中,用0到1之间的数值记载,在纵列所示的音素与在横行所示的音素容易混淆的情况下为接近于0的值,在不易混淆的情况下为接近于1的值。其中,SP是表示“无声”的特殊记号。例如,音素b不易与音素a混淆,因此在音素混淆矩阵中被分配了1。相对于此,音素l和音素r对于以日语为母语的用户而言是容易混淆的音素,所以在音素混淆矩阵中被分配0值。在相同的音素的情况下总是被分配0。音素混淆矩阵按照用户的母语语言准备1个。以下,在音素混淆矩阵中,将对音素X的行、音素Y的列分配的值表示为Matrix(X,Y)。所谓编辑距离,是定义某字符串A与字符串B之间的距离尺度的距离,定义为用来对字符串A实施替换、插入、删除的各操作而变换为字符串B的最小操作成本。例如在如图10所示字符串A是abcde、字符串B是acfeg时,通过首先将字符串A的第2个字符b删除、将字符串A的第4个字符d替换为f、对字符串A的最末尾追加g,能够变换为字符串B。这里,分别定义有关替换、插入、删除的成本,将选择了操作成本之和最小的操作时的操作成本之和作为编辑距离Ed(A,B)。在本实施例中,假设某个音素X的有关插入的成本是Matrix(SP,X),某个音素X的有关删除的成本是Matrix(X,SP),有关将音素X替换为音素Y的成本是Matrix(X,Y)。由此,能够计算反映了音素混淆矩阵的编辑距离。例如考虑按照图6的音素混淆矩阵来计算关键字“play”的音素表现“pleI”与单词“pray”的音素表现“preI”的编辑距离。通过将“pleI”的第2个字符l替换为r,能够变换为“preI”。这里,在图6的音素混淆矩阵中,由于对l和r分配了0值,所以将l替换为r的成本Matrix(l,r)是0,所以“pleI”能够以成本0变换为“preI”,因而,计算为编辑距离Ed(play,pray)=0。另外,作为编辑距离的高效率的计算方法的动态计划法对于本领域的技术人员是周知的,所以这里仅表示伪代码。图13中示出了伪代码。这里, 音素串A的第i个字符的音素表示为A(i),假设音素串A和音素串B的长度分别为N和M。此外,作为与上述不同的编辑距离的定义,也可以定义为用来对字符串A实施替换、插入、删除的各操作而使操作后的字符串包含于字符串B中的最小操作成本。例如在如图11所示字符串A是abcde、字符串B是xyzacfegklm的情况下,通过首先将字符串A的第2个字符b删除,接着将第3个字符的字符d替换为f,从而操作后的字符串acfe包含在字符串B中。将此时的操作成本之和作为编辑距离Ed(A,B)。在对照关键字生成中,作为编辑距离的定义,使用上述两种的任何一种都可以。此外,除了上述所示的处理以外,只要是计测字符串间的距离的方法,任何一种方法都能够利用。进而,在图4的处理403、404中,不仅是单词Wi,也可以使用单词串W1…WN。进而,也可以是,在处理403中,不仅求出编辑距离Ed(K,W1…WN),还一起求出生成单词串W1…WN的概率P(W1…WN),在处理404中如果编辑距离是阈值以下、且P(W1…WN)是阈值以上则设为C←C∪{W1…WN}。在此情况下,在对照关键字集合中还包括单词串。另外,作为P(W1…WN)的计算方法,例如可以使用在语言处理的领域中周知的N-gram模型。关于N-gram模型的详细情况对于本领域的技术人员是周知的,所以这里省略。此外,除上述以外,也可以利用将Ed(K,W1…WN)和P(W1…WN)组合的任意的尺度。例如在处理404中也可以利用Ed(K,W1…WN)/P(W1…WN)、或P(W1…WN)*(length(K)-Ed(K,W1…WN))/length(K)这样的尺度。其中,length(K)是关键字K的音素表现中包含的音素数。[音素混淆矩阵的生成]在对照关键字生成中使用的音素混淆矩阵可以根据用户的母语或可使用语言进行切换。在此情况下,用户通过语言信息输入部114对系统输入关于用户的母语或可使用语言的信息。接受了来自用户的输入的系统通过音素混淆矩阵生成部115输出用户的母语用的音素混淆矩阵。例如图6中, 虽然是日语说话者用,但对于以中文为母语的用户,能够使用如图9所示的音素混淆矩阵。例如在图9中,与图6不同,音素l与音素r交叉的点是1,定义成这两个音素对于以中文为母语的用户而言不易混淆。音素混淆矩阵生成部并不限定于用户的母语,也可以根据用户能够理解的语言的信息来切换音素混淆矩阵。进而,在用户能够理解多种语言的情况下,音素混淆矩阵生成部115也可以生成将这些语言信息组合的音素混淆矩阵。作为实施例之一,针对能够理解α语和β语双方的用户,可以生成α语用户用的音素混淆矩阵的i行j列要素和β语用户用的音素混淆矩阵的i行j列要素中的更大一方作为i行j列要素的混淆矩阵。在能够理解三国语言以上的语言的情况下,也只要在各语言的音素混淆矩阵中按各矩阵要素选择最大的就可以。例如针对能够理解日语和中文的用户,生成图12的音素混淆矩阵。图12的音素混淆矩阵的各要素是代入日语说话者用音素混淆矩阵(图6)和中文说话者用音素混淆矩阵(图9)的各矩阵要素中的大的一方而成的。此外,也可以由用户直接操作音素混淆矩阵来调整矩阵的值。另外,音素混淆矩阵的生成可以在对照关键字生成部动作前的任意的定时进行。[对照关键字候选的检查]对于由对照关键字生成部107生成的对照关键字候选,对照关键字检查部108进行动作,选择是否向用户提示该对照关键字。由此,将不需要的对照关键字候选除去。在图7中表示该处理的流程。(1)首先,对于由对照关键字生成部107生成的全部的对照关键字候选Wi(i=1,…,N),设为flag(Wi)=0(处理701)。(2)接着,对从声音数据搜索部得到的关键字的讲话时刻候选全部进行以下的(i)~(iii)的处理。(i)将包含关键字的讲话时刻的起始端和末端的声音X切出(处理703)。(ii)对于全部的对照关键字候选Wi(i=1,…,N),进行对该声音的字定位处理(处理705)。(iii)对于字定位的结果得到的分数P(*Wi*|X)超过阈值的单词Wi,设为flag(Wi)=1(处理706)。(3)将flag(Wi)是0的关键字从对照关键字候选中去除(处理707)。另外,在字定位处理中,按照数式1式计算在声音X内讲出关键字Wi的概率P(*key*|X)。[数式1]这里,h0是任意的音素集合中的包含关键字的音素表现的要素,h1是任意的音素串集合的要素。详细情况在非专利文献2等中示出,对于本领域的技术人员是周知的,所以这里省略进一步的说明。此外,也可以是,在检查对照关键字时计算的字定位的值P(*Wi*|X)超过阈值的情况下,从检索结果中去除该检索结果。另外,对照关键字候选的检查处理也可以省略。[声音合成处理]将对照关键字候选及用户输入的关键字双方通过声音合成部109变换为声音波形。这里,关于将文本变换为声音波形的声音合成技术,对于本领域的技术人员是周知的,所以详细情况省略。[检索结果提示]最后,检索结果提示部110通过显示装置111及声音输出装置113,向用户提示关于检索结果及对照关键字的信息。在图8中表示此时向显示装置111显示的画面的例子。用户通过向检索窗801输入检索关键字并按下按钮802,能够在储存在声音数据储存装置102中的声音数据中检索讲出关键字的部分。在图8的例子中,用户检索“play”的关键字在储存在声音数据储存装置102中的声音数据中被讲出的部分。检索结果是用户输入的关键字被讲出的声音文件名805和该关键字在该声音文件内被讲出的时刻806,通过点击“从关键字起再现”807的部分,从该文件的该时刻起通过声音输出装置113再现声音。此外,通过点击“从文件开头起再现”808的部分,从该文件的开头起通过声音输出装置113 再现声音。此外,通过点击“听关键字声音合成”803的部分,将该关键字的声音合成通过声音输出装置113再现。由此,用户能够听该关键字的正确的发音,能够作为该检索结果是否正确的参考。此外,在图8的804中,作为对照关键字的候选而显示有pray和clay,如果点击“听音声合成”809的部分,则将该声音合成通过声音输出装置113再现。由此,用户注意到作为检索结果而有可能被误检测出“pray”、“clay”这样的关键字被讲出的部分,通过听该对照关键字的合成声音,用户能够作为判断该检索结果是否正确时的参考。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1