获取多音字拼音、基于拼音检索的方法及其相应装置与流程
本申请涉及信息检索技术领域,特别涉及一种获取多音字拼音的方法及装置、基于文字拼音的检索方法及装置。
背景技术:
随着信息技术的发展,涌现出越来越多的基于文字拼音的信息检索系统。这些信息检索系统通过直接接收文字拼音或将接收的文字按照默认方式转换为相应拼音后,以拼音为索引查找预置拼音数据库,获得与该拼音对应的一个或多个关键词,然后根据关键词进行海量信息检索获得检索结果。比如,百度搜索引擎可基于输入的汉语拼音给出提示词条,用户选择相应词条后,即以相应词条进行搜索获得相应信息;车载导航仪在接收汉字拼音首字母后可快速检索出海量地理信息。这些检索系统完成检索依赖于拼音数据库。拼音数据库以拼音为索引组织数据,一个拼音可标识具有该相同拼音的多个词组、短语或者句子。以中文拼音数据库为例,一种基于文字拼音的数据组织过程是:将汉字对应的汉语拼音建立一一对应的哈希表,汉字有多个读音时选择一个常规音作为默认音,将具有相同拼音的汉字或词组放置于相同区域构建成数据库,以便在接收到拼音时从该数据库中查找汉字检索词。与该方式类似的还有根据汉字在GBK(汉字国际扩展码)编码表内的分布情况获取拼音(参见图1(a)、图1(b)),或者将上述两种方式结合起来用于获取拼音,进而基于文字拼音的数据组织。但是,这些获取文字拼音的方式由于对多音字采取默认音,因此,大多数情况下无法获取多音字在不同语境下的正确拼音。此外,上述获取的多音字拼音仅有默认音,减少了以相同拼音组织数据的数据库的信息容量、增加了数据库内的数据的错误率,进而导致依据拼音对应的关键词进行检索后获得的检索结果准确率降低。
技术实现要素:
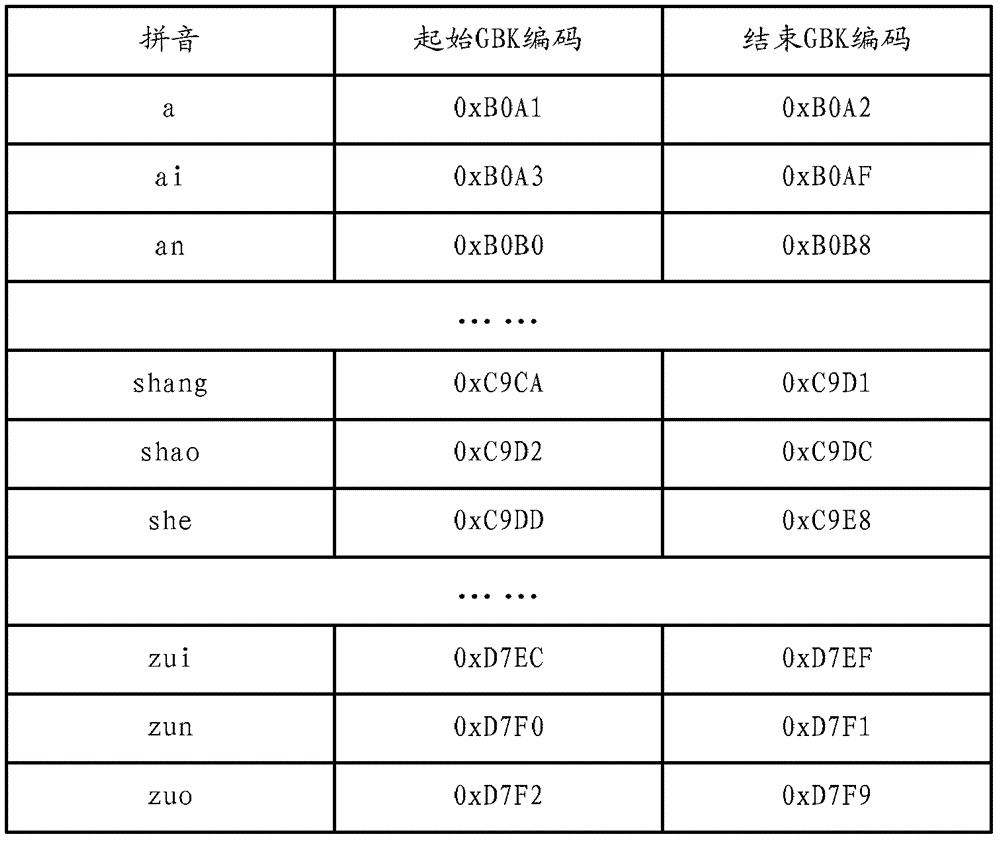
为解决上述技术问题,本申请实施例的目的在于提供一种获取多音字拼音的方法与装置,以及基于文字拼音的检索方法与装置,以获取多音字在不同语境下的正确读音以及提高基于文字拼音进行检索的检索准确率。本申请实施例提供的获取多音字拼音的方法包括:获取文字串;对所述文字串进行分词处理,以获得至少一个分词;将所述分词与预设的多音字表进行匹配,以判断分词是否包含多音字,若包含多音字,则将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表。优选地,若所述包含多音字的分词中进一步包含非多音字,则所述方法还包括:获取所述分词中每个非多音字的拼音;将所述分词中非多音字的拼音和多音字的拼音组合为所述分词的拼音;以所述分词的拼音或拼音的首字母为索引,将所述分词添加到拼音数据库中。优选地,获取所述分词中每个非多音字的拼音,具体包括:通过查找GBK编码表,获得所述分词中每个非多音字的拼音。优选地,将分词与预设的多音字表进行匹配以判断分词是否包含多音字,具体包括:将所述分词中的每个汉字分别与所述预设的多音字表进行匹配,若所述分词包含所述预设多音字表中的汉字,则确定所述分词包含多音字。优选地,所述预设多音字表中包含各多音字对应的默认音,若从预设多音字词语表中未获得所述分词中的多音字的拼音,则所述方法还包括:从所述预设多音字表中,获取所述分词中多音字对应的默认音,将所述默认音作为所述分词中的多音字的拼音。优选地,将所述分词与预设多音字词语表进行匹配以获得该分词中的多音字的拼音,包括:确定所述分词中的多音字在该分词中的位置;从所述多音字词语表中确定出至少一个预选分词,所述预选分词包含所述分词中的多音字,且该多音字在所述预选分词中的位置与该多音字在所述分词中的位置相同;将所述分词与确定出的预选分词进行匹配,若匹配成功,则从所述多音字词语表中,获取与所述分词匹配的预选分词中的多音字的拼音,将所述预选分词的多音字的拼音,确定为所述分词中的相应多音字的拼音。本申请实施例提供的获取多音字拼音装置包括:第一获取单元、切分单元、第一匹配单元和第二匹配单元,其中:所述第一获取单元,用于获取文字串;所述切分单元,用于对所述文字串进行分词处理,以获得至少一个分词;所述第一匹配单元,用于将分词与预设多音字表进行匹配,以判断分词是否包含多音字,若包含多音字,则触发第二匹配单元;所述第二匹配单元,用于将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表。优选地,所述装置还包括第二获取单元和添加单元,其中:所述第二获取单元,用于在所述多音字的分词中包含非多音字时,获取所述分词中每个非多音字的拼音,将所述分词中的非多音字的拼音和多音字的拼音组合为所述分词对应的拼音;所述添加单元,用于以所述分词的拼音或拼音的首字母为索引,将所述分词添加到拼音数据库中。优选地,所述第二获取单元获取所述分词中每个非多音字的拼音,具体用于:通过查找GBK编码表,获得所述分词中的每个非多音字的拼音。优选地,第一匹配单元将分词与预设多音字表进行匹配以判断分词是否包含多音字,具体包括:将所述分词中的每个汉字分别与所述预设多音字表进行匹配,若所述分词中包含所述预设多音字表中的汉字,则确定所述分词包含多音字。优选地,所述预设多音字表包含多音字的默认音,所述第二匹配单元进一步用于,若从预设多音字词语表中未获得所述分词中的多音字的拼音,从所述预设多音字表中,获取所述分词中多音字对应的默认音,将所述默认音作为所述分词中的多音字的拼音。优选地,所述第二匹配单元包括:第一确定子单元,第二确定子单元、匹配子单元和第三确定子单元,其中:所述第一确定子单元,用于确定所述分词中的多音字在该分词中的位置;所述第二确定子单元,用于从所述多音字词语表中确定出至少一个预选分词,所述预选分词包含所述分词中的多音字,且该多音字在所述预选分词中的位置与该多音字在所述分词中的位置相同;所述匹配子单元,用于将所述分词与确定出的预选分词进行匹配,若匹配成功,则触发第三确定子单元;所述第三确定子单元,用于从所述多音字词语表中,获取与所述分词匹配的预选分词中的多音字的拼音,将所述预选分词的多音字的拼音,确定为所述分词中的相应多音字的拼音。本申请实施例提供的基于文字拼音的检索方法包括:获取拼音或拼音首字母;以所述拼音或拼音首字母为索引查找拼音数据库;所述拼音数据库是以分词的拼音或拼音首字母为索引,将具有相同拼音或拼音首字母的分词作为一个索引单位进行数据组织,且当所述分词为包含多音字的分词时,该分词中的多音字在该分词中的拼音是通过与预设的多音字词语表进行匹配得到,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表;将查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索,获得检索结果。优选地,所述获取拼音或拼音首字母包括:接收用户输入的拼音或拼音首字母;或者,接收用户输入的文字串,并对所述文字串进行分词处理,以获得至少一个分词;将所述分词与预设多音字表进行匹配以判断分词是否包含多音字,若包含多音字,则将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表;获得分词的拼音后,提取分词的拼音或拼音首字母。优选地,在查找到的具有相同拼音或拼音首字母的分词包含多个时,提示用户进行选择,将用户选择的分词作为关键词进行检索,获取检索结果。本申请实施例提供的基于文字拼音的检索装置包括:第三获取单元、查找单元和检索单元,其中:所述第三获取单元,用于获取拼音或拼音首字母;所述查找单元,用于以所述第三获取单元获得的拼音或拼音首字母为索引查找拼音数据库,所述拼音数据库是以分词的拼音或拼音首字母为索引,将具有相同拼音或拼音首字母的分词作为一个索引单位进行数据组织,且当所述分词为包含多音字的分词时,该分词中的多音字在该分词中的拼音是通过与预设的多音字词语表进行匹配得到,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表;所述检索单元,用于将所述查找单元查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索,获得检索结果。优选地,所述第三获取单元接收用户输入的拼音或拼音首字母;或者,所述第三获取单元包括:接收子单元、切分子单元、第一匹配子单元、第二匹配子单元和提取子单元,其中:所述接收子单元,用于接收用户输入的文字串;所述切分子单元,用于对所述文字串进行分词处理,以获得至少一个分词;所述第一匹配子单元,用于将分词与预设多音字表进行匹配以判断分词是否包含多音字,若包含多音字,则触发第二匹配子单元;所述第二匹配子单元,用于将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述多音字词语表为包含多音字的词语与多音字在该词语中的读音之间的对应关系表;所述提取子单元,用于在获取分词的拼音后,提取分词的拼音或拼音首字母。优选地,所述装置还包括提示单元,用于在所述查找单元查找到的具有相同拼音或拼音首字母的分词包含多个时,提示用户进行选择;则:所述检索单元将用户选择的分词作为关键词进行检索,获取检索结果。本申请实施例给出了获取多音字拼音的方法与装置以及基于文字拼音的检索方法与装置。获取多音字拼音方法与装置的实施例,对文字串进行分词处理所得到的分词进行多音字判断,将包含多音字的分词与预设多音字词语表进行匹配,从而确定多音字在不同语境下的准确拼音。与现有技术相比,本申请实施例由于根据每个多音字的语境确定其各自的拼音,从而提高了获取多音字正确拼音的概率。此外,通过本申请实施例可获得多音字具有的多个拼音,而不再是一个默认拼音,将其用于组织拼音数据库时,增加了具有相同拼音的词组、短语或句子的数量,扩展了拼音数据库的信息容量,避免了包含多音字的分词由于拼音错误放入错误的拼音索引之下,从而也增加了拼音数据库内数据的正确率。基于文字拼音的检索方法与装置的实施例以获取的拼音为拼音首字母为索引查找拼音数据库,将查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索获得检索结果。与现有技术相比,由于本申请实施例的拼音数据库考虑了文字的多音字现象以及多音字在不同语境下的不同拼音问题,使拼音数据库的信息容量和其内部数据正确率得到提高,从而使得依据分词的准确拼音所对应的关键词,在拼音数据库中进行检索后所获取的检索结果准确率更高。附图说明为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1(a)、图1(b)为现有技术中GBK编码表的示意图;图2为本申请的获取多音字拼音的方法实施例的流程图;图3(a)为图2所述实施例中的预设多音字表的一种示意图;图3(b)为图2所述实施例中的预设多音字词语表的一种示意图;图4为图2所述实施例的一个实例的流程图;图5为本申请基于文字拼音的检索方法实施例的流程图;图6为图5所述实施例中的获取拼音或拼音首字母步骤的流程图;图7为本申请获取多音字拼音的装置实施例的结构框图;图8为本申请基于文字拼音的检索装置实施例的结构框图。具体实施方式为了使本技术领域的人员更好地理解本申请中的技术方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本申请作进一步详细的说明。参见图2,该图示出了本申请获取多音字拼音的方法实施例的流程。该实施例包括:步骤S201:获取文字串;文字串是文字的集合,获取文字串即是获取多个文字,这些文字可以表现为词组、短语,甚至一个句子。这里的“文字”可以是适应本申请主题的任何一种文字,即该文字具有拼音,可通过拼音方式进行数据组织。常见的如中文,每个汉字均对应至少一个拼音,还比如日文,每个日语词均对应至少一个平假名或片假名,平假名或片假名即是日语词汇的拼音。对于获取文字串的方式,具体可以表现为多种,比如直接接收用户输入的方式获取,也可以通过网络进行抓取,还可以从预先收集好的文字数据集中读取等方式获得文字串。步骤S202:对所述文字串进行分词处理,以获得至少一个分词;获取文字串后对文字串进行分词处理,其目的是获得一个或多个相对独立且具有自身含义的词语或短语,如果一个文字串过长也可以切分为一个或多个相对独立且具有自身含义的句子。这里对文字串做分词处理的具体方法,根据实际情况的不同,可选择不同的切分方式。分词技术在现有技术中已有较多的描述,这里为节约篇幅,仅简要介绍一种常用的正向/逆向最大匹配词典分词法。该方法在已构建的包含丰富、全面的中文词语(短语)词典的基础之上,按照一定的字符串匹配与词频统计策略,将文字串与词典内词条进行逐一、快速的匹配并进行词频统计,由此从该文字串内分析出若干个相对独立且具有自身含义的词语(或短语)。比如将“蚌埠市人民政府”的文字串切分为“蚌埠市”、“人民”、“政府”三个分词。步骤S203:将所述分词与预设多音字表进行匹配,以判断分词是否包含多音字,若包含多音字,则将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表;获得分词后,以每个分词为处理对象,分两步进行处理:一是判断该分词是否包含多音字;二是给出分词的正确拼音。分词内是否包含多音字影响到给出分词内汉字的正确拼音。判断分词是否包含多音字的文字,可通过将分词内的每个文字分别与预设的多音字表进行匹配的方式进行判断。以中文为例:汉语体系存在着多音字现象,但多音字的数量有限,据初略统计,《新华字典》所列多音字有六百多个,如:朝、行、壳、给、会、曾、长等。通过对这些汉字拼音进行统计可构建一个预设多音字表,该多音字表列出了汉语中所有的多音字。参见图3(a),该图示出了一种预设多音字表,该多音字表以拼音为序罗列出了汉语中的全部多音字,该表的第二列为多音字的预设默认拼音。通过匹配方式确定了分词是否包含多音字后,进行给出多音字的正确拼音的步骤:如果通过匹配,确认分词包含多音字,则将包含多音字的分词与预设多音字词语表进行匹配,预设多音字词语表以多音字为索引,列出了包含该多音字的词语以及多音字在该词语中的拼音(参见图3(b)),在该预设多音字词语表中查找到相应的多音字,然后比较分词与包含多音字的词语,若匹配上,则将多音字词语表登记的包含该多音字的词语对应的拼音作为多音字的拼音;如果通过匹配,确认分词内的字没有多音字,则可通过现有的方式给出拼音,比如通过查找哈希表或GBK编码表方式获得分词文字的拼音。上述实施例给出的获取多音字拼音的方法对文字串切分的分词进行多音字判断,将多音字与预设多音字词语表进行匹配,从而确定多音字在不同语境下的拼音。与现有技术相比,根据每个多音字所在的语境来确定该多音字的拼音,从而提高了获取多音字正确拼音的概率。上述实施例中若包含多音字的分词中进一步包含非多音字,还可以将分词的拼音用于组织拼音数据库。具体包括:获取所述分词中每个非多音字的拼音,具体方式可通过查找GBK编码表获得;将所述分词中非多音字的拼音和多音字的拼音组合为所述分词的拼音;以所述分词的拼音或拼音的首字母为索引,将所述分词添加到拼音数据库中。这里获得分词的拼音后,可以分词的拼音为索引,将具有相同拼音的分词作为一个索引单位添加进拼音数据库,也可以分词的拼音首字母为索引,将具有相同拼音首字母的分词作为一个索引单位添加到拼音数据库。添加进入拼音数据库的工作可以在获得一个包含多音字的分词的拼音后即进行,也可在从文字串中切分出来的包含多音字的全部分词的拼音均获得后进行,为避免在不同操作之间多次转换影响效率,本申请优选后者。按照上述方式组织的拼音数据库的一个拼音之下,对应多个分词,这多个分词可以预先分别对应相应的关联信息,以供用户检索数据库时直接获得这些关联信息。也可仅将分词作为关键词,在用户需要检索时利用这些关键词通过搜索引擎进行关联信息的检索。在获得包含多音字的分词的拼音后,将该分词添加到拼音数据库相应拼音或拼音首字母索引下,与现有技术相比,通过本申请实施例可获得多音字具有的多个拼音,而不再是一个默认拼音,将其用于组织拼音数据库时,增加了具有相同拼音的词组、短语或句子的数量,扩展了拼音数据库的信息容量,避免了包含多音字的分词由于拼音错误放入错误的拼音或拼音首字母索引之下,从而也增加了拼音数据库内数据的正确率。上述实施例中提到多音字的默认音,多音字的默认音也是多音字的常规音,在实际的语言应用过程中,使用频率较高。在多音字词语表中可以包含多音字的所有拼音对应的全部短语、词语,但是,这并不是最恰当的方式,因为,通常情况下,多音字常规音对应的词语较其他音的词语数量更多,如果让多音字词语表包含多音字所有拼音对应的全部短语,势必增加了多音字词语表的容量,容量增加将影响到匹配效率。为此,本申请优选在多音字表中列出多音字的常规音(默认音),而在多音字词语表中不列出包含常规音的多音字词语,这样虽然对多音字表的容量有所增加,但不影响多音字表的匹配效率,且相对于多音字词语表的容量而言,将大为减少多音字词语表的容量,从而有利于提高匹配效率。通过上述处理后,若从预设多音字词语表中未获得所述分词中的多音字的拼音,则从所述预设多音字表中,获取所述分词中多音字对应的默认音,将所述默认音作为所述分词中的多音字的拼音。上述实施例中,在将分词与预设多音字词语表进行匹配以获得分词中多音字拼音时,可以采用先从多音字词语表中查找出包含该多音字的词语,然后将分词与查找出的词语逐个匹配以获得多音字拼音。除这种方式外,本申请优选采用如下方式进行匹配过程:确定所述分词中的多音字在该分词中的位置;从所述多音字词语表中确定出至少一个预选分词,所述预选分词包含所述分词中的多音字,且该多音字在所述预选分词中的位置与该多音字在所述分词中的位置相同;将所述分词与确定出的预选分词进行匹配,若匹配成功,则从所述多音字词语表中,获取与所述分词匹配的预选分词中的多音字的拼音,将所述预选分词的多音字的拼音,确定为所述分词中的相应多音字的拼音。通过这种方式,可减少匹配的工作量,提高匹配效率。为了便于进一步理解本申请的多音字拼音获取方法以及基于包含多音字的分词拼音构建拼音数据库的过程,下面以一个具体的实例进行阐释。该实例中的文字串从预先收集好的中文数据集中读取。参见附图4,该图示出了该实例的流程。该流程包括:步骤S401:初始化参数i、j、k、r、s,即令i=1,j=1,k=1,r=1,s=1,其中:i表示中文数据集Sdb中的一条中文字串的序号,j表示中文字串分词后的一个分词的序号,k表示分词中的一个汉字的序号,r表示包含多音字的词语序列中的一个词语的序号,s表示包含多音字词语中的一个汉字的序号;步骤S402:判断i是否达到n(n为中文数据集Sdb包含的总中文字串数),若i<=n,则执行步骤S403;若i>n,则执行步骤S419;步骤S403:从中文数据集Sdb中取出第i条中文字串利用中文分词技术对进行分词处理,以得到组成该中文字串的各分词,即比如:中文字串“蚌埠市人民政府”经过分词后,共包括3个分词:“蚌埠市”、“人民”、“政府”;步骤S404:判断j是否达到m(m为中文字串包含的总分词数),若j<=m,则执行步骤S405;若j>m,则令i=i+1,返回步骤S402;步骤S405:从中文字串的分词序列中取出第j个分词,该分词包含C个汉字,即比如,“蚌埠市”分词,由3个汉字组成;步骤S406:判断k是否达到C,若k<=C,则执行步骤S407;若k>C,则令j=j+1,返回步骤S404;步骤S407:从上述分词的C个汉字中取出第k个汉字将与预设多音字表BasicTablePolyChar进行匹配,比如,将汉字“蚌”进行匹配;步骤S408:判断是否能够相互匹配,如果是,则说明该汉字为多音字,执行步骤S409;如果否,则说明该汉字不是多音字,执行步骤S410;步骤S409:从预设多音字表BasicTablePolyChar中取出信息其中Spell′为多音字的默认拼音,记录该多音字的默认拼音以及包含该多音字的分词,进入步骤S411;步骤S410:通过GBK编码获得的默认拼音Spellnormal,记录该默认拼音,令k=k+1,返回步骤S406;比如,汉字“市”默认拼音为“shi”,通过GBK编码即可获得该默认拼音;步骤S411:以多音字为关键词查找预设多音字词语表WorldTablePolySpell,找出该多音字Chark对应的包含该多音字的词语序列:其中1≤r≤L;比如如下的多音字词语序列:{行;[洗车行,hang,3],[鞋行,hang,2],[银行,hang,2],[行走,xing,1]};步骤S412:判断r是否达到L,若r≤L,则执行步骤S413;若r>L,则进入步骤S418;步骤S413:从多音字词语序列中取出第r个词语:该词语包含P个汉字;步骤S414:判断s是否达到P,若s≤P,则执行步骤S415;若s>P,则执行步骤S417;步骤S415:取出记录的包含多音字的分词与第r个词语的第s个汉字;步骤S416:比较两个汉字是否相同,如果相同,则令s=s+1,返回步骤S414;如果不同,则令r=r+1,返回步骤S412;步骤S417:将第r个词语中的多音字拼音记录为Chark的拼音,令k=k+1,返回步骤S406;步骤S418:将步骤S409记录的多音字的默认拼音作为Chark的拼音,k=k+1,返回步骤S406;步骤S419:获得中文数据集Sdb中全部的中文字串拼音后,以拼音或拼音首字母为索引,将具有相同拼音或拼音首字母的分词作为一个索引单位进行拼音数据库的组织。下面再以中文字串“美国银行”为例,进一步说明从文字串中获取文字串中的多音字的拼音过程。(1)对中文字串“美国银行”进行分词处理,得到两个分词“美国”和“银行”。(2)对上述两个分词中的第一个分词“美国”进行拼音转换:先读取其第一个汉字“美”,将“美”字与《多音字表》进行匹配,即在《多音字表》中查找是否包含“美”字;经查找,查找结果为:汉字“美”不是多音字。(3)通过查找《GBK编码表》获取“美”的默认拼音。非多音字汉字“美”的GBK编码为“0xC3C0”,在《GBK编码表》中找到与之相关的信息[mei,0xC3B5,0xC3C4],由此可知:汉字“美”的GBK编码在范围[0xC3B5,0xC3C4]内,因此,汉字“美”的拼音为“mei”。(4)获取第一个分词“美国”的第二个汉字“国”的拼音;分词“美国”的第二个汉字“国”的处理过程与“美”类似:汉字“国”也不是多音字,在《GBK编码表》内找到其相关信息为[guo,0xB9F8,0XB9FD],因此汉字“国”的拼音为“guo”。(5)对前述两个分词中的第二个分词“银行”进行拼音转换:先读取其第一个汉字“银”,将“银”字与《多音字表》进行匹配,即在《多音字表》中查找是否包含“银”字;经查找,查找结果为:汉字“银”不是多音字。(6)通过查找《GBK编码表》获取“银”的默认拼音;非多音字汉字“银”的GBK编码为“0xD2F8”,在《GBK编码表》内找到与之相关的信息[yin,0xD2F0,0xD3A1],由此可知:汉字“银”的GBK编码在范围[0xD2F0,0xD3A1]内,因此,汉字“银”(0xD2F8)的拼音为“yin”。(7)获取第二个分词“银行”的第二个汉字“行”的拼音,具体包括以下步骤:①将读取的“行”字与《多音字表》进行匹配,即在《多音字表》内查找是否包含“行”字;经查找,找到与之相匹配的信息[行,xing];②将汉字“行”与《多音字词语表》进行匹配,即在《多音字词语表》内进行查找处理;经查找,得到如下关于“行”的词语串信息:{行;[洗车行,hang,3],[鞋行,hang,2],[银行,hang,2],[行走,xing,1]};③从“行”的词语串中取出第一条词语信息[洗车行,hang,3],由于汉字“行”为词语“银行”的第二个汉字,因此该汉字的字位z=2;计算Posstart=z-3=2-3=-1,由于Posstart<0,因此,该第一条词语信息不是需要的目的词语信息;④从“行”的词语串中取出第二条词语信息[鞋行,hang,2],计算Posstart=z-2=2-2=0,令x=1;比较词语“银行”中第x个汉字(即“银”)与“鞋行”中第Posstart+x个汉字(即“鞋”),发现两个汉字不同,因此,该第二条词语信息不是需要的目的词语信息;⑤从“行”的词语串中取出第三条词语信息[银行,hang,2],计算Posstart=z-2=2-2=0,令x=1;比较词语“银行”中第x个汉字(即“银”)与“银行”中第Posstart+x个汉字(即“银”),发现两个汉字相同,令x=x+1;比较分词“银行”中第x个汉字(即“行”)与“银行”中第Posstart+x个汉字(即“行”),发现两个汉字也相同;⑥由于x=2,因此进行到该步骤⑤,即可得出汉字“行”在整条中文字串“美国银行”中的拼音为“hang”。通过上述实施例所述的方法,可以实现以拼音为索引的拼音数据库的组织,以这种形式完成拼音数据库可用于基于文字拼音的检索。为此,本申请还提供了一种基于文字拼音的检索方法实施例。参见附图5,该图示出了本申请基于文字拼音的检索方法实施例的流程。该实施例包括:步骤S501:获取拼音或拼音首字母;在搜索引擎中,通常设置一个输入框,该输入框用来接收用户的输入,为了采用本申请的方式进行检索,用户可以在搜索引擎输入框中直接输入拼音或拼音首字母,搜索引擎从而获取拼音或拼音首字母,用户也可以在搜索引擎输入框中输入文字串,通过对该文字串的转换来获取拼音或拼音首字母。参见附图6,该图示出了后一种获取拼音或拼音首字母的流程,包括:步骤S5011:接收用户输入的文字串;步骤S5012:对所述文字串进行分词处理,以获得至少一个分词;步骤S5013:将所述分词与预设多音字表进行匹配以判断分词是否包含多音字,若包含多音字,则将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述预设多音字词语表为包含多音字的词语与多音字在该词语中的读音之间的对应关系表;该步骤S5013如果在分词与预设多音字表匹配后判断出分词的文字不是多音字时,则可通过查找哈希表或GBK编码表方式获得分词文字的拼音。步骤S5014:获得分词的拼音后,提取分词的拼音或拼音首字母。通过上述的任何一种方式获取拼音或拼音首字母后,进入后续步骤。步骤S502:以所述拼音或拼音首字母为索引查找拼音数据库,所述拼音数据库是以分词的拼音或拼音首字母为索引,将具有相同拼音或拼音首字母的分词作为一个索引单位进行数据组织,且当所述分词为包含多音字的分词时,该分词中的多音字在该分词中的拼音是通过与预设的多音字词语表进行匹配得到,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表;搜索引擎接收到拼音或拼音首字母后,以该拼音或拼音首字母为索引查找拼音数据库,这里的拼音数据库为按照前述基于文字拼音的数据组织方法组织的数据库。步骤S503:将查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索获得检索结果。本申请基于文字拼音的检索方法与装置的实施例以获取的拼音为拼音首字母为索引查找拼音数据库,将查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索获得检索结果。与现有技术相比,由于拼音数据库的组织考虑了文字的多音字现象以及多音字在不同语境下的不同拼音问题,从而使得依据拼音对应的关键词进行检索后获取的检索结果准确率更高。上述检索实施例中步骤S503如果查找到具有相同拼音或拼音首字母的分词包含多个时,为了减少检索工作量和增加检索结果与用户需求的一致性,本申请优选在这种情况下,提示用户进行选择,将用户选择的分词作为关键词进行检索获取检索结果。提示用户进行选择可弹出对话框,列出检索到的具有相同拼音或拼音首字母的分词的编号,通过选择编号确认分词,然后利用该分词进行检索获取检索结果。上述叙述内容均是对本申请方法实施例的描述,相应地,本申请实施例还提供了一种获取多音字拼音的装置和基于文字拼音的检索装置。参见附图7,该图示出了本申请获取多音字拼音的装置结构。该装置实施例700包括:第一获取单元701、切分单元702、第一匹配单元703和第二匹配单元704,其中:所述第一获取单元701,用于获取文字串;所述切分单元702,用于对所述文字串进行分词处理,以获得至少一个分词;所述第一匹配单元703,用于将分词与预设多音字表进行匹配,以判断分词是否包含多音字,若包含多音字,则触发第二匹配单元704;所述第二匹配单元704,用于将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述预设多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表;本装置实施例700的工作过程是:第一获取单元701获取文字串后,通过切分单元702对所述文字串进行分词处理,以获得至少一个分词;第一匹配单元703将分词与预设多音字表进行匹配以判断分词是否包含多音字,若是,则触发第二匹配单元704,由第二匹配单元704将该分词与预设多音字词语表进行匹配以获得多音字的拼音,所述预设多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表。本申请获取多音字拼音的装置实施例对文字串切分的分词进行多音字判断,将多音字与预设多音字词语表进行匹配,从而确定多音字在不同语境下的正确拼音。与现有技术相比,本装置实施例由于根据每个多音字所在的语境确定其准确的拼音,从而提高了获取多音字正确拼音的概率。上述装置实施例700中还可以包括第二获取单元705和添加单元706,其中:第二获取单元705,用于在所述多音字的分词中包含非多音字时,获取所述分词中每个非多音字的拼音,将所述分词中的非多音字的拼音和多音字的拼音组合为所述分词对应的拼音;添加单元706,用于以所述分词的拼音或拼音的首字母为索引,将所述分词添加到拼音数据库中。通过增加上述两个单元后,由于获得的多音字具有多个拼音,不再是一个默认拼音,从而增加了具有相同拼音的词组、短语或句子的数量,扩展了基于文字拼音进行数据组织的数据库的信息容量,避免了包含多音字的分词由于拼音错误放入错误的拼音索引之下,从而也增加了数据库内数据的正确率。上述装置实施例700的第一匹配单元703将分词与预设多音字表进行匹配以判断分词是否包含多音字,具体包括:将所述分词中的每个汉字分别与所述预设多音字表进行匹配,若所述分词中包含所述预设多音字表中的汉字,则确定所述分词包含多音字。上述装置实施例700的第二获取单元705,具体用于:通过查找GBK编码表,获得所述分词中的每个非多音字的拼音。上述装置实施例700中的预设多音字表可以包含多音字的默认音,这种情况下,第二匹配单元704进一步用于,若从预设多音字词语表中未获得所述分词中的多音字的拼音,从所述预设多音字表中获取所述分词中多音字对应的默认音,将所述默认音作为所述分词中的多音字的拼音。通过该方式可以减少多音字词语表的容量,从而加快匹配速率,从整体上提高获取多音字拼音的效率。第二匹配单元704还可以包括:第一确定子单元,第二确定子单元、匹配子单元和第三确定子单元,其中:所述第一确定子单元,用于确定所述分词中的多音字在该分词中的位置;所述第二确定子单元,用于从所述多音字词语表中确定出至少一个预选分词,所述预选分词包含所述分词中的多音字,且该多音字在所述预选分词中的位置与该多音字在所述分词中的位置相同;所述匹配子单元,用于将所述分词与确定出的预选分词进行匹配,若匹配成功,则触发第三确定子单元;所述第三确定子单元,用于从所述多音字词语表中,获取与所述分词匹配的预选分词中的多音字的拼音,将所述预选分词的多音字的拼音,确定为所述分词中的相应多音字的拼音。通过这种结构的第二匹配单元,可进一步减少匹配的工作量,提高匹配效率。参见附图8,该示出了本申请的基于文字拼音的检索装置实施例的结构。该检索装置实施例800包括:第三获取单元801、查找单元802和检索单元803,其中:所述第三获取单元801,用于获取拼音或拼音首字母;所述查找单元802,用于以所述第三获取单元801获得的拼音或拼音首字母为索引查找拼音数据库,所述拼音数据库是以分词的拼音或拼音首字母为索引,将具有相同拼音或拼音首字母的分词作为一个索引单位进行数据组织,且当所述分词为包含多音字的分词时,该分词中的多音字在该分词中的拼音是通过与预设的多音字词语表进行匹配得到,所述多音字词语表为包含多音字的词语与多音字在该词语中的拼音之间的对应关系表;所述检索单元803,用于将所述查找单元802查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索,获得检索结果。本检索装置实施例800的工作过程是:第三获取单元801获取拼音或拼音首字母后,由查找单元802以所述拼音或拼音首字母为索引查找拼音数据库;检索单元803将查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索获得检索结果。本申请基于文字拼音的检索装置的实施例以获取的拼音为拼音首字母为索引查找拼音数据库,将查找到的具有相同拼音或拼音首字母的分词作为关键词进行检索获得检索结果。与现有技术相比,由于拼音数据库的组织考虑了文字的多音字现象以及多音字在不同语境下的不同拼音问题,从而使得依据拼音对应的关键词进行检索后获取的检索结果准确率更高。上述检索装置实施例的第三获取单元801可直接接收用户输入的拼音或拼音首字母,也可将用户输入的文字转换为拼音或拼音首字母。在后一种情况下,第三获取单元801可以包括:接收子单元8011、切分子单元8012、第一匹配子单元8013、第二匹配子单元8014和提取子单元8015,其中:接收子单元8011,用于接收用户输入的文字串;切分子单元8012,用于对所述文字串进行分词处理,以获得至少一个分词;第一匹配子单元8013,用于将分词与预设多音字表进行匹配以判断分词是否包含多音字,如果包含多音字,则触发第二匹配子单元8014;第二匹配子单元8014,用于将该分词与预设多音字词语表进行匹配,以获得多音字在该分词中的拼音,所述多音字词语表为包含多音字的词语与多音字在该词语中的读音之间的对应关系表;提取子单元8015,用于在获取分词的拼音后,提取分词的拼音或拼音首字母。该检索装置实施例的第一匹配子单元8013在分词与预设多音字表匹配后判断出分词不包含多音字时,可以通过查找哈希表或GBK编码表方式获得分词文字的拼音。上述检索装置实施例800还可以包括提示单元804,用于在查找到的具有相同拼音或拼音首字母的分词包含多个时,提示用户进行选择。这种情况下,检索单元803将用户选择的分词作为关键词进行检索获取检索结果。通过该方式减少了检索工作量和增加了检索结果与用户需求的一致性,从而改善了基于文字拼音的检索装置的性能。为了描述的方便,描述以上装置时以功能分为各种单元分别描述。当然,在实施本申请时可以把各单元的功能在同一个或多个软件和/或硬件中实现。通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例或者实施例的某些部分所述的方法。本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的系统实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。本申请可用于众多通用或专用的计算系统环境或配置中。例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络PC、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。本申请可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本申请,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。以上所述仅是本申请的具体实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本申请的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1