一种文档主题的在线追踪方法与流程
本发明属于计算机领域,具体涉及一种文档主题的在线追踪方法。
背景技术:
随着信息技术的快速发展和学术研究的蓬勃发展,我们所能获取的学术论文也在不断地增长。而如何从海量的数据中获取有效信息,这就需要进行主题追踪。例如,若想获取近年来关于贝叶斯网络的研究进展,我们首先可以针对贝叶斯网络这一主题搜索相关的论文;其次,可以对所获取论文的主要作者及其同实验室研究者所发表的论文进行追踪,进而可以全面地了解贝叶斯网络的研究过程。目前,大部分的主题追踪都采用离线算法,而离线算法相当于在生产过程中,把一个产品的各个零部件凑齐后再进行组装,而这在训练海量数据时就会面临内存不足和数据集不能完整获取的问题。因此,如果可以动态追踪主题,并实时给出当前最热冷门主题,将会给搜索引擎提供更准确的搜索。上述的这个例子属于机器学习中的概念,而完成这项工作的基础即为在线主题追踪技术。在线消息传递算法是从马尔科夫模型的角度将传统的概率图表示转化成因子图,具备概念清晰,速度快,精度高等优点。目前在众多领域都已经提出了在线学习算法。机器学习和统计学领域的很多问题都涉及到矩阵运算,如:近邻算法和聚类算法中的K均值算法等,而目前的研究大多是在不高效而且没有理论保证的离线算法基础上,所以Shwartz等提出采用在线学习算法处理大规模矩阵;在训练数据集能提前获取的情况下,基于核函数的算法,如:支持向量机(supportvectormachine,SVM)算法,已有相应的文献提出其在处理各种问题上都已经取得了很大的成就,但是这些算法几乎无法应用到实时数据中,所以Kivinen等基于SVM的核函数提出在线学习算法;尽管统计学习在近年来取得了很大的成功,但是高维输入数据的非线性函数逼近仍然是个棘手的问题,特别是在增长式和实时的情形下局部加权投影回归(Locallyweightedprojectionregression,LWPR)在高维冗余和不相关的输入维数空间中,Vijayakumar等提出一种新的增量非线性函数逼近算法,即在线非线性函数逼近算法处理高维数据集;采用学习好的分类器进行目标检测已经成功地应用到了很多困难的任务中,如:人脸和行人检测,使用这种方法的系统通常在学习分类器时是采用离线学习算法为训练数据手动贴上标签,Pham等提出一种在线学习框架并且自动为视频中运动物体贴标签,因为在线学习的过程中没有手动的帮助,这样也能同步进行检测和自适应分类,Mairal等也提出一种提高分类器的目标检测准确性的在线学习算法;稀疏编码广泛应用于机器学习、神经科学、信号处理和统计学,有相应的文献对大规模矩阵分解、信号处理中的字典学习、非负矩阵分解和稀疏主成分分析等一系列的问题提出了一种新颖的基于随机近似的在线优化算法,扩展到数以百万计的大型训练样本,并自然延伸到各种矩阵因子分解,使其成为一种广泛适用的学习算法。所谓主题,即作者通过文章的全部材料和表现形式所表达出的基本思想,也称为“主题思想”。而主题追踪是机器学习中的一个基本概念,它是在给定的主题下,根据文档的内容自动判别文档归属的主题,监控新主题的报道,并将涉及到某个主题的文档组织起来。从上述的例子可知,搜索引擎等为用户提供更加准确的搜索结果主要就是依赖于对数据流的主题追踪,所以对数据流进行有效的主题追踪是重要的基础性工作,因此主题追踪是机器学习中最为基础和关键的研究内容之一。目前主题追踪系统已经广泛应用到多领域。如:在近邻算法(K-NearestNeighboralgorithm,KNN)和支持向量机(Supportvectormachine,SVM)中研究主题追踪系统,主要是研究主题追踪系统中特征维和k近邻值如何影响主题追踪;基于朴素贝叶斯算法研究主题追踪,文档分类是主题追踪的关键技术,贝叶斯算法是一种简单有效的文档分类模型,所以发明中用向量空间模型作为研究主题追踪系统的预处理模型,通过实验表明朴素贝叶斯文档分类是有效解决主题追踪问题的关键技术;在主题追踪中,主题模型对主题追踪的准确性有很大的影响,主题追踪的特征也就是主题在初始化时包含的信息非常少,但是主题又是在不断地动态变化,这就导致初始化的主题模型不能准确的表达主题,所以本发明中提出一种基于反馈信息的自适应主题追踪方法;在主题模型领域,目前已经提出相应的在线学习算法进行主题追踪,用在线学习算法不断追踪主题的变化,并且实时检测新出现的主题。主题模型中,传统的离线算法是相当于把一个产品的各个零部件凑齐后再进行组装,即:收集大量数据后统一处理,但是主题追踪面临的实际数据集一般都比较巨大,如何有效的对数据进行切分以解决内存不足的问题,以及如何有效的利用已经取得的训练结果亟待研究。尽管目前国内外的众多学者已经提出了很多新颖的方法,但是算法往往具有很强的针对性和局限性,而且准确性和速度依然有待提高。
技术实现要素:
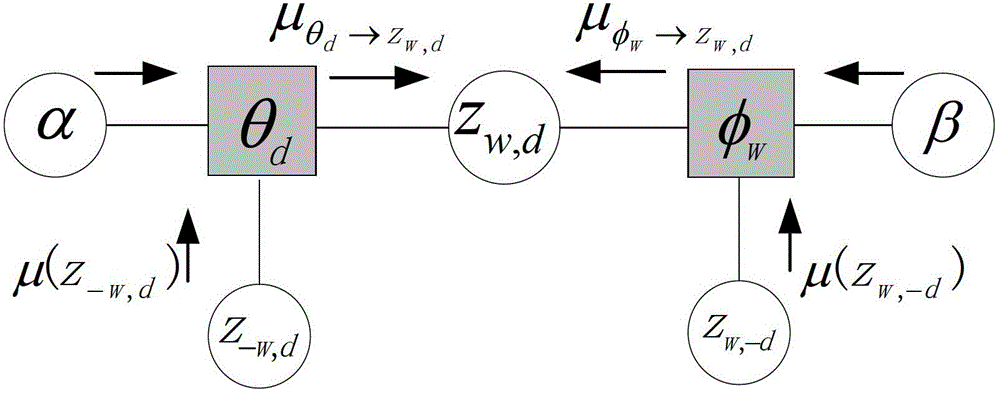
本发明目的是:提供一种以海量数据和流数据为处理对象,基于概率潜在语义分析(PLSA)模型和潜在狄利克雷分布(LDA)模型提出更高效的文档主题的在线追踪方法,采用在线学习算法训练模型的精度和速度都很高,有效的解决了主题模型训练中的一些不足,在海量数据和数据流中表现出较好的鲁棒性。本发明的技术方案是:一种文档主题的在线追踪方法,其特征在于,包括以下步骤:(1)对数据进行预处理,将数据切分成若干独立段,然后逐段训练;(2)对数据在主题模型上采用在线学习算法进行训练,其中每段的训练均权重取决于已经训练得到的结果;(3)对每段训练得到的结果进行主题演变计算,对相应的主题进行追踪。针对当前所面临的海量数据和流数据,离线算法会因为内存不足和数据集不能完整获取而无法解决文档分类的问题,因此本发明提出的在线学习算法首先对海量数据进行切分,然后对切分后的若干独立段逐个训练,并且采用前段的结果参数计算当前数据段的梯度下降。优选的,所述在线学习算法为基于概率潜在语义分析(PLSA)模型和潜在狄利克雷分布(LDA)模型的在线学习算法。目前,主题追踪主要有两类方法:基于概率潜在语义分析(Probabilisticlatentsemanticanalysis,PLSA)模型的在线期望最大化(OnlineExpectationMaximization,OEM)算法,基于潜在狄利克雷(LatentDirichletallocation,LDA)模型的在线吉布斯采样(OnlineGibbssampling,OGS)算法和在线变分贝叶斯(OnlinevariationalBayes,OVB)算法,以及众多基于LDA的变形模型的在线学习算法。OEM算法是基于期望最大化(ExpectationMaximization,EM)算法,而OGS和OVB算法分别是基于吉布斯采样(Gibbssampling,GS)算法和变分贝叶斯(variationalBayes,OVB)算法。OEM算法简单稳定,但实质上只是一个优化算法,而且通常收敛速度很慢;OGS算法收敛很慢,实际中通常需要对文档-词汇共现矩阵扫描500-1000次才会收敛,而且OGS算法需要对每一个单词元进行扫描,如果语料库中每篇文档的单词元过多,就导致扫描的时间成本很大,所以无法满足海量数据的处理;OVB算法是通过一个近似的下界函数来逼近要求解的真实后验概率函数,但是OVB算法的下界函数和真实的目标之间会存在误差,所以在收敛情况下精度不如OGS算法,而且在实际实验中,OVB算法引入了较为复杂的digamma函数运算,使得计算效率大大下降,在某些情况下速度甚至低于OGS算法。本发明中优选了基于概率潜在语义分析(PLSA)模型和潜在狄利克雷分布(LDA)模型的在线学习算法。优选的,所述基于概率潜在语义分析(PLSA)模型的在线学习算法为基于概率潜在语义分析(PLSA)模型改进因子图表示的在线消息传递(OBP)算法。PLSA模型是一种简单的文档分类方法,然而针对海量数据和流数据,PLSA模型无法继续采用传统的离线算法解决文档分类的问题,虽然现在已经提出相应的在线学习算法,但是仍然不能满足快速和准确的要求,所以提出基于PLSA模型改进因子图表示的OBP算法。优选的,所述基于潜在狄利克雷分布(LDA)模型的在线学习算法为基于潜在狄利克雷分布(LDA)模型改进因子图表示的在线消息传递(OBP)算法。针对PLSA模型在处理海量数据时,模型中参数的个数随文档数和单词数呈线性增长,从而导致PLSA模型的在线学习算法在处理海量数据时非常复杂这一问题,因此提出了基于LDA模型改进因子图表示的OBP算法。优选的,所述步骤(3)具体为:对流数据的不断训练,给出当前最热冷门主题,并更准确地计算各个主题的变化趋势。本发明的优点是:本发明针对主题追踪现存在的难点问题,以海量数据和流数据为研究对象,基于概率潜在语义分析(PLSA)模型和潜在狄利克雷分布(LDA)模型提出更高效的在线学习算法。在线学习算法就等于是流水线上来一个零件我们就组装一个,整个过程非常高效,不必等待全部的零部件聚齐后再组装。采用在线学习算法训练模型的精度和速度都很高,有效的解决了主题模型训练中的一些不足,在海量数据和数据流中表现出较好的鲁棒性。附图说明下面结合附图及实施例对本发明作进一步描述:图1为LDA模型的概率图表示;图2为LDA模型的因子图;图3为LDA模型在线学习算法的流程图;图4为各主题下预测混淆度的对比图(a)blog;(b)enron;(c)nytimes和(d)pubmed;图5为各主题下训练耗时的对比图(a)blog;(b)enron;(c)nytimes和(d)pubmed;图6为enron数据集在OBP与OEM算法的混淆度对比;图7为enron数据集在OBP算法上前25个主题的追踪过程;图8为enron数据集在OBP算法上后25个主题的追踪过程;图9为nytimes数据集在OBP与OGS及OVB算法的混淆度对比;图10为nytimes数据集在OBP算法上前25个主题追踪过程;图11为nytimes数据集在OBP算法上后25个主题的追踪过程。具体实施方式实施例1:主题追踪技术包括模型建立、模型训练和模型预测三个步骤。在此过程中,首先是模型的建立,即将LDA模型传统的概率图表示转化成因子图表示。图1所示为LDA模型的概率图,图1的这种图模型表示法也称作“盘子表示法”,图中的阴影圆圈表示可观测变量,非阴影圆圈表示潜在变量,箭头表示两变量间的条件依赖性,方框表示重复抽样,重复次数在方框的右下角。LDA模型是一个三级层次贝叶斯模型,其中wn和zn是单词层变量,分别代表单词和主题,1≤wn≤W是可观测变量,zn=k,1≤k≤K是隐藏主题变量,主题定义为单词表中所有单词上的概率分布;θd和φk是文档层变量,分别表示指定文档所对应的主题分布和指定主题所对应的单词概率分布;α和β是语料库层的超级参数,用于控制文档层的θd和φk变量。图中D表示语料库中总文档数,N表示每篇文档平均包含的单词数,W表示单词表中单词总个数,K表示总主题的个数。图2给出的是LDA模型的因子图表示。将主题模型视为贴标签问题,即目标是为单词表中的所有单词索引W={w,d}赋予语义标签Z={zw,d}。在无向概率图模型中,马尔科夫模型通过邻居系统和团势函数解决标签问题,已经广泛应用于图像分析和计算机视觉。在主题模型中,马尔科夫模型根据最大化后验估计,通过最大化后验概率来指派最佳主题标签。从马尔科夫的角度看,发明中将LDA模型的概率图表示转换为等价的因子图表示。首先定义主题标签zw,d的邻居为z-w,d和zw,-d,其中标签z-w,d表示文档d中除单词w外的所有单词索引的主题标签,zw,-d表示单词w在除文档d外的所有文档的主题标签;然后设置合适的惩罚函数或者团势函数对邻居系统中不同的局部标签惩罚或奖励以实现主题模型的三个本质假设:1)相同文档中的不同单词索引倾向于赋予相同的主题标签;2)不同文档中相同的单词索引也倾向于赋予相同的主题标签;3)单词表中所有的单词不能赋予相同的主题标签。LDA模型中消息传递算法并不是直接计算后验分布p(z|w),而是计算边缘概率p(zw,d),也称为消息μ(zw,d)。根据图2消息μ(zw,d)等于其从邻居因子获取的消息之积,即:μ(zw,d)∝μθd→zw,d(zw,d)×μφw→zw,d(zw,d)---(1)]]>图2中的箭头表示消息之间传递的方向。为了方便,下文均使用如下标记:μ(zw‾,d)=Σv≠wμ(zv,d),]]>μ(z·,d)=∑wμ(zw,d),μ(zw,d‾)=Σs≠dμ(zw,s),]]>μ(zw,·)=∑dμ(zw,d)。图中从因子传递给变量的消息是将所有邻居变量传入的消息进行叠加,并乘以相应的团势函数,即:μθd→zw,d(zw,d)∝fdμ(zw‾,d=k)---(2)]]>μφw→zw,d(zw,d)∝fwμ(zw,d‾=k)---(3)]]>在马尔科夫模型中,我们通常是基于自身的先验知识对局部主题标签设置相应的因子函数。基于主题平滑先验假设,本发明对LDA模型的团势函数定义如下:fd=1Σk[μ(zw‾,d=k)+α]---(4)]]>fw=1Σw[μ(zw,d‾=k)+β]---(5)]]>等式(4)将传入的消息在文档d上对所有主题的消息进行归一化,使得各个文档之间具有可比性,等式(5)对传入的消息在单词表中对所有单词进行归一化,以使得单词之间具有可比性。为了简化,下发明中简记Σzw,d=kμ(zw,d=k)=Σkμ(zw,d=k).]]>结合等式(1)到等式(5),消息更新等式为:μ(zw,d=k)∝μ(zw‾,d=k)+αΣkμ(zw‾,d=k)+α×μ(zw,d‾=k)+βΣwμ(zw,d‾=k)+β---(6)]]>对于更新后的消息还需要在主题维上进行归一化处理,即满足等式∑kμ(zw,d=k)=1。然后固定更新后的消息参数μ(zw,d),采用等式(7)和等式(8)分别更新参数θd和φw,直到达到最大循环次数:θd∝μ(z·,d=k)+αΣkμ(z·,d=k)+α---(7)]]>φw∝μ(zw,·=k)+βΣwμ(zw,·=k)+β---(8)]]>本发明提出了在线消息传递(OnlineBeliefPropagation,OBP)算法,该算法的主要思想如图3所示。OBP算法将整个数据集切分成一系列的小数据段,对于第一段数据集,OBP算法的具体训练方式和离线BP算法相同,训练结束后保存当前段的结果参数φ;从第二段到最后一段数据集,OBP算法直接采用前一段的训练结果参数φ,然后用梯度下降法计算当前段的消息。对于每一段的参数φ,发明中是在OBP算法收敛或者达到最大迭代次数时才更新。根据在线随机优化理论,本发明为当前段以及已训练段分别设置权重为ρt=(τ0+t)-κ和1-ρt,其中参数κ∈(0.5,1]用于控制已经处理过的数据集,常数τ0≥0用于减小每段开始迭代时的影响,变量t表示当前训练数据所处的段数。图3中M表示海量数据集被分成的总段数,其中当M=1且κ=0时,在线消息传递算法即转化为离线消息传递算法。在训练的过程中,发明中首先在0与1之间随机初始化第一段的参数φw(k),μw,d和θd(k),并且进行归一化处理,确保满足∑kμ(zw,d=k)=1,训练结束后保存参数φw(k)。从第二段到最后一段,OBP算法只需要初始化当前段的θd(k)参数,前一段的训练结果参数φw(k),更新消息直到收敛。在该算法中可以根据参数θd(k)在相邻迭代之间的差值来判断当前段是否收敛,也可以采用等价的参数μw,d在相邻迭代之间的差值来判断是否收敛。因为在更新参数μw,d时,参数φw(k)是固定的,所以只有μw,d和θd(k)之间是互相影响的。此处简记μ(zw,d=k)=μw,d(k)。基于收敛后的消息,估计参数φw(k)new∝(μw,·(k)+β)∑w(μw,·(k)+β)。而对于训练的结果参数φw(k)是取当前段和已训练段的权重和:φw(k)=(1-ρt)φw(k)+ρtφw(k)new。LDA模型的目标是在给定文档数据集w=(w1,…,wN)的条件下,推断出文档对应的主题分布θ,主题对应单词表的概率分布φ,和单词所属隐藏主题变量z=(z1,…,zN)的分布。本小节将证明在线消息传递算法:LDA模型的OBP算法能收敛到一个稳定值。首先给出LDA模型的目标函数:L(w,φ,θ,μ)=Πdp(θd|α)Πkp(φk|β)Πwp(μw,d|θd)p(wd,w|μd,w,φk)]]>∝Σd[logp(θd|α)+Σklogp(θk|β)+]]>+Σw(logp(μw,d|θd)+logp(wd,w|μd,w,φk))]]]>=Σd(logΓθd,k-logΓ(Σkθd,k)+Σk(α-θd,k)logθd,kΣkθd,k)+]]>Σk(logΓφk,w-logΓ(Σwφk,w)+Σw(β-φk,w)logφk,wΣwφk,w)/D+]]>Σwnd,wΣkμd,w,k(logθd,kΣkθd,k+logφk,wΣwφk,w)]]>=Σdl(nd,μd,θd,φ)---(9)]]>计算的过程中采用μ(nd,φ)代表μd参数,θ(nd,φ)代表θd参数,因此LDA模型的目标是估计参数φ以最大化L:L(n,φ)=∑dl(nd,μ(nd,φ),θ(nd,φ),φ)。此处利用随机自然梯度下降法来分析在线算法的收敛性,随机最优算法使用梯度估计来最优化目标函数。首先定义函数s(n)用于不断采样文档,其中当n=nd时,Ι(n=nd)=1,否则Ι(n=nd)=0。所以可以将目标似然函数改写成:L(s,φ)=DEs[l(n,μ(n,φ),θ(n,φ),φ)|φ](10)其中l被定义于等式(9)中。在φ参数固定的条件下最大化等式(10),即通过nt~s分布不断地抽取观测样本,其中μt=μ(nt,φ),θt=θ(nt,φ),对φ参数采用以下的更新方式:φ←φ+ρtD▿φl(nt,μt,θt,φ)---(11)]]>其中权重采用算法中的计算公式ρt=(τ0+t)-κ。对于每一篇文挡nt首先固定参数φ,而将μt和θt参数同时作为随机变量,此时等式(10)转变为Es[D▿φl(nt,μt,θt,φ)|φ]=▿φΣdl(nd,μd,θd,φ).]]>根据相关文献,当参数ρt满足Σt=0∞ρt=∞]]>和Σt=0∞ρt2∞]]>时,参数φ收敛,并且梯度▿φΣdl(nd,μd,θd,φ)]]>会收敛到0,因此φ会收敛到某个稳定的值。在上面的推理中,等式(11)只应用了一阶梯度。根据相关文献,若对梯度乘以一个合适的正定矩阵H的逆,可以使得随机梯度算法加速。对正定矩阵H的选择通常是取目标函数的哈森矩阵。∂l(nt,μt,θt,φ)∂φk,w=Σv=1w∂log(φk,vΣvφk,v)∂φk,w(-φk,w/D+β/D+nt,vμt,v,k)]]>=Σv=1w-∂2logφk∂φk,v∂φk,w(-φk,w/D+β/D+nt,vμt,v,k)---(12)]]>(-∂2logφk∂φk,v∂φk,w)-1∂l(nt,μt,θt,φ)∂φk,w=-φk,w/D+β/D+nt,vμt,v,k---(13)]]>对等式(13)乘以ρtD再加上φ,便得到参数φ的更新等式。图4和图5分别给出了LDA模型上的OBP算法与OGS和OVB算法在训练时的混淆度和训练消耗时间的对比结果。实施例2:在PLSA模型上进行主题追踪。首先通过实验对比PLSA模型下的OBP算法和OEM算法在训练数据流数据时预测测试集的准确性。图6给出了在enron数据集上,OBP算法和OEM算法对测试数据集的预测混淆度对比分析结果。从中可看出OEM算法在训练的过程中收敛的速度相对缓慢,而OBP算法在训练文档数越多时混淆度降低地越迅速,收敛速度也越快,因此从这个实验我们可以看出OBP算法显著优越于OEM算法。PLSA模型在处理数据流数据时,每个主题会随着不断流入的训练样本集而变化。图7和图8给出了在PLSA模型上采用OBP算法训练数据流数据时,对应50个主题的演变追踪趋势。根据图7和图8可以看出,每个主题对应的概率值都会随训练数据集的增加而不断变化,例如:图7中的第一个主题随训练文档数的增多,其对应的概率值不断变大,这表明该主题在此数据集下得到的关注度正在持续上升;图7的第二个主题对应的概率值随训练文档数的增加却在不断变小,表明该主题在此数据集下被研究的热度正在不断下降;图7的第七个主题随训练文档数的增加,概率值变化相对缓慢,表明该主题被关注的程度几乎不变。在每个主题演变图的右侧标出的是属于该主题概率较大的部分单词,从中可看出每个主题下包含的单词之间意思几乎相近,而且还可以根据这些单词推断出当前的主题。实施例2:在LDA模型上进行主题追踪。首先通过实验对比LDA模型下的OBP和OGS,OVB算法在训练数据流数据时预测测试集的准确性。从图9中可看出,OGS和OVB算法在整个训练过程中,任何时刻对应的混淆度值均大于OBP算法,而且最终的收敛混淆度值也是远大于OBP算法,这说明在相同训练样本集的条件下,OGS和OVB算法对未知测试集的预测能力都比OBP算法差。此外,OBP算法在随训练样本数不断增加时,混淆度值降低地越迅速,表明模型的收敛速度越快。采用LDA模型在处理数据流数据时,每个主题会随着不断流入的训练样本集数据而变化。根据图10和图11可以看出,主题随训练数据集的增加而不断变化,例如,根据图10中的第一个主题演变图,其概率值随训练文档的增多而不断变大,表明该主题得到的关注度正在持续上升;图10的第十三个主题对应的概率值随训练文档的增加却不断变小,表明该主题被研究的热度不断下降;图10的第九个主题随训练文档的增加,概率值变化比较缓慢,表明该主题被关注的程度几乎保持不变。在每个主题演变图的右侧标出了属于该主题概率较大的部分单词,从中可看出每个主题下包含的单词之间意思几乎相近,而且还可以根据这些单词推断出当前的主题。实施例3:PLSA模型的OBP算法的具体实现如下所示。算法:PLSA模型的OBP算法输入:p(w|z),p(z|d)输出:p(w|z),p(z|d)定义ρt=(τ0+t)-κ随机初始化第一段参数p(w|z)Fort=0to∞do初始化当前段p(z|d)Repeatμw,dt+1(k)∝μ-w,dt(k)Σkμ-w,dt(k)×μw,-dt(k)Σwμw,-dt(k)]]>p(z=k|d)t+1∝μ·,dt+1(k)/Σkμ·,dt+1(k)]]>until1kΣk|changeinp(z|d)|0.00001]]>计算当前段训练得到的p(w|z=k)new∝μw,·(k)/Σwμw,·(k)p(w|z=k)=(1-ρt)p(w|z=k)+ρtp(w|z=k)new。endfor在训练每段数据后,保存其中的参数p(w|z),获取每个主题对应单词表中的概率最大值及其对应的单词,然后将所有数据段的结果相连接。给出当前最热冷门主题,并更准确地计算各个主题的变化趋势。本实施例的基于PLSA模型改进因子图表示的OBP算法能够快速准确的解决文档分类的问题。本发明解决了传统离线算法中的存在的内存不足和数据不能完整获取等问题,提高主题追踪的精度和速度,使其达到智能化的要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1