基于贝叶斯模型的文本垃圾识别方法和系统与流程
本发明涉及互联网领域,尤其涉及一种基于贝叶斯模型的文本垃圾识别方法和系统。
背景技术:
互联网技术迅猛发展,网上信息爆炸式增长;随着生活、工作节奏的加快,人们越来越倾向于用简短的文字来沟通交流。以twitter(推特)和新浪微博为代表的以较小的文本来生产、组织和传播信息的SNS(SocialNetworkService,社会性网络服务)网站,获得网友的青睐。目前,对互联网上的文本内容进行自动垃圾识别的主要方法是,采用基于向量模型的方法,对于某个文本内容将其分类为垃圾文本,或非垃圾文本;该方法包括:训练阶段和识别阶段。在训练阶段,根据训练集中大量的文本进行建模的方法,通常如图1所示,包括如下步骤:S101:对于训练集中已区分为垃圾文本,或非垃圾文本的各个文本,进行分词得到每个文本的词语集合。S102:根据每个文本的词语集合计算得到每个文本的词语特征向量。具体地,针对每个文本,根据该文本的词语集合中的每个词语,确定该词语在该文本中的TF(TermFrequency,词频)值,计算该词语在训练集中的IDF(InverseDocumentFrequency,逆向文件频率)值,根据该词语的TF值和IDF值,如下公式1计算该词语的特征值:log(TF+1.0)×IDF(公式1)将该文本的词语集合中各词语的特征值组成该文本的词语特征向量。S103:基于训练集中每个文本的词语特征向量建立向量模型。例如,根据训练集中每个文本的词语特征向量,运用SVM分类算法、或最大熵分类算法等建立向量模型。在识别阶段,对于待判定文本,进行分词得到该待判定文本的词语集合后,根据该待判定文本的词语集合计算出该待判定文本的词语特征向量;根据待判定文本的词语特征向量与训练阶段建立的向量模型来判断待判定文本是否为垃圾文本。但是,在实际应用中,本发明的发明人发现,运用现有技术的建模和文本内容的垃圾识别方法的系统,鲁棒性较差,容易受到攻击:例如,在训练阶段,训练集中某个文本中若大量出现某个关键词,则会出现分类结果被该关键词绑架的情况,导致分类结果中划分的垃圾文本超平面、或非垃圾文本超平面因该关键词的干扰而有较大偏离;因此,有必要提供一种具有更好鲁棒性的建模和文本内容的垃圾识别的方法和系统。
技术实现要素:
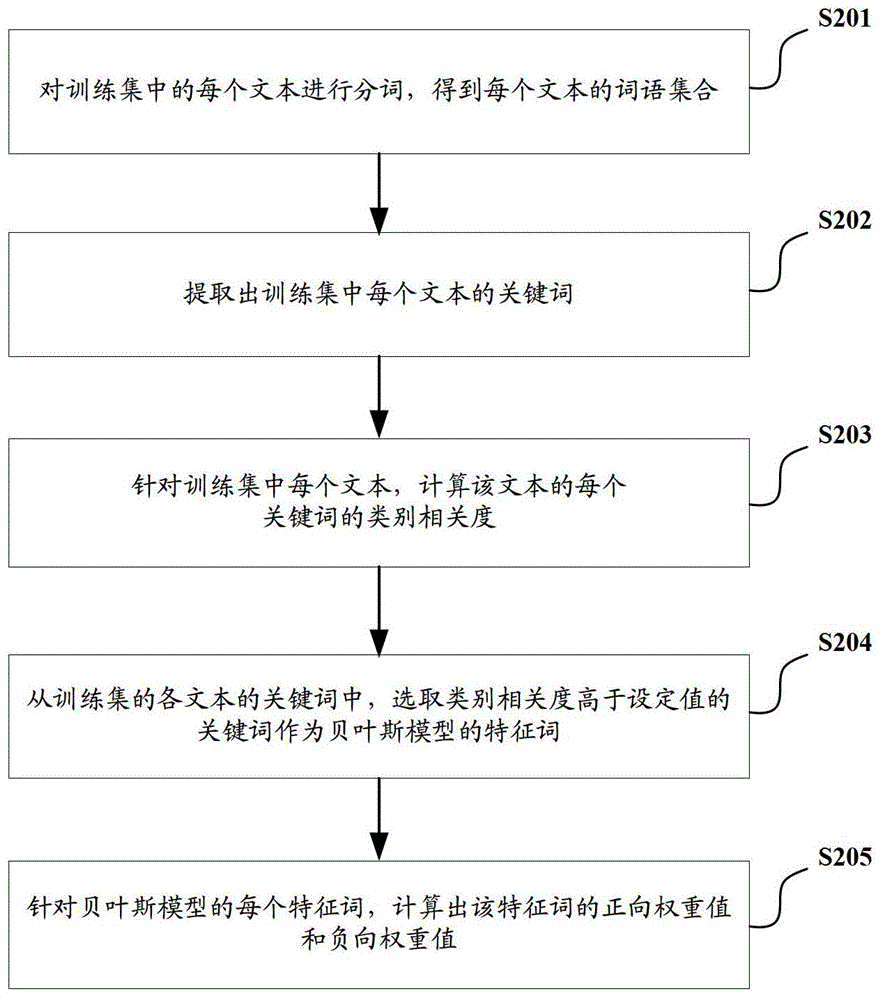
针对上述现有技术存在的缺陷,本发明提供了一种基于贝叶斯模型的文本垃圾识别方法和系统,用以提高文本垃圾识别系统的鲁棒性。根据本发明的一个方面,提供了一种基于贝叶斯模型的文本垃圾识别方法,包括:对待判定文本进行分词,得到所述待判定文本的关键词;针对所述待判定文本的每个关键词,计算该关键词的特征值,并在贝叶斯模型中查找与该关键词相匹配的特征词,获取查找到的特征词的正向权重值和负向权重值,分别作为该关键词的正向权重值和负向权重值;其中,所述特征词的正、负向权重值分别指的是所述特征词属于非垃圾文本、垃圾文本的概率权重值;根据所述待判定文本的每个关键词的特征值以及正向权重值,计算所述待判定文本的正向分类值;根据所述待判定文本的每个关键词的特征值以及负向权重值,计算所述待判定文本的负向分类值;其中,所述待判定文本的正、负向分类值分别指的是所述待判定文本为非垃圾文本、垃圾文本的概率权重值;根据所述待判定文本的正向分类值和负向分类值,确定所述待判定文本是否为垃圾文本。其中,所述贝叶斯模型为预先得到的:对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词,并计算该文本的每个关键词的类别相关度;从所述训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为所述贝叶斯模型的特征词;针对所述贝叶斯模型的每个特征词,根据该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值;其中,numg为所述训练集的非垃圾文本中包含有该特征词的文本的数量;numb为所述训练集的垃圾文本中包含有该特征词的文本的数量。较佳地,所述计算该文本的每个关键词的类别相关度具体包括:对于该文本的每个关键词,根据如下公式2计算该关键词的类别相关度:(公式2)其中,T表示该关键词,CE(T)表示该关键词的类别相关度,P(C1|T)表示包含该关键词的文本属于垃圾文本类别的概率,P(C2|T)表示包含该关键词的文本属于非垃圾文本类别的概率,P(C1)表示垃圾文本在所述训练集中出现的概率,P(C2)表示非垃圾文本在所述训练集中出现的概率。较佳地,所述根据该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值,具体包括:根据如下公式3计算出该特征词的正向权重值weightg:(公式3)根据如下公式4计算出该特征词的负向权重值weightb:(公式4)其中,word_numg表示所述训练集的非垃圾文本中包含有该特征词的文本的数量;word_numb表示所述训练集的垃圾文本中包含有该特征词的文本的数量;total_numg表示所述训练集中非垃圾文本总数;total_numb表示所述训练集中垃圾文本总数。较佳地,所述根据所述待判定文本的每个关键词的特征值以及正向权重值,计算所述待判定文本的正向分类值;根据所述待判定文本的每个关键词的特征值以及负向权重值,计算所述待判定文本的负向分类值,具体包括:根据如下公式5计算出所述待判定文本的正向分类值Scoreg:(公式5)根据如下公式6计算出所述待判定文本的负向分类值Scoreb:(公式6)其中,n表示所述待判定文本的关键词的总数;word_valuei表示所述待判定文本的n个关键词中的第i个关键词的特征值;word_weight_gi表示所述待判定文本的n个关键词中的第i个关键词的正向权重值;word_weight_bi表示所述待判定文本的n个关键词中的第i个关键词的负向权重值。较佳地,所述根据所述待判定文本的正向分类值和负向分类值,确定所述待判定文本是否为垃圾文本,具体包括:根据如下公式7,计算出所述待判定文本为垃圾文本的概率:(公式7)其中,aprioity表示所述训练集中非垃圾文本的占比;根据计算出的概率Pbad,确定所述待判定文本是否为垃圾文本。较佳地,所述对待判定文本进行分词,得到所述待判定文本的关键词,具体包括:对于待判定文本进行分词后得到的每个词语,确定该词语的词性和IDF值;从对待判定文本进行分词后得到的词语中,选择IDF值高于设定阈值、词性符合预设条件的词语作为所述待判定文本的关键词。较佳地,所述计算该关键词的特征值,具体包括:根据该关键词的TF值和IDF值,计算该关键词的特征值。根据本发明的另一个方面,还提供了一种建模方法,包括:对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词,并计算该文本的每个关键词的类别相关度;从所述训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为所述贝叶斯模型的特征词;针对所述贝叶斯模型的每个特征词,在所述训练集中统计非垃圾文本中包含有该特征词的文本的数量numg,统计垃圾文本中包含有该特征词的文本的数量numb;根据该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值。较佳地,所述计算该文本的每个关键词的类别相关度具体包括:对于该文本的每个关键词,根据如下公式2计算该关键词的类别相关度:(公式2)其中,T表示该关键词,CE(T)表示该关键词的类别相关度,P(C1|T)表示包含该关键词的文本属于垃圾文本类别的概率,P(C2|T)表示包含该关键词的文本属于非垃圾文本类别的概率,P(C1)表示垃圾文本在所述训练集中出现的概率,P(C2)表示非垃圾文本在所述训练集中出现的概率。较佳地,所述对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词,具体包括:对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行如下操作:对该文本进行分词后得到的每个词语,确定该词语的词性和IDF值;从对该文本进行分词后得到的词语中,选择IDF值高于设定阈值、词性符合预设条件的词语作为该文本的关键词。根据本发明的另一个方面,还提供了一种基于贝叶斯模型的文本垃圾识别系统,包括:关键词确定模块,用于对待判定文本进行分词,得到所述待判定文本的关键词;正负向权重值计算模块,用于针对所述关键词确定模块得到的所述待判定文本的每个关键词,计算该关键词的特征值,并在贝叶斯模型中查找与该关键词相匹配的特征词,获取查找到的特征词的正向权重值和负向权重值,分别作为该关键词的正向权重值和负向权重值;其中,所述特征词的正、负向权重值分别指的是所述特征词属于非垃圾文本、垃圾文本的概率权重值;正负向分类值计算模块,用于根据所述待判定文本的每个关键词的特征值以及正向权重值,计算所述待判定文本的正向分类值;根据所述待判定文本的每个关键词的特征值以及负向权重值,计算所述待判定文本的负向分类值;其中,所述待判定文本的正、负向分类值分别指的是所述待判定文本为非垃圾文本、垃圾文本的概率权重值;判定结果输出模块,用于根据所述待判定文本的正向分类值和负向分类值,确定所述待判定文本是否为垃圾文本,并将判定结果输出。较佳地,所述关键词确定模块、正负向权重值计算模块、正负向分类值计算模块、判定结果输出模块包含于所述系统的识别装置中;以及所述系统还包括:建模装置;所述建模装置包括:训练集关键词确定模块,用于对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词;特征词选取模块,用于针对训练集中每个文本,计算该文本的每个关键词的类别相关度;从所述训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为所述贝叶斯模型的特征词;统计模块,用于针对所述贝叶斯模型的每个特征词,在所述训练集中统计非垃圾文本中包含有该特征词的文本的数量numg,统计垃圾文本中包含有该特征词的文本的数量numb;特征词正负向权重值计算模块,用于根据该特征词的numg以及所述训练集中非垃圾文本的总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值。根据本发明的另一个方面,还提供了一种建模装置,包括:训练集关键词确定模块,用于对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词;特征词选取模块,用于针对训练集中每个文本,计算该文本的每个关键词的类别相关度;从所述训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为所述贝叶斯模型的特征词;统计模块,用于针对所述贝叶斯模型的每个特征词,在所述训练集中统计非垃圾文本中包含有该特征词的文本的数量numg,统计垃圾文本中包含有该特征词的文本的数量numb;特征词正负向权重值计算模块,用于根据该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值。本发明的技术方案中,在训练阶段主要是应用词语的IDF值(即包含该词语的垃圾文本,或非垃圾文本的文本频率值)来确定贝叶斯模型,避免TF值对贝叶斯模型的绑架;从而在识别阶段,依据该贝叶斯模型进行垃圾文本识别的系统可以具有更好的鲁棒性。而且,识别阶段综合考虑词语的TF值和IDF值,根据TF值和IDF值计算出词语的特征值进行文本的垃圾文本的识别,以有效利用词语的特征的信息量,以作出较为准确的垃圾文本判断。附图说明图1为现有技术的构建向量模型的方法流程图;图2为本发明实施例的建立贝叶斯模型的方法流程图;图3为本发明实施例的对待判定的文本进行垃圾识别的方法流程图;图4为本发明实施例的基于贝叶斯模型的文本垃圾识别系统的内部结构框图。具体实施方式为使本发明的目的、技术方案及优点更加清楚明白,以下参照附图并举出优选实施例,对本发明进一步详细说明。然而,需要说明的是,说明书中列出的许多细节仅仅是为了使读者对本发明的一个或多个方面有一个透彻的理解,即便没有这些特定的细节也可以实现本发明的这些方面。本申请使用的“模块”、“系统”等术语旨在包括与计算机相关的实体,例如但不限于硬件、固件、软硬件组合、软件或者执行中的软件。例如,模块可以是,但并不仅限于:处理器上运行的进程、处理器、对象、可执行程序、执行的线程、程序和/或计算机。举例来说,计算设备上运行的应用程序和此计算设备都可以是模块。一个或多个模块可以位于执行中的一个进程和/或线程内,一个模块也可以位于一台计算机上和/或分布于两台或更多台计算机之间。本发明的发明人对现有技术的方法导致鲁棒性较差的原因进行分析,发现在计算词语的特征值的过程中,由于考虑了TF值,导致词语在某个文本中大量出现时,TF值非常高,根据TF值和IDF值计算出的特征值基本被TF值所影响,从而造成包含该词语的特征值的词语特征向量对分类结果的绑架,使得构建的垃圾文本超平面、或非垃圾文本超平面出现偏离。基于上述分析,本发明的技术方案中,在训练阶段主要是应用词语的IDF值来确定分类结果,避免TF值对分类结果的绑架;在识别阶段,则综合考虑词语的TF值和IDF值,根据TF值和IDF值计算出词语的特征值进行文本的垃圾文本的识别,以有效利用词语的特征的信息量,以作出较为准确的垃圾文本判断。下面结合附图详细说明本发明的技术方案。本发明的实施例提供了一种基于贝叶斯模型的文本垃圾识别方法和系统;在训练阶段,先建立贝叶斯模型;在识别阶段,则利用构建的贝叶斯模型,进行垃圾文本的判定。训练阶段中,根据训练集中的各文本建立贝叶斯模型的方法,流程如图2所示,具体步骤包括:S201:对训练集中的每个文本进行分词,得到每个文本的词语集合。具体地,对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词:将该文本中连续的字序列划分为一个个词语;在划分出的词语中,去除掉没有实际意义的虚词(如标点、组动词、语气词、叹词、拟声词等);剩余的词语构成该文本的词语集合。S202:提取出训练集中每个文本的关键词。具体地,对于训练集中的每个文本进行分词后得到的每个词语,确定该词语的词性和IDF值;从对训练集中的每个文本进行分词后得到的词语中,选择IDF值高于设定阈值、词性符合预设条件的词语作为所述训练集中的每个文本的关键词。上述的设定阈值可以由本领域技术人员根据实际情况进行设定;所述词性符合预设条件的词语具体可以是词性为名词、或动词的词语。S203:针对训练集中每个文本,计算该文本的每个关键词的类别相关度。具体地,针对训练集中每个文本,对于该文本的每个关键词,可以根据如下公式2计算该关键词的类别相关度:(公式2)其中,T表示该关键词,CE(T)表示该关键词的类别相关度,P(C1|T)表示包含该关键词的文本属于垃圾文本类别的概率,即包含该关键词的文本在训练集中为垃圾文本的概率;P(C2|T)表示包含该关键词的文本属于非垃圾文本类别的概率,即包含该关键词的文本在训练集中为非垃圾文本的概率;P(C1)表示垃圾文本在所述训练集中出现的概率,P(C2)表示非垃圾文本在所述训练集中出现的概率。S204:从训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为贝叶斯模型的特征词。具体地,上述的设定值可以由本领域技术人员根据实际情况进行设定。S205:针对贝叶斯模型的每个特征词,计算出该特征词的正向权重值和负向权重值。本步骤中,根据该特征词的numg以及训练集中非垃圾文本总数,计算出该特征词的正向权重值;其中,numg为所述训练集的非垃圾文本中包含有该特征词的文本的数量。特征词的正向权重值用以表征该特征词属于非垃圾文本的概率,即为该特征词属于非垃圾文本的概率权重值。本步骤中,根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值;其中,numb为所述训练集的垃圾文本中包含有该特征词的文本的数量。特征词的负向权重值用以表征该特征词属于垃圾文本的概率,即该特征词属于垃圾文本的概率权重值。具体地,可以根据如下公式3计算出该特征词的正向权重值weightg:(公式3)上述公式3中,word_numg表示所述训练集的非垃圾文本中包含有该特征词的文本的数量;total_numg表示所述训练集中非垃圾文本总数;根据如下公式4计算出该特征词的负向权重值weightb:(公式4)上述公式4中,word_numb表示所述训练集的垃圾文本中包含有该特征词的文本的数量;total_numb表示所述训练集中垃圾文本总数。将计算出的特征词的正、负向权重值存储于贝叶斯模型中。在训练阶段,采用包含该特征词的垃圾/非垃圾文本数量来计算正/负向权重值可以很好的反应该特征词的区分度;相比于现有技术中采用IDF值来计算词语的特征值的方法,可以避免在单个文本中某个特征词大量出现时TF值对分类结果的绑架、干扰分类模型的区分度。在训练阶段构建出贝叶斯模型后,可以在识别阶段根据构建出的贝叶斯模型,对待判定的文本进行垃圾识别,具体流程图如图3所示,具体步骤包括:S301:对待判定文本进行分词,得到该待判定文本的词语集合。具体地,对于待判定文本进行分词:将该文本中连续的字序列划分为一个个词语;在划分出的词语中,去除掉没有实际意义的虚词(如标点、组动词、语气词、叹词、拟声词等);剩余的词语构成该文本的词语集合。S302:提取出待判定文本的关键词。具体地,对于待判定文本进行分词后得到的每个词语,确定该词语的词性和IDF值;从对待判定文本进行分词后得到的词语中,选择IDF值高于设定阈值、词性符合预设条件的词语作为所述待判定文本的关键词。其中,设定阈值可以由本领域技术人员根据实际情况进行设定;所述词性符合预设条件的词语具体可以是词性为名词、或动词的词语。S303:针对待判定文本的每个关键词,计算该关键词的特征值。具体地,针对所述待判定文本,根据该文本的每个关键词的TF值和IDF值,采用上述公式1计算该词语的特征值。S304:针对待判定文本的每个关键词,在贝叶斯模型中查找与该关键词相匹配的特征词。具体地,针对待判定文本的每个关键词,从上述方法得到的贝叶斯模型中的特征词中,查找出与该关键词相匹配的特征词。S305:针对待判定文本的每个关键词,将查找到的与该关键词相匹配的特征词的正向权重值和负向权重值,分别作为该关键词的正向权重值和负向权重值。具体地,对于查找到的特征词,将该特征词的正向权重值和负向权重值,分别作为与之匹配的关键词的正向权重值和负向权重值。S306:根据待判定文本的每个关键词的特征值以及正向权重值,计算待判定文本的正向分类值;根据待判定文本的每个关键词的特征值以及负向权重值,计算待判定文本的负向分类值。本步骤中,可以根据如下公式5计算出待判定文本的正向分类值Scoreg:(公式5)上述公式5中,n表示待判定文本的关键词的总数;word_valuei表示待判定文本的n个关键词中的第i个关键词的特征值;word_weight_gi表示待判定文本的n个关键词中的第i个关键词的正向权重值;本步骤中,可以根据如下公式6计算出待判定文本的负向分类值Scoreb:(公式6)上述公式6中,n表示待判定文本的关键词的总数;word_valuei表示待判定文本的n个关键词中的第i个关键词的特征值;word_weight_bi表示待判定文本的n个关键词中的第i个关键词的负向权重值。上述待判定文本的正向分类值指的是该待判定文本为非垃圾文本的概率权重值;上述待判定文本的负向分类值指的是该待判定文本为垃圾文本的概率权重值。S307:根据待判定文本的正向分类值和负向分类值,确定待判定文本是否为垃圾文本。具体地,根据如下公式7,计算出所述待判定文本为垃圾文本的概率:(公式7)上述公式7中,Scoreg表示该待判定文本的正向分类值;Scoreb表示该待判定文本的负向分类值;aprioity表示训练集中非垃圾文本的占比,即非垃圾文本数量与训练集中总文本数的比例。根据计算出的概率Pbad,确定所述待判定文本是否为垃圾文本。具体地,当计算出该待判定文本的概率Pbad大于某一设定概率值时,此时判定该待判定文本为垃圾文本。在识别阶段,由于待判定文本的可用信息有限;此时,某特征词在待判定文本中大量出现时,是分类的有效区分标志,所以采用特征词频率(IDF值)来计算待判定文本的关键词的特征值,可充分利用文本信息,强化重要特征信息,提升分类准确性。基于上述的方法,本发明实施例提供的一种基于贝叶斯模型的文本垃圾识别系统,如图4所示,包括:识别装置401和建模装置402。其中,建模装置402中包括:训练集关键词确定模块421、特征词选取模块422、统计模块423和特征词正负向权重值计算模块424。训练集关键词确定模块421用于对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词。特征词选取模块422用于针对训练集关键词确定模块421得到的训练集中每个文本的关键词,计算每个关键词的类别相关度;从训练集关键词确定模块421中得到的各文本的关键词中,选取类别相关度高于设定值的关键词作为所述贝叶斯模型的特征词。统计模块423用于针对特征词选取模块422得到的贝叶斯模型的每个特征词,在所述训练集中统计非垃圾文本中包含有该特征词的文本的数量numg,统计垃圾文本中包含有该特征词的文本的数量numb。特征词正负向权重值计算模块424用于针对特征词选取模块422得到的贝叶斯模型的每个特征词,根据统计模块423得到的该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据统计模块423得到的该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值;并将计算出的特征词的正、负向权重值存储于所述贝叶斯模型中。其中,识别装置401中包括:关键词确定模块411、正负向权重值计算模块412、正负向分类值计算模块413和判定结果输出模块414。关键词确定模块411用于对待判定文本进行分词,得到所述待判定文本的关键词。正负向权重值计算模块412用于针对关键词确定模块411得到的所述待判定文本的每个关键词,计算该关键词的特征值,并在贝叶斯模型中查找与该关键词相匹配的特征词,获取查找到的特征词的正向权重值和负向权重值,分别作为该关键词的正向权重值和负向权重值;其中,所述特征词的正、负向权重值分别指的是所述特征词属于非垃圾文本、垃圾文本的概率权重值。正负向分类值计算模块413用于根据计算出的待判定文本的每个关键词的特征值以及正负向权重值计算模块412得到的每个关键词的正向权重值,计算所述待判定文本的正向分类值;根据待判定文本的每个关键词的特征值以及正负向权重值计算模块412得到的每个关键词的负向权重值,计算所述待判定文本的负向分类值。判定结果输出模块414用于根据正负向分类值计算模块413得到的待判定文本的正向分类值和负向分类值,确定所述待判定文本是否为垃圾文本,并将判定结果输出。本发明的技术方案中,在训练阶段主要是应用词语的IDF值(即包含该词语的垃圾文本,或非垃圾文本的文本频率值)来确定贝叶斯模型,避免TF值对贝叶斯模型的绑架;从而在识别阶段,依据该贝叶斯模型进行垃圾文本识别的系统可以具有更好的鲁棒性。而且,识别阶段综合考虑词语的TF值和IDF值,根据TF值和IDF值计算出词语的特征值进行文本的垃圾文本的识别,以有效利用词语的特征的信息量,以作出较为准确的垃圾文本判断。以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1