基于协方差特征的图像场景类型判别方法与流程
本发明涉及图像场景类型的判别方法,特别是一种利用协方差特征进行图像场景分类识别的方法。
背景技术:
图像场景分类是计算机视觉领域的一个重要问题,场景类别不但包含了人们对图像的总体认识,还对场景中兴趣目标的检测和识别、视频监视等计算机视觉方面的应用具有重要意义,在图像检索、遥控装置导航领域有着广泛地应用,因此获得广泛关注。目前,场景分类的研究已取得了一定成果,但由于场景本身的复杂性、光照、遮挡等变化因素,场景分类仍是一个富有挑战的问题。早期场景分类的方法,主要是利用图像的全局特征信息对场景进行建模。但这些方法只适用于两类场景间的分类,如判断室内或室外。随后开始利用以pLSA为代表的方法来描述图像的“语义结构”,实现了多类场景间的分类[文献1:SmeuldersAW,WorringM,SantiniS.Content-basedimageretrievalattheendoftheearlyyears.IEEETrans.onPatternAnalysisandMachineIntelligence,2000,22(12):1349–1380]。但基于“语义结构”的方法描述复杂,训练结果的泛化能力不足,对机器自动分类的效果不佳。近年来,“特征袋”模型(bagoffeatures,BOF)[文献2:NowakE,JurieF,TriggsB.SamplingStrategiesforBag-of-FeaturesImageClassification.EuropeanConferenceonComputerVision.2006:409-503]在信息检索的应用中取得了巨大成功。受此启发,大量研究者将其应用到了场景分类中,该方法成为当前的研究热点。“特征袋”模型的关键是特征模型的选择。以SIFT不变特征为基础的局部图像块提取和描述方法,能描述场景中的有效信息,在BOF模型中获得了较好的应用。但“特征袋”模型将图像表示成局部特征的无序集合,完全忽略了图像各部分间的空间信息。针对此缺陷,空间金字塔匹配算法(spatialpyramidmatching,SPM)[文献3:LazebnikS,SchmidC.Beyondbagsoffeatures:Spatialpyramidmatchingforrecognizingnaturalscenecategories.IEEEConferenceonComputerVisionandPatternRecognition,2006:2169-2178],将图像由粗到细划分成多个子区域,各子区域的特征直方图组合为全局特征,结合SVM进行场景分类,取得了比BOF更好的分类效果。对于SPM来说,仍采用传统的SIFT特征描述,用K均值聚类形成全局的“视觉字典”,受SIFT特征维数和特征点数量的影响,SPM的计算量还不适合实时应用。戴琼海等的授权专利“基于监督流形学习的场景分类方法及装置”(授权公告号:CN102254194B)完成了对SIFT特征分类法改进,以流形学习代替了K均值聚类,使得最终的SIFT直方图更具有稳定性。但是它依然采用了SIFT作为基础特征,在计算量上没有改变。基于SIFT点的场景分类方法,还受到SIFT点数量不稳定、分布不均匀等不利因素的影响。特别地,SIFT点是底层图像特征,不具有语义识别能力,所以SIFT类场景分类器还存在泛化能力不足的问题。
技术实现要素:
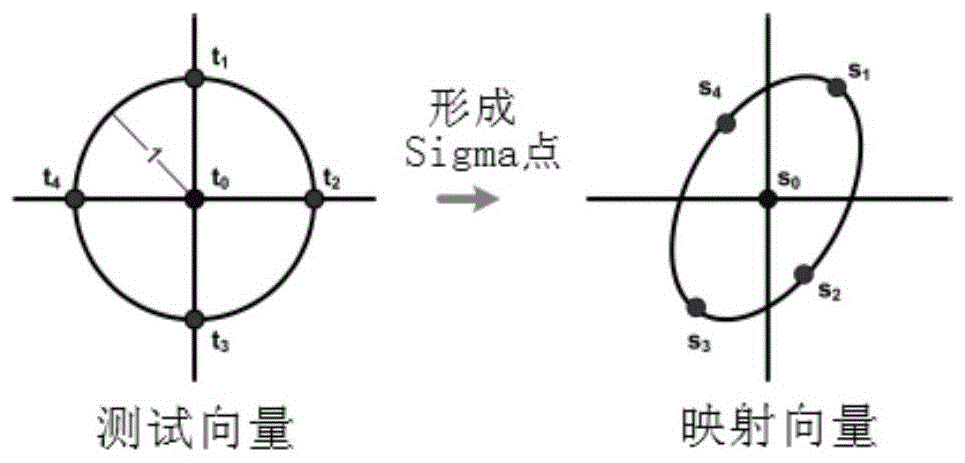
本发明的目的在于提出一种基于兴趣目标协方差矩阵的局部Sigma点特征,对场景进行语义建模并完成场景分类的方法。实现本发明目的的技术方案为:一种基于协方差特征的图像场景类型判别方法,包括基于协方差特征的字典形成过程、场景分类器的训练过程和待分类图像的判别过程,具体步骤如下:第一步,以交互式图像分割方法从训练图像中提取兴趣目标的区域像素内容,基于区域的协方差特征形成兴趣目标的特征字典,完成字典的形成过程;第二步,利用兴趣目标特征字典和训练图像的场景标记,完成场景分类器的训练过程;第三步,对待分类图像,完成基于场景分类器的判别过程。所述协方差特征的形成方法是:(1)对指定兴趣区域中的每个像素,提取它的位置、不变颜色量、梯度绝对值、Gabor滤波结果、LBP纹理系数,级联为19维的向量,作为像素的特征;(2)把指定兴趣区域内所有像素的特征,按二阶统计方法形成协方差特征。所述兴趣目标特征字典形成方法如下:(1)利用UT变换,把属于黎曼空间的协方差特征转换为欧式空间中的Sigma点区域特征,形成兴趣区域的特征向量;(2)汇总所有训练图像中兴趣区域的特征向量,基于K均值聚类算法得到兴趣目标特征字典;(3)记录K均值聚类算法中,训练样本与特征字典元素的最大距离δmax。本发明中K取值为50。所述场景分类器的训练过程如下:(1)按金字塔分解算法对训练图像进行均匀划分;(2)划分出的每块都计算对应的Sigma点区域特征;(3)根据每个区域特征与字典项的欧式距离,以δmax为门限,丢弃到字典元素距离过大的背景块;(4)完成基于前景块的兴趣目标直方图特征统计,直方图的统计区间为每个字典元素;(5)把直方图特征连同训练图像的场景类别标签输入到支持向量机,完成场景分类器的训练。所述待分类图像的场景类别识别过程如下:(1)按经典的金字塔分解算法对待分类图像进行均匀划分;(2)划分出的每块都计算对应的Sigma点区域特征;(3)根据每个区域特征与字典项的欧式距离,以δmax为门限丢弃背景块;(4)完成基于前景块的兴趣目标直方图特征统计,直方图的统计区间为每个字典元素;(5)把待分类图像的直方图输入到训练得到的支持向量机中,输出待分类图像的场景判别结果。本发明与现有技术相比,其显著优点:本发明对场景分类器训练图库中的兴趣目标进行了交互式分割,提取其协方差特征并转换到欧式空间中,使得常用的字典方法可以完成后续的训练和判别任务。该方法不但保留了具有语义识别能力的兴趣区域的特征,具有很强的分类能力可扩充性,而且能在欧式空间中使用成熟的字典描述方法和支持向量机分类器。附图说明图1是协方差特征场景分类方法的流程图。图2是Sigma点的原理示意图。图3是场景分类效果图。图4是分类准确度对比图。具体实施方式本发明包括三部分内容:1)在字典形成阶段,利用图像分割工具手工完成训练图像中的具有语义功能的兴趣目标提取,计算兴趣目标的协方差特征,把兴趣目标的协方差特征进行Sigma点分解,转换为欧式空间向量,然后对所有训练图像中提取的兴趣目标向量进行聚类,获取兴趣目标的特征字典。2)在分类器训练阶段,均匀分割训练图像为分块,计算每块的欧式空间向量,形成以特征字典为元素的直方图,以特征字典直方图和图像场景类别为输入,训练场景分类的支持向量机。3)在场景识别阶段,以相同方法形成待识别图像的特征字典直方图,输入支持向量机获得场景类别。本发明解决其技术问题所采用的技术方案是:(1)特征字典的形成字典形成要经过数据准备和特征计算两个阶段。在数据准备阶段,首先获取场景分类的训练图像,并标记每张图像的场景类别。该过程可以使用互联网上提供的各种图库,例如Sun2009,ETHZ等。也可以针对使用者的需要自行添加训练图像和对应的场景类别。然后利用GraphCut等交互式图像分割工具,对每种训练图像分割出兴趣目标。分割出的兴趣目标呈连通状态,保存这些兴趣目标的像素信息。图像分割工具的选择用户可以自行决定。如果已经存在独立的语义兴趣目标库,也可以跳过交互式图像分割步骤。在字典形成的特征计算阶段,主要围绕兴趣目标的协方差特征进行。基于协方差矩阵的特征描述方法,在快速的目标发现和分类方面已经有所应用,但是用于场景分类还是首次应用,这也是本发明的核心思想。协方差矩阵属于黎曼空间,不同于常用的欧式空间,它在距离测度的定义上存在较大区别,常用的内积运算不再适用。为了方便协方差特征间距离的比较,本发明把协方差特征转换到欧式空间中,使常用的向量内积和聚类算法等工具能继续使用。协方差特征是对多种特征信道(如颜色、滤波响应等)进行组合,通过相关系数计算形成的一种低维统计特征描述。假设I是彩色场景图像中兴趣目标块,我们可以得到兴趣目标的d维像素特征集F(x,y)=φ(I,x,y),其中映射函数φ是对多种特征信道的组合,将图像中的每个像素扩展成d维特征,x,y是像素在兴趣图像块内的相对横坐标和纵坐标。于是,对于图像中任何兴趣区域R,令{zk}k=1…n表示该区域内的所有d维特征像素点,根据式(1)可计算出d×d维的协方差矩阵,称其为区域协方差描述子:其中μ表示区域像素点d维特征的均值,n是区域内的像素数量。像素特征的选取,通常采用像素位置、RGB颜色、梯度强度和方向等。但对于不同场景中的兴趣目标,由于存在光照强度和视角的变化,以及非刚性变化的问题,将直接影响场景判断的准确性。传统的像素特征不能很好的解决上述这些问题。因此,针对影响因素,本发明提出了新的像素特征集,如下所示:在保留位置信息x,y和梯度信息的同时,改变颜色通道的描述形式,增加Gabor滤波器组提取轮廓信息和LBP纹理信息。其中,O1(x,y)/O2(x,y)和O2(x,y)/O3(x,y)按公式(3)由彩色图像的RGB颜色空间转换得到,是颜色空间中的不变量,能保证不同光照条件下颜色特征的稳定性:把彩色兴趣目标块I转换为对应的灰度图像f(x,y),然后利用尺度系数为m方向系数为n的Gabor滤波器组对f(x,y)进行滤波,结果用Gabor(x,y),即:Gabor(x,y)=f(x,y)*gmn(x,y)gmn(x,y)=a-mg(x',y')x'=a-m(xcosθ+ycosθ),y'=a-m(-xsinθ+ycosθ)θ=nπ/(n+1)a-m为尺度因子,σx和σy表示高斯函数标准差,f0是滤波器中心频率,θ为滤波器方向。在本发明中m取3,n取4。则每个像素点形成的Gabor特征为12个。利用Gabor滤波器对图像进行特征提取,实质是检测出图像中一些具有相应的方向频率信息的显著特征,可以有效地表示兴趣目标的轮廓外形语义特征。LBP(x,y)表示像素点(x,y)的纹理特征。对每个像素3x3范围内的8邻居的亮度差分二值化结果,进行旋转不变级联后形成。LBP特征对光照变化具有不变性,从而增强对兴趣目标的语义描述准确性。根据公式(2),每个像素的特征是一个19维向量。获得兴趣目标区域内所有像素的特征向量后,根据公式(1)计算出兴趣目标的协方差矩阵。协方差矩阵属于黎曼空间,不具有简便的距离测度,不能在标准的机器学习算法中直接使用。所以在本发明中,利用UT变换(UnscentedTransform)把协方差矩阵转换为欧式空间中,19维的协方差特征转换成欧式空间中的39个Sigma特征点,每个Sigma点包含19维特征。Sigma点的计算过程如下:1、已知协方差阵Σ和区域特征向量的均值μ。对Σ进行简单正则化:Σ=Σ+εI,ε=10-6,其中I为d维单位阵;2、利用Cholesky分解计算协方差矩阵的标准差:得到下三角矩阵3、计算Sigma点si:其中为下三角阵的第i列,α定义元素的权重,取常数4、将所有的Sigma点级联形成最终的区域特征S=(s0,s1,…s2d),特征维数是741。计算所有训练图像中通过交互式分割获得的兴趣目标区域Sigma点区域特征。由于Sigma点区域特征是欧式向量,所以可以直接对汇总形成的区域特征样本集合进行K均值聚类算法,得到的K个中心点(c0,c1,...,cK-1)就构成了特征字典,每个字典项的维数是741。同时,记录所有区域特征样本与K个中心点的最大距离δmax。本发明中K取值为50。(2)场景分类器训练特征字典是兴趣目标的特征子空间。在交互式图像分割时,用户只挑选了具有较强语义判别能力的目标。这些目标在不同的图像中可能同时出现,但是用户不一定在每个图像中都对它们进行分割。作为图像场景的分类器,应该完整体现兴趣区域的分类效果。所以,在分类器训练阶段,本发明采用了均匀采样,统计训练的方式。具体做法如下:1、仿照空间金字塔方法,把训练图像进行两层金字塔分解。在每一层中按行列划分64*64像素的方形区域,每个方向区域在行、列方向与其相邻区域各有32个像素的重叠;金字塔的测试可以根据需要增加;2、对每个方向区域计算Sigma点区域特征;3、计算每个Sigma点区域特征与字典(c0,c1,...,cK-1)中每个元素的距离,记录最小距离dk,其中k是字典元素的下标。如果dk>δmax,则当前的Sigma点区域特征属于背景区域,直接丢弃;否则对字典元素k计数加1,认为出现兴趣目标1次;4、统计每张训练图像的兴趣目标出现次数,归一化为该图像的兴趣目标直方图;5、以兴趣目标直方图和训练图像标记的场景类型为输入,训练支持向量机,完成对场景分类器的训练。(3)场景分类仿照分类器训练阶段的方法,对待分类图像进行金字塔分解,然后利用Sigma点区域特征形成兴趣目标直方图。以待分类图像的兴趣目标直方图为输入,分类器给出场景类别的判别结果。下面结合附图对本发明做进一步说明。参考图1,选择合适的训练图库。图库中应该包括与待识别图像具有一定的相似性的图像,特别是具有语义相似性的兴趣目标。对特定场景中的标志性目标应该作为先验知识加入到图库中。选择可用的交互式图像分割工具,辅助用户进行兴趣目标的提取。推荐使用GraphCut。获得的兴趣目标像素区域尽量去除背景像素,并且保持像素的无空洞全连通。参考图2,对兴趣区域进行基于Sigma点的字典形成和分类器训练。主要步骤如下:(1)根据兴趣区域的像素内容,根据公式(1)计算对应的协方差特征;(2)根据公式(5)把黎曼空间的协方差特征转换为欧式空间中的Sigma点区域特征;(3)汇总所有训练图像的兴趣区域,基于K均值聚类算法得到特征字典,并记录训练样本与字典项的最大距离δmax;(4)按金字塔分解算法对训练图像进行均匀划分,划分出的每块都计算对应的Sigma点区域特征。根据每个区域特征与字典项的欧式距离,以δmax为门限丢弃背景块;统计前景块的兴趣目标直方图,连同训练图像的场景类别标签,输入到支持向量机中进行训练。(5)对待分类图像,按金字塔分解算法进行均匀划分,以步骤(4)中相同的方法进行兴趣目标直方图的计算。把得到的兴趣目标直方图输入到训练得到的支持向量机中,输入对待分类图像场景类型的判别结果。选择SUNDatabase场景数据库进行协方差分类方法的实验。该场景库2010年由布朗大学的研究者建立,包含人工标注的899个场景类别和130519幅场景图像,是一个基本无遗漏性的场景数据库,对于分类算法的性能验证具有普遍意义。实验时,选择SUNDatabase中Bedroom、Building、City、Coast、Forest、Highway和Mountain7类场景作为标准实验库。在标准实验库上,将每幅图像的尺寸规范到256x256像素,然后使用GraphCut进行兴趣目标的提取,把获得的兴趣目标像素区域尽量去除背景像素,并且保持像素的无空洞全连通。在计算像素特征时,把Gabor滤波器组的方向参数取4,尺度参数取3;转换形成的Sigma点特征是741维的特征向量;在基于K均值聚类算法形成字典时,字典元素数量K取50,并记录训练样本与字典项的最大距离δmax。为对所有标准场景进行充分学习,随机地从每类场景中选择一半作为训练集,其余作为测试集;选择LIBSVM进行all-vs-all多类学习,核函数选择线性函数,并与典型的Gist、LBP(LocalBinaryPatterns)、HMAX(HierarchicalModelswithMaxMechanisms)、BOF(BagofFeature)和SPM(SpatialPyramidMatching)算法进行性能比较。参见图3、4的ROC曲线对比和分类准确度对比图,ROC曲线能够很好地表示分类虚警率和识别率的变化趋势,横坐标即表示每种算法分类时的虚警率,纵坐标即表示场景识别率。随着虚警率不断增加,训练样本和类别将随之增加,保证了识别率的提升。本发明具有很高的分类正确率。各算法对每类场景的分类准确度对比中,横坐标表示场景类别,纵坐标表示对每类场景的分类准确度。表1场景分类算法执行效率从结果看,本发明的算法具有与SPM相近的最高分类准确性,但是本发明的计算时间只有SPM的一半。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1