一种数据库故障的处理方法及装置与流程
本发明涉及数据库领域,特别涉及一种数据库故障的处理方法及装置。
背景技术:
TimesTen内存数据库是运行过程中全部数据、事务变更操作在内存中完成的数据库。内存是业界当前公认最快的存储装置,因此TimesTen内存数据常被用于业务响应及时性要求非常高的场景。目前的通信业务系统中,计费系统是业务响应要求非常高的,一般要求在1秒以内完成响应。因此通信行业中,TimesTen内存数据库被用于计费系统中。
但Timesten数据库这个产品本身没有提供表的统计收集功能,而表的统计信息是否准确对于数据库的业务性能快慢、效率高低起到决定性的作用。为了保证数据库的正常稳定运行,一般都会选择在数据库业务运行闲时部署表对象的例行统计收集。
在业务闲时部署表对象的例行统计收集,一般情况下能够保证Timesten内存数据库的稳定运行,但在计费系统忙时,由于表的统计收集不及时,很容易引起表统计收集的数据与表(特别是中间临时表)中实际存在数据差异量过大,从而引起系统运行缓慢,业务无法处理,甚至挂机。而Timesten内存数据库本身不能监控到这类故障,会导致故障时间过长,这是计费系统不可接受的。
技术实现要素:
本发明要解决的技术问题是提供一种数据库故障的处理方法及装置,解决现有内存数据库不能及时监控并处理由于表统计收集不及时引起的故障的问题。
为解决上述技术问题,本发明的实施例提供一种数据库故障的处理方法, 所述处理方法包括:
获取数据库运行过程中预设的监控事件对数据库运行效率检测的第一检测值;
根据所述第一检测值确定所述数据库的第一运行状态,并在所述数据库的第一运行状态为故障状态时,对所述数据库的中间临时表进行第一次统计收集;
获取所述预设的监控事件在对所述数据库的中间临时表进行第一次统计收集之后的数据库运行效率检测的第二检测值;
根据所述第二检测值确定所述数据库的第二运行状态,并在所述数据库的第二运行状态为故障状态时,对所述数据库的全库表进行第二次统计收集。
其中,所述预设的监控事件包括:对数据库运行过程中的CPU使用率的监控和/或离线话单率的监控;
所述获取数据库运行过程中预设的监控事件对数据库运行效率检测的第一检测值的步骤包括:
对数据库运行过程中的CPU使用率监控时,获取对数据库CPU使用率检测的第一CPU使用率;和/或
对数据库运行过程中的离线话单率监控时,获取对数据库离线话单率检测的第一离线话单率。
其中,所述根据所述第一检测值确定所述数据库的第一运行状态的步骤包括:
若所述第一CPU使用率大于第一预设值或所述第一离线话单率大于第二预设值,则确定所述数据库的第一运行状态为故障状态。
其中,所述获取所述预设的监控事件在对所述数据库的中间临时表进行第一次统计收集之后的数据库运行效率检测的第二检测值的步骤包括:
获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库CPU使用率检测的第二CPU使用率;和/或
获取对数据库运行过程中的离线话单率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库离线话单率检测的第二离线话单率。
其中,所述根据所述第二检测值确定所述数据库的第二运行状态的步骤包 括:
若所述第二CPU使用率大于所述第一预设值或所述第二离线话单率大于所述第二预设值,则确定所述数据库的第二运行状态为故障状态。
其中,所述根据所述第二检测值确定所述数据库的第二运行状态之后还包括:
在所述数据库的第二运行状态为故障状态时,发出第一次告警。
其中,所述根据所述第二检测值确定所述数据库的第二运行状态,并在所述数据库的第二运行状态为故障状态时,对所述数据库的全库表进行第二次统计收集之后还包括:
获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库CPU使用率检测的第三CPU使用率;和/或
获取对数据库运行过程中的离线话单率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库离线话单率检测的第三离线话单率。
其中,所述处理方法还包括:
若所述第三CPU使用率大于所述第一预设值或所述第三离线话单率大于所述第二预设值,则确定所述数据库的第三运行状态为故障状态,并在所述数据库的第三运行状态为故障状态时,发出第二次告警。
为解决上述技术问题,本发明的实施例还提供一种数据库故障的处理装置,所述处理装置包括:
第一获取模块,用于获取数据库运行过程中预设的监控事件对数据库运行效率检测的第一检测值;
第一统计收集模块,用于根据所述第一检测值确定所述数据库的第一运行状态,并在所述数据库的第一运行状态为故障状态时,对所述数据库的中间临时表进行第一次统计收集;
第二获取模块,用于获取所述预设的监控事件在对所述数据库的中间临时表进行第一次统计收集之后的数据库运行效率检测的第二检测值;
第二统计收集模块,用于根据所述第二检测值确定所述数据库的第二运行状态,并在所述数据库的第二运行状态为故障状态时,对所述数据库的全库表 进行第二次统计收集。
其中,所述预设的监控事件包括:对数据库运行过程中的CPU使用率的监控和/或离线话单率的监控;
所述第一获取模块包括:
第一获取子模块,用于对数据库运行过程中的CPU使用率监控时,获取对数据库CPU使用率检测的第一CPU使用率;和/或
第二获取子模块,用于对数据库运行过程中的离线话单率监控时,获取对数据库离线话单率检测的第一离线话单率。
其中,所述第一统计收集模块包括:
第一确定模块,用于若所述第一CPU使用率大于第一预设值或所述第一离线话单率大于第二预设值,则确定所述数据库的第一运行状态为故障状态。
其中,所述第二获取模块包括:
第三获取子模块,用于获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库CPU使用率检测的第二CPU使用率;和/或
第四获取子模块,用于获取对数据库运行过程中的离线话单率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库离线话单率检测的第二离线话单率。
其中,所述第二统计收集模块包括:
第二确定模块,用于若所述第二CPU使用率大于所述第一预设值或所述第二离线话单率大于所述第二预设值,则确定所述数据库的第二运行状态为故障状态。
其中,所述处理装置还包括:
第一告警模块,用于在所述数据库的第二运行状态为故障状态时,发出第一次告警。
其中,所述处理装置还包括:
第三获取模块,用于获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库CPU使用率检测的第三CPU使用率;和/或
第四获取模块,用于获取对数据库运行过程中的离线话单率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库离线话单率检测的第三离线话单率。
其中,所述处理装置还包括:
第二告警模块,用于若所述第三CPU使用率大于所述第一预设值或所述第三离线话单率大于所述第二预设值,则确定所述数据库的第三运行状态为故障状态,并在所述数据库的第三运行状态为故障状态时,发出第二次告警。
本发明的上述技术方案的有益效果如下:
本发明实施例的数据库故障的处理方法,首先获取数据库运行过程中预设的监控事件对数据库运行效率检测的第一检测值;然后根据第一检测值确定数据库的第一运行状态,并在数据库的第一运行状态为故障状态时,对数据库的中间临时表进行第一次统计收集;再获取预设的监控事件在对数据库的中间临时表进行第一次统计收集后的数据库运行效率检测的第二检测值;然后根据第二检测值确定数据库的第二运行状态,并在数据库的第二运行状态仍为故障状态时,对数据库的全库表进行第二次统计收集。实现了对数据库故障的及时监控和处理,有效解决了由于表统计收集不及时而引起的故障,保证了数据库的正常运行,提高了处理效率。
附图说明
图1为本发明数据库故障的处理方法流程图;
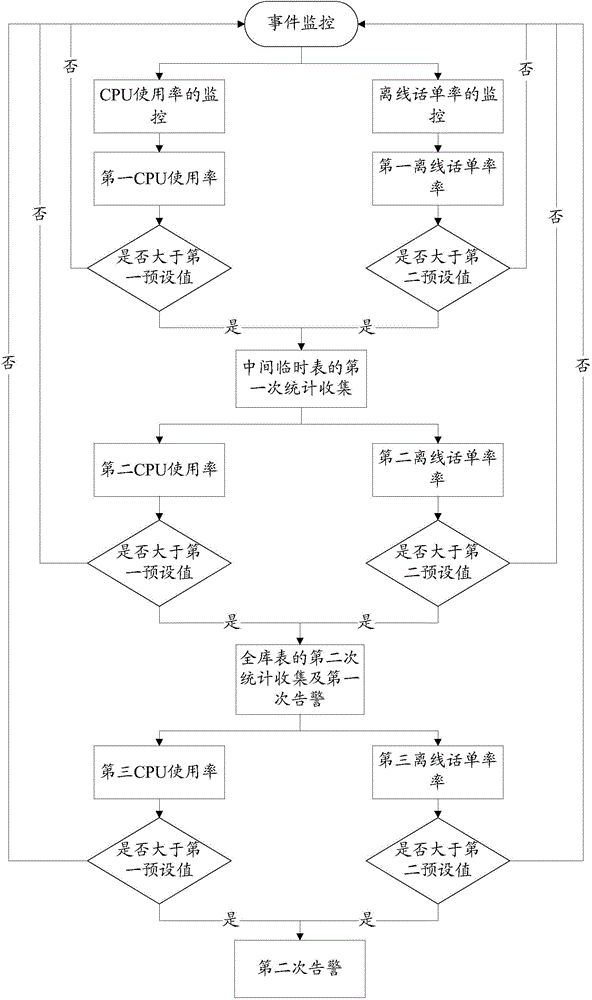
图2为本发明数据库故障的处理方法一具体实施例的流程图;
图3为本发明数据库故障的处理装置的结构示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
在通信行业中,TimesTen内存数据库被用于计费系统中。由于计费系统涉及客户计费、语音通信、短彩信、GPRS(General Packet Radio Service,通用分组无线服务技术)上网(特别是4G),客户敏感度非常高,一个操作不当 或是处理不当,直接影响客户的感知度,影响公司的业务和声誉。
TimesTen数据库这个产品本身没有提供表的统计收集功能,而统计收集本身需要消耗一定的资源,正常情况下(业务高峰)不能对数据库表对象实施统计收集,会影响系统的正常运行。因此为了保证数据库的正常稳定运行,一般都会选择在业务运行闲时(例如23:00-6:00)部署数据库表对象例行的统计收集。但数据库表对象随着业务的变化,存储的数据也不在不断的变化,因此在业务运行闲时例行的统计收集只能反映某一个时刻表对象中存储的数据,这样由于表的统计收集不及时,就会导致统计收集的数据与表中实际存储的数据不相符。
而在融合计费系统业务设计中,有一类中间临时表用来存储中间处理数据。这类表的特点就是快进快出,先插入数据,数据完成处理之后,立即删除。因此这类中间临时表较其他表变化更大,尤其在月底月初等业务忙时,很容易引起数据库中表对象的统计信息收集的数据与表中实际存在数据差异量超过30%。如果差异量超过30%,就会引起系统运行缓慢,业务无法处理,甚至挂机,从而影响用户感知。
由于TimesTen内存数据库本身的特性,不能监控到此类故障,必须要等到业务发出监控告警,才会介入故障处理。或者是等到运营前台、业务部报障,才知道已经发生问题,时延长,可能会超过30分钟,这是计费系统不可接受的。
本发明实施例的数据库故障的处理方法,根据故障表象形成事件监控,对由于表统计收集不及时引起的故障进行智能化处理,使用户在没有感知的情况下解决后续可能引发的业务投诉,增强了系统的稳定性和可靠性。
如图1所示,本发明实施例的数据库故障的处理方法,包括:
步骤11,获取数据库运行过程中预设的监控事件对数据库运行效率检测的第一检测值;
步骤12,根据所述第一检测值确定所述数据库的第一运行状态,并在所述数据库的第一运行状态为故障状态时,对所述数据库的中间临时表进行第一次统计收集;
步骤13,获取所述预设的监控事件在对所述数据库的中间临时表进行第 一次统计收集之后的数据库运行效率检测的第二检测值;
步骤14,根据所述第二检测值确定所述数据库的第二运行状态,并在所述数据库的第二运行状态为故障状态时,对所述数据库的全库表进行第二次统计收集。
其中,数据库的业务表按照业务运行的特殊性分为两类,分别是中间临时表和非中间临时表。在正常情况下,中间临时表存在大量的插入、删除、更新等操作,数据变化量大,且总量小,很容易触发由于表的统计收集不准引起的业务运行缓慢等故障。如果数据库运行出现故障,在未做任何变更的情况下,可以确定为中间临时表统计收集不准引起的故障,因此通过上述步骤12可实施对中间临时表的第一次统计收集,进行第一次故障处理。
但也不排除业务突然对其他非中间临时表做了大量的数据变更,从而引起业务运行缓慢等故障。因此,当执行中间临时表的统计收集之后,若未能完成故障恢复,通过上述步骤13,立即实施数据库全库表的第二次统计收集,进行第二次故障处理。
本发明实施例的数据库故障的处理方法,实现了对数据库故障的及时监控和处理,有效解决了由于表统计收集不及时而引起的故障,保证了数据库的正常运行,提高了处理效率,增强了系统的稳定性和可靠性。
其中,通过对数据库故障的深度分析和总结,优选的,所述预设的监控事件可包括:对数据库运行过程中的CPU使用率的监控和/或离线话单率的监控;
上述步骤11的步骤可包括:
步骤111,对数据库运行过程中的CPU使用率监控时,获取对数据库CPU使用率检测的第一CPU使用率;和/或
步骤112,对数据库运行过程中的离线话单率监控时,获取对数据库离线话单率检测的第一离线话单率。
此时,通过对数据库运行过程中的CPU使用率和/或离线话单率的监控,能准确获取到数据库的故障状态,以对数据库故障及时进行处理,提高了处理效率。
进一步的,上述步骤12的步骤可包括:
步骤121,若所述第一CPU使用率大于第一预设值或所述第一离线话单 率大于第二预设值,则确定所述数据库的第一运行状态为故障状态。
此时,在CPU使用率或离线话单率超出预设正常值时,即可判断数据库的运行状态为故障状态,实现方式简单有效,且提高了判断的准确性。
其中,所述第一预设值可为80%,在业务运行正常的情况下,CPU使用率小于80%;所述第二预设值可为10%,在业务运行正常的情况下,离线话单率小于10%。具体的,也可根据业务运行情况对第一预设值和第二预设值进行优化调整。
进一步的,上述步骤13的步骤可包括:
步骤131,获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库CPU使用率检测的第二CPU使用率;和/或
步骤132,获取对数据库运行过程中的离线话单率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库离线话单率检测的第二离线话单率。
此时,在对中间临时表进行第一次统计收集后,通过获取第二CPU使用率和/或第二离线话单率,来检测数据库故障是否恢复,以在数据库故障没有恢复时进行进一步的故障处理,增加了监控的有效性和合理性。
其中,上述步骤14的步骤可包括:
步骤141,若所述第二CPU使用率大于所述第一预设值或所述第二离线话单率大于所述第二预设值,则确定所述数据库的第二运行状态为故障状态。
此时,在CPU使用率或离线话单率超出预设正常值时,即可判断数据库的运行状态为故障状态,实现方式简单有效,且提高了判断的准确性。
本发明的具体实施例中,由于中间临时表的数据量一般情况下小于30万,因此执行统计时间非常快,一般在5分钟之内可以完成。若对中间临时表进行第一次统计收集后,数据库故障没有恢复,则立即执行对数据库全库表的统计收集。而数据库全库表的统计收集时间,一般情况下在30分钟内完成,但是30分钟的故障时长对于融合计费系统来说是一个不可接受的时间。因此,考虑计费业务的特殊性,优选的,上述步骤14之后还可以包括:
步骤15,在所述数据库的第二运行状态为故障状态时,发出第一次告警。
此时,在对中间临时表进行统计收集后,若故障没有恢复,则立即发出第一次告警,以通知运维人员介入处理。提高了故障处理的时效性,避免了由于全库表统计收集时间过长,而对业务运行产生过大影响。并能将故障处理情况实时反馈给运维人员,方便运维人员处理。
进一步的,上述步骤14之后还可以包括:
步骤161,获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库CPU使用率检测的第三CPU使用率;和/或
步骤162,获取对数据库运行过程中的离线话单率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库离线话单率检测的第三离线话单率。
此时,如果不是由于表统计收集不准引起的故障,则对数据库全库表进行统计收集后,数据库故障不会恢复。因此,在对全库表进行第二次统计收集后,通过获取第三CPU使用率和/或第三离线话单率,来检测数据库故障是否恢复,以在数据库故障没有恢复时进行进一步的故障处理,增加了监控的有效性和合理性。
优选的,所述处理方法还包括:
步骤17,若所述第三CPU使用率大于所述第一预设值或所述第三离线话单率大于所述第二预设值,则确定所述数据库的第三运行状态为故障状态,并在所述数据库的第三运行状态为故障状态时,发出第二次告警。
此时,在对全库表进行统计收集后,若故障仍没有恢复,就可以确定不是由于表统计收集不准引起的故障,则发出第二次告警,以通知运维人员介入处理,提高了故障处理的有效性,并能将故障处理情况实时反馈给运维人员。
优选的,所述第二次告警的告警级别大于所述第一次告警的告警级别。此时,通过提高第二次告警的级别,可警示运维人员此次故障不能通过表的统计收集恢复,以方便运维人员制定故障处理策略,提高了处理的有效性。
下面对本发明的具体实施例举例说明如下:
如图2所示,本发明实施例的数据库故障的处理方法,分别对数据库运行过程中的CPU使用率和离线话单率进行监控。首先获取对数据库运行过程中 的CPU使用率检测的第一CPU使用率及离线话单率检测的第一离线话单率;若第一CPU使用率大于第一预设值或第一离线话单率大于第二预设值,则确定数据库的第一运行状态为故障状态,并立即实施对数据库中间临时表的第一次统计收集;在完成对数据库中间临时表的第一次统计收集后,继续获取对数据库运行过程中的CPU使用率检测的第二CPU使用率及离线话单率检测的第二离线话单率;若第二CPU使用率大于第一预设值或第二离线话单率大于第二预设值,则确定数据库的第二运行状态仍为故障状态,并立即实施对数据库全库表的第二次统计收集,同时发出第一次告警;在完成对数据库全库表的第二次统计收集后,继续获取对数据库运行过程中的CPU使用率检测的第三CPU使用率及离线话单率检测的第三离线话单率;若第三CPU使用率大于第一预设值或第三离线话单率大于第二预设值,则确定数据库的第三运行状态仍为故障状态,并发出第二次告警,同时提高告警级别。
本发明实施例的数据库故障的处理方法,为了保证发生的故障能够及时处理,根据故障表象进行事件监控和智能化处理。在进行故障的智能化处理时,首先执行中间临时表的统计收集,执行时间快,一般5分钟完成。如果故障没有恢复,再执行全库表的统计收集,保证不是由于表的统计收集不及时引起的故障。同时为了保证故障能及时、快速、有效地处理,新增了预警功能。在智能化处理的过程中能够实时将智能化处理结果告知运维人员,尽可能减小业务影响,提高了处理的时效性。
本发明实施例的数据库故障的处理方法,将智能处理运用于TimesTen内存数据库,实现了对数据库故障的及时监控和处理,减小了融合计费业务故障处理时间,提升了处理时效。有效解决了由于表统计收集不及时而引起的故障,保证了数据库的正常运行,提高了处理效率,增强了系统的稳定性和可靠性。
如图3所示,本发明的实施例还提供了数据库故障的处理装置,包括:
第一获取模块,用于获取数据库运行过程中预设的监控事件对数据库运行效率检测的第一检测值;
第一统计收集模块,用于根据所述第一检测值确定所述数据库的第一运行状态,并在所述数据库的第一运行状态为故障状态时,对所述数据库的中间临时表进行第一次统计收集;
第二获取模块,用于获取所述预设的监控事件在对所述数据库的中间临时表进行第一次统计收集之后的数据库运行效率检测的第二检测值;
第二统计收集模块,用于根据所述第二检测值确定所述数据库的第二运行状态,并在所述数据库的第二运行状态为故障状态时,对所述数据库的全库表进行第二次统计收集。
本发明实施例的数据库故障的处理方法,实现了对数据库故障的及时监控和处理,有效解决了由于表统计收集不及时而引起的故障,保证了数据库的正常运行,提高了处理效率,增强了系统的稳定性和可靠性。
优选的,所述预设的监控事件包括:对数据库运行过程中的CPU使用率的监控和/或离线话单率的监控;
所述第一获取模块包括:
第一获取子模块,用于对数据库运行过程中的CPU使用率监控时,获取对数据库CPU使用率检测的第一CPU使用率;和/或
第二获取子模块,用于对数据库运行过程中的离线话单率监控时,获取对数据库离线话单率检测的第一离线话单率。
进一步的,所述第一统计收集模块包括:
第一确定模块,用于若所述第一CPU使用率大于第一预设值或所述第一离线话单率大于第二预设值,则确定所述数据库的第一运行状态为故障状态。
优选的,所述第二获取模块包括:
第三获取子模块,用于获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库CPU使用率检测的第二CPU使用率;和/或
第四获取子模块,用于获取对数据库运行过程中的离线话单率监控时,在对所述数据库的中间临时表进行第一次统计收集之后的数据库离线话单率检测的第二离线话单率。
进一步的,所述第二统计收集模块包括:
第二确定模块,用于若所述第二CPU使用率大于所述第一预设值或所述第二离线话单率大于所述第二预设值,则确定所述数据库的第二运行状态为故障状态。
优选的,所述处理装置还包括:
第一告警模块,用于在所述数据库的第二运行状态为故障状态时,发出第一次告警。
其中,所述处理装置还包括:
第三获取模块,用于获取对数据库运行过程中的CPU使用率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库CPU使用率检测的第三CPU使用率;和/或
第四获取模块,用于获取对数据库运行过程中的离线话单率监控时,在对所述数据库的全库表进行第二次统计收集之后的数据库离线话单率检测的第三离线话单率。
优选的,所述处理装置还包括:
第二告警模块,用于若所述第三CPU使用率大于所述第一预设值或所述第三离线话单率大于所述第二预设值,则确定所述数据库的第三运行状态为故障状态,并在所述数据库的第三运行状态为故障状态时,发出第二次告警。
本发明实施例的数据库故障的处理装置,将智能处理运用于TimesTen内存数据库,实现了对数据库故障的及时监控和处理,减小了融合计费业务故障处理时间,提升了处理时效。有效解决了由于表统计收集不及时而引起的故障,保证了数据库的正常运行,提高了处理效率,增强了系统的稳定性和可靠性。
需要说明的是,该数据库故障的处理装置是与上述数据库故障的处理方法相对应的装置,其中上述方法实施例中所有实现方式均适用于该装置的实施例中,也能达到同样的技术效果。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!