数据库的查询方法及装置与流程
本发明涉及通信领域,具体而言,涉及一种数据库的查询方法及装置。
背景技术:
对于关系数据库查询,相关技术中的效率优化办法是采用适当的索引,必要时使用结构化查询语言(Structured Query Language,简称为SQL)注释(如Oracle hint)来指定数据库查询优化方式。对于一些场景,由于数据分布的不均匀、Hint不是最优方式,导致无法达到实际效率的最优状态。
针对相关技术中对于数据库的查询方式比较单一的问题,目前尚未提出有效的解决方案。
技术实现要素:
本发明的主要目的在于提供一种数据库的查询方法及装置,以至少解决相关技术中对于数据库的查询方式比较单一的问题。
根据本发明的一个方面,提供了一种数据库的查询方法,包括:获取用于指示查询数据库的查询场景的多个参数:依据所述多个参数进行综合决策,并按照与决策结果对应的查询类型执行对所述数据库的查询。
进一步地,获取用于指示查询数据库的查询场景的多个参数包括:获取第一预设统计时间内查询条件中限制返回的数据量与从所述数据库查询的数据总量之比的第一参数;获取在第二预设统计时间内所述数据库内需要查询的数据索引范围与所述数据库中所有数据的索引范围之比的第二参数;获取在第三预设统计时间内查询条件中的数据库分区与总分区之比的第三参数。
进一步地,依据所述多个参数进行综合决策,并按照与决策结果对应的查询类型执行对所述数据库的查询包括:获取所述第一参数分别与预设的第一阈值和第二阈值进行比较后的第一比较结果,并依据所述第一比较结果确定是否将所述数据库查询SQL拆分为多个子SQL;在确定是否拆分为多个子SQL之后,获取所述第二参数与所述第三参数之间较小的参数,并将所述较小的参数分别与预设的第三阈值和第四阈值进行比较,得到第二比较结果,并依据所述第二比较结果随机选择指定索引查询方式进行查询或全表扫描查询方式进行查询。
进一步地,依据所述第一比较结果确定是否将所述数据库查询SQL拆分为 多个子SQL包括:在所述第一比较结果小于等于所述第一阈值时,拆分为多个子SQL;或,在所述第一比较结果大于等于所述第二阈值时,不拆分为多个子SQL;或,在所述第一比较结果大于所述第一阈值且小于所述第二阈值时,随机选择是否拆分为多个子SQL;依据所述第二比较结果确定采用指定索引查询或全表扫描查询包括:在所述第二比较结果小于等于所述第三阈值时,采用指定索引查询;或,在所述第二比较结果大于等于第四阈值时,采用全表扫描查询;或,在所述第二比较结果大于所述第三阈值且小于所述第四阈值时,随机选择所述指定索引查询或所述全表扫描查询。
进一步地,在依据所述指定参数与预定阈值的比较结果执行对所述数据库的查询之后,所述方法还包括:保存所述用于指示查询所述数据库数据的所述多个参数,以及采用当前的查询类型查询所述数据库的耗时。
进一步地,在保存所述用于指示查询所述数据库数据的所述多个参数,以及采用当前的查询类型查询所述数据库的耗时之后,所述方法还包括:获取本地保存的与查询类型对应的查询耗时,其中,所述查询类型包括:所述全表扫描查询和所述指定索引查询;比较多个所述查询耗时,并按照比较结果调整所述第一阈值、所述第二阈值、所述第三阈值以及所述第四阈值的取值。
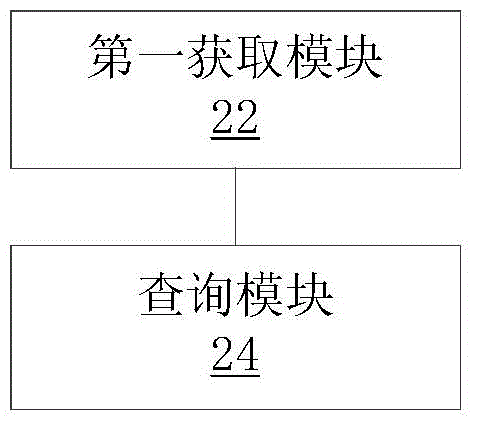
根据本发明的另一个方面,提供了一种数据库的查询装置,包括:第一获取模块,用于获取用于指示查询数据库的查询场景的多个参数:查询模块,用于依据所述多个参数进行综合决策,并按照与决策结果对应的查询类型执行对所述数据库的查询。
进一步地,所述第一获取模块包括:第一获取单元,用于获取第一预设统计时间内查询条件中限制返回的数据量与从所述数据库查询的数据总量之比的第一参数;第二获取单元,用于获取在第二预设统计时间内所述数据库内需要查询的数据索引范围与所述数据库中所有数据的索引范围之比的第二参数;第三获取单元,用于获取在第三预设统计时间内查询条件中的数据库分区与总分区之比的第三参数。
进一步地,所述查询模块包括:确定单元,用于获取所述第一参数分别与预设的第一阈值和第二阈值进行比较后的第一比较结果,并依据所述第一比较结果确定是否将所述数据库查询SQL拆分为多个子SQL;查询单元,用于在确定是否拆分为多个子SQL之后,获取所述第二参数与所述第三参数之间较小的参数,并将所述较小的参数分别与预设的第三阈值和第四阈值进行比较,得到第二比较结果,并依据所述第二比较结果随机选择指定索引查询方式进行查询或全表扫描查询方式进行查询。
进一步地,所述确定单元,还用于在所述第一比较结果小于等于所述第一 阈值时,拆分为多个子SQL;或,在所述第一比较结果大于等于所述第二阈值时,不拆分为多个子SQL;或,在所述第一比较结果大于所述第一阈值且小于所述第二阈值时,随机选择是否拆分为多个子SQL;所述查询单元,还用于在所述第二比较结果小于等于所述第三阈值时,采用指定索引查询;或,在所述第二比较结果大于等于第四阈值时,采用全表扫描查询;或,在所述第二比较结果大于所述第三阈值且小于所述第四阈值时,随机选择所述指定索引查询或所述全表扫描查询。
通过本发明,采用获取用于指示查询数据库的查询场景的多个参数,进而对该多个参数进行综合决策,并按照决策结果对应的查询类型指定对数据库的查询;可见,在本实施例中是通过获取查询场景的多个参数,并不仅仅是用hint来指定数据库进行查询,通过该多个参数的综合决定能够更好的适应场景采用优化的查询的方式,解决了相关技术中对于数据库的查询方式比较单一的问题,提高了数据库的查询效率。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是根据本发明实施例的数据库的查询方法的流程图;
图2是根据本发明实施例的数据库的查询装置结构框图;
图3是根据本发明可选实施例的数据库的查询装置可选结构框图一;
图4是根据本发明可选实施例的数据库的查询装置可选结构框图二;
图5是根据本发明可选实施例的适应使用场景的数据查询算法的流程图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
本实施例提供了一种数据库的查询方法,图1是根据本发明实施例的数据库的查询方法的流程图,如图1所示,该方法的步骤包括:
步骤S102:获取用于指示查询数据库的查询场景的多个参数:
步骤S104:依据多个参数进行综合决策,并按照与决策结果对应的查询类型执行对数据库的查询。
通过本实施例中的上述步骤S102与步骤S104,采用获取用于指示查询数据库的查询场景的多个参数,进而对该多个参数进行综合决策,并按照决策结果对应的查询类型指定对数据库的查询;可见,在本实施例中是通过获取查询场景的多个参数,并不仅仅是用hint来指定数据库进行查询,通过该多个参数的综合决定能够更好的适应场景采用优化的查询的方式,解决了相关技术中对于数据库的查询方式比较单一的问题,提高了数据库的查询效率。
需要说明的是,本实施例中涉及到的该多个参数可以预设获得相应的值,进而可以在使用过程中可以动态调整的。
而对于本实施例中涉及到的获取用于指示查询数据库的查询场景的多个参数的方式,在本实施例的可选实施方式可以通过如下方式来实现:
步骤S11:获取第一预设统计时间内查询条件中限制返回的数据量与从数据库查询的数据总量之比的第一参数;
步骤S12:获取在第二预设统计时间内数据库内需要查询的数据索引范围与数据库中所有数据的索引范围之比的第二参数;
步骤S13:获取在第三预设统计时间内查询条件中的数据库分区与总分区之比的第三参数。
可见,通过上述步骤S11至步骤S13可以获取查询场景中的三个不同参数,但该三个参数仅仅是用来进行举例说明,并不构成对本发明的限定;也就是说,可以根据实际情况获取更多的参数,此外,上述第一预设统计时间、第二预设统计时间以及第三预设统计时间在本可选实施例中可以相等也可以不相等。
在本实施例的另一个可选实施方式中,对于本实施例涉及到的依据多个参数进行综合决策,并按照与决策结果对应的查询类型执行对数据库的查询的方式可以通过如下方式来实现:
步骤S21:获取第一参数分别与预设的第一阈值和第二阈值进行比较后的第一比较结果,并依据第一比较结果确定是否将数据库查询SQL拆分为多个子SQL;
步骤S22:在确定是否拆分多个子SQL之后,获取第二参数与第三参数之间较小的参数,并将较小的参数分别与预设的第三阈值和第四阈值进行比较,得到第二比较结果,并依据第二比较结果随机选择指定索引查询方式进行查询或全 表扫描查询方式进行查询。
通过上述步骤S21和S22,可知,通过第一参数、第二参数以及第三参数与预定阈值进行比较之后,确定是否要对数据库进行拆分,进而确定对于拆分或未拆分的数据库进行指定索引查询或全表扫描查询;通过该方式进一步细化了在对数据库进行查询时考虑的因素,在综合考虑到查询场景的多个参数之后,能够使得查询更加优化。而对于上述步骤S21和S22中具体如何执行对数据库的查询,可以通过如下可选方式来实现;
对于上述步骤S21中的依据第一比较结果确定是否将数据库拆分为多个子SQL可以通过如下方式来实现:在第一比较结果小于等于第一阈值时,拆分为多个子SQL;或,在第一比较结果大于等于第二阈值时,不拆分为多个子SQL;或,在第一比较结果大于第一阈值且小于第二阈值时,随机选择是否拆分为多个子SQL;
而对于上述步骤S22中的依据第二比较结果确定采用指定索引查询或全表扫描查询的方式可以通过如下方式来实现:在第二比较结果小于等于第三阈值时,采用指定索引查询;或,在第二比较结果大于等于第四阈值时,采用全表扫描查询;或,在第二比较结果大于第三阈值且小于第四阈值时,随机选择指定索引查询或全表扫描查询。
可见,在上述步骤S21和S22中给出了一种可选的如何在综合考虑到查询场景的多个参数之后,选取查询方式。
而在上述步骤S22之后,即在依据指定参数与预定阈值的比较结果执行对数据库的查询之后,本实施例的方法还可以包括:保存用于指示查询数据库数据的多个参数,以及采用当前的查询类型查询数据库的耗时。也就是说,每次执行查询之后都会保存查询采用的参数、预定阈值以及查询的耗时。
而对于上述保存的数据,在保存用于指示查询数据库数据的多个参数,以及采用当前的查询类型查询数据库的耗时之后,本实施例的方法还可以包括:
获取本地保存的与查询类型对应的查询耗时,其中,查询类型包括:全表扫描查询和指定索引查询;
比较多个查询耗时,并按照比较结果调整第一阈值、第二阈值、第三阈值以及第四阈值的取值。
也就是说,通过保存的数据,进行比较得出最优或最合适的查询方式为以后的查询提供可靠的依据。
在本实施例中还提供了一种数据库的查询装置,该装置用于实现上述实施例及可选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块” “单元”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
图2是根据本发明实施例的数据库的查询装置结构框图,如图2所示,该装置包括:第一获取模块22,用于获取用于指示查询数据库的查询场景的多个参数:查询模块24,与获取模块22耦合连接,用于依据多个参数进行综合决策,并按照与决策结果对应的查询类型执行对数据库的查询。
图3是根据本发明可选实施例的数据库的查询装置可选结构框图一,如图3所示,该第一获取模块22包括:第一获取单元32,用于获取第一预设统计时间内查询条件中限制返回的数据量与从数据库查询的数据总量之比的第一参数;第二获取单元34,与第一获取单元32耦合连接,用于获取在第二预设统计时间内数据库内需要查询的数据索引范围与数据库中所有数据的索引范围之比的第二参数;第三获取单元36,与第二获取单元34耦合连接,用于获取在第三预设统计时间内查询条件中的数据库分区与总分区之比的第三参数。
图4是根据本发明可选实施例的数据库的查询装置可选结构框图二,如图4所示,查询模块24包括:确定单元42,用于获取第一参数分别与预设的第一阈值和第二阈值进行比较后的第一比较结果,并依据第一比较结果确定是否将数据库查询SQL拆分为多个子SQL;查询单元44,与确定单元42耦合连接,用于在确定是否拆分多个子SQL之后,获取第二参数与第三参数之间较小的参数,并将较小的参数分别与预设的第三阈值和第四阈值进行比较,得到第二比较结果,并依据第二比较结果随机选择指定索引查询方式进行查询或全表扫描查询方式进行查询。
可选地,该确定单元42,还用于在第一比较结果小于等于第一阈值时,拆分为多个子SQL;或,在第一比较结果大于等于第二阈值时,不拆分为多个子SQL;或,在第一比较结果大于第一阈值且小于第二阈值时,随机选择是否拆分为多个子SQL;
可选地,查询单元44,还用于在第二比较结果小于等于第三阈值时,采用指定索引查询;或,在第二比较结果大于等于第四阈值时,采用全表扫描查询;或,在第二比较结果大于第三阈值且小于第四阈值时,随机选择指定索引查询或全表扫描查询。
可选地,本实施例涉及到的装置还可以包括:在依据指定参数与预定阈值的比较结果执行对数据库的查询之后,该装置还包括:保存模块,与查询模块22耦合连接,保存用于指示查询数据库数据的多个参数,以及采用当前的查询类型查询数据库的耗时。
可选地,在保存用于指示查询数据库数据的多个参数,以及采用当前的查询类型查询数据库的耗时之后,该装置还可以包括:第二获取模块,与保存模块耦合连接,用于获取本地保存的与查询类型对应的查询耗时,其中,查询类型包括:全表扫描查询和指定索引查询;
比较模块,与第二获取模块耦合连接,用于比较多个查询耗时,并按照比较结果调整第一阈值、第二阈值、第三阈值以及第四阈值的取值。
下面通过本发明的可选实施例对本发明进行举例说明;
本可选实施例提供了一种自适应使用场景的数据查询算法,通过本可选实施例能够让数据查询随使用场景的变化自动选取优化的方式。
本可选实施例采用了根据查询的类型、查询的索引范围、查询的数据表分区大小、查询的数据量估算与查询返回条数限制的参数,综合评定后选取结构化查询语言(Structured Query Language,简称为SQL)的优化方式,SQL优化方式包括按分区索引拆分子SQL语句、hint选择等,并根据每次查询耗用的时间统计来作为下一次选取优化方式的依据。
下面对于本可选实施例中涉及到的查询的类型、查询的索引范围、查询的数据表分区大小、查询的数据量估算与查询返回条数限制的参数进行说明;
对于本可选实施例的中查询的类型一般有实时查询与统计查询,实时查询对时间要求高、而对返回的数据量有限制;统计查询对时间要求低,但往往要求统计全部的数据。因此,对于这两种查询类型:实时查询更偏重按索引扫描,而统计查询更偏向于分区内的全表扫描。
对于本可选实施例涉及到的查询的索引范围对hint的选择影响比较大,如果查询的索引范围已经达到分区内这个索引全部数据的1/2以上,而且需要返回满足条件的全部数据时,适合于全表扫描;如果查询的索引范围小于分区内这个索引全部数据的1/5时,适合于按索引扫描。对于索引范围占全部范围的1/5至1/2的场景,其效率受数据库服务器、存储设备硬软件配置的影响比较大,那么采用哪种方式,可以更进一步的采用以往查询耗用的时间统计来作为下一次选取优化方式的依据。
此外,需要说明的是对于索引范围难以判断的场景,比如时间索引下的数据缺失、位置索引下的位置变化,适用于采用历史查询耗用的时间统计来作为下一次选取优化方式的依据。
在本可选实施例中对于拆分子SQL的场景,如果有返回条数限制,那么可以依据数据量估算来拆分为子SQL,具体情况例如查询1个月的数据,查询返回条数限制为10万条,而1个月的数据估算有3000万条,那么可以拆分为30 个1天来查询,这样只用查询1天的数据就能满足要求。
而对于本实施例中的查询1周的大量数据,按位置汇总,数据表分区为1天,可以拆分为7个1天的子查询,避免1周大数据汇总带来的响应延迟。
图5是根据本发明可选实施例的适应使用场景的数据查询算法的流程图,如图5所示,基于上述说明,本可选实施例的自适应使用场景的数据查询算法可以通过如下步骤来实现:
步骤S502:获取查询类型,确定参数A,其中,参数A=1为实时查询,A=0为报表统计查询;
步骤S504:判断查询的索引范围,确定参数B,其中,参数B=查询索引范围/所有数据范围,如数据表保存1个月数据,按时间索引,查询1天数据,则B=1/30;
步骤S506:判断是否分区,及分区大小,确定参数C;其中,如该数据表没有分区,则C=1,如果有分区且按时间分区、分区大小为1周,查询条件中时间范围是1天,则C=1/7;
步骤S508:判断查询是否有返回条数限制,以及查询条件中时间范围内的数据量估算,确定参数D。比如所查询的数据表1天数据量估算为100万,而查询返回条数限制为10万,则D=1/10;
步骤S510:按照参数D,当D<=t1时拆分子SQL,当D>=t2时不拆分子SQL,t1<D<t2时随机选择是否拆分子SQL;进而按照value=min(B,C)的值来确定是否采用指定索引的方式:value<=k1时指定索引查询;value>=k2时全表扫描查询;k1<value<k2时,随机采用是否指定索引;
需要说明的是value=min(B,C)该公式表示取B和C中较小的值作为value的值;
步骤S512:保存每次查询使用的参数、t1、t2、k1、k2以及查询耗时;
步骤S514:根据保存的耗时数据、根据参数A的不同分开统计,判断t1、t2、k1、k2的取值是否需要调整。
通过本可选实施例的方式,针对大数据表的数据统计,不用依赖固定的SQL来满足效率优化目的,而是灵活根据实际使用场景采取适当的优化方式,满足业务统计的同时大大提升了查询效率。
以上仅为本发明的可选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!