一种配置寄存器的方法和装置与流程
本发明时间逻辑验证领域,尤指一种配置寄存器的方法和装置。
背景技术:
在集成电路(ASIC,Application Specific Integrated Circuit)芯片设计和现场可编逻辑门阵列(FPGA,Field Programmable Gate Array)设计中,逻辑工程师们按照设计说明书把具体的需求翻译成Verilog代码,在翻译过程中,会由于各种原因导致Verilog代码存在功能性的错误。为了保证设计功能的正确性,通过逻辑验证来定位并改正设计中的错误已成为一种必要手段。
在传统验证方式不断发展的背景,通用验证方法学(UVM,Universal Verification Methodology)的出现,对于提升验证效率有极大的帮助。它是基于开放验证方法学(OVM,Open Verification Methodology)发展而来的新一代验证方法学。在UVM的五步验证流程(即制定验证计划、开发验证平台、大规模激励验证、缩小范围激励验证、特别定制激励验证)中,开发验证平台是最基本的要求,但耗时最多的大规模激励验证阶段便是需要对待验证模块(DUT,Design Under Test)灌输大量的随机数据来保证代码覆盖率和功能覆盖率,这些灌输的激励中就包括了对寄存器的配置。UVM在system verilog的基础上,在实现UVM的库文件中定义了一些在验证平台中经常使用到的基类、宏、和块语句。这些库文件可以直接调用,方便对DUT的验证时定位错误。
随着光通信网络的演化和验证技术(即采用UVM来进行验证)的发展,以及FPGA的库文件与EDA工具编译的兼容性,ASIC芯片验证和FPGA逻辑验证趋向于统一。在这种前提下,光通信网络的硬件逻辑验证时数据流激励和寄存器实时随机配置,在验证平台中变得很重要,也是保障逻辑功能覆盖率的重要方式。一般地,需要添加激励数据并且对DUT内部的寄存器进 行实时改变。在DUT的逻辑设计中,通常都会用到低速总线,比如外围总线(APB,Advanced Peripheral Bus)、串行外围设备接口(SPI,Serial Peripheral Interface)总线、内部集成电路(I2C,Inter-Integrated Circuit)总线等等,我们称之为带配置总线的DUT。这些低速总线会连接到DUT中的待配置寄存器,通过低速总线来配置寄存器。
其中,图1为现有UVM中实现数据流激励的装置的结构组成示意图。如图1所示,实现数据流激励的方法大致包括:
事物处理(Transaction)模块获取目标验证数据包中每一数据包的包结构信息,并将每一数据包的包结构信息以预置参数类型打包发送至第一sequence模块;第一序列(sequence)模块根据每一数据包的包结构信息生成随机数,且将每一数据包对应的所有随机数生成帧数据;第一定序器(sequencer)模块通过预置的事物级建模(TLM,Transaction Level Modeling)端口将帧数据发送给第一驱动(driver)模块;第一driver模块将帧数据打包成字节数据流,并加载到DUT中;第一monitor模块监控DUT的输入数据(即第一driver模块加载到DUT中的数据包),并将DUT的输入数据发送给参考(Reference)模块;Reference模块根据DUT的输入数据完成与DUT相同的功能后,将输出的期望数据信息发送给计分板(scoreboard)模块;第二监控(monitor)模块检测DUT输出的检测数据信息,并发送给scoreboard模块;scoreboard模块对检测数据信息和期望数据信息进行比较。其中,设置好transaction的数据包结构,然后在sequence类中只需设置`uvm_do_on类或`uvm_do_on_with类的循环次数,便可简单地完成大批量随机数据的灌输功能。
其中,包结构信息包括包头、静荷、负载、开销字节位及数据包的约束条件。
其中,transaction模块可以直接派生UVM的库文件中的uvm_sequence_item类得到的transaction类来实现,第一sequence模块可以直接派生UVM的库文件中的uvm_sequence类得到的第一sequence类来实现,第一sequencer模块可以直接派生UVM的库文件中的uvm_sequencer类得到的第一sequencer类来实现,第一driver模块可以直接派生UVM的库文 件中的uvm_driver类得到的第一driver类来实现,Reference模块可以直接派生UVM的库文件中的uvm_Reference类得到的Reference类来实现,第一monitor模块可以直接派生UVM的库文件中的uvm_monitor类得到的第一monitor类来实现,第二monitor模块可以直接派生UVM的库文件中的uvm_monitor类得到的第二monitor类来实现,scoreboard模块可以直接派生UVM的库文件中的uvm_scoreboard类得到的scoreboard类来实现。
在现有实现激励的过程中,配置寄存器的方法大致包括:用户手动将写入寄存器的值输入到force语句中,采用force语句进行层次化的引用来改变寄存器的值。例如,force a.b.c.d=1表示将a模块下的b模块下的c模块下的d寄存器的值改为1。
现有的配置寄存器的方法中,写入寄存器的值需要手动输入,而在验证过程中,为了保证验证的代码覆盖率和功能覆盖率,要求写入寄存器的值随机变化,而现有的配置寄存器的方法很难保证写入寄存器的值的随机变化。
技术实现要素:
为了解决上述问题,本发明提出了一种配置寄存器的方法和装置,能够保证写入寄存器的值的随机变化。
为了达到上述目的,本发明提出了一种配置寄存器的方法,预先设置寄存器和地址之间的对应关系,该方法包括:
生成随机数,根据对应关系和生成的随机数生成对寄存器的写控制指令;
根据写控制指令将生成的随机数写入寄存器中。
优选地,还包括:
根据所述对应关系生成对所述寄存器的读控制指令;
根据所述读控制指令读取所述寄存器。
优选地,所述方法和实现数据流激励的方法封装到顶层平台文件中,并在case类中实例化所述顶层平台文件。
本发明还提出了一种配置寄存器的装置,至少包括:
设置模块,用于预先设置寄存器和地址之间的对应关系;
生成模块,用于生成随机数,根据对应关系和生成的随机数生成对寄存器的写控制指令;
控制模块,用于根据写控制指令将生成的随机数写入寄存器中。
优选地,所述生成模块还用于:
根据所述对应关系生成对所述寄存器的读控制指令;
所述控制模块还用于:
根据所述读控制指令读取所述寄存器。
优选地,所述装置和实现数据流激励的装置封装到顶层平台文件中,并在case类中实例化所述顶层平台文件。
与现有技术相比,本发明包括:生成随机数,根据预先设置的对应关系和生成的随机数生成对寄存器的写控制指令;根据写控制指令将生成的随机数写入寄存器中。通过本发明的方案,根据生成的写控制指令将生成的随机数写入寄存器中,保证了写入寄存器的值的随机变化。
附图说明
下面对本发明实施例中的附图进行说明,实施例中的附图是用于对本发明的进一步理解,与说明书一起用于解释本发明,并不构成对本发明保护范围的限制。
图1为现有UVM中实现数据流激励的装置的结构组成示意图;
图2为本发明配置寄存器的方法的流程图;
图3为本发明配置寄存器的装置的结构组成示意图;
图4为本发明实施例配置寄存器的装置的结构组成示意图。
具体实施方式
为了便于本领域技术人员的理解,下面结合附图对本发明作进一步的描 述,并不能用来限制本发明的保护范围。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的各种方式可以相互组合。
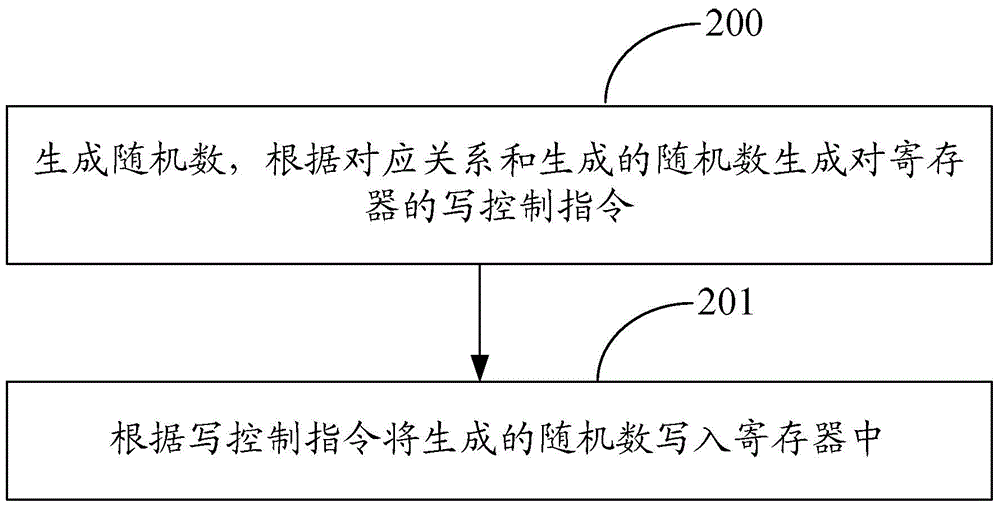
参见图2,本发明提出了一种配置寄存器的方法,预先设置寄存器和地址之间的对应关系。
其中,对应关系中的寄存器为DUT中的寄存器。
寄存器可以采用寄存器的标识来表示,例如,寄存器的名称等。
该方法包括:
步骤200、生成随机数,根据对应关系和生成的随机数生成对寄存器的写控制指令。
本步骤中,写控制指令中包含有要进行写操作的寄存器及其对应的地址、生成的随机数。
本步骤中,可以在数据流激励的过程中生成随机数。
本步骤中,可以根据实际需要多次生成虽极少数。
本步骤中,可以采用随机数生成函数来生成随机数,具体实现属于本领域技术人员的公知技术,并不用于限定本发明的保护范围,这里不再赘述。
步骤201、根据写控制指令将生成的随机数写入寄存器中。
该方法还包括:
根据对应关系生成对寄存器的读控制指令;根据读控制指令读取寄存器。
通过本发明的方案,根据生成的写控制指令将生成的随机数写入寄存器中,保证了写入寄存器的值的随机变化。
本发明的方法中,可以将配置寄存器的方法和实现数据流激励的方法封装到顶层平台文件中,在case类中实例化顶层平台文件。
其中,可以在整个验证平台的基础上派生出case类。
参见图3,本发明还提出了一种配置寄存器的装置,至少包括:
设置模块,用于预先设置寄存器和地址之间的对应关系;
生成模块,用于生成随机数,根据对应关系和生成的随机数生成对寄存器的写控制指令;
控制模块,用于根据写控制指令将生成的随机数写入寄存器中。
本发明的装置中,生成模块还用于:
根据对应关系生成对寄存器的读控制指令;
控制模块还用于:
根据读控制指令读取寄存器。
其中,配置寄存器的装置和实现数据流激励的装置封装到顶层平台文件中,并在case类中实例化顶层平台文件。
下面通过具体实施例详细说明本发明的方法。
图4为配置寄存器的装置的结构组成示意图。如图4所示,配置寄存器的方法包括:
寄存器模型(Reg_model)模块中预先设置有寄存器和地址之间的对应关系。
第二sequence模块生成随机数,根据对应关系和生成的随机数生成对寄存器的写控制指令,将生成的写控制指令发送给第一适应(adapter)模块;第一adapter模块将写控制指令转换成第二sequencer模块能够识别的格式;第二sequencer模块将转换后的写控制指令发送给第二driver模块;第二driver模块根据转换后的写控制指令控制DUT将生成的随机数写入寄存器中。
第二sequence模块根据对应关系生成对寄存器的读控制指令,将生成的读控制指令发送给第一adapter模块;第一adapter模块将读控制指令转换成第二sequencer模块能够识别的格式;第二sequencer模块将转换后的读控制指令发送给第二driver模块;第二driver模块根据转换后的读控制指令控制DUT读取寄存器;第三monitor模块检测DUT读取寄存器的输出数据;predictor模块将输出数据发送给第二adapter模块;第二adapter模块将输出数据转换成reg_model模块或scoreboard模块能够识别的格式后发送给reg_model模块或scoreboard模块。
其中、第二sequencer模块、第二driver模块和第三monitor模块模拟了APB总线的功能。
其中,可以采用派生自UVM中的sequence类的Virtual sequence类来实例化第二sequence模块和第一sequence模块。
其中,可以将配置寄存器的装置中的所有模块和实现数据流激励的装置中的所有模块封装到顶层平台文件中,并在顶层平台文件中实例化Virtual sequencer,采用在整个验证平台基础上派生出来的case类中实例化顶层平台文件。
其中,Virtual sequencer中同时实例化第一sequence类、第一sequencer类、第二sequence类、第二sequencer类来实现数据流激励和寄存器配置的同步。
也可以通过脚本调用的形式来实现寄存器的配置。
其中,reg_model模块可以直接派生UVM的库文件中的uvm_reg_model类得到的reg_model类来实现,第二sequence模块可以直接派生UVM的库文件中的uvm_sequence类得到的第二sequence类来实现,第一adapter模块可以直接派生UVM的库文件中的uvm_adapter类得到的第一adapter类来实现,第二sequencer模块可以直接派生UVM的库文件中的uvm_sequencer来得到的第二sequencer类来实现,第二driver模块可以直接派生UVM的库文件中的uvm_driver类得到的第二driver类来实现,第三monitor模块可以直接派生UVM的库文件中的uvm_monitor类得到的第三monitor类来实现,predictor模块可以直接派生UVM的库文件中的uvm_predictor类得到的predictor类来实现,第二adapter模块可以直接派生UVM的库文件中的uvm_adapter类得到的第二adapter类来实现。
需要说明的是,以上所述的实施例仅是为了便于本领域的技术人员理解而已,并不用于限制本发明的保护范围,在不脱离本发明的发明构思的前提下,本领域技术人员对本发明所做出的任何显而易见的替换和改进等均在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!