一种特征词提取方法及装置与流程
本发明涉及推荐系统领域,尤其涉及一种特征词提取方法及装置。
背景技术:
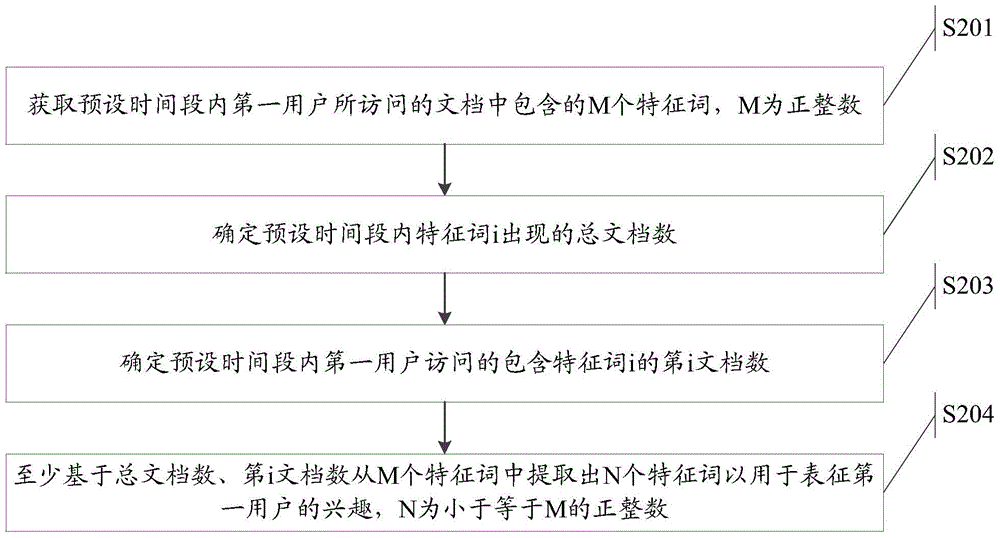
:如今已经进入了一个数据爆炸的时代,随着互联网的发展,Web已经变成数据分享的平台。人们在海量的数据中找到需要的信息,变得越来越难,推荐系统则应运而生。推荐系统主要使用基于协同过滤的推荐方法或基于内容的推荐方法。协同过滤是一种基于一组兴趣相同的用户或项目进行的推荐,它根据邻居用户(与目标用户兴趣相似的用户)的偏好信息产生对目标用户的推荐列表。在新闻推荐中,常采用基于内容的推荐方法。如图1所示,为现有技术中推荐系统基于内容进行信息推荐的流程图,其具体包括以下步骤:步骤S101:收集用户消费数据;步骤S102:从用户消费数据中提取用户在预设时间段内消费的特征词;步骤S103:计算每个特征词的IUF(InverseUserFrequency:逆向用户数频率);步骤S104:计算每个特征词的TF(termfrequency:词频);步骤S105:计算用户针对每个特征词的偏好权重,该偏好权重具体计算公式为:IUF*TF。采用现有技术的方案,能够提取出热点类特征词,但是对于非热点类的特征词的提取则不够准确,往往会遗漏。因为非热点类特征词的相关内容少、PV(pageview:页面浏览量)少,从而容易被遗漏掉。技术实现要素:本发明提供一种特征词提取方法及装置,以解决现有技术中对于非热点类特征词提取不够准确的技术问题。第一方面,本发明实施例提供一种特征词提取方法,包括:获取预设时间段内第一用户所访问的文档中包含的M个特征词,M为正整数;确定所述预设时间段内特征词i出现的总文档数,i为1至M的整数;确定所述预设时间段内所述第一用户访问的包含所述特征词i的第i文档数;至少基于所述总文档数、所述第i文档数从所述M个特征词中提取出N个特征词以用于表征所述第一用户的兴趣,N为小于等于M的正整数。可选的,在所述至少基于所述总文档数、所述第i文档数从所述M个特征词中提取出N个特征词之前,所述方法还包括:确定在所述预设时间段内访问特征词i的所有用户数的倒数值;所述至少基于所述总文档数、所述第i文档数从所述M个特征词中提取出N个特征词,具体为:至少基于所述总文档数、所述第i文档数、所述倒数值从所述M个特征词中提取出所述N个特征词。可选的,所述至少基于所述总文档数、所述第i文档数、所述倒数值从所述M个特征词中提取出N个特征词,具体包括:至少基于所述总文档数、所述第i文档数、所述倒数值确定各个特征词i的兴趣权重;从所述M个特征词中通过所述兴趣权重提取出所述N个特征词。可选的,所述兴趣权重通过以下公式计算获得:weight(i)=IUF(i)*dftotaldf]]>其中,IUF(i)表示所述倒数值;df表示所述第一用户访问的包含所述特征词i的第i文档数;totaldf表示所述特征词i出现的总文档数。可选的,所述方法还包括:确定所述第一用户访问特征词i的访问方式权重;至少基于所述总文档数、所述第i文档数、所述倒数值和所述访问方式权重通过以下公式确定各个特征词i的兴趣权重:weight(i)=IUF(i)*dftotaldf*access(i)]]>其中,IUF(i)表示所述倒数值;df表示所述第一用户访问的包含所述特征词i的第i文档数;totaldf表示所述特征词i出现的总文档数;access(i)表示所述第一用户访问特征词i的访问方式权重。可选的,从所述M个特征词中通过所述兴趣权重提取出所述N个特征词,具体为:从所述M个特征词中提取出兴趣权重高的前N个特征词作为所述N个特征词;或分别计算特征词i在多个所述预设时间段内的兴趣权重,将计算得到的多个兴趣权重进行加和,从所述M个特征词中提取出所述加和的和值位于前N位的特征词作为所述N个特征词。可选的,在所述至少基于所述总文档数、所述第i文档数从所述M个特征词中提取出N个特征词之后,所述方法还包括:从所述N个特征词中去除满足预设规则的特征词。可选的,所述从所述N个特征词中去除满足预设规则的特征词,具体包括:从所述N个特征词中去除所述第一用户的访问天数小于预设天数的特征词;和/或从所述N个特征词中去除所述第一用户的访问次数小于预设次数的特征词。第二方面,本发明实施例提供一种特征词提取装置,包括:获取模块,用于获取预设时间段内第一用户所访问的文档中包含的M个特征词,M为正整数;第一确定模块,用于确定所述预设时间段内特征词i出现的总文档数,i为1至M的整数;第二确定模块,用于确定所述预设时间段内所述第一用户访问的包含所述特征词i的第i文档数;提取模块,用于至少基于所述总文档数、所述第i文档数从所述M个特征词中提取出N个特征词以用于表征所述第一用户的兴趣,N为小于等于M的正整数。可选的,所述装置还包括:第三确定模块,用于确定在所述预设时间段内访问特征词i的所有用户数的倒数值;所述提取模块,具体用于:至少基于所述总文档数、所述第i文档数、所述倒数值从所述M个特征词中提取出所述N个特征词。可选的,所述提取模块,具体包括:第一确定单元,用于至少基于所述总文档数、所述第i文档数、所述倒数值确定各个特征词i的兴趣权重;提取单元,用于从所述M个特征词中通过所述兴趣权重提取出所述N个特征词。可选的,所述提取单元,具体用于:从所述M个特征词中提取出兴趣权重高的前N个特征词作为所述N个特征词;或分别计算特征词i在多个所述预设时间段内的兴趣权重,将计算得到的多个兴趣权重进行加和,从所述M个特征词中提取出所述加和的和值位于前N位的特征词作为所述N个特征词。可选的,所述装置还包括:去除模块,用于从所述N个特征词中去除满足预设规则的特征词。本发明有益效果如下:由于在本发明实施例中,首先获取预设时间段内第一用户所访问的文档中包含的M个特征词,M为正整数;然后确定预设时间段内特征词i出现的总文档数,i为1至M的整数;接着确定预设时间段内第一用户访问的包含特征词i的第i文档数;最后至少基于总文档数、第i文档数从M个特征词中提取出N个特征词以用于表征第一用户的兴趣,N为小于等于M的正整数。也就是在从M个特征词中提取出N个特征词时,会考虑每个特征词出现的总文档数、第一用户访问对应特征词所对应的文档数,从而对于非热点的特征词也能够进行准确的提取,从而能够提高非热点类特征词作为用户兴趣的召回率。附图说明图1为现有技术中提取用户的偏好权重的流程图;图2为本发明实施例中特征词提取方法的流程图;图3为本发明实施例特征词提取方法中从M个特征词中提取出N个特征词的流程图;图4为本发明实施例中特征词提取装置的结构图。具体实施方式本发明提供一种特征词提取方法及装置,以解决现有技术中对于非热点类特征词提取不够准确的技术问题。本申请实施例中的技术方案为解决上述的技术问题,总体思路如下:首先获取预设时间段内第一用户所访问的文档中包含的M个特征词,M为正整数;然后确定预设时间段内特征词i出现的总文档数,i为1至M的整数;接着确定预设时间段内第一用户访问的包含特征词i的第i文档数;最后 至少基于总文档数、第i文档数从M个特征词中提取出N个特征词以用于表征第一用户的兴趣,N为小于等于M的正整数。也就是在从M个特征词中提取出N个特征词时,会考虑每个特征词出现的总文档数、第一用户访问对应特征词所对应的文档数,从而对于非热点的特征词也能够进行准确的提取,从而能够提高非热点类特征词作为用户兴趣的召回率。为了更好的理解上述技术方案,下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本发明实施例以及实施例中的具体特征是对本发明技术方案的详细的说明,而不是对本发明技术方案的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互组合。第一方面,本发明实施例提供一种特征词提取方法,请参考图2,包括:步骤S201:获取预设时间段内第一用户所访问的文档中包含的M个特征词,M为正整数;步骤S202:确定预设时间段内特征词i出现的总文档数;步骤S203:确定预设时间段内第一用户访问的包含特征词i的第i文档数;步骤S204:至少基于总文档数、第i文档数从M个特征词中提取出N个特征词以用于表征第一用户的兴趣,N为小于等于M的正整数。步骤S201中,所述预设时间段例如为:1天、半天、1周等等,可以根据实际需求设置不同的所述预设时间段,对此本发明实施例不再详细列举,并且不做限制。其中,可以以预设时间段(例如:天)为单位对用户所访问的数据进行分析,进而抽取其中所包含的特征词。其中,在对用户所访问的数据进行分析时,为了提高分析速率,可以仅仅分析用户所访问的数据的标题;而为了提高分析的全面性,则还可以分析数据的摘要、全文等等。步骤S202中,可以针对所有用户,搜集整理所有用户所访问的文档,然后判断每篇文档中是否包含特征词i,进而获得预设时间段内特征词i出现的总文档数。步骤S203中,可以搜集获得第一用户所访问的文档,然后判断每篇文档中是否包含特征词i,进而获得预设时间段内第一用户访问的包含特征词i的第i文档数。步骤S204中,所提取的N个特征词往往表征用户的兴趣特征。其中,可以基于多种参数从M个特征词中提取出N个特征词,下面列举其中的四种进行介绍,当然,在具体实施过程中,不限于以下四种情况。第一种,至少基于总文档数、第i文档数从M个特征词中提取出N个特征词,具体为:基于总文档数、第i文档数从M个特征词中提取出N个特征词。第二种,在至少基于总文档数、第i文档数从M个特征词中提取出N个特征词之前,方法还包括:确定在所述预设时间段内访问特征词i的所有用户数的倒数值;至少基于总文档数、第i文档数从M个特征词中提取出N个特征词,具体为:基于总文档数、第i文档数、倒数值从M个特征词中提取出N个特征词。举例来说,可以统计每个用户所访问的特征词,然后逐一判断每个用户所访问的特征词中是否包含特征词i,进而可以获取访问特征词i的所有用户数,然后对访问特征词i的所有用户数取倒数,就可以获得在所述预设时间段内访问特征词i的用户数的倒数值。由于在上述方案中,在从M个特征词中筛选出N个特征词时,需要考虑到访问每个特征词的用户数的倒数值,从而所确定出的N个特征词更加准确。第三种,在基于总文档数、第i文档数从M个特征词中提取出N个特征词之前,方法还包括:确定第一用户访问第i关键词的访问方式权重;至少基于总文档数、第i文档数从M个特征词中提取出N个特征词,具体包括:基于总文档数、第i文档数和访问方式权重,从M个特征词中筛选出N 个特征词。举例来说,在统计第一用户所访问的特征词i的文档数的同时,还可以统计第一用户访问特征词i所对应的文档的访问方式,该访问方式例如为:通过收藏夹访问、通过关键词访问、通过热点新闻访问等等,针对不同的访问方式可以设置不同的权重,例如:通过收藏夹访问的权重为0.5、通过关键词访问的权重为0.3、通过热点新闻访问的权重为0.2,当然也可以根据实际需求设置其他的权重,本发明实施例不再详细列举,并且不作限制。然后确定出第一用户访问特征词i时,每种访问途径所对应的访问次数,例如如表1所示:表1访问途径收藏夹关键词热点新闻次数10125则将对应的访问次数按照访问方式的权重进行加和,就可以获得第一用户访问特征词i的访问方式权重,例如,所获得的访问方式权重为:access(i)=10*0.5+12*0.3+5*0.2=9.6………………………………[1]当然,在具体实施过程中,基于访问次数和每种访问途径的权重不同,从而所获得权重值也不同,对此本发明实施例不再详细列举,并且不作限制。由于在上述方案中,在从M个特征词中提取出N个特征词时,需要考虑第一用户访问特征词i所对应的文档的访问方式,而不用的访问方式往往表征用户的喜好程度也不同,故而通过该方案能够更加准确的提取出特征词。第四种,在基于总文档数、第i文档数从M个特征词中提取出N个特征词之前,方法还包括:确定在所述预设时间段内访问特征词i的用户数的倒数值;确定第一用户访问特征词i的访问方式权重;至少基于总文档数、第i文档数、倒数值和访问方式权重确定各个特征词i的兴趣权重。由于在上述方案中,在计算获得兴趣权重时需要考虑特征词i出现的总文 档数的倒数,故而可以提高第一用户长尾兴趣所对应的特征词的召回率。作为进一步的优选实施例,步骤S204中至少基于总文档数、第i文档数从M个特征词中提取出N个特征词,请参考图3,具体包括:步骤S301:至少基于总文档数、第i文档数确定M个特征词中每个特征词的兴趣权重;步骤S302:从M个特征词中通过兴趣权重筛选出N个特征词。步骤S301中基于从M个特征词中提取出N个特征词的参数不同,计算兴趣权重的方式也不同,下面基于前面所列举的四种参数分别进行介绍。第一种,兴趣权重通过以下公式计算获得:weight(i)=dftotaldf...[2]]]>其中,df表示第一用户访问的包含所述特征词i的第i文档数;totaldf表示特征词i出现的总文档数。第二种,兴趣权重通过以下公式计算获得:weight(i)=IUF(i)*dftotaldf...[3]]]>其中,IUF(i)表示倒数值;df表示第一用户访问的包含所述特征词i的第i文档数;totaldf表示特征词i出现的总文档数。第三种,兴趣权重通过以下公式计算获得:weight(i)=dftotaldf*access(i)...[4]]]>其中,df表示第一用户访问的包含所述特征词i的第i文档数;totaldf表示特征词i出现的总文档数;access(i)表示特征词i的访问方式权重。第四种,兴趣权重通过以下公式计算获得:weight(i)=IUF(i)*dftotaldf*access(i)...[5]]]>其中,IUF(i)表示倒数值;df表示第一用户访问的包含所述特征词i的第i文档数;totaldf表示特征词i出现的总文档数;access(i)表示特征词的访问方式权重。步骤S302中,在通过兴趣权重筛选出N个特征词时,又可以采用多种方式,下面列举其中的两种进行介绍,当然,在具体实施过程中,不限于以下两种情况。第一种,从M个特征词中通过兴趣权重筛选出N个特征词,具体为:从M个特征词中筛选出兴趣权重高的前N个特征词作为所述N个特征词。举例来说,可以计算出M个特征词中每个特征词的兴趣权重,然后将其按照从高到低的顺序排列,最后筛选出位于前N位的特征词,通过该方案所筛选出的兴趣权重能够较好的反映出第一用户的当前兴趣。第二种,从M个特征词中通过兴趣权重筛选出N个特征词,具体为:分别计算特征词i在多个所述预设时间段内的兴趣权重,将计算得到的多个兴趣权重进行加和,从所述M个特征词中提取出所述加和的和值位于前N位的特征词作为所述N个特征词。举例来说,多个预设时间段例如为:3个、5个等等,其中在每个预设时间段内针对每个特征词都会计算兴趣权重,然后获得多个兴趣权重,进而可以针对每个特征词的在多个预设时间段内的兴趣权重求和获得和值;然后将和值按照从高到底的顺序排列,进而筛选出位于前N位的特征词,作为反应第一用户的兴趣特征的N个特征词。通过上述方案能够保证所提取出的特征词不受热点事件的影响,能够较好的反应第一用户的兴趣特征;例如:如果第一用户在特征词i的非热点时间内,也会访问特征词i,则其兴趣权重相较于在非热点时间没有访问特征词i的用户会高,进而其综合的兴趣权重的和值也会较高,而其他用户仅仅在特征词i的热点时间会访问特征词i,但是由于其在非热点事件不会访问,所以其综合的兴趣权重的和值也不会太 高,从而能够排除热点事件的干扰。作为进一步的优选实施例,在基于步骤S204筛选出N个特征词之后,方法还包括:从N个特征词中去除满足预设规则的特征词。其中,可以通过多种预设规则对N个特征词进行筛选,下面列举其中的两种预设规则,当然,在具体实施过程中,不限于以下两种情况。第一种,从N个特征词中去除第一用户的访问天数小于预设天数的特征词。举例来说,在获得N个特征词之后,可以统计某一预设时间段(例如:1个月、3个月、半年等等),第一用户访问每个特征词的访问天数,如果访问天数不小于预设天数,则说明第一用户对对应的特征词比较感兴趣,如果访问天数小于预设天数,则说明第一用户对对应的特征词不太感兴趣,故而需要将对应的特征词从N个特征词中去除,可以根据实际需求设置不同的预设天数,例如:3天、5天等等,本发明实施例不再详细列举并且不作限制。第二种,从N个特征词中去除第一用户的访问次数小于预设次数的特征词。举例来说,在获得N个特征词之后,可以统计某一预设时间段(例如:1个月、3个月、半年等等),第一用户访问每个特征词的访问次数,如果访问次数不小于预设次数,则说明第一用户对对应的特征词比较感兴趣,如果访问次数小于预设次数,则说明第一用户对对应的特征词不太感兴趣,故而需要将对应的特征词从N个特征词中去除,可以根据实际需求设置不同的预设次数,例如:3天、5天等等,本发明实施例不再详细列举并且不作限制。优选的,本发明中的特征词为实体词。通常情况下,实体词指的是能够用于描述用户兴趣的特征词。其中,实体词通常具备以下条件:①名词;②指代明确;③非大众;④非小众,下面将对上述四种条件分别进行介绍。①名词:通常情况下,用户兴趣特征中的关键词基本上都是名词,如:汽车、电影、体育,但并非所有名词均适合用作描述用户兴趣,如:人们、集团、 友情。通常情况下,实体词主要包括专有名词、个体名词和物质名词,而集体名词、抽象名词基本不是实体词。②指代明确:汉语是一个灵活百变的语言,往往一个词包含有多个含义,如苹果(食物/数码产品)、火箭(航天器/nba球队),用作用户兴趣必须要指代明确,所以在本发明实施例中将所有特征词分成若干类别,单独为每个类别抽取实体词。结合类别实体词指代便明确了,如:美食.苹果和数码.苹果、军事.火箭和nba.火箭。③非大众:抽象名词、集体名词是人们对于名词基于已有知识的划分,但对于计算机却无法识别,也无法反应用户的兴趣特征,而从大量新闻语料中发现这类词分布广出现频率高,故而可以通过这种分布特征去除;④非小众:此处的小众指的是满足上述条件后各垂直类别内部出现频率很低的特征词。去除此部分词的原因不是因为小众词一定不是实体词,而是因为该类词数据采样不足,引入该类词同时会引入更多的噪音。第二方面,基于同一发明构思,本发明实施例提供一种特征词提取装置,请参考图4,包括:获取模块40,用于获取预设时间段内第一用户所访问的文档中包含的M个特征词,M为正整数;第一确定模块41,用于确定所述预设时间段内特征词i出现的总文档数,i为1至M的整数;第二确定模块42,用于确定所述预设时间段内所述第一用户访问的包含所述特征词i的第i文档数;提取模块43,用于至少基于所述总文档数、所述第i文档数从所述M个特征词中提取出N个特征词以用于表征所述第一用户的兴趣,N为小于等于M的正整数。可选的,所述装置还包括:第三确定模块,用于确定在所述预设时间段内访问特征词i的所有用户数 的倒数值;所述提取模块43,具体用于:至少基于所述总文档数、所述第i文档数、所述倒数值从所述M个特征词中提取出所述N个特征词。可选的,所述提取模块43,具体包括:第一确定单元,用于至少基于所述总文档数、所述第i文档数、所述倒数值确定各个特征词i的兴趣权重;提取单元,用于从所述M个特征词中通过所述兴趣权重提取出所述N个特征词。可选的,所述第一确定单元用于通过以下公式计算获得所述兴趣权重:weight(i)=IUF(i)*dftotaldf]]>其中,IUF(i)表示所述倒数值;df表示所述第一用户访问的包含所述特征词i的第i文档数;totaldf表示所述特征词i出现的总文档数。可选的,所述装置还包括:第四确定模块,用于确定所述第一用户访问特征词i的访问方式权重;第五确定模块,用于至少基于所述总文档数、所述第i文档数、所述倒数值和所述访问方式权重通过以下公式确定各个特征词i的兴趣权重:weight(i)=IUF(i)*dftotaldf*access(i)]]>其中,IUF(i)表示所述倒数值;df表示所述第一用户访问的包含所述特征词i的第i文档数;totaldf表示所述特征词i出现的总文档数;access(i)表示所述第一用户访问特征词i的访问方式权重。可选的,所述提取单元,具体用于:从所述M个特征词中提取出兴趣权重高的前N个特征词作为所述N个特 征词;或分别计算特征词i在多个所述预设时间段内的兴趣权重,将计算得到的多个兴趣权重进行加和,从所述M个特征词中提取出所述加和的和值位于前N位的特征词作为所述N个特征词。可选的,所述装置还包括:去除模块,用于从所述N个特征词中去除满足预设规则的特征词。可选的,所述去除模块,具体用于:从所述N个特征词中去除所述第一用户的访问天数小于预设天数的特征词;和/或从所述N个特征词中去除所述第一用户的访问次数小于预设次数的特征词。本发明一个或多个实施例,至少具有以下有益效果:由于在本发明实施例中,首先获取预设时间段内第一用户所访问的文档中包含的M个特征词,M为正整数;然后确定预设时间段内特征词i出现的总文档数,i为1至M的整数;接着确定预设时间段内第一用户访问的包含特征词i的第i文档数;最后至少基于总文档数、第i文档数从M个特征词中提取出N个特征词以用于表征第一用户的兴趣,N为小于等于M的正整数。也就是在从M个特征词中提取出N个特征词时,会考虑每个特征词出现的总文档数、第一用户访问对应特征词所对应的文档数,从而对于非热点的特征词也能够进行准确的提取,从而能够提高非热点类特征词作为用户兴趣的召回率。本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产 品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的嵌入式控制器以产生一个机器,使得通过计算机或其他可编程数据处理设备的嵌入式控制器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1