一种精确计算铁水脱硫用镁粉量的方法与流程
本发明涉及一种精确计算铁水脱硫用镁粉量的方法,属于铁水预处理技术领域。
背景技术:
通常,硫是钢中的有害元素,铁水进入转炉之前须进行脱硫预处理,复合喷吹法是主要的铁水脱硫工艺之一,常用的脱硫剂为镁粉,其用量由铁水预处理脱硫目标硫含量和铁水条件所决定。传统的镁粉用量确定方法通过人工查询脱硫剂用量静态表得到,该表根据历史数据的分析,列出了不同的铁水硫含量、不同的铁水预处理脱硫目标硫所对应的镁粉用量。这种方式不但操作繁琐,劳动强度大,容易查询错误,而且没有系统考虑铁水重量、铁水温度等因素的影响,镁粉用量偏大。
为提高自动化水平,避免人为错误,人们开发了脱硫剂计算模型,如中国专利申请号为201310268262.1公开了“一种脱硫计算方法及其应用的系统”,该方法根据倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量等数据,采用多元线性回归的方法计算出脱硫剂用量,提高了准确性和脱硫成功率。但是该方法采用线性回归方程,不能如实地反映倒罐铁水硫含量和脱硫目标硫含量对脱硫剂用量的影响,而且更为重要的是其参数是固定不变的,无法适应铁水预处理脱硫能力的变化,为避免硫超标,同样存在脱硫剂用量偏高、硫质量过剩的问题。在现有技术中,也有相关的介绍,选取倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫作为输入参数,脱硫剂用量作为输出参数,建立了基于改进BP算法的脱硫剂加入量预报模型,使脱硫命中率达到96.8%。但是当遇到实际铁水条件与学习组中的铁水条件相差较大时,神经网络的计算结果会出现跳跃,导致脱硫剂用量过高或过低。以上方法都不能有效地解决脱硫用镁粉量的精确计算问题,表现为操作繁琐、镁粉用量偏高、计算异常等。因此,迫切的需要一种新的技术方案解决该技术问题。
技术实现要素:
为了解决上述存在的问题,本发明公开了一种精确计算铁水脱硫用镁粉量的方法,该将BP神经网络模型和回归模型相结合,通过历史数据的训练和自学习,确定模型参数,实现对镁粉量的自动、精确计算,解决现有技术中存在的操作繁琐、镁粉用量偏高、计算异常等问题,从而减少镁粉消耗,降低公司生产成本。
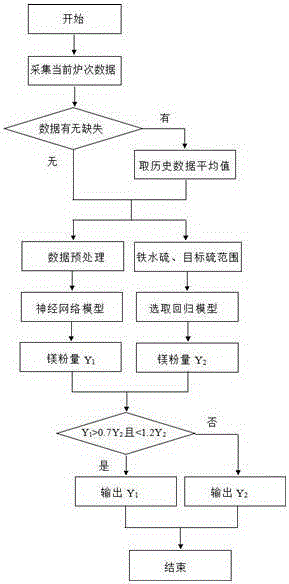
为了实现上述目的,本发明的技术方案如下,一种精确计算铁水脱硫用镁粉量的方法,种精确计算铁水脱硫用镁粉量的方法,其特征在于,所述方法包括以下步骤:
a、采集距离当前炉次最近的历史数据,建立五个样本集U1、U2、U3、U4、U5作为学 习组,U1~U4为样本量均为m的条件样本集,70≤m≤140,判定条件分别为倒罐铁水硫含量<0.03%且脱硫目标硫含量≤0.002%、倒罐铁水硫含量<0.03%且脱硫目标硫含量>0.002%、倒罐铁水硫含量≥0.03%且脱硫目标硫含量≤0.002%、倒罐铁水硫含量≥0.03%且脱硫目标硫含量>0.002%;U5为样本量为n的全样本,40≤n≤100,用于神经网络模型学习;
b、对样本集U5中的数据进行预处理,以消除硫含量、温度、重量数据因数量级不同而对神经网络造成影响,减少神经网络学习时出现平台现象,具体处理方法如下:
式中,x1k~yk为样本集中第k炉的倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量、钢种上限硫含量、镁粉量,x1,min~ymin为样本集中倒罐铁水温度最小值、倒罐铁水重量最小值、倒罐铁水硫含量最小值、脱硫目标硫含量最小值、钢种上限硫含量最小值、镁粉量最小值,x1,max~ymax为样本集中倒罐铁水温度最大值、倒罐铁水重量最大值、倒罐铁水硫含量最大值、脱硫目标硫含量最大值、钢种上限硫含量最大值、镁粉量最大值,为处理后的第k炉的倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量、钢种上限硫含量、镁粉量;
c、建立BP神经网络模型,BP神经网络模型为包含输入层、隐含层和输出层的三层网络,其中输入层用于接收输入信号,其变量为倒罐铁水温度x1、倒罐铁水重量x2、倒罐铁水硫含量x3、脱硫目标硫含量x4、钢种上限硫含量x5;输出层用于输出信号即计算结果,其变量为镁粉量Y1;隐含层的神经节点数f根据公式确定,p为输入层的神经节点数,q为输出层神经节点数,r为1~10之间的常数;本发明p=5,q=1,因此隐含层的神经元节点数f的范围为4~12,若f太小网络不能识别未出现过的样本,容错性差,f太大会使网络复杂化,增加网络的学习时间,出现“过拟合”现象,反而会增大误差;
d、训练BP神经网络模型,根据网络实际输出结果与期望结果的误差,调整神经网络输入层与隐含层的权值wih、隐含层与输出层的权值who、隐含层各神经元的阈值θh、输出层各神经元的阈值θo,使误差减小;权值和阈值的调整方法相同,具体如下:
(1)初始化网络。分别给wih、who、θh、θo赋一个区间(-1,1)内的随机数,设定计算精度值α、最大学习次数T、学习率η,其中学习率影响着网络收敛的速度,以及网络能否收敛。学习率设置偏小可以保证网络收敛,但是收敛速度变慢,训练时间增加。相反,学习率设置偏大则有可能使网络训练不收敛,影响识别效果;
(2)选取样本集U5中经预处理后的第k炉输入样本及对应的期望输出
(3)计算隐含层和输出层各神经元的输入和输出,其中隐含层的输出采用函数
隐含层各神经元输入hih(k)和输出hoh(k),h=1,2,···,9;
输出层各神经元输人yi(k)和输出yo(k),
(4)计算全局误差判断E是否满足要求。如果E>学习精度α时,进入步骤(4)和步骤(5),调整权值和阈值,当E≤α或学习次数t>T时调整结束;
(5)计算误差函数对权值和阈值的偏导数
其中,ek为网络输出误差函数
δh(k)=δo(k)whof'(hih(k))=δo(k)whohih(k)(1-hih(k))
(6)利用迭代法调整权值who(k)、wih(k)和阈值θo、θh,t为学习次数。
e、建立镁粉量的回归计算模型,采用分段多元非线性回归方程,自变量为倒罐铁水温度x1、倒罐铁水重量x2、倒罐铁水硫含量x3、脱硫目标硫含量x4,具体的计算公式为:
当倒罐铁水硫含量x3<0.03%、脱硫目标硫含量x4≤0.002%时:
当倒罐铁水硫含量x3<0.03%、脱硫目标硫含量x4>0.002%时:
当倒罐铁水硫含量x3≥0.03%、脱硫目标硫含量x4≤0.002%时:
Y2=c0+c1×x1+c2×x2+c3×x3+c4×x4
当倒罐铁水硫含量x3≥0.03%、脱硫目标硫含量x4>0.002%时:
f、利用样本集U1~U4中的数据分别计算参数a0~a5、b0~b6、c0~c4、d0~d5,在计算时脱硫目标硫含量x4用脱硫后硫含量x6代替;
计算a0~a5的公式如下,其中x1i、x2i、x3i、x6i为样本集U1中第i炉的x1、x2、x3、x6:
计算b0~b6的公式如下,其中x1i、x2i、x3i、x6i为样本集U2中第i炉的x1、x2、x3、x6:
计算c0~c4的公式如下,其中x1i、x2i、x3i、x6i为样本集U3中第i炉的x1、x2、x3、x6:
计算d0~d5的公式如下,其中x1i、x2i、x3i、x6i为样本集U4中第i炉的x1、x2、x3、x6:
g、计算神经网络模型的镁粉量Y1,当收到铁水预处理作业开始信号后,采集当前炉次的倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量、钢种上限硫含量等数据,输入至已训练好的神经网络模型中,输出层的输出值经变换后得到镁粉量Y1,
h、计算回归模型的镁粉量Y2,判断倒罐铁水硫含量是否<0.03%、脱硫目标硫含量是否≤0.002%,根据判定结果选择选择相应的回归方程,并将倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量代入方程中,计算得出镁粉量Y2;
i、输出镁粉量的最终结果,用回归模型计算的镁粉量判定神经网络模型计算的镁粉量是否合适,以防止神经网络出现局部极小或极大值,具体判定逻辑为,当0.7Y2<Y1<1.2Y2时,取神经网络模型的镁粉量计算值Y1,否则取回归模型的镁粉量计算值Y2;j、更新学习组,当前炉次结束后,判断当前炉次是否符合进入学习组的条件,判定条件为:倒罐铁水硫含量在0.005~0.1%、倒罐铁水温度在1201~1480℃、倒罐铁水重量在(转炉公称吨位-15)~(转炉公称吨位+25)t、脱硫后硫含量在0.0005~0.015%、镁粉利用率在15~65%,若符合条件,替换回归模型学习样本集U1、U2、U3、U4和神经网络模型的学习样本集U5中的最旧的炉次,保持样本数不变,其中,当前炉次进入U1、U2、U3、U4中的哪一个样本集,根据倒罐铁水硫含量和脱硫目标硫含量的大小而定;
k、模型重新启动学习,当回归模型学习样本集U1、U2、U3、U4每更新1炉,返回步骤f,重新计算参数a0~a5、b0~b6、c0~c4、d0~d5。当神经网络模型样本集U5每更新5炉,返回步骤d,重新训练网络,以确保计算得到的镁粉用量自动适应铁水预处理脱硫能力的变化。
作为本发明的一种改进,所述步骤a中,为防止含有异常数据的炉次进入学习组U1~U5,采集距离当前炉次最近的历史数据时,对炉次进行筛选,筛选条件包括:倒罐铁水硫含量0.005~0.1%、倒罐铁水温度在1201~1480℃、铁水重量在为:转炉公称吨位-15吨~转炉公称吨位+25吨、脱硫后硫含量在0.0005~0.015%、镁粉利用率在15%~65%。
作为本发明的一种改进,所述步骤a中,镁粉利用率为用于脱硫反应的镁粉量占总镁粉量的比率,计算公式为:(倒罐铁水硫含量-脱硫后硫含量)×倒罐铁水量×0.75÷总镁粉量。
作为本发明的一种改进,所述步骤g中,当倒罐铁水温度、倒罐铁水重量以及倒罐铁水硫含量缺失时,计算样本集U5中距离当前炉次最近的20炉数据的倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量的平均值,将倒罐铁水温度平均值和倒罐铁水重量平均值作为当前炉次的倒罐铁水温度和倒罐铁水重量,将1.1倍的倒罐铁水硫含量平均值作为当前炉次的倒罐铁水硫含量
相对于现有技术,本发明的优点如下,该技术方案将神经网络模型和分段的回归模型相结合,综合了两者的优势,建立了镁粉用量与铁水条件、目标硫含量的关系,实现了镁粉用量的自动计算,解决了人工查询问题,有效地避免了因神经网络学习组覆盖面不广所导致的计算结果异常问题。同时通过神经网络模型和回归模型的自学习,可实现镁粉量的自动调整,适应铁水预处理脱硫能力的变化,确保镁粉量更加精确、合理,控制脱硫后硫含量在目标硫含量附近;通过本技术的运用,复合喷吹脱硫工艺的吨铁镁粉消耗由0.41kg/t降低至0.33kg/t以下。
附图说明
图1为本发明的镁粉量计算过程示意图;
图2为本发明所用的BP神经完了结构图。
具体实施方式
为了加深对本发明的认识和理解,下面结合附图和具体实施方式,进一步阐明本发明。
实施例:
一种精确计算铁水脱硫用镁粉量的方法,包括以下步骤:
a、采集距离当前炉次最近的历史数据,建立五个样本集U1、U2、U3、U4、U5作为学习组,样本的数据内容包括铁水预处理结束时间、铁水处理号、出钢记号、钢种上限硫含量、脱硫目标硫含量、倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量、脱硫后硫含量、镁粉量,样本按铁水预处理结束时间的降序进行排序。U1~U4为样本量均为m的条件样本集,判定条件分别为倒罐铁水硫含量<0.03%且脱硫目标硫含量≤0.002%、倒罐铁水硫含量<0.03%且脱硫目标硫含量>0.002%、倒罐铁水硫含量≥0.03%且脱硫目标硫含量≤0.002%、倒罐铁水硫含量≥0.03%且脱硫目标硫含量>0.002%。U5为样本量为n的全样本。为防止含有异常数据的炉次进入学习组,应对炉次进行筛选,筛选条件包括:倒罐铁水硫含量0.005~0.1%、倒罐铁水温度在1201~1480℃、铁水重量在(转炉公称吨位-15吨)~(转炉公称吨位+25吨)、脱硫后硫含量在0.0005~0.015%、镁粉利用率在15%~65%。本实施例m=100,n=60。
b、对样本集U5中的数据进行预处理,以消除硫含量、温度、重量等数据因数量级不同而对神经网络造成影响,减少神经网络学习时出现平台现象,具体处理方法如下:
式中,x1k~yk为样本集中第k炉的倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量、钢种上限硫含量、镁粉量,x1,min~ymin为样本集中倒罐铁水温度最小值、倒罐铁水重量最小值、倒罐铁水硫含量最小值、脱硫目标硫含量最小值、钢种上限硫含量最小值、镁粉量最小值,x1,max~ymax为样本集中倒罐铁水温度最大值、倒罐铁水重量最大值、倒罐铁水硫含量最大值、脱硫目标硫含量最大值、钢种上限硫含量最大值、镁粉量最大值,为处理后的第k炉的倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量、钢种上限硫含量、镁粉量;
c、建立BP神经网络模型。BP神经网络模型为包含输入层、隐含层和输出层的三层网络,其中输入层用于接收输入信号,其变量为倒罐铁水温度x1、倒罐铁水重量x2、倒罐铁水硫含量x3、脱硫目标硫含量x4、钢种上限硫含量x5;输出层用于输出信号即计算结果,其变量为镁粉量Y1;隐含层的神经节点数f根据公式确定,p为输入层的神经节点数,q为输出层神经节点数,r为1~10之间的常数。本发明p=5, q=1,因此隐含层的神经元节点数f的范围为4~12,若f太小网络不能识别未出现过的样本,容错性差,f太大会使网络复杂化,增加网络的学习时间,出现“过拟合”现象,反而会增大误差。本实施例确定最佳的神经元节点数为9;
d、训练BP神经网络模型,根据网络实际输出结果与期望结果的误差,调整神经网络输入层与隐含层的权值wih、隐含层与输出层的权值who、隐含层各神经元的阈值θh、输出层各神经元的阈值θo,使误差减小。权值和阈值的调整方法相同,具体如下:
(1)初始化网络。分别给wih、who、θh、θo赋一个区间(-1,1)内的随机数,设定计算精度值α、最大学习次数T、学习率η。本实施例取α=0.0001,T=10000,η=0.1;
(2)选取样本集U5中经预处理后的第k炉输入样本及对应的期望输出
(3)计算隐含层和输出层各神经元的输入和输出,其中隐含层的输出采用函数
隐含层各神经元输入hih(k)和输出hoh(k),h=1,2,···,9;
输出层各神经元输人yi(k)和输出yo(k),
(4)计算全局误差判断E是否满足要求。如果E>0.0001时,进入步骤(4)和步骤(5),重新调整权值和阈值,当E≤0.0001或学习次数t>10000时权值和阈值调整结束;
(5)计算误差函数对权值和阈值的偏导数
其中,ek为网络输出误差函数
δh(k)=δo(k)whof'(hih(k))=δo(k)whohih(k)(1-hih(k));
(6)利用迭代法调整权值who(k)、wih(k)和阈值θo、θh,t为学习次数。
e、建立镁粉量的回归计算模型。公式采用分段多元非线性回归方程,自变量为倒罐铁水温度x1、倒罐铁水重量x2、倒罐铁水硫含量x3、脱硫目标硫含量x4,其中倒罐铁水硫含量和脱硫目标硫含量对镁粉消耗影响最大,且在不同的区间影响程度不同。具体的计算公式为:
当倒罐铁水硫含量x3<0.03%、脱硫目标硫含量x4≤0.002%时:
当倒罐铁水硫含量x3<0.03%、脱硫目标硫含量x4>0.002%时:
当倒罐铁水硫含量x3≥0.03%、脱硫目标硫含量x4≤0.002%时:
y=c0+c1×x1+c2×x2+c3×x3+c4×x4;
当倒罐铁水硫含量x3≥0.03%、脱硫目标硫含量x4>0.002%时:
f、利用样本集U1~U4中的数据分别计算参数a0~a5、b0~b6、c0~c4、d0~d5,在计算时脱硫目标硫含量x4用脱硫后硫含量x6代替;
计算a0~a5的公式如下,其中x1i、x2i、x3i、x6i为样本集U1中第i炉的x1、x2、x3、x6:
计算b0~b6的公式如下,其中x1i、x2i、x3i、x6i为样本集U2中第i炉的x1、x2、x3、x6:
计算c0~c4的公式如下,其中x1i、x2i、x3i、x6i为样本集U3中第i炉的x1、x2、x3、x6:
计算d0~d5的公式如下,其中x1i、x2i、x3i、x6i为样本集U4中第i炉的x1、x2、x3、x6:
g、计算神经网络模型的镁粉量Y1。当收到铁水预处理作业开始信号后,采集当前炉次的倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量、钢种上限硫含量等数据,输入至已训练好的神经网络模型中,输出层的输出值经变换后得到镁粉量Y1,
h、计算回归模型的镁粉量Y2。判断倒罐铁水硫含量是否<0.03%、脱硫目标硫含量是否≤0.002%,根据判定结果选择选择相应的回归方程,并将倒罐铁水温度、倒罐铁水重量、倒罐铁水硫含量、脱硫目标硫含量代入方程中,计算得出镁粉量Y2;
i、输出镁粉量的最终结果。用回归模型计算的镁粉量判定神经网络模型计算的镁粉量是否合适,以防止神经网络出现局部极小或极大值,具体判定逻辑为,当0.7Y2<Y1<1.2Y2时,取神经网络模型的镁粉量计算值Y1,否则取回归模型的镁粉量计算值Y2;
j、更新学习组。当前炉次结束后,判断当前炉次是否符合进入学习组的条件,判定条件为:倒罐铁水硫含量在0.005~0.1%、倒罐铁水温度在1201~1480℃、倒罐铁水重 量在(转炉公称吨位-15)~(转炉公称吨位+25)t、脱硫后硫含量在0.0005~0.015%、镁粉利用率在15~65%。若符合条件,替换回归模型学习样本集U1、U2、U3、U4和神经网络模型的学习样本集U5中的最旧的炉次,保持样本数不变。其中,当前炉次进入U1、U2、U3、U4中的哪一个样本集,根据倒罐铁水硫含量和脱硫目标硫含量的大小而定;
k、模型重新启动学习。当回归模型学习样本集U1、U2、U3、U4每更新1炉,返回步骤f,重新计算参数a0~a5、b0~b6、c0~c4、d0~d5。当神经网络模型样本集U5每更新5炉,返回步骤d,重新训练网络,以确保计算得到的镁粉用量自动适应铁水预处理脱硫能力的变化;
表1示出了实施例的目标硫含量、钢种上限硫含量和铁水条件,表2示出了实施例的镁粉量及脱硫后硫含量。
表1本发明实施例的钢种及铁水条件
表2本发明实施例的镁粉量及脱硫后硫
本发明公开的一种精确计算铁水脱硫用镁粉量的方法,利用该方法实施例1~14,吨铁镁粉用量较原技术平均降低0.088kg/t,脱硫后铁水硫含量均控制在脱硫目标硫含量的合理范围内。
该发明方法实现了镁粉用量的自动计算并根据脱硫能力的变化自动调整,使镁粉用量更加合理和精确。
- 还没有人留言评论。精彩留言会获得点赞!