具有脑认知机理的发育自动机及其学习方法与流程
本发明涉及了具有脑认知机理的发育自动机及其学习方法,属于智能机器人技术领域。技术背景学习与记忆是人与动物智能行为的本质,人与动物的多种技能都是在其神经系统通过自学习和自组织的过程中逐渐形成和发展起来的,学习和模拟人与动物的神经活动和自我调节机制,并将其赋予给智能机器人,是人工智能与控制科学的重要研究课题。1996年,J.Weng最早提出了机器人自主心智发育思想,他认为智能体应该在模拟人脑的基础上,在内在发育程序的控制下通过传感器和效应器与未知环境交互来发展心智能力。Brooks等强调机器人与教师、环境进行交互学习逐渐发展其智能,并通过结合神经科学的研究理论提出模拟人与动物的脑皮层中的前额叶、下丘脑、海马等区域的计算模型来处理复杂环境中复杂问题,这也就涉及到了感觉运动系统。最初的认知发育是从感觉运动系统协调机制的形成和发育开始的,同时感觉运动系统又是在内在动机形成和发育的过程中不断协调和完善的。神经学相关文献表明,在人与动物学习的过程中,大脑皮层、基底核以及小脑会以自身特有的方法平行工作,并且在人与动物运动有关的相互关系中,小脑和基底核分布在大脑皮质到脊髓之间运动信号传递的路线的两侧,它们会参与任一行为动作的发起及控制。相关的专利如申请号CN200910086990.4的发明专利基于自动机理论,提出了操作自动机模型,并将该模型应用到机器人的自主学习控制中。申请号为CN201310656943.5的专利则将操作条件反射原理应用于图像处理领域,有效的提高了系统处理图像的精度和速度。申请号为201410101272.0的专利主要针对传统机器人学习效率低,适应能力差等问题提出了一种仿生智能控制方法,有效的提高了机器人智能水平。申请号为201410163756.8提出了一种基于云计算的自主心智发育云机器人系统,该系统能够有效地减轻机器人执行运算密集型任务的负担,还可以实现不同机器人间知识的共享。但是,以上专利并没有涉及模拟人类脑认知机理的学习系统。
技术实现要素:
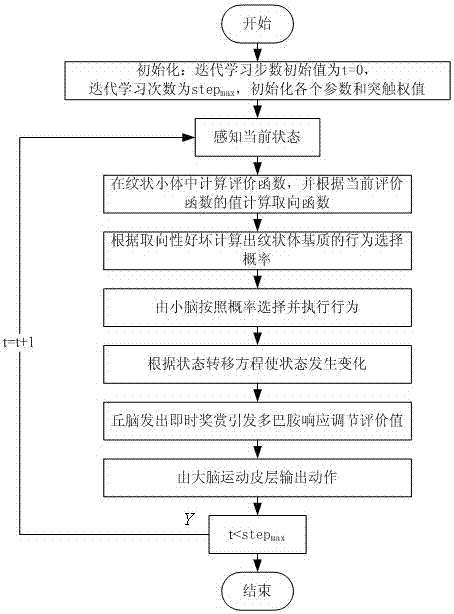
针对上述技术问题,本发明以生物感觉运动系统为理论依据,并引入心理学中的内在动机机制来驱动学习,提供一种具有脑认知机理的发育自动机及其学习方法,提高机器人的自主发育认知能力。具有脑认知机理的发育自动机,包括内部状态集合,系统输出集合,内部操作行为集合,状态转移方程,奖赏信号,系统评价函数,系统动作选择概率,多巴胺响应差分信号;(1)SC=[s1,s2,...sj]表示为有限的内部状态集合,相对应于大脑皮层中的感觉皮层,sj表示第j个状态,j为内部状态的个数。(2)MC=[y1,y2,...yi]表示为系统输出集合,相对应于大脑皮层中的运动皮层,yi表示第i个输出,i表示输出的个数。(3)CbA=[a1,a2,...ak]表示为内部操作行为集合,相对应于小脑区域,ak为第k个内部动作,k为内部动作的个数。(4)f:s(t)×a(t)→s(t+1)为状态转移方程,即t+1时刻的状态s(t+1)由t时刻的状态s(t)和操作行为a(t)共同决定,一般有环境或者模型来决定。(5)r(t)=r(s(t),a(t))表示为系统在t时刻在内部状态为s(t)是所采取的内部操作行为a(t)后使状态转移到s(t+1)后的奖赏信号,相对于丘脑所发出的丘觉。(6)大脑皮层中的输入信号包含两部分,分别是感觉皮质信息和运动皮质信息,作为纹状体的输入,因此:CC={SC,MC}(1)纹状体主要是预测生物体动作取向性好坏的评价机制,进一步说也是内在动机机制取向性好坏的评价机制,定义系统评价函数如下:BGstrio(t)=r(t+1)+γr(t+2)+γ2r(t+3)+...(2)其中,γ∈[0,1]为折扣因子;由于内在动机机制存在的缘故,使得系统的评价函数BGstrio逐渐趋近于0,从而保证系统最终处于稳定状态;定义η为内在动机机制中的取向核心,主要功能是指导自主认知方向;定义取向核心η的取值范围在[ηmin,ηmax]之间,即取向性最好与取向性最差的函数值之间;那么在纹状体中内在动机取向函数定义如公式(3)所示:其中λ为取向函数的参数,定义两个相邻时刻的取向函数的差值为θ(t)=η(t)-η(t-1),来判别系统的取向性程度,如果θ(t)>0,说明t时刻比t-1时刻的取向值大,反之θ(t)<0,说明说明t时刻比t-1时刻的取向值小。(7)在基底神经节的学习过程中,纹状体中的基质主要是动作选择功能;在由内在动机机制驱动的学习过程中最重要的一个特点就是依照概率大小来选择执行动作;采用Boltzmann概率规则来实现基质的行为选择功能,从而实现学习自动机的概率选择机制,其中Boltzmann概率规则属于公知;首先定义:其中:m表示第m个内部动作,A表示Boltzmann概率规则,p(a=ak)表示动作选择概率。根据公式(4)中的定义,将纹状体基质的系统动作选择概率输出用BGmatrix(s,a)来替代p(a=ak)表示,公式(2)代入公式(4)中得到公式(5):其中,T为温度常数,表示动作的选择随机程度,T越大说明动作选择的程度越大,相反T越小说明动作选择的程度越小;当T逐渐趋于零时,则BGstrio(SC(t),ak)所对应的动作选择概率逐渐趋于1,系统中T的数值是随着时间逐渐减小的,表示系统在学习过程中经验知识的逐渐增多,并且从一个不稳定的系统逐渐演化为一个稳定系统;(8)由黑质致密部所释放的多巴胺能用来作为动作评估的指导信号,用于改善由动作导致的最大未来奖赏的行为表达,以便获得更加精确的执行动作;在t+1时刻由纹状体所决定的评价函数为:BGstrio(t+1)=r(t+2)+γr(t+3)+γ2r(t+4)+...(6)结合公式(2)和公式(6)可以得出公式(7):BGstrio(t)=r(t+1)+γBGstrio(t+1)(7)这表明,在t时刻时,评价函数BGstrio(t)可以用t+1时刻的评价函数BGstrio(t+1)来表示,但是由于预测初期所存在的误差的影响,使得用评价值BGstrio(t+1)来表示BGstrio(t)的值与实际值并不相等,这样由丘脑输出和纹状体输出的奖赏信息需要在黑质致密部进行处理,并释放多巴胺能SNDPA来调节评价值的表,用公式(8)来表示多巴胺响应差分信号:SNDPA=r(t+1)+γBGstrio(t+1)-BGstrio(t)(8)具有脑认知机理的发育自动机的学习方法,包括以下步骤:(1)初始化:迭代学习步数初始值t=0,迭代学习次数为stepmax,初始化各个参数和突触权值,则实验开始时执行初始内部操作行为的概率相同;(2)感知当前状态SC(t);(3)在纹状体中计算评价函数BGstrio(t),由于内在动机机制的存在,根据当前BGstrio(t)的值计算出取向函数η(t);(4)根据取向性好坏按照公式计算纹状体基质的动作选择概率BGmatrix(s,a)并由小脑执行动作a(t);(5)根据状态转移方程,状态由SC(t)→SC(t+1);(6)丘脑发出即时奖赏r(t)并引发多巴胺响应调节评价值;(7)由大脑运动皮层输出动作y(t);(8)重复执行(2)~(7)直到t=stepmax;学习结束。与现有技术相比,本发明提供的具有脑认知机理的发育自动机及其学习方法,以学习自动机为基础框架为系统自主发育过程提供了一种泛化能力强,适用范围广的数学模型;其次该方法将感觉运动系统与内在动机机制相结合,提高系统的自学习与自适应能力,实现真正意义上的智能。附图说明图1为本发明系统结构图;图2为本发明学习流程图;图3为实施例的两轮机器人平衡控制各状态响应曲线;图4为实施例的两轮机器人平衡控制评价函数与误差仿真曲线;图5为实施例的抗干扰实验仿真结果;图6为实施例的学习方法与传统学习自动机方法评价函数曲线对比图;图7实施例的学习方法与传统学习自动机方法误差曲线对比图。具体实施方式下面结合附图和具体实施方式对本发明作进一步说明。以两轮机器人为实施例,系统结构图如图1所示,按照图2的步骤流程来进行学习。针对非完整式两轮自平衡机器人而言,它是一个本征不稳定的系统,在实现各种运动之前,首先要保证机器人能够保持自身平衡,所以两轮机器人的姿态平衡是进行运动控制的首要条件。为了验证本发明所提出的一种具有脑认知机理的发育自动机的有效性、鲁棒性以及优越性,本实施例以两轮机器人为对象,研究了在未知环境下机器人是怎样通过自主学习最后学会运动技能的。机器人在实验过程中有四个输出量并满足相应条件,即左右两轮角速度θr和θl均小于3.489rad/s,机身自身倾角α<0.1744rad和机器人摆杆角速度β<3.489rad/s。折扣因子γ=0.9,采样时间为0.01s。在每次实验中,当机器人的尝试次数超过1000次或者一次尝试的平衡步数超过20000步时,则停止机器人的学习并重新开始另一次实验。如果机器人在其中一次尝试中经历20000步后还能保持平衡,则认为机器人已经学会平衡控制的技能了。每次实验失败后,将初始状态及各个权值重新复位为一定范围内的随机值,再重新学习。实验1:平衡控制实验机器人在没有干扰的未知环境下,采用本发明提出的方法,经过不断的学习,经过42次试探并在第43次试探中完成实验,大约需要经历220歩左右,即2.2s左右就学会了平衡控制技能,表现了其较快的自主学习能力和本发明的有效性,仿真结果中前3000步的各状态量响应曲线和评价函数与误差仿真曲线如图3和图4所示。实验2:抗干扰实验在系统实际的运行过程中,输入输出信号会或多或少的受到外部噪声的干扰,或检测装置的不精确,都会使状态量产生一定的误差。那么为了模拟实际环境,当机器人已经学会平衡控制后保持9800步时,将幅值为25的脉冲信号加入到各个输入状态量中,如果机器人能够经受脉冲信号的干扰并保持平衡,则认为实验成功并证明本发明具有一定的鲁棒性。图5为加入脉冲信号后各状态的输出响应,可以看出经过200步,即2s左右后,机器人重新达到平衡位置。实验3:本实施例与传统学习自动机对比实验由于本发明引进了内在动机机制来驱动机器人的自主学习,有利于降低系统的误差,提高算法的收敛速度。为了证明本发明的优越性,分别应用传统学习自动机算法和本发明对两轮机器人进行了平衡控制实验,并对其实验结果进行分析。实验中两种算法的参数设定相同,图6和图7为前2000步中两种算法的评价函数与误差曲线的对比图。通过图6可以看出本发明在大约220步,即2.2s,就完成了平衡控制技能的学习,而传统学习自动机方法在大约600步,即6s,才完成学习,证明本发明的收敛速度优于传统学习自动机方法。图7表明本发明的误差幅度优于传统学习自动机方法,更有利于系统的稳定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1