网络标签自动识别方法及其系统与流程
本发明涉及网络标签识别的技术领域,特别是涉及一种网络标签自动识别方法,以及一种网络标签自动识别系统。
背景技术:
通常在各种网络通信系统中,用户常常通过签名的方式对自己的心情,兴趣等进行简要的介绍,因此在签名中会带有各种不同的网络标签,例如用户在描述兴趣的一栏添加的网络标签可能有“电影”、“旅游”等标签。随着用户画像在数据挖掘技术的推动下得到越来越广的应用,在获得用户兴趣标签属性后,我们可以根据标签推荐用户喜欢的日志、微博、游戏等,还可以根据用户的标签进行精准的广告投放,同时在基于用户兴趣标签的陌生交友方面,也有很重要的应用意义。例如各个网络运营商通常会根据各个用户的网络标签,为用户查找具有相同兴趣的其他用户,或者推荐用户可能感兴趣的各种产品、服务等。然而,对各个网络标签的分类不准确有可能导致推荐信息的混乱,例如在用户喜爱的一栏可能带有“苹果”标签,而“苹果”标签有可能是指一种水果,也可能是指一个电子产品的品牌。因此,无法根据“苹果”这一标签,为用户准确地进行信息推荐。如果用户添加的标签代表水果,而向用户推荐电子产品相关的信息,就会达不到目的,影响用户的体验。
技术实现要素:
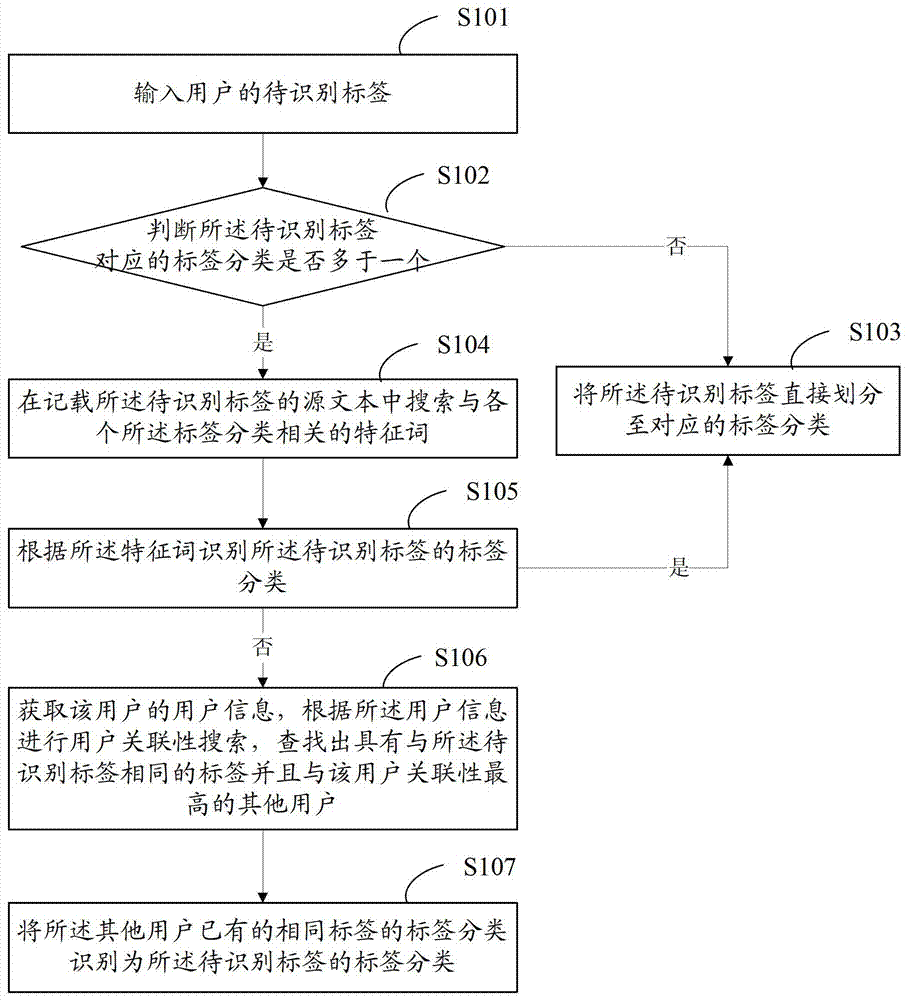
本发明的目的在于提供一种网络标签自动识别方法,通过对标签的来源文件进行文本搜索,根据搜索确定的特征词准确识别网络标签的分类,解决背景技术中对网络标签的识别不准确的问题,据此能够对用户进行准确的广告投放和业务推荐等操作,提高用户体验。一种网络标签自动识别方法,包括以下步骤:输入用户的待识别标签;判断所述待识别标签对应的标签分类是否多于一个;如果所述待识别标签对应的标签分类只有一个,则将所述待识别标签直接划分至对应的标签分类;如果所述待识别标签对应的标签分类多于一个,则在记载所述待识别标签的源文本中搜索与各个所述标签分类相关的特征词;根据所述特征词识别所述待识别标签的标签分类;如果根据所述特征词不能识别所述待识别标签的标签分类,则进一步获取该用户的用户信息,所述用户信息包括用户的属性和用户的已有标签;根据所述用户信息进行用户关联性搜索,查找出具有与所述待识别标签相同的标签并且与该用户关联性最高的其他用户;将所述其他用户已有的相同标签的标签分类识别为所述待识别标签的标签分类。针对上述背景技术中存在的问题,本发明的目的还在于提供一种网络标签自动识别系统。一种网络标签自动识别系统,包括:标签输入模块,用于输入用户的待识别标签;第一判断模块,判断所述待识别标签对应的标签分类是否多于一个;第一分类模块,用于在所述待识别标签对应的标签分类只有一个时,将所述待识别标签直接划分至对应的标签分类;文本解析模块,用于在所述待识别标签对应的标签分类多于一个时,在记载所述待识别标签的源文本中搜索与各个所述标签分类相关的特征词;第二分类模块,用于根据所述特征词识别所述待识别标签的标签分类;用户关联模块,用于在所述第二分类模块不能识别所述待识别标签的标签分类时,获取该用户的用户信息,所述用户信息包括用户的属性和用户的已有标签;根据所述用户信息进行用户关联性搜索,查找出具有与所述待识别标签相同的标签并且与该用户关联性最高的其他用户;第三分类模块,用于将所述其他用户已有的相同标签的标签分类识别为所述待识别标签的标签分类。本发明的网络标签自动识别方法及其系统中,首先判断用户输入的网络标签是否有歧义,即对应多于一个的标签分类,如果是,则在记载所述待识别标签的源文本中搜索与各个所述标签分类相关的特征词,然后将所述特征词对应的标签分类识别为所述待识别标签的标签分类。因此可以通过所述待识别标签的源文本中的其他特征词准确地识别所述标签所属的标签分类,据此能够对用户进行准确的广告投放和业务推荐等操作,提高用户体验。附图说明图1是本发明网络标签自动识别方法的一个实施方式的流程示意图;图2是本发明网络标签自动识别方法的第二个实施方式的流程示意图;图3是本发明网络标签自动识别方法的第三个实施方式的流程示意图;图4是本发明网络标签自动识别系统的一个实施方式的结构示意图;图5是本发明网络标签自动识别系统的第二个实施方式的结构示意图;图6是本发明网络标签自动识别系统的第三个实施方式的结构示意图。具体实施方式请参阅图1,图1是本发明网络标签自动识别方法一个实施方式的流程示意图。所述网络标签自动识别方法,包括以下步骤:S101,输入用户的待识别标签;所述用户的待识别标签可以从用户的网络日志,微博和搜索特征词等UGC(UserGeneratedContent,用户生成内容)中抽取。例如,所述待识别标签可以是网络日志或微博中出现次数较多的某个名词,或者是用户最新输入搜索框的搜索特征词,也可以是用户在社交通信软件中描述兴趣的一栏所输入的内容,等等。S102,判断所述待识别标签对应的标签分类是否多于一个;如果所述待识别标签对应的标签分类只有一个,则执行步骤S103,将所述待识别标签直接划分至对应的标签分类;如果所述待识别标签对应的标签分类多于一个,则执行步骤S104,在记载所述待识别标签的源文本中搜索与各个所述标签分类相关的特征词;S105,根据所述特征词识别所述待识别标签的标签分类。在步骤S102中,预先建立或者从网上搜索获取所述待识别标签所对应的所有的标签分类,所述标签分类可以是根据所述标签的解释,网络流行语的含义等等来确定。所述待识别标签所对应的标签分类可以是一个或多个,例如,用户输入的待识别标签为“瑜伽”,则通过对“瑜伽”的词义搜索,可以确定标签“瑜伽”只对应一个标签分类:“运动”,则直接将所述标签“瑜伽”匹配至对应的标签分类“运动”。又例如用户输入的待识别标签为“苹果”,则通过对“苹果”的词义搜索,可以获得“苹果”所对应的标签分类包括“水果”或者“电子产品”。亦即标签“苹果”对应的标签分类多于一个,因此执行步骤S104,在记载所述标签“苹果”的源文本中搜索与所述两个标签分类“水果”和“电子产品”相关的特征词,例如在所述源文本中搜索得到的特征词为“吃”或“水果”,则执行步骤S105,根据这两个特征词确定所述标签的分类是“水果”。而如果所述源文本中搜索得到的特征词为“手机”、“安卓平台”或者“触摸屏”等,则可以确定所述标签的分类是“电子产品”。其中,记载所述待识别标签的源文本通常是指在步骤S101中获得所述待识别标签的文本,亦即网络日志,微博和搜索特征词等用户生成内容。上述步骤S104中,可根据所述标签对应的多个标签分类,分别在所述源文本中搜索与各个所述标签分类相关的特征词。上述步骤S105可以通过对所述源文本作贝叶斯文本分类的方式实现。在一个实施例中,所述步骤S105包括:根据每一所述特征词对相应的标签分类的权值,累计每一所述标签分类的总权值,将所述总权值最高的标签分类识别为所述待识别标签的标签分类。其中,所述权值可由系统预设。在另一个实施例中,所述步骤S105包括:根据每一所述特征词对相应的标签分类的权值,累计每一所述标签分类的总权值,将所述总权值最高并且超过预设的权值门限的标签分类识别为所述待识别标签的标签分类。其中,所述权值和所述权值门限可由系统预设。与现有技术相比较,本发明的网络标签自动识别方法中,首先判断用户输入的网络标签是否有歧义,即对应多于一个的标签分类,如果是,则在记载所述待识别标签的源文本中搜索与各个所述标签分类相关的特征词,然后将所述特征词对应的标签分类识别为所述待识别标签的标签分类。因此可以通过所述待识别标签的源文本中的其他特征词准确地识别所述标签所属的标签分类,据此能够对用户进行准确的广告投放和业务推荐等操作,提高用户体验。在本发明的网络标签自动识别方法中,如果根据所述源文本中的特征词不能识别所述待识别标签的标签分类,则可进一步执行以下步骤:S106,获取该用户的用户信息,根据所述用户信息进行用户关联性搜索,查找出具有与所述待识别标签相同的标签并且与该用户关联性最高的其他用户;S107,将所述其他用户已有的相同标签的标签分类识别为所述待识别标签的标签分类。如图2所示。通常,在源文本中搜索特征词的方式已经可以确定所述待识别标签的分类,提高对标签分类的准确性。然而,还有个别情况是搜索不到特征词的,或者特征词的累计的总权值没有超过预设的权值门限,甚至也有可能是搜索出的同一个特征词具有多种意思,对应多种标签分类的情形。在此不再一一举例。则此时根据上述方式无法准确识别所述待识别标签的分类。因此,如果步骤S105中根据所述源文本中的特征词不能识别所述待识别标签的标签分类,则执行步骤S106,获取该用户的用户信息,其中,所述用户信息可包括用户的属性和用户的已有标签,所述用户的属性可包括用户的年龄、收入、喜好,毕业学校等等信息。然后根据所述用户信息进行用户关联性搜索,优选地,可根据所述属性和已有标签,进行基于FP增长算法的用户关联性搜索。根据搜索出的其他用户的已有标签的分类对本用户的标签分类进行识别。如,对于用户B输入的待识别标签“苹果”,通过关联性搜索获得具有相同标签的用户为年龄、收入和毕业学校相同的用户A,所述用户A中对标签“苹果”的标签分类为“电子产品”,则在步骤S107中将所述用户B输入的待识别标签“苹果”的标签分类确定为“电子产品”。通过上述方式,可以在对源文本的特征词搜索仍不能确定待识别标签的标签分类的情况下,进一步通过用户关联性搜索的方式确定待识别标签的标签分类。并且因为是匹配与当前用户关联性较高的其他用户的标签分类,所以识别的标签分类准确性也较高。而如果执行步骤S107,根据关联性最高的其他用户的已有标签也不能识别所述待识别标签的标签分类,则本发明的网络标签自动识别方法进一步包括以下步骤:S108,获取所述待识别标签对应的所有标签分类,将统计匹配成功率最高的标签分类识别为所述待识别标签的标签分类。如图3所示。亦即,假如搜索不到关联性高的其他用户,或者关联性高但没有相同标签的等等情形,导致根据关联性最高的其他用户的已有标签也不能识别所述待识别标签的标签分类的,则执行步骤S108,将统计匹配成功率最高的标签分类识别为所述待识别标签的标签分类。所述匹配成功率最高是指同一标签匹配至某一标签分类的几率最高。通过这种方式,可以通过统计的方式,将仍无法准确识别的待识别标签匹配至可能性最大的一个标签分类,因此识别结果也是较为准确的。请参阅图4,图4是本发明网络标签自动识别系统的结构示意图。所述网络标签自动识别系统包括:标签输入模块401,用于输入用户的待识别标签;第一判断模块402,判断所述待识别标签对应的标签分类是否多于一个;第一分类模块403,用于在所述待识别标签对应的标签分类只有一个时,将所述待识别标签直接划分至对应的标签分类;文本解析模块404,用于在所述待识别标签对应的标签分类多于一个时,在记载所述待识别标签的源文本中搜索与各个所述标签分类相关的特征词;以及,第二分类模块405,用于根据所述特征词识别所述待识别标签的标签分类。其中,所述标签输入模块401可以从用户的网络日志,微博和搜索特征词等UGC(UserGeneratedContent,用户生成内容)中抽取所述待识别标签。例如,所述待识别标签可以是网络日志或微博中出现次数较多的某个名词,或者是用户最新输入搜索框的搜索特征词,也可以是用户在社交通信软件中描述兴趣的一栏所输入的内容,等等。所述第一判断模块402可预先建立或者从网上搜索获取所述待识别标签所对应的所有的标签分类。所述标签分类可以是根据所述标签的解释,网络流行语的含义等等来确定。所述待识别标签所对应的标签分类可以是一个或多个。所述文本解析模块404对所述待识别标签的源文本执行文本搜索,并且在一个实施方式中,对所述源文本执行贝叶斯文本分类。其中,所述源文本通常是指获得所述待识别标签的文本,亦即网络日志,微博和搜索特征词等用户生成内容。在一个实施例中,所述文本解析模块404根据所述标签对应的多个标签分类,分别在所述源文本中搜索与各个所述标签分类相关的特征词;所述第二分类模块405根据每一所述特征词对相应的标签分类的权值,累计每一所述标签分类的总权值,将所述总权值最高的标签分类识别为所述待识别标签的标签分类。其中,所述权值可由系统预设。在另一个实施例中,所述文本解析模块404根据所述标签对应的多个标签分类,分别在所述源文本中搜索与各个所述标签分类相关的特征词;所述第二分类模块405根据每一所述特征词对相应的标签分类的权值,累计每一所述标签分类的总权值,将所述总权值最高并且超过预设的权值门限的标签分类识别为所述待识别标签的标签分类。其中,所述权值和所述权值门限可由系统预设。与现有技术相比较,本发明的网络标签自动识别系统通过首先判断用户输入的网络标签是否有歧义,即对应多于一个的标签分类,如果是,则在记载所述待识别标签的源文本中搜索与各个所述标签分类相关的特征词,然后将所述特征词对应的标签分类识别为所述待识别标签的标签分类。因此可以通过所述待识别标签的源文本中的其他特征词准确地识别所述标签所属的标签分类,据此能够对用户进行准确的广告投放和业务推荐等操作,提高用户体验。在一个实施方式中,所述网络标签自动识别系统还包括:用户关联模块406,用于在所述第二分类模块405不能识别所述待识别标签的标签分类时,获取该用户的用户信息,根据所述用户信息进行用户关联性搜索,查找出具有与所述待识别标签相同的标签并且与该用户关联性最高的其他用户;以及,第三分类模块407,用于将所述其他用户已有的相同标签的标签分类识别为所述待识别标签的标签分类。如图5所示。通常,在源文本中搜索特征词的方式已经可以确定所述待识别标签的分类,提高对标签分类的准确性。然而,还有个别情况是是搜索不到特征词的,或者特征词的累计的总权值没有超过预设的权值门限,甚至也有可能是搜索出的同一个特征词具有多种意思,对应多种标签分类的情形。在此不再一一举例。则此时根据上述方式无法准确识别所述待识别标签的分类。因此,如果所述第二分类模块405不能识别所述待识别标签的分类时,所述用户关联模块406获取该用户的用户信息,然后根据所述用户信息进行用户关联性搜索。优选地,所述用户关联模块406包括:用户信息获取模块,用于获取用户的属性和用户的已有标签;所述用户的属性可包括用户的年龄、收入、喜好,毕业学校等等信息;以及,关联搜索模块,用于根据所述属性和已有标签,进行基于FP增长算法的用户关联性搜索。通过上述方式,可以在对源文本的特征词搜索仍不能确定待识别标签的标签分类的情况下,进一步通过用户关联性搜索的方式确定待识别标签的标签分类。并且因为是匹配与当前用户关联性较高的其他用户的标签分类,所以识别的标签分类准确性也较高。而在另一个实施方式中,本发明的网络标签自动识别系统进一步包括:第四分类模块408,用于在所述第三分类模块407不能识别所述待识别标签的标签分类时,获取所述待识别标签对应的所有标签分类,将统计匹配成功率最高的标签分类识别为所述待识别标签的标签分类。如图6所示。亦即,假如所述用户关联模块406搜索不到关联性高的其他用户,或者关联性高但没有相同标签的等等情形,导致所述第三分类模块407根据关联性最高的其他用户的已有标签也不能识别所述待识别标签的标签分类的,所述第四分类模块408将统计匹配成功率最高的标签分类识别为所述待识别标签的标签分类。所述匹配成功率最高是指同一标签匹配至某一标签分类的几率最高。通过这种方式,可以通过统计的方式,将仍无法准确识别的待识别标签匹配至可能性最大的一个标签分类,因此识别结果也是较为准确的。以上所述实施方式仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1