车标自动识别方法及系统与流程
本发明涉及的是车辆自动识别技术领域,具体地,涉及的是一种车标自动识别方法及系统。
背景技术:
随着社会经济及道路交通的迅速发展,汽车得到大面积普及,机动车数量激增。这一方面使高速路、停车场等车辆激增而难以统计,增加道路交通管理的难度;另一方面违规、违章和盗抢案件显著增加,增加了治安管理的难度。传统的道路交通管理及治安管理,通常只能靠人眼观察车辆信息,效率和侦破率很低。因此,车辆的安全自动化管理成为了一个亟待解决的重要问题。车辆的自动识别,可以方便快捷的实现轻松缴费、违章记录、流量统计等大量工作,既能代替人实现繁重、繁琐的工作,又可以提高工作的速度和准确度。目前,基于视频图像的运动车辆识别技术仍然是相对薄弱的技术环节。车辆识别需要最大限度地利用车辆的信息对道路上的车辆进行确认。车标是车辆的一个非常重要信息,不仅是车辆的标志性图像,更重要的是包含了车型和生产厂家的信息,且难以更换。因此车标识别技术将在城市智能交通中发挥越来越重要的作用,以车标识别为核心技术的相关产品也会成为智能交通系统的重要前端设备。经对现有的技术文献检索发现,目前车标识别的方法主要有以下四种:模板匹配法,边缘直方图法,特征匹配法以及特征训练分类器法。然而,现有的这四种车标识别方法都有很大的局限性。模板匹配法只适用于摄像机正面拍摄的场景,当摄像机倾斜或拍摄的车标图像移位时,这种识别方法准确率低,不适合实际应用;边缘直方图法算法简单,但不同车标具有相似的边缘直方图,这种方法误识率较大;特征匹配法计算量大、易受光照、天气、遮挡、噪声等的影响,系统鲁棒性差,而且这种方法随着车标种类增多其准确率会降低;特征训练分类器法算法复杂、计算量大,计算时间长,难以实现实时识别,不适合实时系统的应用。由于复杂的城市交通环境(如光线及天气变化变化,遮挡等),车标识别系统仍然面临很大的挑战。车标识别技术近几年才得以发展,目前算法仍然不成熟,总结来说主要存在以下几个难点:1)准确率低,相似车标误识率大,车标类别越多识别准确率越低;2)计算量大,计算时间长,不适合在实时系统应用;3)鲁棒性低,易受光照、天气、摄像机角度、遮挡等环境因素影响。4)低图像分辨率条件下,识别能力差。
技术实现要素:
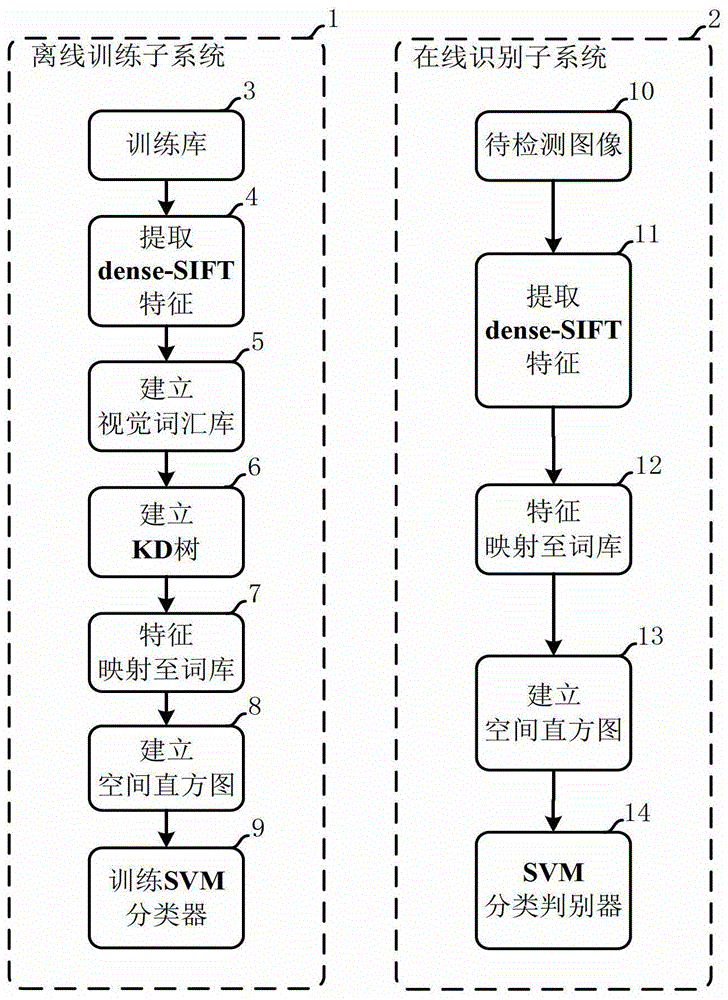
鉴于现有技术存在的上述不足,本发明提出了一种车标自动识别方法及系统,具有高识别率、强鲁棒性、高实时性的特点。本发明的车标识别系统对光照、天气、拍摄角度等变化具有更强的鲁棒性,在低分辨率条件下识别能力强,并且在线计算量小、处理时间少,适合于实时系统的应用。根据本发明的一方面,提供一种车标自动识别方法,所述方法包括两个部分:离线训练部分和在线识别子部分,其中:所述离线训练部分包括以下几个步骤:第一步:对训练车标样本图片I提取dense-SIFT特征d。具体步骤为:1.1)用密集采样网格确定特征提取点。网格上的交叉点即为特征提取点,其中采样密度为M个像素,即网格上一个特征提取点到下一个特征提取点的距离是M个像素。1.2)以每个特征提取点为中心,取N*N的窗口,计算SIFT特征描述子。第二步:从提取的所有dense-SIFT特征中,随机选取104个dense-SIFT组成特征集,利用K-MEANS聚类法,将dense-SIFT特征集分为K个聚类并计算出聚类质心。每个聚类质心作为一个视觉词,最终形成一个具有K个视觉词的词汇库。第三步:建立KD树,快速索引第二步建立的词汇库中的视觉词。第四步:根据已建立的词汇库,将车标图片I={di,di∈I}的所有dense-SIFT特征映射成视觉词,具体方法为:根据距离越近越相似的原则,计算dense-SIFT特征di与视觉词μj之间的相关度建立dense-SIFT特征di与K个视觉词μj之间的映射,映射关系为f(di)=[K(di,μ1),…,K(di,μk)]T;其中di表示第i个特征,μj表示第j个视觉词,μk表示第k个视觉词,k为视觉词的个数,σ2为高斯函数的宽度参数,控制了函数的径向作用范围,T为矩阵转置符。第五步:采用“回字形空间金字塔”,建立空间视觉词直方图来表示图像。分析一张W*H(宽*高)的车标图片,具体方法是:5.1)以(W/2,H/2)为中心,提取一个宽为W,高为H的矩形区域,即将整幅图像作为感兴趣区域I1,计算该感兴趣区域的视觉词直方图h(I1)。h(I1)为K维。5.2)以(W/2,H/2)为中心,选择一个宽为2W/3,高为2H/3的矩形区域作为感兴趣区域I2,计算该感兴趣区域的视觉词直方图h(I2)。h(I2)为K维。5.3)以(W/2,H/2)为中心,选择一个宽为W/3,高为H/3的矩形区域作为一个感兴趣区域I3,计算该感兴趣区域的视觉词直方图h(I3)。h(I3)为K维。5.4)将三个感兴趣区域I1、I2、I3的视觉词直方图顺次拼接并归一化,形成车标直方图建立最终的视觉词直方图H(I),即H(I)=[h(I1),h(I2),h(I3)]/‖H(I)‖1,‖H(I)‖1代表H(I)的绝对值和,H(I)的维数为3×K维。计算视觉词直方图的方法为:其中|Ij|代表该感兴趣区域中dense-SIFT的个数,f(di)如离线训练子系统的第四步所示,表示dense-SIFT特征与视觉词之间的映射关系f(di)=[K(di,μ1),…,K(di,μk)]T。第六步:利用车标的空间视觉词直方图,训练支持向量机SVM分类器。当训练第i类车标时,将该类的车标图像标记为+1,其余的车标图片标记为-1,本实施例采用径向基(RBF)核为SVM的核函数,为每类车标训练SVM模型。径向基(RBF)核函数公式为:K(Hi,Hj)=exp(-γ||Hi-Hj||2)其中Hi、Hj表示训练样本的空间直方图;γ为RBF的核参数;另外训练SVM模型时还需输入惩罚因子C。所述在线识别部分包括以下几个步骤:第一步:提取待检测车标图片的dense-SIFT特征。具体方法是:1.1)在车标图像上设定密集采样网格,网格上的交叉点作为特征提取点,以每个特征提取点为中心。其中采样密度为M个像素,即网格上一个特征提取点到下一个特征提取点的距离是M个像素。1.2)以每个特征提取点为中心,取N×N的窗口,计算SIFT特征描述子。M的取值要满足既能够得到丰富的特征提取点,又不能导致过大的计算量;N*N窗口大小的选取要保证能较好的描述出提取点处的特征。M,N与离线系统中的参数保持一致。第二步:根据离线训练部分已建立的词汇库,将待检测车标图片I={di,di∈I}的所有dense-SIFT特征映射成视觉词,具体方法为:计算dense-SIFT特征di与K个视觉词的相关度将dense-SIFT映射成K个视觉词表示,f(di)=[K(di,μ1),…,K(di,μk)]T。第三步:利用回字形空间金字塔,建立空间直方图来表示图像,具体方法是:5.1)以(W/2,H/2)为中心,提取一个宽为W,高为H的矩形区域,即将整幅图像作为感兴趣区域I1,计算该感兴趣区域的视觉词直方图h(I1)。h(I1)为K维。5.2)以(W/2,H/2)为中心,选择一个宽为2W/3,高为2H/3的矩形区域作为感兴趣区域I2,计算该感兴趣区域的视觉词直方图h(I2)。h(I2)为K维。5.3)以(W/2,H/2)为中心,选择一个宽为W/3,高为H/3的矩形区域作为一个感兴趣区域I3,计算该感兴趣区域的视觉词直方图h(I3)。h(I3)为K维。5.4)将三个感兴趣区域I1、I2、I3的视觉词直方图顺次拼接并归一化,形成车标直方图建立最终的视觉词直方图H(I),即H(I)=[h(I1),h(I2),h(I3)]/‖H(I)‖1,‖H(I)‖1代表H(I)的绝对值和,H(I)的维数为3×K维。计算视觉词直方图的方法为:其中|Ij|代表该感兴趣区域Ij中dense-SIFT的个数,f(di)如在线识别子系统的第二步所示,表示dense-SIFT特征与视觉词之间的映射关系f(di)=[K(di,μ1),…,K(di,μk)]T。第四步:将待检测图片的空间视觉直方图输入支持向量机SVM分类器,输出识别结果。待检测车标的识别类别根据SVM输出的最大预测值来判定。P(H(I))=argmaxPi(H(I)),其中,Pi(H(I))为经输入视觉词直方图后SVM的预测值,P(H(I))为车标的识别类别。其中wj是权重,sj是支持向量即部分训练样本的视觉词直方图,β是偏值,这些参数可以由离线系统中训练的SVM模型得到。H(I)是待识别车标的空间直方图,K(·,·)是SVMRBF核函数,根据本发明的另一方面,提供一种车标自动识别系统,所述系统包括一个离线训练子系统以及一个在线识别子系统,离线训练子系统以训练车标样本为输入,输出训练好的SVM分类器;在线识别子系统利用训练好的SVM分类器处理待检测图像,识别出待检测图像的车标类别。所述离线训练子系统包括:dense-SIFT特征提取模块:提取训练车标样本图片的dense-SIFT特征,得到dense-SIFT特征集;视觉词库建立模块:用K-MEANS方法对dense-SIFT特征集聚类分析,建立视觉词汇库;建立KD树索引视觉词汇库模块:建立KD树,快速索引视觉词库建立模块建立的词汇库中的视觉词;特征映射至视觉词模块:根据视觉词库建立模块已建立的词汇库,计算dense-SIFT特征提取模块得到的dense-SIFT特征集与视觉词的相关性,将dense-SIFT映射成所有视觉词表示;建立空间直方图模块:采用回字形空间金字塔,建立空间视觉词直方图来表示图像;训练支持向量机分类器模块:利用建立空间直方图模块建立的空间视觉词直方图训练支持向量机SVM分类器;训练图片库中的车标图片依次经过上述几个模块处理,得到训练好的SVM分类器。所述识别子系统包括:dense-SIFT特征提取模块:提取待检测车标图片的dense-SIFT特征;特征映射至视觉词模块:根据离线训练部分已建立的词汇库,计算dense-SIFT特征提取模块获得的dense-SIFT特征集与视觉词的相关性,将dense-SIFT映射成视觉词表示;空间直方图建立模块:采用回字形空间金字塔,建立空间视觉直方图来表示图像;SVM分类器预测模块:将空间直方图建立模块建立的待检测图片的空间视觉直方图输入支持向量机SVM分类器,输出识别结果。与现有技术相比,本发明具有以下有益效果:本发明的车标识别方法及系统,采用dense-SIFT提取车标特征,能在低分辨率车标图片上提取丰富、稳定以及具有识别判别性的特征;建立KD树索引视觉词库,加快了计算速度;根据dense-SIFT和视觉词的相关性,将dense-SIFT映射成所有视觉词来表示,增加特征的描述性;在建立视觉词直方图时,引入空间位置信息,提升判别效果。本发明在低分辨率图像下具有高识别率,对遮挡、光照变化、拍摄角度变化等具有更高的鲁棒性,并且本发明所需计算时间短,具有实时性。附图说明通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:图1为本发明总体流程图。图2为本发明离线训练子系统及在线识别子系统流程图。图3为提取车标图像的dense-SIFT特征示意图。图4为利用K-MEANS建立视觉词汇库流程示意图。图5为采用“回字形空间金字塔”建立空间直方图示意图。图6为本发明车标识别结果图。具体实施方式下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。本实施采用的数据库共有840张已分割的车标图片,包含14类车标,每类有60张图片,每张图片的高度为30个像素,分辨率较低。数据库中的图片在不同时间、不同天气条件、不同相机角度下拍摄所得。参见图1的流程示意图所示,本实施例涉及的车标识别系统包括离线训练子系统1和在线识别子系统2。离线训练子系统1以训练车标样本为输入,输出训练好的SVM分类器;在线识别子系统2利用训练好的SVM分类器处理待检测图像,识别出待检测图像的车标类别。在图2所示实施例中,离线训练子系统实现离线训练的过程包括输入训练车标图片3、提取dense-SIFT特征4、建立视觉词汇库5、建立KD树6、特征映射至视觉词表示7、建立空间直方图8、训练SVM分类器9。具体实现步骤为:(1):如图3所示,对所有的训练车标样本图片提取dense-SIFT特征,则车标图片I可以表示成dense-SIFT特征di的集合,即I={di,di∈I}。具体步骤为:1.1)在车标图像上设定密集采样网格,网格上的交叉点作为特征提取点15。其中采样密度为5个像素,即网格上一个特征提取点到下一个特征提取点的距离是5个像素。1.2)以每个特征提取点为中心,取4×4的窗口,计算SIFT特征描述子16。M的取值要满足既能够得到丰富的特征提取点,又不能导致过大的计算量;N*N窗口大小的选取要保证能较好的描述出提取点处的特征。本实施例中M=5,N=4。在这一步中,dense-SIFT特征提取算法直接用密集采样网格确定特征提取点,缩短特征点检测的时间;并且dense-SIFT能在低分辨率图片上提取数目较多的特征,增加了本发明的识别率;此外,dense-SIFT特征具有尺度不变、旋转不变等特性,增强了本发明的鲁棒性。(2):如图4所示流程图中,从所有dense-SIFT特征中,随机选取104个dense-SIFT组成dense-SIFT特征集17,利用K-MEANS聚类法,对dense-SIFT特征集17进行聚类分析,建成一个具有300个视觉词的词汇库5,具体步骤为:2.1)从dense-SIFT特征集17中任意选择300个dense-SIFT特征作为初始聚类质心μ(18);2.2)对除聚类质心外的每个dense-SIFT特征di,计算di到所有聚类质心μj的欧式距离Dij,并把该dense-SIFT特征di归到欧式距离Dij最短的质心所属的聚类Cj中,由此形成300个新聚类C。其中Dij=||di-μj||2;2.3)更新聚类的质心。计算新聚类中所有dense-SIFT的均值,并作为新聚类的质心,即其中|Cj|是聚类Cj中dense-SIFT特征的个数。2.4)重复过程2.2)和2.3)直至收敛,收敛是指新聚类的质心趋于稳定。K-MEANS收敛时,可得到的每个聚类最终的质心μj,每个聚类质心即为视觉词。视觉库是由300个聚类质心(视觉词)组成,V={μj,j=1:300}。(3):如图2流程图中所示,在得到视觉词汇库后,建立KD树(6)索引词汇库中的视觉词。KD树可以加快多维空间关键数据的搜索,这一步,可以减少训练系统及识别系统中视觉词的搜索时间,提高本发明的实时性。(4):如图2流程图所示,将训练车标图片I中所有的dense-SIFT特征映射成视觉词7表示,具体方法为:根据dense-SIFT与视觉词之间的距离,计算每一个dense-SIFT特征di与300个视觉词的相关度,将dense-SIFT映射至300个视觉词,映射关系为f(di)=[K(di,μ1),…,K(di,μ300)]T,T表示矩阵转置符。其中K(·,·)是表示di与μj之间距离的高斯核函数本实施例中,σ2=100控制了高斯函数的径向作用范围。这一步,传统方法是,根据dense-SIFT与视觉词之间的距离,将dense-SIFT量化到离其距离最近的一个视觉词中。传统方法的缺点是,不能表示出dense-SIFT与其他视觉词之间相似的关系,因此带有片面性。本发明借助映射的思想表示出了dense-SIFT和所有视觉词的相似性,可以很大程度上增强dense-SIFT特征的描述能力,提高本发明的识别准确率。(5):在图2流程图及图5实施例中,提出“回字形空间金字塔”,建立空间直方图来表示图像,分析宽为W高为H的车标图像,具体方法是:5.1)以(W/2,H/2)为中心,提取一个宽为W,高为H的矩形区域,即将整幅图像作为感兴趣区域I123,计算该感兴趣区域的视觉词直方图h(I1)24,h(I1)为K维。5.2)以(W/2,H/2)为中心,选择一个宽为2W/3,高为2H/3的矩形区域作为感兴趣区域I225,计算该感兴趣区域的视觉词直方图h(I2)26,h(I2)为K维。5.3)以(W/2,H/2)为中心,选择一个宽为W/3,高为H/3的矩形区域作为一个感兴趣区域I327,计算该感兴趣区域的视觉词直方图h(I3)28,h(I3)为K维。5.4)将三个感兴趣区域I1、I2、I3的视觉词直方图顺次拼接并归一化,形成车标直方图建立最终的视觉词直方图H(I)29,即H(I)=[h(I1),h(I2)h(I3)]/‖H(I)‖1。‖H(I)‖1代表空间直方图绝对值和,H(I)的维数为3×K维。计算视觉词直方图的方法为:其中|Ij|代表该感兴趣区域Ij中dense-SIFT的个数,f(di)如离线训练子系统的步骤(4)所示,表示dense-SIFT特征与视觉词之间的映射关系f(di)=[K(di,μ1),…,K(di,μk)]T。关于K值的选择,K增大时,识别准确率会在一定范围内增高,但当K过大时,识别准确率不能明显提高,计算量却明显增大。本实施例中K=300。这一步,传统的视觉词直方图是对一张图片中视觉词出现次数或者所占比重的统计,不能反映视觉词在图片中的空间位置信息。本发明提出“回字形空间金字塔”思想,一方面可以在直方图中增加特征区域的空间位置信息,更加准确的描述图像所包含的内容,提高车标识别率;另一方面,“回字形空间金字塔”增加了车标内部特征的比重,降低车标周围排气扇的干扰,降低不同种类车标之间的误识率。(6):利用车标图像的视觉词直方图训练支持向量机SVM分类器,具体方法为:在支持向量机理论中,其本质上是二类分类器,因此,如何设计一个好的分类器也是解决问题的关键。在本实施例中,所属的支持向量机分类器采用一对多方法组建,具体是为每一类车标训练一个SVM模型,当训练第i类车标时,将该类的车标图像标记为+1,其余的车标图片标记为-1,本实施例采用径向基(RBF)核为SVM的核函数,为每类车标训练SVM模型。径向基(RBF)核函数公式为:K(Hi,Hj)=exp(-γ||Hi-Hj||2)其中Hi、Hj表示训练样本的空间直方图;γ为RBF的核参数;另外训练SVM模型时还需输入惩罚因子C。本实施例采用“grid-search”方法,确定最优参数C=32.0,γ=2.0。在图2所示实施例中,在线识别子系统2实现在线识别的过程包括读取待检测车标图片10、提取dense-SIFT特征11、将dense-SIFT特征映射至视觉词表示12、建立空间直方图13、SVM分类器预测14。具体实现步骤为:(7):如图3实施例中所示,提取待检测图像的dense-SIFT特征,具体方法为:7.1)在车标图像上设定密集采样网格,网格上的交叉点作为特征提取点15。其中采样密度为5个像素,即网格上一个特征提取点到下一个特征提取点的距离是5个像素。7.2)以每个特征提取点为中心,取4×4的窗口,计算SIFT特征描述子16。在这一步中,dense-SIFT特征提取算法直接用密集采样网格确定特征提取点,缩短特征点检测的时间;并且dense-SIFT能在低分辨率图片上提取数目较多的特征,增加了本发明的识别率;此外,dense-SIFT特征具有尺度不变、旋转不变等特性,增强了本发明的鲁棒性。(8):在图2流程图的12,根据离线系统中已建立的词汇库,将待检测车标图片I={di,di∈I}的所有dense-SIFT特征映射至视觉词,具体方法是:根据dense-SIFT与视觉词之间的距离,计算每一个dense-SIFT特征di与300个视觉词的相关度,将dense-SIFT映射至300个视觉词,映射关系为f(di)=[K(di,μ1),…,K(di,μ300)]T,T表示矩阵转置。其中K(·,·)是表示di与μj之间距离的高斯核函数本实施例σ2=100控制了高斯函数的径向作用范围。这一步,传统方法是,根据dense-SIFT与视觉词之间的距离,将dense-SIFT量化到离其距离最近的一个视觉词中。传统方法的缺点是,不能表示出dense-SIFT与其他视觉词之间相似的关系,因此带有片面性。本发明借助映射的思想表示出了dense-SIFT和所有视觉词的相似性,可以很大程度上增强dense-SIFT特征的描述能力,提高本发明的识别准确率。(9):如图2和图5所示,采用“回字形空间金字塔”,建立空间直方图13,具体方法是:9.1)以(W/2,H/2)为中心,提取一个宽为W,高为H的矩形区域,即将整幅图像作为感兴趣区域I123,计算该感兴趣区域的视觉词直方图h(I1)24,h(I1)为K维。9.2)以(W/2,H/2)为中心,选择一个宽为2W/3,高为2H/3的矩形区域作为感兴趣区域I225,计算该感兴趣区域的视觉词直方图h(I2)26,h(I2)为K维。9.3)以(W/2,H/2)为中心,选择一个宽为W/3,高为H/3的矩形区域作为一个感兴趣区域I327,计算该感兴趣区域的视觉词直方图h(I3)28,h(I3)为K维。9.4)将三个感兴趣区域I1、I2、I3的视觉词直方图顺次拼接并归一化,形成车标直方图建立最终的视觉词直方图H(I)29,即H(I)=[h(I1),h(I2)h(I3)]/‖H(I)‖1。‖H(I)‖1表示空间直方图的绝对值之和,H(I)的维数为3×K维。计算视觉词直方图的方法为:其中|Ij|代表该感兴趣区域Ij中dense-SIFT的个数,f(di)如在线识别子系统步骤(8)所示,表示dense-SIFT特征与视觉词之间的映射关系f(di)=[K(di,μ1),…,K(di,μk)]T。本实施例中k=300。这一步,传统的视觉词直方图是对一张图片中视觉词出现次数或者所占比重的统计,不能反映视觉词在图片中的空间位置信息。本发明提出“回字形空间金字塔”思想,一方面可以在直方图中增加特征区域的空间位置信息,更加准确的描述图像所包含的内容,提高车标识别率;另一方面,“回字形空间金字塔”增加了车标内部特征的比重,降低车标周围排气扇的干扰,降低不同种类车标之间的误识率,得到更好的车标识别效果。(10):如图2流程图中示,将待检测图像的空间直方图输入到支持向量机SVM分离器9中,识别车标类别14。待检测车标的识别类别根据SVM输出的最大预测值来判定。P(H(I))=argmaxPi(H(I)),其中,P(H(I))为车标的识别类别,Pi(H(I))为SVM对当前图片的预测值。其中wj是权重,sj是支持向量即部分训练样本的视觉词直方图,β是偏值,这些参数可以由训练的SVM模型得到。H(I)是待识别车标的空间直方图,K(·,·)是SVMRBF核函数,图6为本发明的车标识别系统结果图。本实施例中,将车标样本库分为图片数量逐步增多的子库进行测试,分别为6、12、18…60张/类。本实施例的识别准确率为97.38%,并且效果非常稳定,平均识别每张车标的时间不到0.022秒,处理速度快。以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1