目标序列化实现方法和装置与流程
本发明涉及计算机应用领域,特别是涉及一种目标序列化实现方法和装置。
背景技术:
对象序列化技术是将对象数据转换为另一种持久化数据形式的技术,转换之后的数据形式必须易于存储在外部介质上,或易于使用网络进行传输。为了使得存储和传输后的数据能够再次变回内存中的对象,这样的转换必须是可逆的。目标序列化技术在数据的传输和存储过程中,引入了对象的抽象,使得这个过程更加直观,使用更加方便,因此,目标序列化技术在面向对象的软件系统中使用非常广泛。
由于目标序列化技术使用的广泛性,很多计算语言都在语言层面,通过标准库的方式,提供目标序列化的功能支持,如java语言等。在Android系统中,目标序列化代码读写都是手工完成的,例如每新增一个对象,在数据库中通过需要手动写一遍序列化代码,然而大量函数和大量代码重复,通过手工复制粘贴,其开发效率低,且手工复制粘贴,容易引入缺陷。
技术实现要素:
基于此,有必要针对传统的目标序列化过程中手工复制粘贴代码,导致开发效率低且容易引入缺陷的问题,提供一种目标序列化实现方法,能够提高开发效率且避免引入缺陷。
此外,提供一种目标序列化实现装置,能够提高开发效率且避免引入缺陷。
一种目标序列化实现方法,包括以下步骤:
自动获取目标中待序列化的部分;
对所述目标中待序列化的部分进行解析得到解析结果,并保存所述解析结果;
根据所述解析结果对所述目标进行序列化,转换为打包序列化包装器;
调用所述打包序列化包装器,通过反射机制对所述目标进行序列化读写。
一种目标序列化实现装置,包括:
获取模块,用于自动获取目标中待序列化的部分;
解析模块,用于对所述目标中待序列化的部分进行解析得到解析结果,并保存所述解析结果;
转换模块,用于根据所述解析结果对所述目标进行序列化,转换为打包序列化包装器;
调用模块,用于调用所述打包序列化包装器,通过反射机制对所述目标进行序列化读写。
上述目标序列化实现方法和装置,通过将自动获取目标中待序列化的部分,进行解析得到解析结果,根据解析结果对目标进行序列化,转换为打包序列化包装器,通过调用打包序列化包装器及反射机制进行序列化读写,不需要手动编码,提高了开发效率,且不需手动复制粘贴,避免了引入缺陷,且转换为打包序列化包装器,减小了工程代码量及函数量,缩减了空间。
附图说明
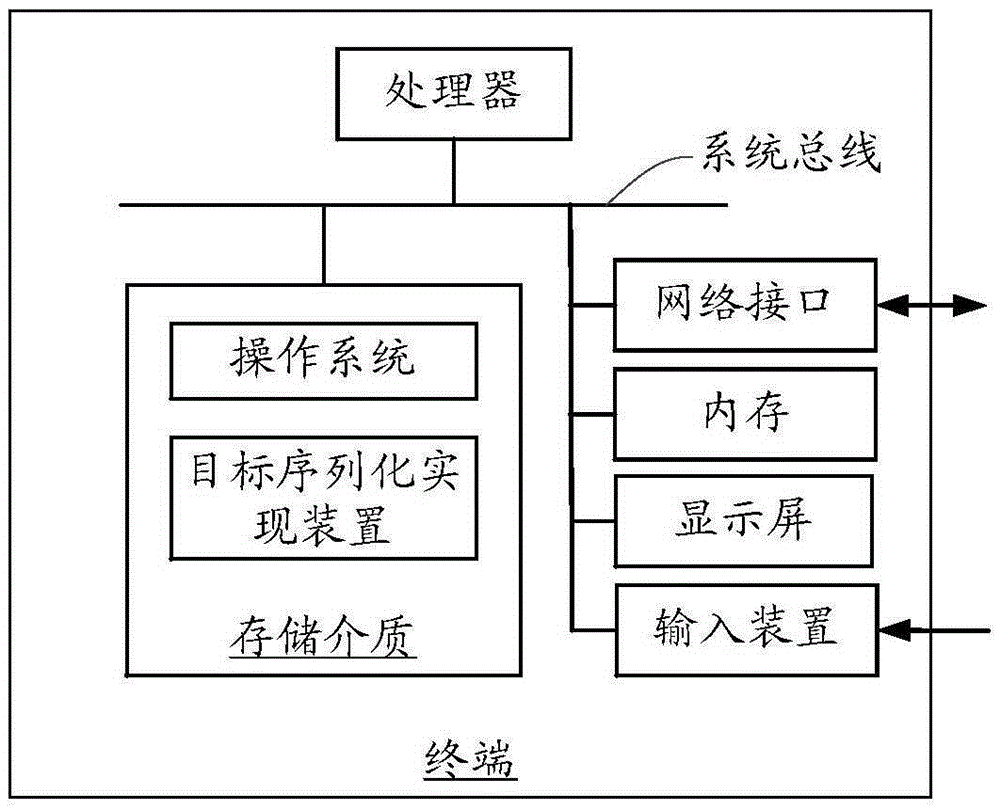
图1为一个实施例中终端的内部结构示意图;
图2为一个实施例中后台服务器的内部结构示意图;
图3为一个实施例中目标序列化实现方法的流程图;
图4为一个实施例中类序列化实现方法的流程图;
图5为一个实施例中数据库序列化实现方法的流程图;
图6为一个实施例中目标序列化实现装置的结构框图;
图7为另一个实施例中目标序列化实现装置的结构框图;
图8为另一个实施例中目标序列化实现装置的结构框图;
图9为另一个实施例中目标序列化实现装置的结构框图;
图10为另一个实施例中目标序列化实现装置的结构框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
可以理解,本发明所使用的术语“第一”、“第二”等可在本文中用于描述各种元件,但这些元件不受这些术语限制。这些术语仅用于将第一个元件与另一个元件区分。举例来说,在不脱离本发明的范围的情况下,可以将第一客户端称为第二客户端,且类似地,可将第二客户端称为第一客户端。第一客户端和第二客户端两者都是客户端,但其不是同一客户端。
图1为一个实施例中终端的内部结构示意图。如图1所示,该终端包括通过系统总线连接的处理器、存储介质、内存、网络接口、显示屏、扬声器和输入装置。其中,终端的存储介质存储有操作系统,还包括一种目标序列化实现装置,该目标序列化实现装置用于实现一种目标序列化实现方法。该处理器用于提供计算和控制能力,支撑整个终端的运行。终端中的内存为存储介质中的目标序列化实现装置的运行提供环境,网络接口用于与服务器进行网络通信,如发送数据请求至服务器,接收服务器返回的数据等。其中,目标可包括类和/或数据库等。类可为Java类中所有需要序列化的类。终端的显示屏可以是液晶显示屏或者电子墨水显示屏等,输入装置可以是显示屏上覆盖的触摸层,也可以是终端外壳上设置的按键、轨迹球或触控板,也可以是外接的键盘、触控板或鼠标等。该终端可以是手机、平板电脑或者个人数字助理。本领域技术人员可以理解,图1中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的终端的限定,具体的终端可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
图2为一个实施例中后台服务器的内部结构示意图。如图2所示,该后台服务器包括通过系统总线连接的处理器、存储介质、内存和网络接口。其中,该服务器的存储介质存储有操作系统、数据库和目标序列化实现装置,数据库中存储有目标序列化数据,该目标序列化实现装置用于实现适用于服务器的一种 目标序列化实现方法。该服务器的处理器用于提供计算和控制能力,支撑整个服务器的运行。该服务器的内存为存储介质中的目标序列化实现装置的运行提供环境。该服务器的网络接口用于据以与外部的终端通过网络连接通信,比如接收终端发送的数据请求以及向终端返回数据等。服务器可以用独立的服务器或者是多个服务器组成的服务器集群来实现。本领域技术人员可以理解,图2中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的服务器的限定,具体的服务器可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
图3为一个实施例中目标序列化实现方法的流程图。如图3所示,一种目标序列化实现方法,包括以下步骤:
步骤302,自动获取目标中待序列化的部分。
具体地,获取目标中待序列化的部分可通过字符串匹配方式获取或添加注解标记,查询到注解标记获取,但不限于此。
在一个实施例中,步骤302包括:从目标中查找与预定字符串相匹配的成员,将相匹配的成员作为待序列化的部分。
具体地,预定字符串可根据需要设定,如%#,&%,*&等,不限于此。
若目标包括类,则从类中查找与第一预定字符串相匹配的成员,将相匹配的成员作为类中待序列化的部分。
其中,第一预定字符串可根据需要设定,如%#,&%,*&等,不限于此。
若目标包括数据库,则从数据库中查找与第二预定字符串相匹配的成员,将相匹配的成员作为类中待序列化的部分。
其中,第二预定字符串可根据需要设定,如%#,&%,*&等,不限于此。且第一预定字符串与第二预定字符串不同。通过字符串匹配可快速查找到需要序列化的部分,不需要额外增加标记。
步骤304,对目标中待序列化的部分进行解析得到解析结果,并保存该解析结果。
具体地,目标可包括类和数据库等中一种或两种。若目标包括类,则解析 结果中包括类信息,主要是类成员的类型信息等。若目标包括数据库,则解析结果中包括数据库中数据表信息等。将解析结果保存在内存缓存中,供后续调用使用。
步骤306,根据该解析结果对该目标进行序列化,转换为打包序列化包装器。
具体地,将目标转换为ParcelWrapper类,即打包序列化包装器,对自动序列化的部分的包装。转换支持的基本类型包括String(字符串类型)、SmartParcel(自动序列化类型)、Parcelable类(Android系统类型)、ArrayList(数组列表类型)、Map(数据结构)等。
步骤308,调用该打包序列化包装器,通过反射机制对该目标进行序列化读写。
具体地,调用ParcelWrapper,根据解析结果通过反射机制对目标进行序列化读写。反射机制是Java系统提供的能力。反射机制是指Java在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法,对于任意一个对象,都能够调用它的任意一个方法和属性,这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制。
Java反射机制主要提供了以下功能:在运行时判断任意一个对象所属的类;在运行时构造任意一个类的对象;在运行时判断任意一个类所具有的成员变量和方法;在运行时调用任意一个对象的方法;生成动态代理。
上述目标序列化实现方法,通过将自动获取目标中待序列化的部分,进行解析得到解析结果,根据解析结果对目标进行序列化,转换为打包序列化包装器,通过调用打包序列化包装器及反射机制进行序列化读写,不需要手动编码,提高了开发效率,且不需手动复制粘贴,避免了引入缺陷,且转换为打包序列化包装器,减小了工程代码量及函数量,缩减了空间。
在一个实施例中,上述目标序列化实现方法还包括:对该目标中待序列化的成员添加注解标记。注解标记可为预先定义的标记,用于表示目标中需要序列化的成员。目标有多个时,每个目标所采用的注解标记不同,每个目标与其注解标记对应。
该自动获取目标中待序列化的部分包括:获取该目标中记录有注解标记的 部分作为该目标中待序列化的部分。通过添加注解标记,方便快速查找到对应的待序列化的部分,且不需重复编写代码和函数,减小了数据量。
图4为一个实施例中类序列化实现方法的流程图。如图4所示,目标为类,一种类序列化实现方法,包括以下步骤:
步骤402,对类中待序列化的成员添加第一注解标记。
具体地,第一注解标记根据需要设定,如@NeedParcel或@n或#m等,不限于此。
例如,类中添加注解标记后的代码如下所示:
上述在类的成员中添加第一注解标记@NeedParcel,表明需要序列化。
步骤404,获取该类中记录有第一注解标记的部分作为类中待序列化的部分。
具体地,识别出具有第一注解标记的部分作为类中待序列化的部分。
步骤406,对类中待序列化的部分进行解析得到解析结果,并保存该解析结果。
具体地,解析结果中包括类信息,主要是类成员的类型信息等。
步骤408,根据该解析结果对类进行序列化,转换为打包序列化包装器。
具体地,将类转换为ParcelWrapper类,即打包序列化包装器,对自动序列化的部分的包装。转换支持的基本类型包括String(字符串类型)、SmartParcel(自动序列化类型)、Parcelable类(Android系统类型)、ArrayList(数组列表类型)、Map(数据结构)等。
SmartParcelable接口为被序列化类的接口,不需要实现任何函数,通过 SmartParcelable接口可以获取类中实现序列化的成员。
步骤410,调用该打包序列化包装器,通过反射机制对该类进行序列化读写。
具体地,调用ParcelWrapper,根据解析结果通过反射机制对目标进行序列化读写。
上述类序列化实现方法,通过将类中待序列化的成员添加第一注解标记,根据第一注解标记获取到类中待序列化的部分,进行解析得到解析结果,根据解析结果对类进行序列化,转换为打包序列化包装器,通过调用打包序列化包装器及反射机制进行序列化读写,不需要手动编码,提高了开发效率,且不需手动复制粘贴,避免了引入缺陷,且转换为打包序列化包装器,减小了工程代码量及函数量,缩减了空间。
图5为一个实施例中数据库序列化实现方法的流程图。如图5所示,目标为数据库,一种数据库序列化实现方法,包括以下步骤:
步骤502,对数据库中待序列化的成员添加第二注解标记。
具体地,第二注解标记根据需要设定,如@DbValue或@t或#p等,不限于此。目标有多个时,每个目标所采用的注解标记不同。
例如,在原有的DbcacheData接口,需要手动实现以下四个函数:
*Interface that must be implemented and provided as a public CREATOR
*field that provides some static access of your cache data.
@Public
public static interface DbCreator<T extends DbCacheable>{
@public
public Structure[]structure();
@public
public String[]sortorder();
@public
public T createFromCursor(Cursor cursor);
@public
public int version();
}
添加第二注解标注@DbValue后代码如下:
Class that help Auto write or read the Dbdata;
Version control of this data,define a static int field named VERSION_INT,like;
Private static final int VERSION_INT=8;//数据库版本号
Sort order of this data,define a static String filed named ORDER_STR,like;
Simple example:
Public class AppInfo extends AutoDbData{
Private static final int VERSION_INT=8;//数据库版本号
//@DbValue(true)means this Colum should be UNIQUE
//default is false;
@DbValue(true)
public int appid;
@DbValue(true)
public String appname;
@DbValue(true)
public String iconUrl;
@DbValue(true)
public String downloadUrl;
@DbValue(true)
public String summary;
@DbValue(true)
public int isRecommend;
@DbValue(true)
public String packageName;
@DbValue(true)
public String h5_url;//触屏应用地址
@DbValue(true)
public String recommendComment;//推荐详情
@DbValue(true)
public int maskAppType;
//本地
Public int appType=AppType.OTHER_APPLICATION;
Public long installTime=0;
Public int cancelable=0;
Public AppInfo(){
}
此外,还可对注解标记设置为true,表示在数据表中唯一。
步骤504,获取该数据库中记录有第二注解标记的部分作为类中待序列化的部分。
具体地,识别出具有第二注解标记的部分作为类中待序列化的部分。
步骤506,对数据库中待序列化的部分进行解析得到解析结果,并保存该解析结果。
具体地,解析结果中包括数据库中数据表信息等。
步骤508,根据该解析结果对数据库进行序列化,转换为打包序列化包装器。
具体地,将数据库转换为ParcelWrapper类,即打包序列化包装器,对自动序列化的部分的包装。转换支持的基本类型包括String(字符串类型)、SmartParcel(自动序列化类型)、Parcelable类(Android系统类型)、ArrayList(数组列表类型)、Map(数据结构)等。
SmartParcelable接口为被序列化类的接口,不需要实现任何函数,通过SmartParcelable接口可以获取类中实现序列化的成员。
步骤510,调用该打包序列化包装器,通过反射机制对该数据库进行序列化读写。
具体地,调用ParcelWrapper,根据解析结果通过反射机制对数据库进行序列化读写。
上述数据库序列化实现方法,通过将数据库中待序列化的成员添加第二注解标记,根据第二注解标记获取到数据库中待序列化的部分,进行解析得到解析结果,根据解析结果对数据库进行序列化,转换为打包序列化包装器,通过调用打包序列化包装器及反射机制进行序列化读写,不需要手动编码,提高了开发效率,且不需手动复制粘贴,避免了引入缺陷,且转换为打包序列化包装器,减小了工程代码量及函数量,缩减了空间。
在一个实施例中,上述数据库序列化实现方法中,还包括:在数据库中存储有数据表版本号,并设置该数据表版本号的静态值。
具体地,数据表版本号写static final int VERSION_INT=8;设置数据包版本号的静态值,每次版本号更新时,版本号自动增加1。
进一步的,上述数据库序列化实现方法中,还包括:对该数据表进行排序,并设置排序方式的静态值。
具体地,通过写“static final String ORDER_STR=Columns.FEED_PRIORITY+"DESC,"+Columns.PUBLISH_DATE+"DESC";”的静态值,设置排序方式,按照排序方式进行排序。通过设置静态值,不需要生成函数,可以通过反射读取到信息。数据库中数据表根据需要自动进行排序。
在其他实施例中,上述目标序列化实现方法可同时对类和数据库进行序列化,若采用注解标记,则类中成员所添加的第一注解标记和数据库中成员所添加的第二注解标记不同,以区分。
上述目标序列化实现方法应用于在即时通信应用程序空间中可以减少大约200多个类,减少900多个函数。开发中也无需再手动写序列化类,提高开发效率。运行效率:自动化执行耗时分为两步,类解析(解析出哪些字段需要读写,字段类型等)与数据读写,类解析耗时较多,对解析的结果做缓存,只有第一次用到时解析一遍。一般数据类总的读写耗时2ms左右。此外,对读写密度较大,或者次数较多的类,也支持使用手动写入,提高执行效率。类中的中间对象可使用对象池,减少零碎对象出现。
图6为一个实施例中目标序列化实现装置的结构框图。如图6所示,一种目标序列化实现装置,包括获取模块610、解析模块620、转换模块630和调用 模块640。其中:
获取模块610用于自动获取目标中待序列化的部分。
具体地,获取模块610获取目标中待序列化的部分可通过字符串匹配方式获取或添加注解标记,查询到注解标记获取。
在一个实施例中,获取模块610还用于从该目标中查找与预定字符串相匹配的成员,将该相匹配的成员作为待序列化的部分。
具体地,预定字符串可根据需要设定,如%#,&%,*&等,不限于此。
若目标包括类,则获取模块610从类中查找与第一预定字符串相匹配的成员,将相匹配的成员作为类中待序列化的部分。
其中,第一预定字符串可根据需要设定,如%#,&%,*&等,不限于此。
若目标包括数据库,则获取模块610从数据库中查找与第二预定字符串相匹配的成员,将相匹配的成员作为类中待序列化的部分。
其中,第二预定字符串可根据需要设定,如%#,&%,*&等,不限于此。且第一预定字符串与第二预定字符串不同。通过字符串匹配可快速查找到需要序列化的部分,不需要额外增加标记。
解析模块620用于对所述目标中待序列化的部分进行解析得到解析结果,并保存所述解析结果。
具体地,目标可包括类和数据库等中一种或两种。若目标包括类,则解析结果中包括类信息,主要是类成员的类型信息等。若目标包括数据库,则解析结果中包括数据库中数据表信息等。将解析结果保存在内存缓存中,供后续调用使用。
转换模块630用于根据该解析结果对所述类进行序列化,转换为打包序列化包装器。
具体地,将目标转换为ParcelWrapper类,即打包序列化包装器,对自动序列化的部分的包装。转换支持的基本类型包括String(字符串类型)、SmartParcel(自动序列化类型)、Parcelable类(Android系统类型)、ArrayList(数组列表类型)、Map(数据结构)等。
调用模块640用于调用所述打包序列化包装器,通过反射机制对所述类进 行序列化读写。
具体地,调用ParcelWrapper,根据解析结果通过反射机制对目标进行序列化读写。反射机制是Java系统提供的能力。
上述目标序列化实现装置,通过将自动获取目标中待序列化的部分,进行解析得到解析结果,根据解析结果对目标进行序列化,转换为打包序列化包装器,通过调用打包序列化包装器及反射机制进行序列化读写,不需要手动编码,提高了开发效率,且不需手动复制粘贴,避免了引入缺陷,且转换为打包序列化包装器,减小了工程代码量及函数量,缩减了空间。
图7为另一个实施例中目标序列化实现装置的结构框图。如图7所示,一种目标序列化实现装置,除了包括获取模块610、解析模块620、转换模块630和调用模块640,还包括标注模块650。其中:
标注模块650用于对该目标中待序列化的成员添加注解标记。
注解标记可为预先定义的标记,用于表示目标中需要序列化的成员。目标有多个时,每个目标所采用的注解标记不同,每个目标与其注解标记对应。
获取模块610还用于获取该目标中记录有注解标记的部分作为该目标中待序列化的部分。通过添加注解标记,方便快速查找到对应的待序列化的部分,且不需重复编写代码和函数,减小了数据量。
图8为另一个实施例中目标序列化实现装置的结构框图。如图8所示,目标包括类,一种目标序列化实现装置,除了包括获取模块610、解析模块620、转换模块630和调用模块640,还包括第一标记模块660。其中:
第一标记模块660用于对该类中待序列化的成员添加第一注解标记。
具体地,第一注解标记根据需要设定,如@NeedParcel或@n或#m等,不限于此。
获取模块610还用于获取该类中记录有第一注解标记的部分作为该类中待序列化的部分。
解析模块620还用于对类中待序列化的部分进行解析得到解析结果,并保 存该解析结果。具体地,解析结果中包括类信息,主要是类成员的类型信息等。
转换模块630还用于根据该解析结果对类进行序列化,转换为打包序列化包装器。SmartParcelable接口为被序列化类的接口,不需要实现任何函数,通过SmartParcelable接口可以获取类中实现序列化的成员。
调用模块640还用于调用该打包序列化包装器,通过反射机制对该类进行序列化读写。
具体地,调用ParcelWrapper,根据解析结果通过反射机制对目标进行序列化读写。
上述类序列化实现装置,通过将类中待序列化的成员添加第一注解标记,根据第一注解标记获取到类中待序列化的部分,进行解析得到解析结果,根据解析结果对类进行序列化,转换为打包序列化包装器,通过调用打包序列化包装器及反射机制进行序列化读写,不需要手动编码,提高了开发效率,且不需手动复制粘贴,避免了引入缺陷,且转换为打包序列化包装器,减小了工程代码量及函数量,缩减了空间。
图9为另一个实施例中目标序列化实现装置的结构框图。如图9所示,目标包括数据库,一种目标序列化实现装置,除了包括获取模块610、解析模块620、转换模块630和调用模块640,还包括第二标记模块670。其中:
第二标记模块670用于对数据库成员添加第二注解标记。
具体地,第二注解标记根据需要设定,如@DbValue或@t或#p等,不限于此。目标有多个时,每个目标所采用的注解标记不同。
获取模块610还用于获取该数据库中记录有第二注解标记的部分作为数据库中待序列化的部分。
解析模块620还用于对数据库中待序列化的部分进行解析得到解析结果,并保存该解析结果。具体地,解析结果中包括数据库中数据表信息等。
转换模块630还用于根据该解析结果对数据库进行序列化,转换为打包序列化包装器。
调用模块640还用于调用该打包序列化包装器,通过反射机制对该数据库 进行序列化读写。
具体地,调用ParcelWrapper,根据解析结果通过反射机制对数据库进行序列化读写。
上述数据库序列化实现装置,通过将数据库中待序列化的成员添加第二注解标记,根据第二注解标记获取到数据库中待序列化的部分,进行解析得到解析结果,根据解析结果对数据库进行序列化,转换为打包序列化包装器,通过调用打包序列化包装器及反射机制进行序列化读写,不需要手动编码,提高了开发效率,且不需手动复制粘贴,避免了引入缺陷,且转换为打包序列化包装器,减小了工程代码量及函数量,缩减了空间。
图10为另一个实施例中目标序列化实现装置的结构框图。如图10所示,目标包括数据库,一种目标序列化实现装置,除了包括获取模块610、解析模块620、转换模块630、调用模块640、第二标记模块670、还包括存储模块680和排序模块690。
存储模块680用于在所述数据库中存储有数据表版本号,并设置该数据表版本号的静态值。
具体地,数据表版本号写static final int VERSION_INT=8;设置数据包版本号的静态值,每次版本号更新时,版本号自动增加1。
排序模块690用于对该数据表进行排序,并设置排序方式的静态值。
通过设置静态值,不需要生成函数,可以通过反射读取到信息。
在其他实施例中,上述目标序列化实现装置,可包括获取模块610、解析模块620、转换模块630、调用模块640、第一标记模块660、第二标记模块670、存储模块680和排序模块690中任意可能的组合,在此不再赘述。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)等。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!