一种互联网账号的数据处理方法及装置与流程
本申请涉及互联网
技术领域:
,尤其涉及一种互联网账号的数据处理方法及装置。
背景技术:
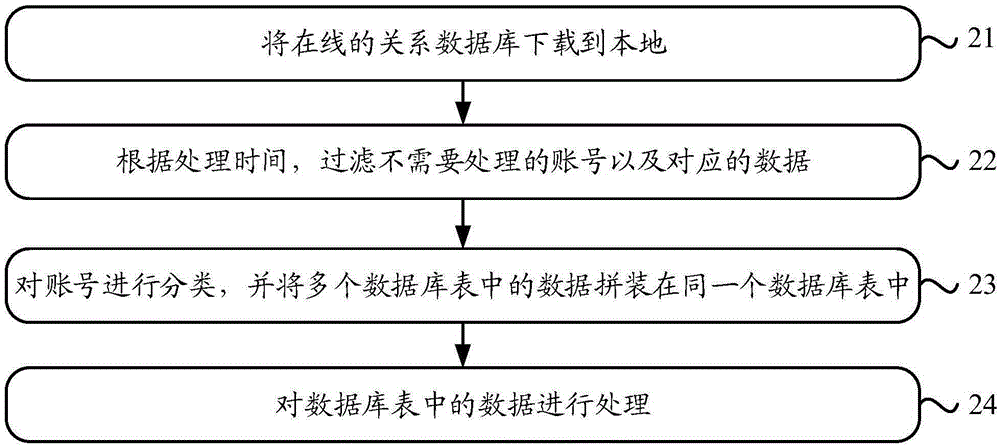
:随着互联网的发展,互联网账号作为用户的唯一标识,广泛应用在网络中,并且账号对于体现个性化数据起到了重要的作用。比如,账号中会包含资料数据、还会包含网络行为数据等,并且账号中包含的所有数据之间,也往往具有一定的关联性。比如,某一账号中包含的资料数据与网络行为数据,可能会反映出账号的兴趣等。现有技术可以定期获取与账号具有关联关系的数据,并针对这些数据进行处理,得到与该账号相关的信息,可以将“定期”看作处理时间、在当前时间到达处理时间时,即可对账号中的数据进行处理。然而,由于账号对应的数据很多,所以不可能将所有数据都存储在同一个位置(比如,保存在同一数据库中多个数据库表中),现有技术每处理一个账号的数据时,都要去多个位置获取该账号对应的数据,处理多少个账号就要去获取多少次。随着大数据时代的到来,账号数量呈线性增长,账号中包含的数据类型也呈现多样化,每时每刻都有可能出现更多的数据处理任务,既有数量上的增加,又有类型上的增多,面对TB级甚至PB级的数据时,以现有的数据处理方式难以胜任,并且效率不高。技术实现要素:本申请实施例提供一种互联网账号的数据处理方法,用于提高互联网账号的数据处理效率。本申请实施例提供一种互联网账号的数据处理装置,用于提高互联网账号的数据处理效率。本申请实施例采用下述技术方案:一种互联网账号的数据处理方法,所述方法将在线数据下载为离线数据,并根据离线数据进行数据处理,该方法包括:根据处理时间,确定离线数据,所述离线数据包含:需要进行数据处理的账号以及所述账号对应的数据;所述数据为与处理所述账号具有关联关系的所有数据;将离线数据包含的需要处理的账号以及所述账号对应的数据按照预设的数据结构进行数据拼装,使拼装后的数据适应于处理模型;所述处理模型是预先设定的用于处理互联网账号数据的计算模型;利用处理模型对所述拼装后的数据进行处理。优选地,将离线数据包含的需要处理的账号以及所述账号对应的数据进行数据拼装,使拼装后的数据适应于处理模型,包括:将存储在关系数据库的多个数据库表中具有关联关系的数据拼装在同一个数据库表中,使拼装后的数据库表适用于处理模型;则利用处理模型对所述拼装后的数据进行处理,包括:利用处理模型,对存储在所述同一个数据库表中的账号以及所述账号对应的数据进行处理。优选地,所述账号对应的数据中包含处理方式标识,则将离线数据包含的需要处理的账号以及所述账号对应的数据进行数据拼装,使拼装后的数据适应于处理模型,具体包括:根据所述账号对应的处理方式标识对账号进行分类;根据分类结果,分别将离线数据包含的需要处理的账号以及所述账号对应的数据进行数据拼装,使拼装后的数据适应于处理模型。优选地,根据处理时间,确定离线数据,具体包括:根据处理时间,过滤在线数据中无需处理的账号;下载需要处理的账号以及所述账号对应的数据。优选地,下载需要处理的账号以及所述账号对应的数据,具体包括:下 载相对于最近一次下载的发生变化的需要处理的账号以及所述账号对应的数据。优选地,根据处理时间,确定离线数据,具体包括:下载在线数据为离线数据;根据处理时间,过滤离线数据中无需处理的账号以及所述账号对应的数据,保留需要处理的账号以及所述账号对应的数据。一种互联网账号的数据处理装置,包括:数据确定单元、数据操作单元以及数据处理单元,其中,所述数据确定单元,用于根据处理时间,确定离线数据,所述离线数据包含:需要进行数据处理的账号以及所述账号对应的数据;所述数据为与处理所述账号具有关联关系的所有数据;所述数据操作单元,用于将离线数据包含的需要处理的账号以及所述账号对应的数据按照预设的数据结构进行数据拼装,使拼装后的数据适应于处理模型;所述处理模型是预先设定的用于处理互联网账号数据的计算模型;所述数据处理单元,用于利用处理模型对所述拼装后的数据进行处理。优选地,所述数据操作单元包括:数据操作子单元,具体用于:将存储在关系数据库的多个数据库表中具有关联关系的数据拼装在同一个数据库表中;则所述数据处理单元,包括:数据处理子单元,具体用于:利用处理模型,对存储在所述同一个数据库表中的账号以及所述账号对应的数据进行处理。优选地,所述账号对应的数据中包含处理方式标识,则所述数据操作单元包括:数据分类单元,具体用于:根据所述账号对应的处理方式标识对账号进行分类;根据分类结果,分别将需要处理的账号以及所述账号对应的数据按照预设的数据结构进行数据拼装,使拼装后的数据适应于处理模型。优选地,所述数据确定单元,具体用于:根据处理时间,过滤在线数据中无需处理的账号;下载需要处理的账号以及所述账号对应的数据。优选地,所述数据确定单元,具体用于:下载相对于最近一次下载的发生变化的需要处理的账号以及所述账号对应的数据。优选地,所述数据确定单元,具体用于:下载在线数据;根据处理时间,过滤离线数据中无需处理的账号以及所述账号对应的数据,保留需要处理的账号以及所述账号对应的数据。本申请实施例采用的上述至少一个技术方案能够达到以下有益效果:将在线数据下载为离线数据,并将离线数据按照处理模型能够处理的数据格式进行拼装,再利用处理模型进行数据处理。不再像现有技术,每处理一个账号的数据就要去获取一次,而是一次全部获取到线下进行拼装,以便处理模型进行处理,从数据处理的过程上来看提高了互联网账号的处理效率。此外,也节省了宝贵的在线资源,以便在线资源可以完成其它任务。附图说明此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:图1为为本申请实施例1提供的一种互联网账号的数据处理方法的具体实现流程示意图;图2为为本申请实施例2提供的一种利用关系数据库进行离线数据处理的方法的具体实现流程示意图;图3为本申请实施例3提供的一种互联网账号的数据处理装置的具体结构示意图;图4为本申请实施例3提供的一种互联网金融账户的结息方法的示意图。具体实施方式为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。在进行本申请的技术方案的详细介绍之前,为了明确起见,这里先对几个术语作简要说明。在本申请实施例中将涉及在线数据、离线数据、数据拼装、关系数据库、数据库表。其中,在线数据是指存储设备和所存储的数据时刻保持在线状态,可供在互联网上随意读取;离线数据是对在线数据的备份,以防范在线数据发生丢失损坏等,离线数据不常被调用,一般也远离互联网应用,所以用离线来生动地描述这种存储方式。数据拼装是指将不同来源的原始数据经过复制粘贴后形成新的数据,可以是以表格或其他各种格式存在。以下结合附图,详细说明本申请各实施例提供的技术方案。实施例1如前文所述,现有技术中,当当前时间到达处理时间时,可以获取与需要进行数据处理的账号具有关联关系的数据,由于账号对应的数据很多,所以不可能将所有数据都存储在同一个位置,但每处理一个账号的数据时,都要去多个位置获取该账号对应的数据,处理多少个账户就要去获取多少次。比如,表格A中存在100个账号(A1、A2……A100),包括用户名等账号数据,表格B中存在100行数据,分别存储了对应表格A中100个账号包含的100行数据(B1、B2……B100),当表格A中的账号A1需要进行数据处理时,就会去获取表格B中对应账号A1的数据B1,当表格A中的账号A2需要进行数据处理时,就会去获取表格B中对应账号A2的数据B2,如果100个账号都需要进行数据处理,就需要如此往复的获取100次。随着大数据时代的到来,账号数量呈线 性增长,账号中包含的数据类型也呈现多样化,需要面对的是TB级甚至PB级的数据,显然,针对每个账号进行数据处理都需要获取,就会造成效率不高。所以,本申请提供了一种互联网账号的数据处理方法,用于提高互联网账号的数据处理效率,该方法是将在线数据下载为离线数据,并根据离线数据进行数据处理,由于本申请中的处理的数据不需要非常严格的实时性,所以可以将处理过程转移至离线,从而避免了占用在线资源,也就减轻了在线资源的压力,节省了这部分在线资源可以完成其它任务。该方法的具体流程示意图如图1所示,包括下述步骤:步骤11:根据处理时间,确定离线数据。该步骤中,处理时间可以是指数据需要进行处理的时间,该时间可以是时间点,如22:10:00,也可以是时间段,如2015年10月13日5:00-17:00这个时间段。当前时间就可以是当前所在的时间,在当前时间到达账号的处理时间或处在账号的处理时间内,就需要对该账号进行数据处理。离线数据可以包含:需要进行数据处理的账号以及账号对应的数据。比如,需要进行数据处理的账号a以及该账号a对应的个人资料、网页收藏信息,等等。处理时间可以包含在账号对应的数据中,也可以是账号带有的标识。由于不同账号的处理时间往往不尽相同,所以,在进行数据处理时,不是所有的账号都需要处理,所以在确定离线数据的过程中,根据处理时间,确定离线数据时,可以有以下两种方式:第一种方式:根据处理时间,确定离线数据,可以包括:根据处理时间,过滤在线数据中无需处理的账号;下载需要处理的账号以及账号对应的数据。具体地,在线数据中保存了所有账号以及对应的数据,但是如上所述,不同账号的处理时间往往不尽相同,所有可以根据处理时间,对在线数据先进行过滤,过滤掉不需要进行数据处理的账号,比如,可以根据当前时间和处理时 间进行过滤,过滤掉没有达到处理时间(时间段)的账号,具体比如,账号b的处理时间为2015年10月13日,当前时间为2015年10月11日,则可以判断出账号b不需要进行数据处理。再将需要处理的账号以及账号对应的数据下载为离线数据。需要说明的是,在实际应用中,账号信息可能存在数据表格中,只要一个数据表格中有一个需要进行数据处理的账号,就可以将该数据表格下载为离线数据。采用这种方式确定离线数据时,由于先对在线数据进行过滤,只下载需要进行数据处理的账号以及对应的数据,无需下载全部数据,所以在一定程度上节省了数据传输资源。在实际应用中,账号以及账号对应的数据的数量不一定每时每刻都在变化,所以,下载需要处理的账号以及账号对应的数据,可以包括:下载相对于最近一次下载的发生变化的需要处理的账号以及账号对应的数据。具体地,每次数据处理的过程都需要下载在线数据,但是如果在本次下载时,需要处理的账号以及账号对应的数据相对于上一次下载时没有变化,就没有下载的必要的,所以只需要下载相对于最近一次下载的发生变化的需要处理的账号以及账号对应的数据就可以了。在数据修改后,都会留下修改时间,如果相对于上一次下载时,修改时间没有变化,就可以认为数据没有变化,具体比如,某一表格,修改时间为2015年10月11日21:00:00,上一次下载在线数据的时间为2015年10月13日23:00:00,当前下载在线数据的时间为2015年10月14日23:00:00,那么就可以认为该表格相对于上一次下载时没有发生变化,在本次下载时就无需再次下载。除了根据修改时间,还可以根据消息摘要算法等,下载相对于最近一次下载的发生变化的需要处理的账号以及账号对应的数据。采用这种方式,由于只下载相对于最近一次下载的发生变化的需要处理的账号以及账号对应的数据,所以又在一定程度上节省了数据传输资源。第二种方式:根据处理时间,确定离线数据,可以包括:下载在线数据为离线数据;根据处理时间,过滤离线数据中无需处理的账号以及账号对应的数据,保留需要处理的账号以及账号对应的数据。具体地,可以先将所有在线数据下载为离线数据,再根据处理时间,过滤离线数据中无需处理的账号以及账号对应的数据,具体实施方式与上文“判断出账号b不需要进行数据处理”类似,此处不再赘述。采用这种方式确定离线数据时,由于先将所有在线数据下载为离线数据,再确定需要进行数据处理的账号以及对应的数据,所以在一定程度上节省了在线资源的占用。此外,有可能下载的全部在线数据还会为其它数据处理任务提供数据支持。步骤12:将离线数据包含的需要处理的账号以及账号对应的数据进行数据拼装,使拼装后的数据适应于处理模型。该步骤中,处理模型是预先设定的用于处理互联网账号数据的模型,比如,账号a以及账号对应的个人资料、网页收藏信息等,利用处理模型可以确定出账号a可能的兴趣信息。该模型可以是一个应用程序(JAVA程序)。由于不同的处理模型在处理数据时,会有不同的数据格式规范要求,所以在将数据交给处理模型进行处理之前,需要进行数据拼装,前文已经介绍,数据拼装是指将不同来源的原始数据经过复制粘贴后形成新的数据,可以是以表格或其他各种格式存在。可以将确定出的离线数据进行拼装,拼装成便于处理模型进行处理的数据。具体地,离线数据可以是一种关系数据库,关系数据库是创建在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。数据库中,存在至少一个数据库表,数据库表是一系列二维数组的集合,它由纵向的列和横向的行组成,在关系数据库中,存在多个数据库表,数据库表之间存在关联关系,比如,在某个关系数据库中存在用于存储账号及账号信息的数据库表C和用于存储对应账号的个人资料数据库表D,数据 库表C和数据库表D中的每个数据都一一对应,即账户C1和数据D1对应,等等。在数据拼装时,可以将多个数据库表拼装为一个数据库表。所以,将离线数据包含的需要处理的账号以及账号对应的数据进行数据拼装,使拼装后的数据适应于处理模型,可以包括:将存储在关系数据库中的多个数据库表中具有关联关系的数据拼装在同一个数据库表中,使拼装后的数据库表适用于处理模型。比如,某个关系数据库中,包含C、D、E、F四个数据库表,这四个数据库表具有关联关系,将这四个数据库表进行数据拼装,拼装为一个数据库表,该数据库表中包含了C、D、E、F四个数据库表中的数据。在进行数据处理时,处理模型不再需要利用关系模型从其它数据库表中获取需要的数据,而是仅需要在一个数据库表中进行数据处理。需要说明的是,本步骤通过关联数据库来介绍拼装过程,并不是限定仅仅依赖于关联数据库,对于非关联数据库,也可能进行拼装。在实际应用中,往往通过不同的处理方式期望得到不同的处理结果,所以,在一种实施方式中,账号对应的数据中可以包含处理方式标识。该处理方式标识可以表示不同的处理方式,比如,以数据类型为标识、以具体的算法为标识等等。则将离线数据包含的需要处理的账号以及账号对应的数据进行数据拼装,使拼装后的数据适应于处理模型,可以包括:根据账号对应的处理方式标识对账号进行分类;根据分类结果,分别将离线数据包含的需要处理的账号以及账号对应的数据进行数据拼装,使拼装后的数据适应于处理模型。步骤13:利用处理模型对拼装后的数据进行处理。该步骤中,拼装数据已经在步骤12中完成,此步骤只需利用处理模型进行处理即可,比如将拼装后的数据输入到用于数据处理的应用程序中,经过该应用程序的处理,得到处理结果。在步骤12中介绍了针对关系数据库包含的数据库表的拼装,所以,在一 种实施方式中,利用处理模型对拼装后的数据进行处理,可以包括:利用处理模型,对存储在同一个数据库表中的账号以及账号对应的数据进行处理。需要说明的是,自出所述的同一数据库表,并非将所有数据都拼装进一个数据库表文件中,而是一个账号以及该账号对应的所有数据在同一个数据库表中。比如,可以有多个数据库表1、2、3……n,但是数据库表1中包含账号a以及账号a对应的所有数据,在除数据库表1以外的其它数据库表中,找不到关于账号a的任何数据。采用实施例1提供的该方法,将在线数据下载为离线数据,并将离线数据按照处理模型能够处理的数据格式进行拼装,再利用处理模型进行数据处理。不再像现有技术,每处理一个账号的数据就要去获取一次,而是一次全部获取到线下进行拼装,以便处理模型进行处理,从数据处理的过程上来看提高了互联网账号的处理效率。此外,也节省了宝贵的在线资源,以便可以利用在线资源完成其它任务。实施例2基于相同的发明构思,实施例2提供了一种利用关系数据库进行离线数据处理的方法,用于提高互联网账号的数据处理效率。假设某一博客网站有若干用户,该网站的关系数据库中会记录用户发表博文的次数以及针对该用户发表的博文的被阅读数、被评论数。还会记录用户评论其它博文的次数,阅读其它博文的次数,并且数据之间存在关联关系。该方法包括以下步骤:步骤21:将在线的关系数据库下载到本地,关系数据库包括:数据库表1包含账号处理时间;数据库表2包含发表博文的次数;数据库表3包含针对博文的被阅读数、被评论数;数据库表4包含评论博文的次数、阅读博文的次数;数据库表5包含对博文的转发次数。账号名称处理时间a2015/10/14b2015/10/15c2015/10/14d2015/10/16e2015/10/17f2015/10/14数据库表1账号名称发表博文次数a20b15c10d5e8f25数据库表2账号名称被阅读数被评论数a5600130b48014121c56130489d125076e6435925f794613235数据库表3账号名称阅读数评论数a1502b23116c00d51e139f4665数据库表4账号名称转发数a4b6c0d13e30f19数据库表5步骤22:根据处理时间,过滤不需要处理的账号以及对应的数据。由于当前时间为2015/10/14,所以过滤掉账号b、d、e以及对应的数据。步骤23:根据是否为与发表的博文相关的数据,对账号进行分类,并将多个数据库表中的数据拼装在同一个数据库表中。得到以下两个数据库表:账号名称发表博文次数被阅读数被评论数a205600130c1056130489f25794613235数据库表A账号名称阅读数评论数转发数a15024f466519数据库表B步骤24:对数据库表A和数据库表B中的数据进行处理。分别得到账号的原创等级(即根据原创博文的相关数据确定的参数)以及账号的参与等级(即根据参与阅读评论转发的次数确定出的参数)。采用实施例2提供的该方法,将在线数据下载为离线数据,并将离线数据按照处理模型能够处理的数据格式进行拼装,再利用处理模型进行数据处理。不再像现有技术,每处理一个账号的数据就要去获取一次,而是一次全部获取到线下进行拼装,以便处理模型进行处理,从数据处理的过程上来看提高了处理效率。实施例3基于相同的发明构思,实施例2提供了一种互联网账号的数据处理装置,用于提高互联网账号的数据处理效率。如图3所示,该装置包括:数据确定单元31、数据操作单元32以及数据处理单元33,其中,数据确定单元31,可以用于根据处理时间,确定离线数据,离线数据包含:需要进行数据处理的账号以及账号对应的数据;数据为与处理账号具有关联关系的所有数据;数据操作单元32,可以用于将离线数据包含的需要处理的账号以及账号对应的数据按照预设的数据结构进行数据拼装,使拼装后的数据适应于处理模型;处理模型是预先设定的用于处理互联网账号数据的计算模型;数据处理单元33,可以用于利用处理模型对拼装后的数据进行处理。在一种实施方式中,数据操作单元32包括:数据操作子单元,可以用于:将存储在关系数据库的多个数据库表中具有关联关系的数据拼装在同一 个数据库表中;则数据处理单元,包括:数据处理子单元,可以用于:利用处理模型,对存储在同一个数据库表中的账号以及账号对应的数据进行处理。在一种实施方式中,账号对应的数据中可以包含处理方式标识,则数据操作单元包括:数据分类单元,可以用于:根据账号对应的处理方式标识对账号进行分类;根据分类结果,分别将需要处理的账号以及账号对应的数据按照预设的数据结构进行数据拼装,使拼装后的数据适应于处理模型。在一种实施方式中,数据确定单元,可以用于:根据处理时间,过滤在线数据中无需处理的账号;下载需要处理的账号以及账号对应的数据。在一种实施方式中,数据确定单元,可以用于:下载相对于最近一次下载的发生变化的需要处理的账号以及账号对应的数据。在一种实施方式中,数据确定单元,可以用于:下载在线数据;根据处理时间,过滤离线数据中无需处理的账号以及账号对应的数据,保留需要处理的账号以及账号对应的数据。采用实施例3提供的该装置,将在线数据下载为离线数据,并将离线数据按照处理模型能够处理的数据格式进行拼装,再利用处理模型进行数据处理。不再像现有技术,每处理一个账号的数据就要去获取一次,而是一次全部获取到线下进行拼装,以便处理模型进行处理,从数据处理的过程上来看提高了互联网账号的处理效率。实施例4基于相同的发明构思,实施例4提供了一种互联网金融账户的结息方法,用于提高互联网金融账户的结息效率。还通过将结息从线上转移到线下,节省了线上资源,也在一定程度上避免了与其它线上业务互相干扰。假设某互联网金融系统需要根据结息日期定期结息,金融系统中存在用于保存金融数据的关 系数据库,包含用于保存存款账户的存款核心;用于保存存款信息的借记账务,用于保存签约信息的签约中心。该方法的示意图如图4所示,包括下述步骤:步骤41:将在线的关系数据库下载到本地,包括如下数据:账户名称结息日期上一次结息日期12015/10/14--22015/11/15--32015/10/14--42015/12/16--52015/10/27--62015/10/142015/7/14存款核心账户名称存款信息(单位:元)存款日期1200002013/10/14260002014/11/1531000002015/4/144100002013/12/16545002015/4/27683002014/1/9借记账务账户名称合约期限(单位:年,0为活期)利率(单位:%)122.6211.7530.51.55422.650.51.55600.35签约中心步骤42:根据结息日期,过滤不需要结息的账户以及对应的数据。由于当前时间为2015/10/14,所以过滤掉账号2、4、5、8、11以及对应的数据。步骤43:根据储蓄业务类型(活期与定期),对账号进行分类,并将多个数据库表中的数据拼装在同一个数据库表中。得到以下两个数据库表:账户名称存款信息(单位:元)合约期限(单位:年)利率(单位:%)12000022.631000000.51.55定期储蓄结息表账户名称存款信息(单位:元)上一次结息日期利率(单位:%)683002015/7/140.35活期储蓄结息表步骤44:根据定期和活期储蓄结息表中的数据进行结息,分别结算各账户的利息。账户1结算2年定期储蓄的利息:20000×2×2.6%=1040(元);账户3结算6月定期储蓄的利息100000×0.5×1.55%=775(元);账户6结算1季度活期储蓄的利息:8300×90/360×0.35%=7.26(元),。采用实施例3提供的该方法,将金融系统中的在线数据下载为离线数据,并将离线数据中具有关联关系的数据库表进行拼装,再根据拼装后的数据进行结息。不再像现有技术,每对一个账户进行结息都要在在线资源中获取一个该账户对应的数据,而是一次全部下载到线下进行拼装,在结息时不需要到处获取数据,在结息时提高了结息效率。此外,也节省了宝贵的在线资源,以便在线资源可以完成其他任务。本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结 合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flashRAM)。内存是计算机可读介质的示例。计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存 (PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitorymedia),如调制的数据信号和载波。还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1