基于Hadoop平台的海量图片的快速检索方法与流程
本发明涉及计算机大数据处理领域,具体是基于Hadoop平台的海量图片的快速检索方法。
背景技术:
随着互联网的普及和广泛应用,电商平台和社交网络也不断发展,用于商品展示或社交分享的图片数量呈爆炸式增长。在这些电子商务网站和社交网站上,图片的信息表达远远超过了文字信息的描述,所以这些电子商务网站和社交网站更加注重图片的质量。从对淘宝网的分析来看,在整个商务平台的流量中,对图片的访问高达91.5%以上。腾讯相册的用户每周上传的图片也高达11亿张,目前的总图片数量有近700亿张,总容量高达15PB。由于海量图片需要消耗海量的存储空间,图片的存储和检索都会出现性能瓶颈。面对海量的图片资源,如何高效的检索以及如何在满足高并发访问的前提下构建高效廉价的检索系统成为需要迫切解决的问题。
Hadoop是一个能够对大量数据进行分布式处理的软件框架,同时它又是可靠、高效、可扩展的。可靠性体现在它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。高效性体现在它以并行的方式工作,通过并行处理加快处理速度。可拓展性指其能够处理PB级数据。
由于Hadoop最初是针对大规模文本数据处理设计的,内部数据类型有限,不能直接处理图片数据。在HDFS中,文件或目录等均是以对象形式在内存中存储,每个对象约使用150比特内存。随着海量图片数量的增加,耗费的内存也迅速增加,大量名字节点内存的耗费,严重影响了Hadoop的应用性。同时,检索大量图片的速度远远慢于访问相同数据量的大文件。
技术实现要素:
针对海量图片的检索出现的性能瓶颈问题,本发明提出了基于Hadoop的海量图片检索方法,通过Sequence实现对小图片合并,并在合并过程中设定单个Sequence File的偏移量,解析索引快速定位存储图片Block的DataNode和Fileld,解决海量图片数据扩容和快速检索的问题。
为解决上述技术问题,本发明的是通过以下技术方案实现的:
步骤一、搭建Hadoop集群平台。每台计算机安装操作系统和Hadoop软件,将一台计算机配置成NameNode,其它计算机配置成DataNodes。各个机器通过SSH直接通信。NameNode负责的是整个存储层的管理,DataNode主要作为存储节点。验证DataNode和NameNode之间联通性是通过心跳检测来实现,并且DataNode还要定期将自己的存储区信息发送给NameNode。当客户端访问时,首先访问NameNode,NameNode会分配相应的空间,在得到相应的空间后开始各个作业。
步骤二、设置安全策略。Hadoop集群平台中新增一台DataNode2作为NameNode备份机,将原有NameNode中的数据复制到选定的DataNode2中,在NameNode运行时,NameNode2会实时的检测NameNode的运行状态,同时把NameNode中的操作实时更新到本地,在NameNode出现故障时,NameNode2代替NameNode保证服务的正常进行。
步骤三、单图片存储处理。图片先经过负载均衡模块过滤,进入应用服务器队列等待进入HDFS存储系统,通过NameNode分配DataNode进行存储,图片写入过程中先确定写入Block,再确定Sequence File,系统将二者的ID组合命名为图片的系统内的名称。图片元数据保存在HBase,同时元数据也保存在由Redis构建的缓存系统中。图片完成写入操作。
步骤四、文件预处理合并。将指定目录下的图片文件读取进图片数组,并初始化byte数组,用相应的输出文件流将byte中的图片读入到指定路径下的合并文件中去。
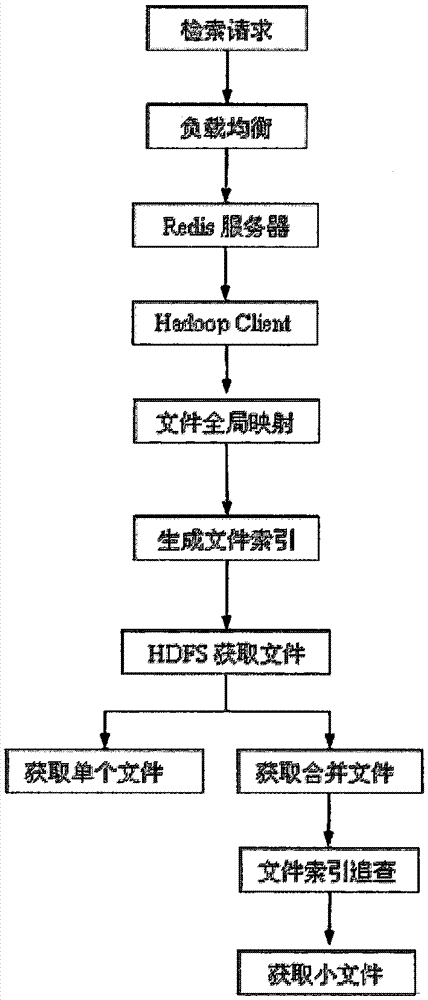
步骤五:建立图片索引。图片名用的是联合编码的方式,主要包含BlockId和FileId两部分。其中BlockId代表的是一个存储单元,NameNode可以根据其确定最近的DateNode地址,FileId代表的是小图片在拼接的时候SequenceFile的Id;offset代表的是相应key值的一个的偏移量。HDFS前端在接收到客户端的请求后首先会解析文件名,根据相关信息定位到相应的Block文件、FileId和offset,然后客户端直接对图片进行读取。在对文件名解析以后,可以直接读取DateNode节点数据,并可以通过偏移量定位到图片的开始位置。
步骤六、客户端以图片名称和创建时间为参数发起访问请求,NameNode运算获取图片所在分钟时间段和合并文件对应的Blocks信息,返回给客户端。客户端向最近的DataNode发起图片读取请求。DataNode运算获得图片具体地址信息。
本发明与现有技术相比,其有益之处在于:本发明可以很好的解决Hadoop检索海量图片时NameNode内存消耗过度和检索效率低下的问题,并有效降低了检索时的NameNode负载,实现了对NameNode性能的提升,从而推动hadoop平台更广泛的应用。
附图说明
图1是图片存储流程图。
图2是图片检索流程图。
具体实施方式
以下参照附图1至图2,给出本发明的具体实施方式,用来对本发明做进一步说明。
实施例1:
第一:部署Hadoop集群。部署好系统之后,检查网络,确保集群中的各个机器能相互通信。安装SSH,配置SSH免密码登录。把IP主机映射关系添加到etc/hosts文件末尾,安装Java环境。在conf/hadoop-env.sh末尾添加export JAVA_HOME=/usr/jdk1.6.0把testA添加到master文件中,把test1、test2、test3添加到slaves文件中修改conf/core-site.xml文件。
第二:安装Redis。下载Redis,并拷贝到相应目录下,安装编译并启动服务。
第三:安装HAProxy。下载haproxy,并拷贝到相应目录下,编译安装。
第四:客户端首先向NameNode发起写数据请求,通过负载均衡模块过滤,首先来到应用服务器排队等待进入HDFS存储系统,请求达到NameNode后,NameNode根据DataNode上的可写块、容量和负载加权平均来选择一个可写的Block和可以写Block的DataNode,信息返回到客户端。
第五:客户端从NameNode返回的DataNode集合中选择一个作为Master,该值由DataNode的负载以及当前作为Master的次数来确定,使得每个DataNode作为Master的机会均等。Master-段选定,除非Master宕机,不会再更换。一旦Master宕机,需要在剩余的DataNode中选择新的Master。
第六:客户端将数据写入Master,Master再依照HDFS的并行写数据过程写入到Slave A和Slave B。等到所有的数据写入过程都结束,Master将Block信息报告给NameNode。NameNode接收Block信息并返回写操作完成信息。
第七:读请求通过负载均衡到达图片服务器,请求先通过Redis缓存模块检查缓存区是否包含图片信息,否则要到HBase检索图片信息,并将检索结果写入到缓存区。
第八:请求到达HDFS请求读取图片内容。图片命名设计为Blockid加Block中的Fileld和offset偏移量,HBase根据图片文件名查询出图片的名字、描述等相关信息。
第九:NameNode维护Block和DataNode之间的映射信息,NameNode根据请求解析中的Block确定该Block在DataNode信息。
第十:客户端根据NameNode给出的DataNode地址取得Block后,根据Fileld检索获取图片信息。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!