异构计算系统及其方法与流程
本发明涉及异构计算,更具体地,涉及一种高能效的异构计算架构。
背景技术:
根据登纳德缩放定律(Dennard Scaling),电压和电流应该正比于晶体管的线性尺寸,并且功耗(亦即,电压和电流的乘积)应该正比于晶体管的面积。随着晶体管的尺寸不断缩小,可以放入芯片上同一面积的晶体管数量已经呈现指数级增长。因此,先前预测每瓦特(watt)所产生的计算性能同样也可呈现指数级增长。但是,在过去十年间,登纳德缩放定律似乎已经失效。尽管晶体管的尺寸不断缩小,但是每瓦特的计算性能并未能按照同样的速率增长。登纳德缩放定律的失效具有多种原因。其中一个原因是,在小尺寸下,电流泄露可导致芯片变热,而这会增加能量成本和热失控的风险。为了防止热失控并满足给定的热设计功耗(thermal design power,TDP)限制,芯片上的一部分硅不能在标称工作电压下上电。这一现象被称为“暗硅(dark silicon)”,其显著地限制了现今的处理器中每瓦特的计算性能。
登纳德缩放定律的瓦解已经促使一些芯片制造商寻求多核心处理器设计。然而,即使是多核心处理器也遇到同样的“暗硅”问题。依据处理器架构、冷却技术和应用工作负载,暗硅的数量可能超过50%。因此,有必要提升现今计算机系统的能量效率和计算效率。
技术实现要素:
有鉴于此,本发明提出一种异构计算系统及其方法。
本发明一实施例提供一种异构计算系统(heterogeneous computing system)。该异构计算系统包括任务前端(task frontend)和多个执行单元(execution unit),其中,任务前端根据与多个队列相关的特性从多个队列中调度多个任务和更新后的多个任务用以执行,多个执行单元包括第一子集和第二子集,第一子集充当生产者(producer)用以执行多个任务并生成更新后的多个任务,且第二子集充当用户(consumer)用以执行更新后的多个任务。多个执行单元包括用以执行控制操作的控制处理器、用以执行矢量操作的矢量处理器、以及用以执行多媒体信号处理操作的加速器中的一个或多个。该异构计算系统还包括包含有所述队列的存储器后端(memory backend),用以存储多个任务和更新后的多个任务供多个执行单元进行执行。
本发明另一实施例提供一种由包括多个执行单元的异构计算系统执行的方法。该方法包括:任务前端根据与多个队列相关的特性从多个队列中调度多个任务和更新后的多个任务用以执行;多个执行单元的第一子集充当生产者以执行所调度的任务以生成更新后的多个任务;以及多个执行单元的第二子集充当用户执行所调度的更新后的多个任务。执行单元包括用以执行控制操作的控制处理器、用以执行矢量操作的矢量处理器、以及用以执行多媒体信号处理操作的加速器中的一个或多个。
本发明提出的异构计算系统及其方法,可提升计算机系统的能量效率和计算效率。
附图说明
本发明通过实例的方式来进行阐述,这些实例可如附图所示,附图中类似的标号代表类似的元件。然而,可以理解的是,这些实例并不构成 对本发明的限制。应该注意的是,本发明中于不同处所引用的“一”实施例并不一定指同一个实施例,这种引用意味着至少一个实施例。另外,当结合一实施例描述某特定的特征、结构或特性时,应当认为,结合其他的实施例以实现这种特征、结构和特性是在本领域熟练技术人员的知识范畴之内的,而无论是否明确说明。
图1为本发明一实施例所揭示的一种异构计算系统架构的方块图。
图2为本发明一实施例所揭示的一种异构计算系统中的执行单元复合体(execution unit complex)的方块图。
图3为本发明一实施例所揭示的一种任务图(task graph)的实例示意图。
图4为本发明一实施例所揭示的一种异构计算系统中的统一任务前端和存储器后端的示意图。
图5为本发明一实施例所揭示的用于立体视觉处理(stereo vision processing)的任务图的实例示意图。
图6为揭示图5所示的立体视觉实例中分配任务至队列中的示意图。
图7为本发明一实施例所揭示的由异构计算系统执行的一种方法的流程图。
具体实施方式
在下面的描述中,将列举大量的具体细节。然而,应该理解的是,本发明的实施例可以脱离这些具体细节而实施。在其他情况下,为了更清晰地阐释本发明的思路,本发明并没有详细地描述熟知的电路、结构和技术。但是,本领域熟练技术人员可以理解的是,本发明可以脱离这些具体细节而实施。且本领域的技术人员在阅读本发明的说明书后,无需过多的试验即可实现本发明。
一种异构计算系统包括多于一种类型的处理引擎协同工作以执行计算任务。举例而言,异构计算系统可包括多个处理引擎如一个或多个中央处理单元(central processing unit,CPU)、一个或多个图形处理单元(graphics processing unit,GPU)、一个或多个数字信号处理器(digital signal processor,DSP)等等。在一些实施例中,处理引擎可全部集成至片上系统(system-on-a-chip,SoC)平台中。多个处理引擎可通过互联器(interconnect)与彼此和系统存储器进行通信。在片上系统平台上,这种互联器可被称为SoC结构(SoC fabric)。
举例而言,异构计算系统可包括多个CPU、GPU和DSP的组合。CPU执行通用计算任务,DSP执行信号、图像和多媒体处理任务的组合。GPU执行图形处理任务,例如,创建3D场景的2D光栅化表征。这些图形处理任务被称为3D图形管线操作或者渲染管线操作。3D管线操作可通过固定功能硬件(fixed-function hardware)和通用可编程硬件(general-purpose programmable hardware)的组合来实现,其中,固定功能硬件专门定制用来加快计算,而通用可编程硬件用来提供图形渲染中的灵活性。通用可编程硬件也被称为着色器硬件(shader hardware)。除了图形渲染以外,着色器硬件也可执行通用计算任务。
在异构计算系统的一个实施例中,CPU通过统一任务前端和存储器后端分配任务至GPU和DSP的执行单元。执行单元是执行GPU或DSP的某一特定功能的通用或者专用处理器。一组执行单元(也称为执行单元复合体)作为一个整体来执行GPU和DSP的功能,并共享统一前端和存储器后端。该异构计算系统具有细粒化架构(fine-grained architecture),亦即,每一个执行单元执行任务的一个单元(也称为分组(packet))以执行对应功能,然后将其传递至该分组的下一个用户。如后续将进一步描述的,该细粒化架构可最大限度地减小系统存储器流量, 并可节省能量。在一实施例中,异构计算系统可包括三种类型的执行单元:用于排序和分支控制的控制处理器、用于数据并行工作负荷的矢量处理器、和一组用于特定的固定功能工作负荷的加速器。
本发明所描述的异构计算系统提高了能量效率,这源于其所使用的架构设计最大限度地利用了任务并行、数据并行和生产者-用户局部性(producer-consumer locality)机制。任务并行是指不同的执行单元或者同一执行单元的不同处理器核心对不同的任务(如,进程和线程)进行处理。数据并行是指矢量处理器对数据矢量进行处理。在一实施例中,每个矢量处理器为一个执行单元。生产者-用户局部性是指生产者执行单元的中间输出通过本地路径如通过高速存储器(例如,二级高速缓存(level-2cache))流向用户执行单元,从而最大限度地减小系统存储器流量并节省能量。CPU并不干预生产者执行单元和用户执行单元之间的数据传输,相反地,数据传输是通过自身入队(self-enqueue)和交叉入队(cross-enqueue)机制进行处理的。每个执行单元可以是生产者执行单元或者用户执行单元,或者同时即是生产者执行单元又是用户执行单元。当生产者执行单元和用户执行单元是同一个执行单元时,生产者-用户局部性可通过自身入队机制进行处理;当生产者执行单元和用户执行单元是不同的执行单元时,生产者-用户局部性可通过交叉入队机制进行处理。在一实施例中,无论是自身入队还是交叉入队均可由统一任务前端进行管理,亦即,统一任务前端在没有CPU干预的情况下,在多个执行单元之间进行任务分配的调度和同步。因此,CPU可对任务分配执行“发射后不理(fire and forget)”机制,也就是说,CPU将初始任务分配写入至存储器后端中,然后由统一任务前端接管后续的任务调度和同步。
图1为本发明一实施例所揭示的异构计算系统100的架构实例的方块图。系统100包括执行单元复合体(execution unit complex)110。执行 单元复合体110进一步包括多个执行单元112,并连接至统一任务前端120(也称为任务前端)和存储器后端130。存储器后端130包括被执行单元112所共享的高速缓冲存储器160(例如,二级高速缓存或者其他级别的高速缓冲存储器)和系统存储器150(例如,动态随机存取存储器(DRAM)或者其他易失性或非易失性随机存取存储器)。CPU复合体140包括一个或多个CPU处理器核心,并通过互联从设备(interconnect slave)141如SoC结构从设备(SoC fabric slave)连接至任务前端120。CPU复合体140还通过互联主设备(interconnect master)142如SoC结构主设备(SoC fabric master)连接至存储器后端130。互联主设备142充当推送数据至目的地的主设备(master)的角色,互联从设备则充当接收数据的从设备(slave)的角色。虽然互联从设备141和互联主设备142显示为两个单独的方块,但是在一些实施例中,从设备141和主设备142可均为同一个互联硬件的一部分。
在一实施例中,执行单元复合体110中的每一个执行单元112均用以从任务前端120中接收任务单元(也称为分组),执行该分组,并输出更新后的分组至存储器后端130中。更新后分组也可称为更新后任务。更新后任务可被发送至任务前端120,而任务前端120又转而发起更新后任务至执行单元复合体110中合适的用户执行单元。用户执行单元对更新后任务进行进一步更新,因此,从存储器后端130开始经由任务前端120至执行单元112最后返回至存储器后端130的执行周期将持续进行直到所有的任务均已完成。
在一实施例中,异构计算系统100可为移动计算和/或通信设备的一部分,移动计算和/或通信设备如,智能手机、平板电脑、笔记本电脑、游戏设备等等。在一实施例中,异构计算系统100可为台式计算系统、服务器计算系统或云计算系统的一部分。
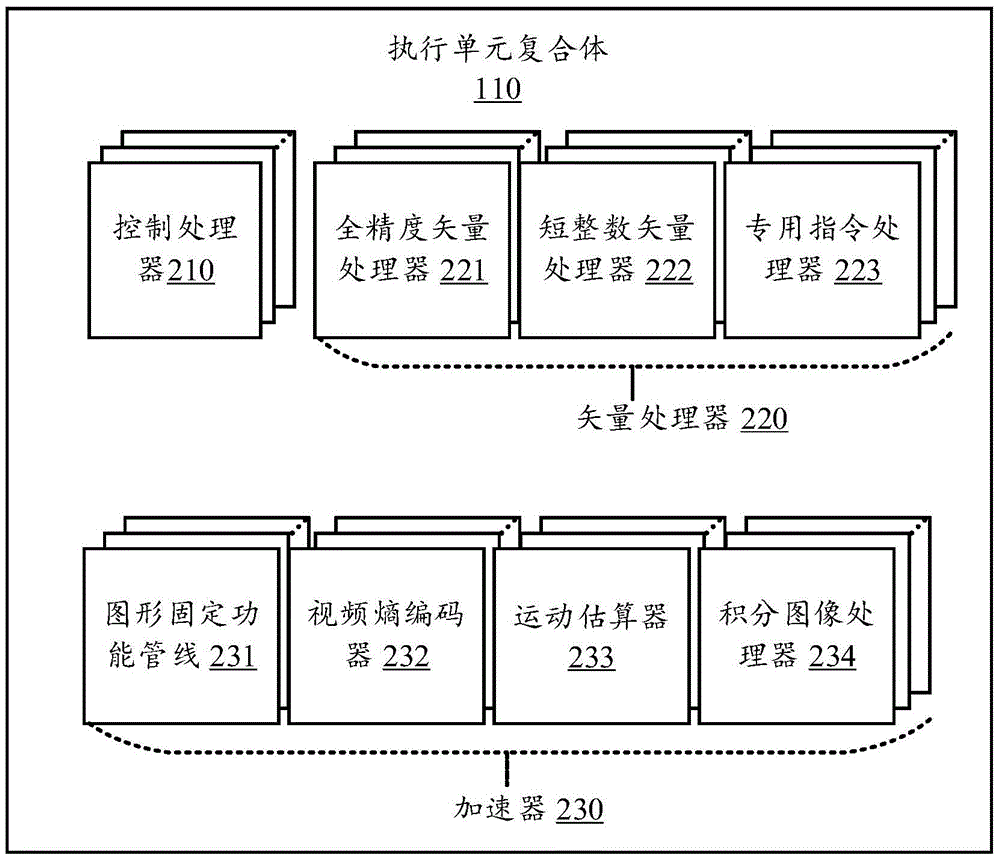
图2为本发明一实施例所揭示的执行单元复合体110的实例的方块图。在该实例中,执行单元复合体110包括多个具有GPU和DSP的功能的执行单元。执行单元的实例包括但不限于:一个或多个用以执行控制操作的控制处理器210、用以执行矢量操作的矢量处理器220,以及用以执行多媒体信号处理操作的加速器230。控制操作的实例包括但不限于:if-then操作,while循环等等。矢量处理器220的实例包括但不限于:全精度矢量处理器221、短整数矢量处理器222和专用指令处理器223。短整数矢量处理器222可包括为不同的短整数类型而优化的矢量处理器,而专用指令处理器223是专有用途处理器,其执行的操作包括但不限于:正弦、余弦、对数以及其他的数学运算。加速器230的实例包括但不限于:图形固定功能管线231、视频熵编码器(video entropy coder)232、运动估算器(motion estimator)233、数字信号处理器和图像处理器如积分图像处理器(integral image processor)234。加速器230可包括为图形管线处理而优化的专有用途硬件。虽然图2所示的实例揭露了每一种执行单元类型(例如,控制处理器210、全精度矢量处理器221、短整数矢量处理器222、专用指令处理器223、图形固定功能管线231、视频熵编码器232、运动估算器233、积分图像处理器234)的多个实例,应该理解的是,每一种执行单元类型可包括任意数量的实例。
在一实施例中,矢量处理器220提供GPU中着色器的功能,同时支持额外的数据类型如多个短整数类型。加速器230提供GPU中固定功能管线的功能,同时支持额外的信号和图像处理。将信号和图像处理能力整合至执行单元复合体110中提升了系统100的能效,这是因为更多类型的执行单元可参与到任务并行、数据并行和生产者-用户局部性机制之中。
图3为本发明一实施例所揭示的任务图300的实例示意图。任务图 300代表了要在计算系统中运行的任务之间的依赖关系,所述计算系统可如图1所示的计算系统100。在该实例中,每一个方块代表一个任务,且方块之间的每一条有向线代表依赖关系。两个或更多的任务可被分配至同一个执行单元或者不同的执行单元,例如,两个或更多的视频编码任务可被分配至同一个视频编码加速器或者不同的视频编码加速器。任务图300有助于辨认任务并行、数据并行和生产者-用户局部性。举例而言,生产者-用户局部性可存在于方块C和方块F中,两方块之间的关系通过虚线310示出。任务并行可存在于方块C和方块D中,两方块之间的关系通过虚线320示出。数据并行可存在于发生矢量计算的任意方块A-G中。
在一实施例中,系统100的CPU复合体140可为将被执行单元所执行的任务生成任务图。根据该任务图,CPU复合体140确定将要生成多少个队列以及如何将队列映射至执行单元。在一实施例中,CPU复合体140充当主生产者从而将任务以任务数据结构(例如,分组)的形式写入至队列中。在一实施例中,分组包括但不限于,任务的大小、指向参数缓冲区(argument buffer)的指针(pointer)、指向任务的程序代码的程序(指令)指针。CPU复合体140还通过将依赖关系信息嵌入至分组和队列中从而对依赖关系进行监管。在一实施例中,分组可包含目的队列的标识符,如此,在生产者执行单元执行完分组之后,生产者执行单元便可将更新后的分组写入至用于用户执行单元的目标队列中。
图4为本发明一实施例所揭示的任务前端120与执行单元复合体110和存储器后端130进行交互的进一步细节的示意图。请同时参照图1,在一实施例中,存储器后端130包括多个队列410。队列数据存储在高速缓冲存储器160中,且队列数据可根据高速缓存替换策略(cache replacement policy)被移动至系统存储器150中。每一个队列410均具有一个相关的 读取指针(RP)和一个相关的写入指针(WP)用以指明当前的读取和写入位置。虽然图中示出了8个队列,但是,应该理解的是,存储器后端130可包括任意数量的队列。
在一实施例中,执行单元复合体110中的执行单元从队列410中接收分组,并将执行结果(即,更新后的分组)写回至队列410中。每个队列仅被指派至一个用户执行单元,且多个队列可被指派至同一个用户执行单元。生产者执行单元可将其执行结果写入至任意队列中。在实际操作中,生产者执行单元将其执行结果写入至被指派至该执行结果的用户的一个或多个队列。生产者-用户局部性通过自身入队和交叉入队的方式加以利用:执行单元可通过将其执行结果写入至其自身队列中从而实现自身入队,并且两个或者更多的执行单元可通过其中一个执行单元将其执行结果写入至指派给另外一个执行单元的队列中从而实现交叉入队。
在一实施例中,CPU复合体140生成任务图(该任务图的实例示于图3),该任务图描述将要执行的任务。基于该任务图,CPU复合体140确定所要创建的队列的数量以及这些队列与执行单元之间的映射关系。然后,CPU复合体140将队列在存储器后端130中的位置连同队列与执行单元之间的映射关系通知给任务前端120。之后,CPU复合体140将任务写入至队列410中。由于CPU复合体140不能直接访问高速缓冲存储器160,因此,CPU复合体140可通过互联主设备142将任务写入至系统存储器150中映射至恰当执行单元的恰当队列所对应的存储位置。
CPU复合体140在完成了任务写入操作之后,便向任务前端120中的门铃控制器(doorbell controller)420发送门铃信号(doorbell signal)并附带写入索引(index)更新信号。本文件中的术语“索引”和“指针”可以互换使用。门铃控制器420监控每个队列410的读取和写入指针。当生产者执行单元完成了对一个队列410的写入操作之后,其还发送门 铃信号(图4中示为内部门铃)至门铃控制器420中。在一实施例中,当对一个队列执行写入操作时,门铃控制器420对写入索引进行更新。此外,生产者执行单元可直接对写入索引进行更新。在一实施例中,生产者(例如,执行单元或者CPU)可将门铃信号写入至与当前被写入的队列相关的内存映射I/O(memory-mapped I/O,MMIO)寄存器中。写入动作可触发信号(图4中为MMIO门铃)发送至门铃控制器420。
当用户执行单元执行完分组之后,便向门铃控制器420发送完成信号。然后,门铃控制器420对该分组从中被读取的队列的读取索引进行更新。当读取索引等于写入索引时,即表明该队列中没有待执行的分组。该队列的用户执行单元可能正在等待来自另外一个执行单元的执行结果,或者可能已经完成了其所有的任务。当每一个队列的读取索引均等于其写入索引时,即表明执行单元对任务的执行已经结束。
在一实施例中,任务前端120进一步包括读取控制器430、指针控制器440和预取控制器450,用以管理来自队列410的读取操作。指针控制器440根据从门铃控制器420发送来的索引从而为每一个队列410维护一个本地读取和写入指针(图中示为CRP/CWP)的列表。在一实施例中,指针控制器440指示预取控制器450,而预取控制器450转而指示读取控制器430以从队列410中预取分组至用于临时存储的内部缓存470(例如,静态RAM(SRAM))中。读取控制器430根据从预取控制器450发送来的读取索引而从一个队列410中读取该读取索引所指向的位置处的分组。在一实施例中,可按照轮回(round-robin)方式或者按照预定计划对队列410执行预取操作。
任务前端120进一步包括仲裁器460。仲裁器460判断哪个分组(内部缓存470中的分组)被发送至执行单元中,并且使用该分组的地址从内部缓存470中读取该分组。该判断操作可以根据轮回、分组停留在内 部缓存470中的时间、或者预定计划而进行。执行单元在接收到该分组之后,即执行所需的操作并将输出(亦即,更新后的分组)写入至被指派给该分组的下一个用户的队列中。执行单元可对该队列的写入索引进行更新,或者发送信号至门铃控制器420以指示其对该写入索引进行更新。
应该指出的是,在图4所示的实施例中,CPU仅在任务开始执行时将任务写入至队列中。任务的执行充分利用了执行单元之间的生产者-用户局部性,其中并不存在CPU的干预。多个执行单元可以并行的方式执行各自的任务,从而充分利用任务并行机制。此外,可通过将矢量计算任务分配至具有矢量处理器的执行单元从而充分利用数据并行机制。
图5为本发明一实施例所揭示的用于立体视觉处理的任务图500的实例示意图。所述立体视觉处理可由图1所示的系统100执行。所述立体视觉处理使用两台摄像机在两个不同角度所产生的图像从而产生3D图像。该任务图500包括立体纠正及重映射方块511和521,其从各自的摄像机接收校准信息作为输入,并调整摄像机的输出图像以对齐图像。任务图500进一步包括深度图计算方块512,其从对齐后的图像中生成3D深度信息。
任务图500进一步包括图像金字塔方块522,其生成具有不同尺度下的层次结构的图像。图像金字塔方块522的输出被馈送至帧中继523中用以生成延迟图像,同时也被馈送至光流计算方块524中。光流计算方块524将前一帧(亦即,延迟帧)与当前帧进行比较以生成代表每一个图形对象的特征和角度的光流,并确定每一个图形对象的运动、尺寸和边缘。来自光流计算方块524的光流可与来自深度图计算方块512的3D深度进行结合以通过检测并追踪对象530生成用于追踪对象的对象坐标550。
图6为本发明一实施例所揭示的用于处理图5所示的任务图500的一种队列结构的实例示意图。该实例使用三个互相之间具有依赖关系(显示为虚线)的队列。其中,队列_0包括立体纠正及重映射内核;队列_1包括立体纠正及重映射内核、图像金字塔、计算光流;队列_2包括等待队列_0和队列_1完成立体纠正和重映射、计算深度图、等待光流计算完成、检测并追踪对象。从属任务等待其父任务完成。在该实例中,该三个队列可被分配至三个不同的以并行方式工作的执行单元(如,用户执行单元)。例如,队列_0和队列_1中的每一个可被分配至加速器(例如,图2所示的加速器230其中之一)或者着色器(例如,图2所示的矢量处理器220其中之一),且队列_2可被分配至着色器。在一实施例中,该三个执行单元可连接至图4所示的任务前端120和存储器后端130,用以充分利用生产者-用户局部性、任务并行和数据并行机制。
图7为本发明一实施例所揭示的由包括多个执行单元的异构计算系统(如,图1所示的系统100)所执行的方法700的流程图。请参照图7,方法700的起始步骤为:任务前端根据与多个队列相关的特性从队列中调度任务和更新后任务用以执行(方块710)。方法700进一步包括步骤:执行单元的第一子集充当生产者执行所调度的任务以生成更新后任务(方块720)。该方法进一步包括步骤:执行单元的第二子集充当用户执行所调度的更新后任务。执行单元包括一个或多个的用以执行控制操作的控制处理器、用以执行矢量操作的矢量处理器、以及用以执行多媒体信号处理操作的加速器(方块730)。
图7所示的流程图中的操作已经参照图1、图2和图4所示的范例性实施例进行描述。然而,应该理解的是,图7所示的流程图中的操作可通过本发明的未参照图1、图2和图4进行讨论的其他实施例来执行,而参照图1、图2和图4所讨论的实施例同样可以执行不同于参照流程图所 讨论的操作的其他操作。虽然图7所示的流程图显示了本发明的某些实施例所执行的操作的特定顺序,但是,应当理解的是,所述特定顺序仅是示例性的(例如,备选实施例中可按照不同的顺序执行这些操作,将特定操作进行组合,覆盖某些操作等等。)。
尽管本发明已经通过若干实施例进行描述,然而,本领域的熟练技术人员将会认识到,本发明并不限于上面所描述的实施例,而且本发明还可在不背离所附权利要求的精神和范畴的前提下进行修改和变更进而实施。因此,本说明书应理解为解释性质而不是限制性质。
- 还没有人留言评论。精彩留言会获得点赞!