用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法和系统与流程
本发明涉及乙肝相关肝硬化的分类方法和系统,具体来说涉及用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法和系统。
背景技术:
我国是病毒性肝炎大国,尤以乙肝患者人数居多。其中乙肝携带者约占总人口的8-10%,其中约有25%发展为慢性乙型肝炎、乙肝相关肝硬化,10%左右发展为肝细胞肝癌(HCC)。乙型肝炎病毒的感染不仅给人民带来了严重的健康危害,而且治疗等疾病相关费用也给患者和国家、社会带来巨大经济负担。
目前肝硬化临床诊断手段主要包括组织病理活检、FibroScan、彩色多普勒超声、CT、胃镜、血浆学指标等。但是这些单一技术或指标的临床应用都存在一些局限性和不足,均不能准确、及时诊断肝硬化进展程度,使得对肝硬化的分期诊断仍有赖于肝穿活检病理标准,临床迫切需要一个/一组方便、及时、无创的肝纤维化、肝硬化分级诊断指标。
microRNA(miRNA)最初发现于1993年,随着高通量测序技术的发展,近年来逐渐成为研究热点。microRNA能够结合于基因序列的侧翼区域阻遏或抑制靶mRNA的翻译,且具有高度的保守性、时序性和组织特异性。近年来的研究表明,肝炎病毒感染、慢性肝炎、肝硬化和microRNA密切相关,microRNA可以通过作用于病毒本身或作用于免疫系统从而影响疾病进程。研究表明,病毒感染的肝病患者microRNA表达谱和健康人组织的microRNA表达谱有明显不同。研究者们还发现在人类血清/血浆中存在大量稳定的小的核糖核酸分子,即microRNA,这为临床上通过检测血清/血浆中microRNA分子表达量诊断肝硬化奠定了基础。
综上所述,研究者们虽然已在该领域进行了研究,但是仍面临许多困难和挑战,均未能准确、及时诊断肝硬化进展程度。运用血清/血浆中microRNA标志物表达水平高低,为肝硬化诊断研究提供了新的思路。但目前尚未有关于肝硬化microRNA标志物或其组合表达变化的深入研究,仍需寻找可有效判断肝硬化的microRNA标志物或其组合,特别是能将乙肝相关肝硬化与慢性乙型肝炎区别开来的microRNA标志物或其组合,以及基于得到的microRNA标志物组合表达水平,用数学模型构建一种合适且准确的乙肝相关肝硬化分类方法和系统。与传统的肝硬化以及乙型肝炎的诊断方法相比,使用microRNA标志物或其组合的方法具有更快速准确的优点。
技术实现要素:
本发明的一个目的是提供了一种用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法,包括以下步骤:
a)使用训练集数据,建立原始数据库;
b)将上述训练集采用两层分类模型;
c)通过对上述训练集进行特征选择和数据优化构建并优化所述的逻辑回归数学模型;
d)进行预测评估;
e)根据预测评估结果选择最优模型并建立最终的分类方法;
f)收集独立的测试集样本用于模型的检验和评估。
优选地,所述的训练集包含基于血浆microRNA标志物表达的Ct值和临床指标的样本数据;所述的两层分类模型包括关于由慢性乙型肝炎/肝硬化和健康对照组成的肝病和健康分类模型(模型DH)以及关于慢性乙型肝炎和乙肝相关肝硬化分类模型(模型AB);所述的特征选择采用信息增益算法对训练集特征进行排序来选择贡献度高的特征作为候选microRNA标志物;所述的数据优化的方式为对所述的训练集中的数据进行质量控制和去端值,去掉试验中由于误差导致的极端值,用逻辑回归方法构建所述的逻辑回归数学模型,将多个microRNA分子标志物组合用公式表达:
h(x)=hθ(x)=θ0+θ1x1+θ2x2+...+θnxn
其中x1,x2,...,xn是所选取的n个特征,θ0,θ1,θ2,...θn是通过训练集得到的各个特征的系数。
本发明的第二个目的是提供了一种用于肝病分类的分类的系统,包括数据库模块、质量控制模块、模型分类模块,其中:所述数据库模块包含作为训练集的原始数据库以及后续收集的盲测数据库;所述质量控制模块为将由于实验误差导致的极端值去除的模块;所述模型分类模块包括关于由慢性乙型肝炎/肝硬化和健康对照组成的肝病和健康之间的分类模型(模型DH)以及关于慢性乙型肝炎和乙肝相关肝硬化之间的分类模型(肝炎或肝硬化)。所述的肝病为乙肝相关肝病。
优选地,所述的数据库模块中包含486例用作训练集的原始数据库以及后续收集的盲测数据,其中每一例的样本包括miR-122-5p、miR-21-5p、miR-146a-5p、miR-29c-3p、miR-381-3p、
miR-223和miR-22-3p的Ct表达值,以及临床指标转氨酶(ALT)、白蛋白(ALB)和HBV病毒DNA的值。
所述质量控制模块通过质量控制将由于实验误差导致的极端值去除,所述的非极端值的范围定义为:模型DH中,标志物miR-381-3p的Ct值范围为19.40-32.10,标志物miR-22-3p的Ct值范围为16.72-26.86,标志物miR-146a-5p的Ct值范围为19.32-29.16;模型AB中,标志物miR-122-5p的Ct值范围为17.61-26.99,标志物miR-21-5p为16.79-24.47,标志物miR-146a-5p为19.31-26.64,标志物miR-29c-3p为18.57-26.18,标志物miR-381-3p为20.13-27.87,标志物miR-223为15.35-24.15,标志物miR-22-3p为16.71-23.95。
模型分类模块的建模的算法为逻辑回归将多个microRNA分子标志物组合用公式表达,其中区分健康和肝病(DH)的算法公式为:
hDH(x)=-1.972X(miR-381-3p)+0.0079X(miR-22-3p)–1.6462X(miR-146a-5p)+74.495
根据最大概率分类可确定的阈值为:
D肝病(慢性乙型肝炎/肝硬化)类:hDH(x)>0;
H健康类:hDH(x)<0;
其中区分乙肝相关肝硬化和慢性乙型肝炎(AB)算法公式为:
hAB(x)=1.1925X(miR-122-5p)+0.3978X(miR-21-5p)+0.3726X(miR-146a-5p)–
1.7062X(miR-29c-3p)+0.1303X(miR-223)+0.8156X(miR-22-3p)–0.1432X alb–
0.3608X dna–0.0041X alt–23.9918
A乙肝相关肝硬化类:hAB(x)>0
B慢性乙型肝炎类:hAB(x)<0。
本发明的用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法和系统的优点是提供了一种利用数据库算法和公式,使用microRNA标志物表达Ct值及常见临床指标,自动快速提供乙肝相关肝硬化和慢性乙型肝炎的分类以及结果。
附图说明
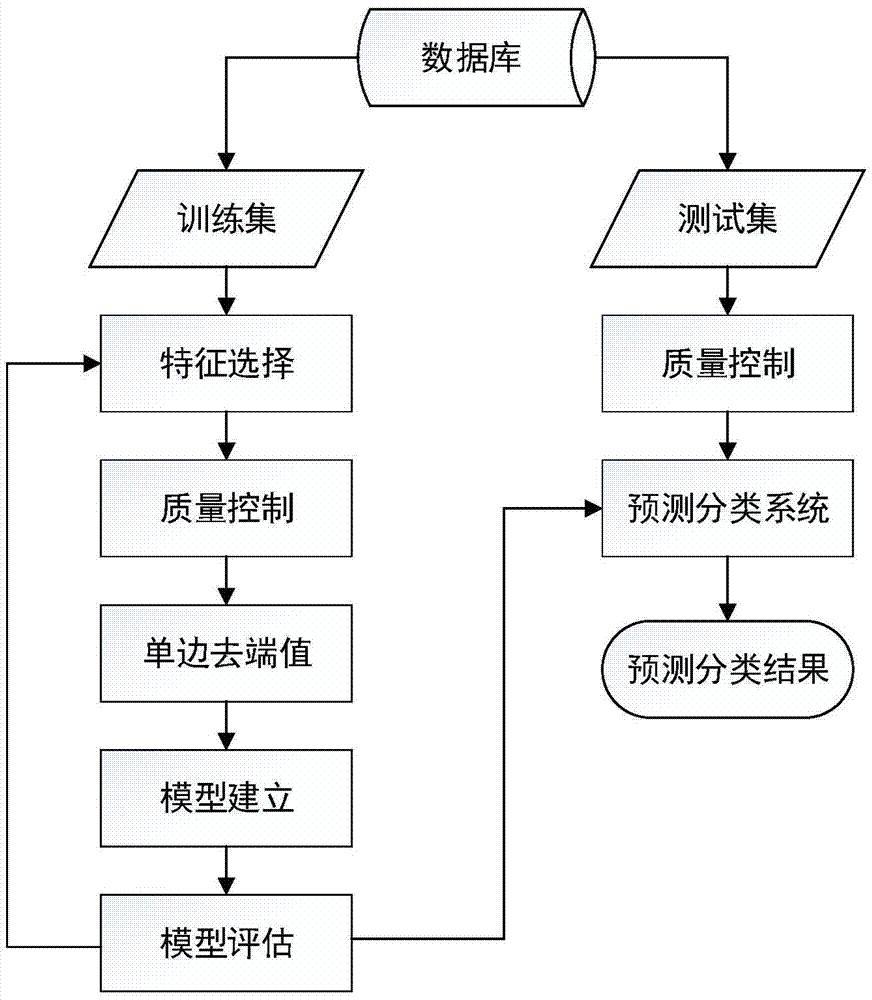
图1示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法的建立的实施例的流程图。
图2示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统中单层的分类模型的实施例的流程图。
图3示例性的示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统中模型DH特征选择交叉验证结果图。
图4示例性的示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统中模型AB质量控制前后交叉验证结果对比图。
图5示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统中实施例的流程图。
具体实施方式
本发明通过具体实施例和附图进一步阐述本发明的技术方案,但是本领域普通技术人员可以理解的是:以下具体实施方式以及实施例旨在阐述本发明,而不应理解为以任何方式限制本发明。
本发明一个方面是一种新型的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法。
本发明第二个方面提供了用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类系统。
本发明的技术方案是:本发明建立了一种用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法,包括:
收集大量慢性乙型肝炎、乙肝相关乙肝相关肝硬化和健康样本数据并建立原始数据库;
采用两层分类模型依次区分健康和慢性乙型肝炎、乙肝相关肝硬化;
通过特征选择和数据优化等方式利用训练集构建并优化逻辑回归模型,经过评估后选择最优模型建立最终的分类方法;
收集独立的测试集样本用于模型的检验和评估。
根据本发明的用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法的一实施例,所述的采用两层分类模型,第一层为肝病(慢性乙型肝炎/肝硬化)和健康分类模型(模型DH),第二层为乙肝相关肝硬化和慢性乙型肝炎分类模型(模型AB)。
根据本发明的用逻辑回归数学模型对进行基于血浆microRNA标志物表达水平的进行乙肝相关肝硬化分类的方法的一实施例,所述的通过特征选择和数据优化等方式利用训练集构建并优化逻辑回归模型,特征选择采用信息增益算法对训练集特征进行排序,得到的数据即各个特征的贡献度指标,贡献度高的特征可作为候选microRNA标志物。通过对训练集进行质量控制、单边去端值等方式处理和优化数据,并建立逻辑回归模型,并进行交叉验证评估模型的准确度。将上述过程不断循环得到准确率最佳的模型。
上述逻辑回归模型公式为:
h(x)=hθ(x)=θ0+θ1x1+θ2x2+...+θnxn
其中x1,x2,...,xn是所选取的n个特征,θ0,θ1,θ2,...θn是通过训练集得到的各个特征的系数。
本发明还揭示了一种用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的肝病分类的系统,包括数据库模块、质量控制模块、模型分类模块,其中:
所述数据库模块,包括用作训练集的原始数据库,以及后续收集的盲测数据;
所述质量控制模块,将由于实验误差导致的极端值去除;
所述模型分类模块,采用两层分类模型(健康和肝病(慢性乙型肝炎/肝硬化),乙肝相关肝硬化和慢性乙型肝炎)判定最终的样本分类。
根据本发明的用逻辑回归数学模型对进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法,所述的数据库模块中存储有包括486例用作训练集的原始数据库,包括150例乙肝相关肝硬化样本,150例慢性乙型肝炎样本,186例健康样本;以及后续收集的盲测数据。每个样本分别包括7个microRNA(miR-122-5p、miR-21-5p、miR-146a-5p、miR-29c-3p、miR-381-3p、miR-223和miR-22-3p)的表达值,以及三个临床指标的含量值(ALT、ALB和DNA)。
根据本发明的用逻辑回归数学模型进行基于血浆microRNA标志物表达水平的乙肝相关肝硬化分类的方法,所述质量控制模块,通过质量控制将由于实验误差导致的极端值去除。非极端值的范围定义为:模型DH中,标志物miR-381-3p的Ct值范围为19.40-32.10,标志物miR-22-3p的Ct值范围为16.72-26.86,标志物miR-146a-5p的Ct值范围为19.32-29.16;模型AB中,标志物miR-122-5p的Ct值范围为17.61-26.99,标志物miR-21-5p为16.79-24.47,标志物miR-146a-5p为19.31-26.64,标志物miR-29c-3p为18.57-26.18,标志物miR-381-3p为20.13-27.87,标志物miR-223为15.35-24.15,标志物miR-22-3p为16.71-23.95。
根据本发明的用逻辑回归数学模型对进行基于血浆microRNA标志物表达水平的进行乙肝相关肝硬化分类的方法,所述的模型分类模块,采用两层分类模型(健康和肝病(慢性乙型肝炎/肝硬化),乙肝相关肝硬化和慢性乙型肝炎)判定样本分类。建模的算法为逻辑回归,将多个microRNA分子标志物组合用公式表达。其中区分健康和肝病(DH)的算法公式为:
hDH(x)=-1.972X(miR-381-3p)+0.0079X(miR-22-3p)–1.6462X(miR-146a-5p)+74.495
根据最大概率分类可确定的阈值为:
D肝病(慢性乙型肝炎/肝硬化)类:hDH(x)>0;
H健康类:hDH(x)<0;
其中区分乙肝相关肝硬化和慢性乙型肝炎(AB)算法公式为:
hAB(x)=1.1925X(miR-122-5p)+0.3978X(miR-21-5p)+0.3726X(miR-146a-5p)–
1.7062X(miR-29c-3p)+0.1303X(miR-223)+0.8156X(miR-22-3p)–0.1432X alb–
0.3608X dna–0.0041X alt–23.9918
A乙肝相关肝硬化类:hAB(x)>0
B慢性乙型肝炎类:hAB(x)<0。
本发明提供了一种用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统。本发明的分类方法和系统比传统的临床诊断方法操作简单,且快速。随着大数据时代的到来,测序技术的发展,收集到的健康和疾病的数据不断增加,本发明涉及到的方法会不断改进,得到准确率更高更好的模型。
下面结合附图和实施例对本发明作进一步的描述。
用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统中的实施例
图1示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统的实施例的流程。请参见图1,下面是对本实施例的方法中的各个步骤的详细描述。
步骤1:收集大量慢性乙型肝炎、乙肝相关乙肝相关肝硬化和健康样本数据并建立原始数据库。
在本步骤中,汇总各大医院收集的慢性乙型肝炎、乙肝相关肝硬化和健康人样本以及相关的临床指标,通过实验提取样本血液测得各样本的microRNA表达值,筛选出差异表达的microRNA分子标志物。样本数据分三类,分别是A乙肝相关肝硬化B慢性乙型肝炎H健康人。
步骤2:采用两层分类模型依次区分健康和肝病(慢性乙型肝炎/肝硬化),乙肝相关肝硬化和慢性乙型肝炎。
在本步骤中,模型分两层建立,第一层是模型DH,将乙肝相关肝硬化A和慢性乙型肝炎B归为疾病D,与健康人H分类建模;第二层为模型AB,用于乙肝相关肝硬化A和慢性乙型肝炎B分类建立模型。
步骤3:通过特征选择和数据优化等方式利用训练集构建并优化逻辑回归模型,经过评估后选择最优模型建立最终的分类方法;
在本步骤中,特征选择的方法为信息增益,对训练集特征进行排序,得到的数据即各个特征的贡献度指标,贡献度高的特征可作为候选microRNA标志物。通过对训练集进行质量控制去掉试验中由于误差导致的极端值。通过单边去端值的方式处理和优化数据,增加不同类别样本之间的区分度。利用处理好的训练集建立逻辑回归模型,并进行交叉验证评估模型的准确度。最后将上述过程不断循环得到最佳的模型。
对于逻辑回归模型,计算公式表达为:
h(x)=hθ(x)=θ0+θ1x1+θ2x2+...+θnxn
其中x1,x2,...,xn是所选取的n个特征,θ0,θ1,θ2,...θn是通过训练集得到的各个特征的系数。n为1<n≤20的整数,优选小于10。
步骤4:收集独立的测试集样本用于模型的检验和评估。
在本步骤中,收集独立的测试集样本用于模型的检验和评估,确定模型无过拟合现象。
图2示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统中单层的分类模型的实施例的流程图,从图中更清晰地了解单层的分类模型的具体细节。
对于上述的步骤,下面是四个具体的实例:
实施例1:收集大量慢性乙型肝炎、乙肝相关乙肝相关肝硬化和健康样本数据并建立原始数据库
其中,肝硬化诊断依据2000年中华医学会病毒性肝炎防治指南,具体如下:具有肝炎病毒慢性感染病史,影像学提示弥漫肝纤维化,再生结界形成,其他表现可有脾大、脾功能亢进、食管胃底静脉曲张,金标准为病理检查发现再生结节。乙型肝炎诊断依据2000年中华医学会病毒性肝炎防治指南,具体如下:肝炎病程超过半年,或原有乙型肝炎或HBsAg携带史,本次又因同一病原再次出现肝炎症状、体征及肝功能异常,但是没有肝硬化表现的患者,可诊断为慢性乙型肝炎。
在2012年6月-2014年3月期间,150个满足以上乙型肝炎定义的患者的血浆样本和150个满足以上乙肝相关肝硬化定义的血浆样本,被预先从首都医科大学附属北京佑安医院采集。经过北京旷博生物技术股份有限公司进行RNA的提取,并完成microRNA的测序分析。将得到的乙肝相关肝硬化和慢性乙型肝炎microRNA表达值集中构建成数据库,成为原始数据库的部分样本数据集。
实施例2:特征选择
特征选择的算法为信息增益,是本领域比较成熟的算法,主要借助于weka下的一个软件包,weka.attributeSelection.InfoGainAttributeEval。可以参考Mitchell,Tom M.(1997).Machine Learning.The Mc-Graw-Hill Companies,Inc.ISBN0070428077,55页至60页。具体为:将microRNA作为特征,通过weka软件包下InfoGainAttributeEval(信息增益)算法进行特征排序,得到的数据即各个特征的贡献度指标,可作为特征选用的参考。将2015年2月28日测序完成的乙肝相关肝硬化、慢性乙型肝炎和健康样本的多组microRNA数据进行特征选择,对于第一层模型DH来说,随着microRNA分子标志物的增多,模型准确率基本恒定,考虑到标志物数量和模型的准确率,最终选择贡献度排名前三的标志物,分别是miR-381-3p、miR-22-3p和miR-146a-5p,这样,模型的准确率为D 0.997,H 0.986,平均准确率为0.995。请参见图3。
实施例3:质量控制
将2015年2月28日测序完成的乙肝相关肝硬化、慢性乙型肝炎和健康样本的多组microRNA数据进行质量控制,去掉由于实验误差导致的极端值。极端值定义为:利用R中boxplot软件包做统计,大于最大值或小于最小值为极端值。将模型AB中A和B合起来做初步的质量控制,标志物miR-122-5p的Ct值范围为17.61-26.99,标志物miR-21-5p为16.79-24.47,标志物miR-146a-5p为19.31-26.64,标志物miR-29c-3p为18.57-26.18,标志物miR-381-3p为20.13-27.87,标志物miR-223为15.35-24.15,标志物miR-22-3p为16.71-23.95。通过质量控制后,训练集的准确率比质量控制前有所提高,请参见图4。
实施例4:最优模型
经过多次优化和评估确定最优模型,模型DH的最优模型的特征为3个microRNA分子标志物(miR-381-3p、miR-22-3p和miR-146a-5p),此时模型交叉验证的准确率为D 0.963,H 0.939,平均准确率为0.954。
用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类方法和系统的实施例
图5示出了本发明的用逻辑回归数学模型,进行基于7个血浆microRNA标志物组合表达水平的乙肝相关肝硬化分类的系统的组成和连接示意图。请参见图5。本实施例的系统包括数据库模块、质量控制模块、模型分类模块。
数据库模块,即存储包括用作训练集的原始数据库以及后续收集的盲测数据;
质量控制模块,是通过质量控制将由于实验误差导致的极端值去除的模块;
模型分类模块,是将健康和肝病、乙肝相关肝硬化和慢性乙型肝炎采用两层分类模型进行判定从而进行样本分类的部分。
本实施例的系统中数据库模块,存储包括486例用作训练集的原始数据库,包括150例乙肝相关肝硬化样本,150例慢性乙型肝炎样本,186例健康样本;以及后续收集的盲测数据。每个样本包括7个microRNA(miR-122-5p,miR-21-5p,miR-146a-5p,miR-29c-3p,miR-381-3p,miR-223和miR-22-3p)的表达值,以及三个临床指标(ALT、ALB和DNA)。
本实施例的系统中质量控制模块,通过质量控制将由于实验误差导致的极端值去除。极端值的范围定义为:模型DH中,标志物miR-381-3p的Ct值范围为19.40-32.10,标志物miR-22-3p的Ct值范围为16.72-26.86,标志物miR-146a-5p的Ct值范围为19.32-29.16;模型AB中,标志物miR-122-5p的Ct值范围为17.61-26.99,标志物miR-21-5p为16.79-24.47,标志物miR-146a-5p为19.31-26.64,标志物miR-29c-3p为18.57-26.18,标志物miR-381-3p为20.13-27.87,标志物miR-223为15.35-24.15,标志物miR-22-3p为16.71-23.95。
本实施例的系统中模型分类模块,采用两层分类模型(健康和肝病,乙肝相关肝硬化和慢性乙型肝炎)判定样本分类。建模的算法为逻辑回归,将多个microRNA分子标志物组合用公式表达。其中区分健康和肝病(DH)的算法公式为:
hDH(x)=-1.972X(miR-381-3p)+0.0079X(miR-22-3p)–1.6462X(miR-146a-5p)+74.495
根据最大概率分类可确定的阈值为:
D肝病(慢性乙型肝炎/肝硬化)类:hDH(x)>0;
H健康类:hDH(x)<0;
其中区分乙肝相关肝硬化和慢性乙型肝炎(AB)算法公式为:
hAB(x)=1.1925X(miR-122-5p)+0.3978X(miR-21-5p)+0.3726X(miR-146a-5p)–
1.7062X(miR-29c-3p)+0.1303X(miR-223)+0.8156X(miR-22-3p)–0.1432X alb–
0.3608X dna–0.0041X alt–23.9918
A乙肝相关肝硬化类:hAB(x)>0
B慢性乙型肝炎类:hAB(x)<0。
测试实例
为了检验本发明的系统的性能,下面使用了两组盲测数据进行验证和评估。
盲测数据1
盲测数据1是首都医科大学附属北京佑安医院于2014年2月20日完成测序的肝病样本集,包含40例样本,其中乙肝相关肝硬化样本20例,慢性乙型肝炎样本20例。
盲测数据2
盲测数据2是首都医科大学附属北京佑安医院于2015年4月1日完成测序的肝病和健康样本集,包含40例样本,其中乙肝相关肝硬化样本12例,慢性乙型肝炎样本13例,健康样本15例。
系统运行需求/环境
1.命令行形式,DOS命令行或者Linux环境下的命令行形式;
2.安装有统计软件包R。
命令行输入格式:
Rscript miRNA.R-i test_DH.txt-type DH-o test_DH_report.txt-e test_DH_poorQC.txt
Rscript miRNA.R-i test_DH.txt-type DH-v
其中,软件名为miRNA.R,-i输入文件,-type数据处理格式,-o输出文件,-e错误文件,-v直接输出在屏幕上。
例1输入文件格式
输出文件格式
结果与讨论
盲测数据1
盲测数据1只含有肝病数据40例样本,经过质量控制后还剩39例样本,将质控后的数据用于模型AB预测分析评估,详细结果请参见表1,其中,A乙肝相关肝硬化的准确率为0.90,B慢性乙型肝炎的准确率为0.737,平均准确率为0.821。绘制ROC(receiver operating characteristic)曲线,AUC(曲线下面积,ROC面积)达到0.884。
表1盲测数据1模型AB预测结果
盲测数据2
盲测数据2含有肝病和健康样本40例,对于第一层模型DH,经过初步质控,保留31例样本全部,将这40例样本数据用于模型DH预测分析评估,详细结果请参见表2,其中D肝病的准确率为0.875,H健康的准确率为1,平均准确率为0.903。绘制ROC曲线,AUC值为0.988。可以明显地看出模型DH的分类效果非常好,也比较符合临床诊断的实际情况。
表2盲测数据2模型DH预测结果
盲测数据2含有25例乙肝相关肝硬化和慢性乙型肝炎样本,经过质量控制后,还剩19例样本。将质控后的样本用于模型AB预测分析评估,详细结果请参见表3,其中,A乙肝相关肝硬化的准确率为0.90,B慢性乙型肝炎的准确率为0.889,平均准确率为0.895。绘制ROC曲线,AUC值达到0.967。
表3盲测数据2模型AB预测结果
综上所述,本发明的系统中模型DH和模型AB的预测分类准确率较高,分类效果很好,没有出现过拟合现象,可以用于实际疾病检测中的乙肝相关肝硬化诊断,且操作简单快速。
- 还没有人留言评论。精彩留言会获得点赞!