找出人群移动行为的方法与流程
本发明是有关于一种藉由收集关于用户装置的位置数据,以找出人群移动行为的方法。
背景技术:
对于许多公司与组织,例如连锁便利商店、大众运输公司、地方政府等等,知道人群于城市中或是在多个城市间如何移动可能是很重要的信息。对于这些组织而言,有许多重大的决策需仰赖关于人群在哪里以及人群从何处来又移动到何处的信息,这些决策例如是设定新的公交车路线、建造新的交通转运站、开设新的店面、以及建造城市公共设施。因此,如何有效地找出人群移动行为的相关信息,乃目前业界所致力的课题之一。
技术实现要素:
本发明是有关于一种找出人群移动行为的方法及执行此方法的非瞬时计算机可读取媒体。
根据本发明之一实施例,提出一种找出人群移动行为的方法,方法包括:收集关于多个用户装置的多个位置数据;检测这些位置数据中的多个惯常模式以产生多个代表性序列,其中各代表性序列包括至少一线段,该至少一线段在起始位置点与结束位置点之间;以及根据这些代表性序列之间的多个序列距离,将这些代表性序列分类为多个集合,以找出人群移动行为。
为了对本发明之上述及其他方面有更佳的了解,下文特举依据本发明的可实施范例,并配合所附图式,作详细说明如下:
附图说明
图1绘示以智能卡进行支付活动的一范例示意图。
图2绘示依据本发明一实施例之找出人群移动行为方法的流程图。
图3绘示一范例支付记录的示意图,支付记录相关于从多个用户装置撷取的位置数据以及时间。
图4绘示依据本发明一实施例之收集关于用户装置的位置数据的流程图。
图5A以及图5B绘示依据本发明一实施例之将支付位置以最接近的参考位置点标注的范例示意图。
图6绘示依据本发明一实施例之整理后与简化后的支付记录的示意图。
图7绘示依据本发明一实施例之检测位置数据中的惯常模式以产生代表性序列的流程图。
图8绘示依据本发明一实施例之聚合惯常模式的示意图。
图9绘示依据本发明一实施例之计算代表性序列之间的序列距离的流程图。
图10绘示依据本发明一实施例之计算第一线段与第二线段之间的线段距离的流程图。
图11绘示依据本发明一实施例之两线段之间线段距离的示意图。
图12绘示依据本发明一实施例之计算第一线段与第二线段之间平行距离的流程图。
图13绘示依据本发明一实施例之两线段之间线段距离的示意图。
图14绘示依据本发明一实施例之计算正规化角距离、正规化垂直距离、及正规化平行距离的流程图。
图15A~图15D绘示依据本发明一实施例之考虑垂直距离域最大值的多种情形示意图。
图16绘示依据本发明一实施例之决定第一序列与第二序列之间序列距离的流程图。
图17A~图17C绘示依据本发明一实施例之两个代表性序列之间多个映像组合的示意图。
图18绘示两个代表性序列之间的一种无效映像的范例示意图。
图19绘示依据本发明一实施例之计算映像组合的映像距离的流程图。
图20绘示依据本发明一实施例之将代表性序列分类为集合的流程图。
图21绘示依据本发明一实施例之找出人群移动行为以及找出典型序列的流程图。
图22绘示依据本发明一实施例之找出目标日期类型的典型序列的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
现代生活中许多人使用智能卡搭乘大众运输,例如公交车、火车、捷运等等,此外,智能卡也可作为电子货币包以购买物品或支付费用,举例而言,智能卡可预存资金在卡内,可用于贩卖机、进出停车场、或进出火车站。图1绘示以智能卡进行支付活动的一范例示意图,于此范例中的智能卡是一种非接触式的智能卡。每当使用智能卡时,会产生一笔支付记录(Payment Log)或是交通记录,而由于贩卖机或是车站闸门可具有静态的地理信息,因此可以收集到关于多个使用者智能卡于使用时的位置数据。发行智能卡的服务提供商可以藉由收集这些支付记录,以获得人群在哪里以及人群如何移动的相关信息。
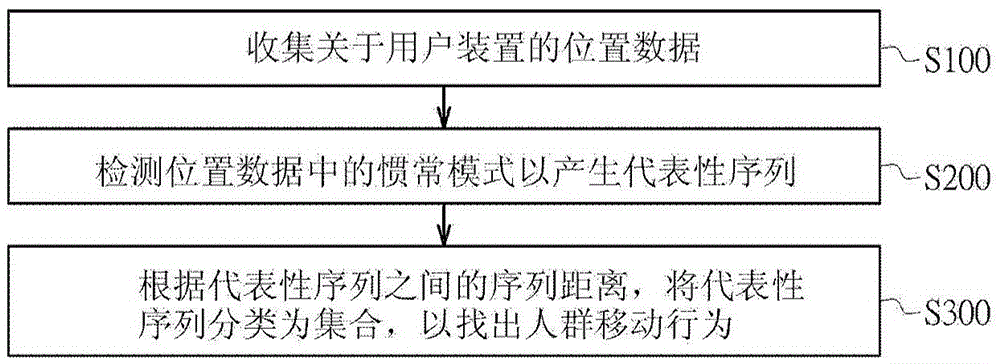
图2绘示依据本发明一实施例之找出人群移动行为方法的流程图,找出人群移动行为的方法包括下列步骤。步骤S100,收集关于多个用户装置的位置数据。步骤S200,检测(Mining)位置数据中的惯常模式(Frequent Patterns)以产生多个代表性序列(Representative Sequences)。步骤S300,根据代表性序列之间的序列距离,将代表性序列分类为集合(Cluster),以找出人群移动行为。其中各代表性序列包括至少一线段,该至少一线段在起始位置点与结束位置点之间。此方法例如可由软件程序实作,软件程序可储存于光盘上,软件程序可以包括多个相关于计算机处理器的指令,这些指令可被计算机处理器加载以执行上述的找出人群移动行为的方法。关于各步骤的详细说明如下。
步骤S100:收集关于多个用户装置的位置数据。用户装置可包括智能卡、电子付费卡、或是具有支付能力的行动装置,当这些用户装置用于支付活动时,可收集相关的位置数据。举例而言,当智能卡用于在一个支付终端机进行支付活动时,可上传一个报告至中央服务器,这个报告可包括智能卡的身份认证(Identification,ID)、支付金额、日期时间、支付终端机的位置。本发明的找出人群移动行为方法并不限于在进行支付活动时收集位置数据,可收集位置数据的时机亦可包括:当用户装置进入车站时、当钱被存入用户装置时、或者当用户装置经过认证而进入建筑物时。为了便于理解,以下说明将以在进行支付活动时收集位置数据作为范例说明,并以支付记录代表收集到的位置数据。
图3绘示一范例支付记录的示意图,支付记录相关于从多个用户装置撷取的位置数据以及时间。支付记录可储存于支付服务提供商的中央服务器。于此范例中,支付记录包括的字段有:uid、离开位置、到达位置、日期时间、支付金额、交易类型。uid即代表用户装置的ID,亦即,相同的uid对应到相同的用户装置,即可能对应到相同的使用者,因此可以获得一个人身处何处的信息,藉由收集关于多个用户装置的位置数据,服务提供商可以得知大多数的人有怎样的共同移动轨迹。交易类型可以是购买、交通、存钱、或其他类型,对于交通类型,支付活动可能是在目的地车站进行,而离开位置与到达位置分别记录相关的交通信息,例如是离开车站与到达车站的地理坐标。对于交通以外的其他交易类型,可使用离开位置字段记录支付活动的位置,而到达位置字段则可以使用「-」记录。
在上述的例子中,所记录的坐标可以是精确的位置数据。而支付记录内,可能由于有大量的商店使用支付服务,因此不同位置的精确位置坐标数量可能会很多。对于找出有兴趣的人群移动行为而言,可能不需要精确的位置,因此可将邻近的位置视为一个语义区域(Semantic Region),并可以选择一个参考位置点(Reference Location Point)以代表一个语义区域。步骤S100可以包括步骤S110及步骤S120,如图4所绘示依据本发明一实施例之收集关于用户装置的位置数据的流程图。
步骤S110:选择多个参考位置点。参考位置点的范例可以包括学校、连锁便利商店、根据居住人口决定的景观位置。步骤S120:将位置数据中的各个位置点,取代为与其地理位置最接近的参考位置点。对于支付记录中的每一笔支付数据,原本的精确位置点可以取代为最接近的一个参考位置点。图5A以及图5B绘示依据本发明一实施例之将支付位置以最接近的参考位置点标注的范例示意图。图5A以三个不同阴影填满的三角形表示三个预先选择的参考位置点Ref_a、Ref_b、Ref_c,以空心圆形原本的支付位置。接着,将每个支付位置取代为地理位置最接近的参考位置点,如图5B所示,每个支付位置的阴影填满状态改变为与其对应的参考位置点相同。在使用最接近的参考位置点标注支付位置之后,在原本支付记录内的地理坐标即可以取代为这些参考位置点。此处所提及的步骤S110及步骤S120为可选步骤,亦即,即使不执行步骤S110及步骤S120,支付记录中保存有原始的支付位置,后续的步骤S200以及步骤S300依然可以对原始的支付位置执行。
步骤S200:检测位置数据中的惯常模式以产生多个代表性序列。在数据收集以及上述的前置处理阶段之后,支付记录可以转为支付序列(Sequence),每一个支付序列包括一序列的项目(Item),代表着特定使用者在特定时间的整个支付轨迹,支付序列中的项目可以是如图5A及图5B所示的参考位置点,一个范例的支付序列可以是{id_677:Ref_h,Ref_c,Ref_c}。从多个支付序列中,可以使用循序样式检测(Sequential Pattern Mining)算法,例如是PrefixSpan或Generalized Sequential Pattern(GSP)算法,以找出支付序列中的惯常模式。在循序样式检测之后,可以得到对于特定时间中的代表性序列以及其对应的支持度(Support Count),支持度可代表出现的次数,可于检测算法中计算得到。各个代表性序列包括至少一线段,该至少一线段在一起始位置点与一结束位置点之间,起始位置点及结束位置点可以是精确位置或是参考位置点。举例而言,支付记录中对应到交通类型的一笔支付资料,可以视为在离开位置以及到达位置之间的一线段。代表性序列的一个范例为<Ref_a,Ref_d,Ref_e>,此代表性序列包括两个线段,一个线段从Ref_a到Ref_d,另一个线段从Ref_d到Ref_e。
在步骤S200当中,支付记录可以先根据uid以及日期时间进行排序,例如可以将对应到相同用户装置的交易群聚在一起,并且将对应此用户装置的事务数据依据时间顺序进行排序。此外,各个位置点可以使用最接近的参考位置点标注,如图5B所示。图6绘示依据本发明一实施例之整理后与简化后的支付记录的示意图。在此例中,对于uid 604可以形成一个交易序列:<Ref_a,Ref_d,Ref_e>,而对于uid 677可以形成另一个交易序列:<Ref_h,Ref_c,Ref_c>,接着便可以对多个交易序列应用循序样式检测算法以找出惯常模式。
图7绘示依据本发明一实施例之检测位置数据中的惯常模式以产生代表性序列的流程图。步骤S200可包括步骤S210、步骤S220、及步骤S230,这些步骤在样式检测之后执行。步骤S210,若是有一个惯常模式仅具有单一位置点,则移除此惯常模式。步骤S220,在每个惯常模式中,移除相同的相邻位置点。由于是找出人群移动行为的方法,因此会排除那些代表停留在原地的惯常模式,例如是<Ref_a>以及<Ref_a,Ref_a>。此外,包括有至少两个相同的相邻位置点的惯常模式,例如<Ref_h,Ref_c,Ref_c>,同样也会排除重复的相邻位置点。如此得到的代表性序列不会包括有相同的相邻位置点,每个代表性序列当中的每一个线段皆代表人群移动行为的方向。
步骤S230,将数日的惯常模式聚合以产生代表性序列。收集到的支付记录可以依照不同时间以及不同日期进行分类,这是由于在不同的时间区段中,人群移动行为轨迹可能不相同。举例而言,6:30am~9:30am、10:30am~13:30am、4:30pm~7:30pm这三个时段可能分别对应到不同的人群活动。若是需要多日累积下来针对特定时间区段的统计分析,则可以将这个时间区段对应的多日的惯常模式进行聚合。图8绘示依据本发明一实施例之聚合惯常模式的示意图。在此范例中,五月当中所有工作日的时段6:30am~9:30am当中的代表性序列被聚合,表格中的数字代表代表性序列的支持度。如图8所示,每一个工作天的序列<Ref_d,Ref_e>经累加后,所产生整个五月这个序列的支持度为5750。数字23/23是出现率(Occurrence Rate),代表这个序列<Ref_d,Ref_e>在五月的23个工作天中出现23次。藉由聚合多日的统计数据,更可以准确地找出大多数人的移动趋势。
步骤S300,根据代表性序列之间的序列距离,将代表性序列分类为集合,以找出人群移动行为。在执行步骤S100及步骤S200之后,关于人群移动行为的代表性序列已被找出,接着可将相似的代表性序列分类为集合,以找出在较大范围区域之间的人群移动行为。如此作法是有益处的,因为大多数有兴趣的人群移动行为是关于在两个大范围区域之间的移动,而非两个特定建筑物之间的移动。在步骤S300可计算两个代表性序列之间的序列距离,以决定这两个代表性序列的相似程度。举例而言,较短的序列距离代表这两个代表性序列有较高的相似程度(例如于地理位置上较为靠近)。可以根据如此计算得到的序列距离,将代表性序列分类为集合。
以下说明一个关于计算序列距离的范例。一个代表性序列可视为一序列的线段,在此说明范例中,代表性序列包括有第一序列Seq_a以及第二序列Seq_b。第一序列Seq_a包括第一线段L1,第一线段L1在第一起始位置点L1_s与第一结束位置点L1_e之间。第二序列Seq_b包括第二线段L2,第二线段L2在第二起始位置点L2_s与第二结束位置点L2_e之间。第一序列Seq_a与第二序列Seq_b之间的序列距离,是根据第一线段L1与第二线段L2之间的线段距离而决定。第一线段L1具有方向性(从第一起始点L1_s指向第一结束点L1_e),第二线段L2亦同样具有方向性(从第二起始点L2_s指向第二结束点L1_e)。因此于以下的说明中,将使用向量以及分别代表第一线段L1以及第二线段L2。
图9绘示依据本发明一实施例之计算代表性序列之间的序列距离的流程图。第一序列Seq_a及第二序列Seq_b形成代表性序列中的一个序列对,对于每一个序列对,步骤S300(将代表性序列分类为集合)更可包括步骤S310以及步骤S320。步骤S310,计算第一线段L1与第二线段L2之间的线段距离,线段距离代表这两个线段的靠近程度或相似程度。步骤S320,根据第一线段L1与第二线段L2之间的线段距离,决定第一序列Seq_a与第二序列Seq_b之间的序列距离,换言之,两个代表性序列之间的相似程度,是根据这两个代表性序列分别具有的线段之间的相似程度而决定。
图10绘示依据本发明一实施例之计算第一线段与第二线段之间的线段距离的流程图。步骤S310可以包括下列步骤。步骤S311,计算第一线段L1与第二线段L2之间的角距离dθ(Angle Distance)、垂直距离d⊥(Perpendicular Distance)、及平行距离d||(Parallel Distance)。步骤S312,根据角距离dθ、垂直距离d⊥、及平行距离d||,计算正规化(Normalized)角距离Ndθ、正规化垂直距离Nd⊥、及正规化平行距离Nd||,其中正规化角距离Ndθ、正规化垂直距离Nd⊥、及正规化平行距离Nd||的值在相同的值域内。步骤S313,根据正规化角距离Ndθ、正规化垂直距离Nd⊥、及正规化平行距离Nd||的加权总和,决定第一线段L1与第二线段L2之间的线段距离。以下提供一范例说明关于两个线段之间线段距离的计算。
图11绘示依据本发明一实施例之两线段之间线段距离的示意图。线段距离由三个成份决定:角距离dθ、垂直距离d⊥、以及平行距离d||。角距离dθ相关于与之间的夹角θ(0≤θ≤180°)。举例而言,夹角θ可根据式子计算,其中是两个向量的内积(dot product),
及代表两个向量的长度。角距离dθ可根据以下式子(1)计算:
角距离dθ代表两个向量在指向方向的相似程度,夹角θ越小,角距离dθ越小。而当夹角θ大于90°时,相当于两个向量实质上指向相反方向,则此时的角距离dθ可设为角距离域(Domain)的最大可能值,以表示这两个向量在方向上并不相似。
图12绘示依据本发明一实施例之计算第一线段与第二线段之间平行距离的流程图。步骤S311包括下列步骤。步骤S331,将第二起始位置点L2_s投影在第一线段L1的延伸线,以获得第三起始投影点L3_s。步骤S332,将第二结束位置点L2_e投影在第一线段L1的延伸线,以获得第三结束投影点L3_e。步骤S333,连接第三起始投影点L3_s及第三结束投影点L3_e,以产生第三线段L3,如此产生的第三起始投影点L3_s、第三结束投影点L3_e、以及第三线段L3,可见图11所绘示。步骤S334,将第一线段L1与第三线段L3的并集(Union)减去第一线段L1与第三线段L3的交集(Intersection),以决定平行距离d||。平行距离d||可根据以下式子(2)计算:
d||=L1∪L3-L1∩L3 (2)
由于第三线段L3是经由将第二线段L2投影至第一线段L1而形成,因此第三线段L3与第一线段L1共线(Collinear)。在图11所示的范例中,第一线段L1与第三线段L3的并集,是从第一起始位置点L1_s到第一结束位置点L1_e的长度,而第一线段L1与第三线段L3的交集,是从第三起始位置点L3_s到第三结束位置点L3_e的长度。在此范例中是将第二线度L2投影至第一线度L1,在其他实施例中,亦可以将第一线段L1投影至(延伸的)第二线段L2而获得平行距离d||(计算出来的值可能不同)。平行距离d||代表两个线段的等效平行长度之间的相似程度。
垂直距离d⊥可根据以下式子(3)计算:
其中l⊥s是第二起始位置点L2_s与第三起始位置点L3_s之间的欧氏距离(Euclidean Distance),l⊥e是第二结束位置点L2_e与第三结束位置点L3_e之间的欧氏距离。式子(3)代表l⊥s与l⊥e的反调和平均(Contraharmonic Mean)。
图13绘示依据本发明一实施例之两线段之间线段距离的示意图。同样可以分别依据式子(1)、(2)、(3)计算角距离dθ、平行距离d||、垂直距离d⊥。在此范例中,夹角θ大于90°,因此角距离dθ等于至于平行距离d||,第一线段L1与第三线段L3的并集,是从第一起始位置点L1_s到第三结束位置点L3_e的长度,而第一线段L1与第三线段L3的交集,是从第三起始位置点L3_s到第一结束位置点L1_e的长度。
如上所述,当计算线段距离时同时考虑三个成份。然而,由于这三个成份的值域可能相差很大,造成不容易根据这三个成份取得一个有意义的组合。于本发明的方法中,在步骤S312计算正规化角距离Ndθ、正规化平行距离Nd||、及正规化垂直距离Nd⊥,其中正规化角距离Ndθ、正规化平行距离Nd||、及正规化垂直距离Nd⊥的值在相同的值域内,例如是[0,1],[0,1]代表大于等于0、小于等于1的区间。由于这三个正规化成份的值在相同的值域内,这三个正规化成份的线性组合对于计算两线段之间的线段距离便具有意义。在一实施例中,线段距离是正规化角距离Ndθ、正规化平行距离Nd||、及正规化垂直距离Nd⊥的加权总和,线段距离可根据以下式子(4)计算:
线段距离=w1×Ndθ+w2×ND||+w3×ND⊥其中
举例而言,w1、w2、w3可以都等于以获得正规化角距离Ndθ、正规化平行距离Nd||、及正规化垂直距离Nd⊥的平均值。
图14绘示依据本发明一实施例之计算正规化角距离、正规化垂直距离、及正规化平行距离的流程图。步骤S312可包括下列步骤。步骤S341,将角距离dθ除以角距离域的最大值,以得到正规化角距离Ndθ。步骤S342,将垂直距离d⊥除以垂直距离域的最大值,以得到正规化垂直距离Nd⊥。步骤S343,将平行距离d||除以平行距离域的最大值,以得到正规化平行距离Nd||。由于三个正规化距离皆是藉由除以在各自距离域的最大值而产生,因此这三个正规化距离成份的值都会在[0,1]范围。
如式子(1)所示,角距离域的最大值是第一线段L1以及第二线段L2当中较短一者的长度。如式子(2)所示,平行距离域的最大值是第一线段L1与第三线段L3的并集。垂直距离域的最大值不易直接从式子(3)看出,其相关计算说明如下。
图15A~图15D绘示依据本发明一实施例之考虑垂直距离域最大值的多种情形示意图。根据式子(3)以及第一线段L1与第二线段L2的几何关系,垂直距离域的最大值发生在垂直于时。因此,在一实施例中,可将第二线段L2绕着第二起始位置点L2s或绕着第二结束位置点L2e旋转,直到垂直于第一线段L1垂直距离域的最大值是第一线段L1与旋转后的第二线段之间的垂直距离。图15A~图15D绘示四种可能的旋转情形。垂直距离域的最大值是这四种可能情形当中最大的垂直距离,垂直距离域的最大值可根据以下式子(5)计算:
其中l2代表第二线段L2的长度。
两线段之间的线段距离可根据以上的计算程序获得,而两个代表性序列之间的序列距离,则可以根据这两个代表性序列分别具有的线段之间的线段距离而决定。图16绘示依据本发明一实施例之决定第一序列与第二序列之间序列距离的流程图。步骤S320包括下列步骤。步骤S321,根据第一序列Seq_a当中至少一线段与第二序列Seq_b当中至少一线段,在第一序列Seq_a与第二序列Seq_b之间产生多个映像(Mapping)组合。步骤S322,计算每个映像组合的映像距离。步骤S333,以每个映像组合当中的最小映像距离,作为第一序列Seq_a与第二序列Seq_b之间的序列距离。
第一序列Seq_a可以是多个线段依据时间顺序排列形成的序列,第一序列Seq_a例如可包括两个线段LineSega1以及LineSega2,线段LineSega1代表的移动轨迹早于线段LineSega2代表的移动轨迹。图17A~图17C绘示依据本发明一实施例之两个代表性序列之间多个映像组合的示意图。在此范例中,第二序列Seq_b亦包括两个依据时间顺序排列的线段LineSegb1以及LineSegb2。
在图17A中,线段映射LineSegb1至一个空线段φ,线段LineSegb2映射至线段LineSega1,而线段LineSega2映射至一个空线段φ。值得注意的是,在各代表性序列的时间顺序仍然维持原本的时间顺序。第17B图以及图17C分别绘示不同的映像组合,在各代表性序列的时间顺序同样是维持原本的时间顺序。图18绘示两个代表性序列之间的一种无效映像的范例示意图,此映像违反时间顺序,因为线段LineSega2(映射至线段LineSegb1)发生晚于线段LineSega1(映射至线段LineSegb2),然而线段LineSegb1发生早于线段LineSegb2。对于每一个有效的映像组合(如图17A~图17C所示),可以计算一个映射距离。第一序列Seq_a与第二序列Seq_b之间的序列距离,可以是各映像组合当中的最小映像距离。
图19绘示依据本发明一实施例之计算映像组合的映像距离的流程图。步骤S322包括下列步骤。步骤S351,依据时间顺序,在第一序列Seq_a当中至少一线段与第二序列Seq_b当中至少一线段之间,形成多个映射对(Mapping Pair)。步骤S352,计算每个映射对的线段距离。步骤S353,计算每个映射对的线段距离的平均值,以获得映射距离。
请参考图17A,此例中的映像组合包括三个映像对:{φ,LineSegb1},{LineSega1,LineSegb2},and{LineSega2,φ}。每一个映像对的线段距离,可以依据前述的线段距离计算方式(包括计算三个正规距离成份,步骤S311~S313以及式子(1)~(5))。而一个真实线段与一个空线段φ之间的线段距离可定义为1(线段距离域的最大可能值)。图17A所示的这个映像组合的映像距离,可以是这三个映射对的线段距离的平均值。举例而言,此映像组合的映像距离等于其中Nd代表两个线段之间的线段距离。类似地,第17B图中有两个映射对,映射距离可以是这两个映射对的线段距离的平均值。
如上所述的计算方式,可以计算出两个代表性序列之间的序列距离。图20绘示依据本发明一实施例之将代表性序列分类为集合的流程图。步骤S300包括下列步骤。步骤S360,将每个代表性序列作为一个集合。步骤S370,计算每个集合对之间的集合距离,集合对是由两个集合所形成。步骤S380,找出具有最小集合距离的第一集合以及第二集合。步骤S390,若最小集合距离小于距离门坎值,合并第一集合以及第二集合。
在此实施例中可以应用聚合式阶层分群(Agglomerative Hierarchical Clustering)方法。于初始状态,将每个代表性序列视为一个集合。接着可以计算每一个集合对(由两个集合形成,初始状态为两个代表性序列)之间的集合距离,可依据步骤S351~步骤S353的方法计算出集合距离(因为在初始状态时,即相当于计算两个代表性序列的序列距离)。找出具有最小集合距离的两个集合,若是最小集合距离小于距离门坎值,例如0.3,则将这两个集合合并成为一个较大的集合。接着流程可再回到步骤S370,以重复地进行合并集合。合并后,有些集合会具有多个代表性序列,而对于具有多个代表性序列的集合所形成的集合对,可以计算此集合对当中所有代表性序列配对(所有配对链结,All-Pair Linkage)的序列距离的平均值,以作为此集合对的集合距离,其中代表性序列配对是由集合对的两个集合当中各自的一个代表性序列所形成。举例而言,集合G1有两个代表性序列,集合G2有三个代表性序列,则集合G1与集合G2之间的集合距离,可以是2×3=6个代表性序列配对的序列距离的平均值。
在一实施例中,提供一种找出典型序列(Typical Sequence)的方法。图21绘示依据本发明一实施例之找出人群移动行为以及找出典型序列的流程图。与图2的流程图相比,图21更包括步骤S410及步骤S420。步骤S410,将日期分为多种日期类型。举例而言,日期可以分类为工作日与休假日,而工作日可进一步分类为单日休假日之前的最后一个工作日、至少双日休假日之前的最后一个工作日、单日休假日之后的第一个工作日等等。类似地,休假日可进一步分类为单日休假日、至少双日休假日的第一个休假日、至少双日休假日的最后一个休假日等等。步骤S420,根据代表性序列在目标日期类型的出现率,找出目标日期类型的典型序列。如图8所示,在聚合数日的数据后,可以得到代表性序列在特定日期类型的出现率,根据出现率,可以找出特定日期类型的典型序列。举例而言,在至少双日休假日的最后一个休假日,可能可以找到的典型序列是在两个火车站之间的移动轨迹。
图22绘示依据本发明一实施例之找出目标日期类型的典型序列的流程图。步骤S420包括下列步骤。步骤S421,计算测试代表性序列在属于目标日期类型日子里的第一出现率。步骤S422,计算测试代表性序列在非属于目标日期类型日子里的第二出现率。步骤S423,根据第一出现率以及第二出现率,计算统计熵(Entropy)。步骤S424,若是第一出现率大于几率门坎值,且统计熵小于熵门坎值,决定测试代表性序列为典型序列。
步骤S421当中的出现率,可以在执行步骤S230之后得到(如图8所示,聚合数日的资料),以下以一例子说明关于步骤S421~S424执行的计算。此例中的目标日期类型是至少双日休假日的第一个休假日,以class H表示。另一方面,以class(all-H)表示不是属于class H的休假日。下面表一列出两个代表性序列,以及这两个代表性序列对应的出现率。
表一
出现率即代表这个序列在这些日子出现的次数,例如序列R1在属于class H的56个日子内总共出现在41个日子,而在属于class(all-H)的128个日子内总共出现在2个日子。此例中步骤S424的几率门坎值Pth等于0.2、熵门坎值Sth等于0.6。步骤S423的统计熵可根据以下式子(6)计算:
其中pi是序列在class i的几率 (6)
根据式子(6),序列R1的统计熵S1等于0.1熵值较大(乱度较大)代表几率分布较接近于均匀分布(Uniform Distribution),而熵值较小则代表几率分布偏向其中一端。在上述的例子中,若是几率分布偏向class H,则此序列可以视为class H日期里的典型序列。在步骤S424,由于第一出现率(41/56)大于几率门坎值Pth,且统计熵S1=0.1小于熵门坎值Sth,序列R1可被决定为class H日期里的典型序列。类似地,序列R2的统计熵S2亦可以根据式子(6)计算,可得到S2=0.69,由于统计熵S2大于熵门坎值Sth,因此序列R2并不是class H日期里的典型序列。如表一所示,序列R2在class H日期里的第一出现率(28/56)与在class(all-H)日期里的第二出现率(50/128)相近,意即序列R2并不是特别会出现在哪一种日期类型当中,因此序列R2不是一个典型序列。在找出一个日期类型的多个典型序列之后,可以将多个典型序列进一步分类为集合,分类的方法可以如步骤S360、S370、S380、S390所示。
依据本发明实施例的找出人群移动行为的方法,可藉由收集从用户装置撷取的位置数据,找出人群移动行为轨迹,用户装置例如是智能卡。发行智能卡的支付服务提供商可以依据得到的人群移动行为轨迹,以估计特定地理区域的持卡人数、对应地设计营销与广告计划、决定开设新店面的位置等等,根据本发明实施例的找出人群移动行为的方法,可以有许多层面的应用,并有助于作出重要决策。进一步而言,由于本发明实施例更可以找出特定日期类型的典型序列,支付服务提供商能够根据不同日期类型的典型序列,对应地规划与组织属于不同日期类型的活动。
综上所述,虽然本发明已以较佳实施例公开如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当以权利要求保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!