一种实现智能问答的系统及方法与流程
本发明属于计算机自然语言处理技术领域,更具体的说,本发明涉及一种实现智能问答的系统及方法。
背景技术:
随着计算机自然语言技术的发展,智能问答系统开始受到极大的关注,一般的,智能问答系统以一问一答形式,精确的定位用户所需要的提问知识,通过与用户进行交互,为用户提供个性化的信息服务。当用户提出问题时,系统不仅将问题答案推送出来,而且会将与这个问题相关的知识也都推送出来供用户查询,这样就做到了一次提问全面掌握所有信息。
现有智能问答系统以自然语言句子提问,系统分析并理解用户的问题,返回用户想要的答案。系统能给用户提供更加精确的信息服务,用户不需要阅读搜索引擎返回的文档列表去查找答案,从而提高了效率。但现有的智能问答系统采用用户输入的文本信息进行交互,用户提出的问题和系统返回的答案呈现模式都是文本信息,而随着互联网及移动互联网的快速发展,对智能问答系统的直观性和丰富性上提出了更高的要求,现有基于文本信息的智能问答系统已无法满足上述需求,用户问答的体验较差,智能化不够。
技术实现要素:
本发明解决的技术问题在于提供一种实现智能问答的系统及方法,可以提高用户信息查询的丰富性,提高用户问答的体验,使问答系统更加智能化。
为解决上述技术问题,本发明采用如下技术方案:
一种实现智能问答的系统,其包括:
多模态信息接收模块,用于接收用户输入的多模态信息问题,其中所述多模态信息包括文本信息、图片信息、文本+图片信息、文本+视频信息、文本+图片+视频信息;
映射模块,用于将所述多模态信息接收模块接收到的多模态信息问题映射为相应的向量空间;
答复生成模块,用于对所述映射模块映射得到的向量空间进行转换分析后获取对应该多模态信息问题的答复。
其中,所述多模态信息若为文本信息,所述映射模块包括文本映射模块,用于根据循环神经网络将所述文本信息映射为文本向量空间。
其中,所述多模态信息若为图片信息,所述映射模块包括图片映射模块,用于根据卷积神经网络将所述图片信息映射为图片向量空间。
其中,所述多模态信息若为视频信息,所述映射模块包括视频映射模块,用于将所述视频信息转换为图像序列,根据卷积神经网络将所述图片序列进行图像向量空间映射,然后进一步按照循环神经网络将序列化连续的图像向量空间映射为视频向量空间。
其中,所述答复包括响应用户输入问题的答案或响应用户输入问题的处理指令。
另外,根据本发明的另一方面,一种实现智能问答的方法,其包括:
接收用户输入的多模态信息问题,其中所述多模态信息包括文本信息、图片信息、文本+图片信息、文本+视频信息、文本+图片+视频信息;
将接收到的多模态信息问题映射为相应的向量空间;
对映射得到的向量空间进行转换分析后获取对应该多模态信息问题的答复。
其中,所述多模态信息若为文本信息,根据循环神经网络将所述文本信息映射为文本向量空间。
其中,所述多模态信息若为图片信息,根据卷积神经网络将所述图片信息映射为图片向量空间。
其中,所述多模态信息若为视频信息,将所述视频信息转换为图像序列,根据卷积神经网络将所述图片序列进行图像向量空间映射,然后进一步按照循环神经网络将序列化连续的图像向量空间映射为视频向量空间。
其中,所述答复包括响应用户输入问题的答案或响应用户输入问题的处理指令。
本发明取得了以下技术效果:
本发明的实现智能问答的系统和方法中由于用户可输入多模态信息问题,而用户输入的多模态信息问题经过映射处理为统一的向量空间,最后根据统一的向量空间进行转换分析后获取对应该多模态信息问题的精准的答案,即本发明对于多模态信息,无论是文本、图片,视频及以上三种信息类型的任意组合均可统一进行处理,具有并行分布处理、高度鲁棒性和容错能力、分布存储及学习能力、能充分逼近复杂的非线性关系等突出特点,从而使得智能问答系统具备针对多模态信息的统一计算和处理能力,可以提高用户信息查询的丰富性,提高了用户问答的体验,使问答系统更加智能化。
附图说明
图1是根据本发明实现智能问答的系统的一种具体实施例框图;
图2是根据图1中映射模块的一种具体实施例示意图;
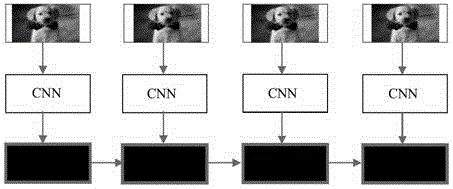
图3是根据图2中图片映射模块进行映射的工作原理图;
图4是根据图2中视频映射模块进行映射的工作原理图;
图5是一个具体实施例中包括文字、图片的一个多媒体信息问题的智能问题示意图;
图6是根据本发明实现智能问答的方法的一种具体实施例流程图。
具体实施方式
为使本发明的上述目的、特征和优点更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明:
参考图1,该图为根据本发明实现智能问答的系统的一种具体实施例框图,其包括:
多模态信息接收模块1,用于接收用户输入的多模态信息问题,其中所述多模态信息包括文本信息、图片信息、文本+图片信息、文本+视频信息、文本+图片+视频信息;
映射模块2,用于将所述多模态信息接收模块1接收到的多模态信息问题映射为相应的向量空间;
答复生成模块3,用于对所述映射模块2映射得到的向量空间进行转换分析后获取对应该多模态信息问题的答复,具体实现时,所述答复包括响应用户输入问题的答案或响应用户输入问题的处理指令或者其他答复,这里不再赘述。
上述实施例中,由于用户输入的多模态信息问题可以是各种形式的,因此,映射模块2对于不同的多模态信息也具有相应的功能模块并按照统一的架构去执行映射,参考图2,例如,所述多模态信息若为文本信息,所述映射模块2包括文本映射模块21,用于根据循环神经网络将所述文本信息映射为文本向量空间。
具体实现时,上述文本映射模块21采用循环神经网络RNN进行句子向量表示,将文本信息映射为文本向量空间,即将词映射到低维空间,例如,假设输入句子为x={x1,x2,…xt..xN},且x1是词,c(x1)表示词向量,既将词进行了低维空间的映射,具体映射时,可采用如下的方式进行映射,例如,映射采用如下公式:
fQ(t)=g(g(c(xt)WQ+fQ(t-1)WQh+b1)MQ+b2) (1)
其中WQ,Wqh,Mq为参数矩阵,b2为偏置项。
上式中t表示问句中词的序列,t取值范围为1…N?即利用循环神经网络RNN将句子表示为其最后一个输出fq(N)。利用上面的模型,将文本问题映射到了一个低维的向量空间fq(N)。
另外,所述多模态信息若为图片信息,所述映射模块2可包括图片映射模块22,用于根据卷积神经网络将所述图片信息映射为图片向量空间。
具体实现时,上述图片映射模块22采用卷积神经网络CNN进行图像的特征提取和低维表示,通过对图像进行特征抽取,抽取的特征利用向量空间进行表示,即将图像映射为低维向量空间,具体映射时,可采用如下的方式进行映射,例如,假设输入的图像为T∈RM×N,Tmn为图像的像素点,映射可采用如下公式:
sub(i)=∑k∑jTm+k,n+j×filter(k,j) (3)
fI=MaxPolling(sub) (4)
其中m,n,k,j表示像素的位置。
结合图3,在上式中滤波器filter进行特征提取,通过提取局部特征后进行maxpolling进行全局特征的提取,获取图像的低维表示。
另外,所述多模态信息若为视频信息,所述映射模块2包括视频映射模块23,用于将所述视频信息转换为图像序列,根据卷积神经网络将所述图片序列进行图像向量空间映射,然后进一步按照循环神经网络将序列化连续的图像向量空间映射为视频向量空间。
具体实现时,上述视频映射模块23对视频进行图像序列化,然后通过卷积神经网络CNN进行图像空间映射,最后通过循环神经网络RNN进行序列化连续的空间映射,即将视频映射为低维向量空间,如图4所示,具体映射时,例如,假设视频为v,对应的序列化的图像为v(t),t为对应的时刻,映射可采用如下公式:
fV(t)=g(g(fI(v(t))WV+fV(t-1)WVh+b1)MV+b2) (5)
其中Mv,Mvh,为参数矩阵,b2为偏置项。
上述具体实施例中,按照统一的架构将文本信息、图片信息和视频信息进行了空间映射,假设分别是fQfIfV,而假设最终生成的答案或指令为y={y1,y2,…yt..yN},t为答案对应的序列,训练的目标函数为:
E(t)=g(RQfQ+RIfI+RVfV+RVfA(t)) (6)
其中,
上式中β(xi)为SoftMax函数,O(t)为目标函数。其中RQ,Ri,Rv,为参数矩阵。
即当答复生成模块3进行分析时,例如对于文本+图片+视频多种模态的组合方式进行分析处理,首先将输入的问题、图片和视频进行空间映射,分别为fQfIfV三种向量形成的向量空间表示,然后将这三个向量空间输入到答复生成模块中,即会产生此问题对应的文本答案或指令。
例如,参考图5,若用户输入多模态信息的问题,答复生成模块3会产生相应的文本答案或指令,例如用户输入“狗嘴里含着什么+图片(狗含着一支玫瑰)”,答复生成模块3会产生“含着一支鲜红的玫瑰”的答案,或者又如用户输入“有这个图片相似的图片有哪些?+图片”,答复生成模块3会产生“查询相似图片”的答复,即产生一条指令。
另外,根据本发明的另一方面,参考图6,本实施例一种实现智能问答的方法,主要包括:
步骤S101,接收用户输入的多模态信息问题,其中所述多模态信息包括文本信息、图片信息、文本+图片信息、文本+视频信息、文本+图片+视频信息;
步骤S102,将接收到的多模态信息问题映射为相应的向量空间,具体实现时,所述多模态信息若为文本信息,可根据循环神经网络将所述文本信息映射为文本向量空间,而所述多模态信息若为图片信息,则可根据卷积神经网络将所述图片信息映射为图片向量空间;所述多模态信息若为视频信息,则可将所述视频信息转换为图像序列,根据卷积神经网络将所述图片序列进行图像向量空间映射,然后进一步按照循环神经网络将序列化连续的图像向量空间映射为视频向量空间,其中对于文本信息、图片信息以及视频信息的具体映射方式可参考前述说明,这里不再赘述。
步骤S103,对映射得到的向量空间进行转换分析后获取对应该多模态信息问题的答复,例如,所述答复包括响应用户输入问题的答案或响应用户输入问题的处理指令或其他答复,这里不再赘述。
以上对本发明实施例所提供的技术方案进行了详细介绍,本文中应用了具体个例对本发明实施例的原理以及实施方式进行了阐述,以上实施例的说明只适用于帮助理解本发明实施例的原理;同时,对于本领域的一般技术人员,依据本发明实施例,在具体实施方式以及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!