网络问答系统、方法与计算机可读取记录媒体与流程
本发明是有关于一种网络问答系统、方法与计算机可读取记录媒体。
背景技术:
因特网对于人们日常生活扮演重要角色。例如,用户可以用网络问答系统与网络搜寻网站(如Google)来进行搜寻想要找的商品或想要看的电影,以方便使用者能尽快找到所想要的商品或想要看的电影。
故而,本发明提供一种网络问答系统与方法,以提供符合使用者需求的智能化问答体验。
技术实现要素:
本发明有关于一种网络问答系统、方法与计算机可读取记录媒体,根据用户对话记录,透过网络问答系统学习功能,学习语境模型,提供更智能化的问答体验。
根据本发明一实施例,提出一种网络问答方法应用于网络问答系统。接收当前回合使用者问句。根据语境标记模型,线上实时标记该当前回合用户问句的语境为语境继续或语境结束。根据该当前回合使用者问句的该语境,决定是否清除旧段落的至少一语境。该网络问答系统回答该当前回合用户问句。比较下一回合使用者问句与该旧段落之间的符合程度,以判断所标记的该当前回合用户问句的该语境是否正确,否要更正该当前回合使用者问句的该语境,以及,判断是否要将该当前回合使用者问句用于调适该语境标记模型。
根据本发明一实施例,提出一种网络问答系统,包括:线上实时对话语境标记模块、语境清除与回答模块、比较模块、语境标记更正模块与语境标记模型调适模块。该线上实时对话语境标记模块根据语境标记模型线上实时标记当前回合用户问句的语境为语境继续或语境结束。根据该当前回合使用者问句的该语境,该语境清除与回答模块决定是否清除旧段落的至少一语境,以及,该语境清除与回答模块回答该当前回合用户问句。该比较模块比较下一回合使用者问句与该旧段落之间的符合程度,以判断所标记的该当前回合用户问句的该语境是否正确。根据该比较模块的判断结果,该语境标记更正模块决定是否更正该当前回合使用者问句的该语境。该语境标记模型根据该比较模块的判断结果以判断是否将该当前回合使用者问句用于调适该语境标记模型。
根据本发明又一实施例,提出一种内储程序的计算机可读取记录媒体,当计算机加载该程序并执行后,可完成如上所述的方法。
附图说明
图1为根据本发明一实施例的网络问答系统与方法的语境标记模型训练流程图。
图2为根据本发明一实施例的网络问答方法的收集用户对话记录与用户语境结束事件的一例。
图3为在本发明实施例中,得到特征对应系数的示意图。
图4为根据本发明一实施例的网络问答方法的流程图。
图5为本发明一实施例中,进行线上实时标记当前回合用户问句的语境的一例。
图6为根据本发明一实施例的清除旧段落语境,并进行回答的一例。
图7为比较下一回合用户问句与旧段落之间的符合程度,以决定是否更正上一回合所标记的语境结束的一例。
图8为本发明另一实施例的网络问答系统的方块图。
图9为根据本发明一实施例的网络问答方法的流程图。
图10为本发明一实施例额网络问答系统的方块图。
附图标记说明:
110-130:步骤
140:用户对话记录数据库
150:语境标记模型
202、204、215:用户对话记录
210、220:使用者语境结束事件
405-450:步骤
610:语境
620、640:段落
641-644:对话回合
710:使用者问句
720:段落
730:语境
800:网络问答系统
810:问答记录模块
820:用户语境结束事件收集模块
830:语境标记模型训练模块
840:线上实时对话语境标记模块
850:语境清除与回答模块
860:比较模块
870:语境标记更正模块
880:语境标记模型调适模块
890:用户语境结束事件侦测模块
905-925:步骤
1000:网络问答系统
1010:线上实时对话语境标记模块
1020:语境清除与回答模块
1030:比较模块
1040:语境标记更正模块
1050:语境标记模型调适模块
具体实施方式
为使本发明的目的、技术方发明和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
在本发明实施例的自动侦测问句的语境标记(Discourse Label)的网络问答系统与方法中,记录用户与网络问答系统之间的问答相关信息(包含相关问答记录、历史对话清除时间、相关问答回合记录、用户空闲时间、用户浏览记录与事务历史记录等相关信息)。一个对话系包含至少一个问句与答句。而语境标记(Discourse Label)包括语境结束(Discourse End,DE)与语境继续(Discourse Continue,DC)两种标记(label)。
本发明实施例的网络问答系统与方法可整合语境结束事件与用户对话记录(User dialog log)成为训练数据,以根据训练数据来训练语境标记模型。
当语境被标记为语境结束且该次判断的信心值落于信心值范围内,则清除目前对话语境并进行持续问答,反之则保留语境。
另外,本发明实施例的网络问答系统与方法可比较目前语句与之前用户对话记录中所包含的相关问答记录,以判断语句是否属于相关语境。如果是,则更正语境标记并回馈至用户对话记录。如果回馈量超过门坎值,本发明实施例的网络问答系统与方法可自动重新训练语境标记模块。
在本发明实施例的网络问答系统与方法中,事先训练语境(discourse)标记模型。现请参考图1,其为根据本发明一实施例的网络问答系统与方法的语境标记模型训练流程图。
如图1所示,在步骤110中,收集用户对话记录,以记录用户与网络问答系统之间的问答相关信息。所收集的用户对话记录系记录至用户对话记录数据库140中。
在步骤120中,收集使用者语境结束事件与事件背景信息。
在本发明一实施例中,使用者语境结束事件例如包括但不受限于:(1)使用者按下重置(reset)键事件;(2)用户交易事件;(3)使用者浏览事件;以及(4)闲置(idle)时期超过门坎值事件。
在本发明一实施例中,网络问答系统可追踪用户是否按下重置按键。如果使用者按下重置键,代表当下语境为语境结束。网络问答系统收集此语境结束事件,产生一个语境结束标记。亦即,在一实施例中,使用者按下一次重置键,则产生一个语境结束标记。
在本发明一实施例中,网络问答系统追踪在用户问答之后,用户是否触发交易事件,交易事件例如但不受限于,结账、(将产品)加入购物车等。如果触发了用户交易事件,代表当下语境为语境结束事件。网络问答系统收集此语境结束事件,得到语境结束标记。亦即,在一实施例中,用户触发一次用户交易事件,则产生一个语境结束标记。
在本发明一实施例中,网络问答系统追踪在用户问答之后,使用者是否有进行浏览(如浏览相关产品、新闻等)。如果触发了使用者浏览事件,代表当下语境为语境结束事件。网络问答系统收集此语境结束事件,得到语境结束标记信息。亦即,在一实施例中,使用者触发一次使用者浏览事件,则产生一个语境结束标记。
在本发明一实施例中,网络问答系统可主动计时用户闲置时期(所谓的使用者闲置时期是指,用户未跟网络问答系统互动的时期),来决定使用者闲置时期是否超过门坎值。如果是,代表当下语境为语境结束事件。网络问答系统收集此语境结束事件,得到语境结束标记信息。亦即,在一实施例中,每一次使用者闲置时期超过门坎值,则产生一个语境结束标记。
步骤120所收集的事件背景信息是指用户语境结束事件的背景信息,包括例如但不受限于,下列的任一或其任意组合:重置时间、相关问答回合记录、用户闲置时期、用户浏览记录、用户事务历史记录等相关信息。
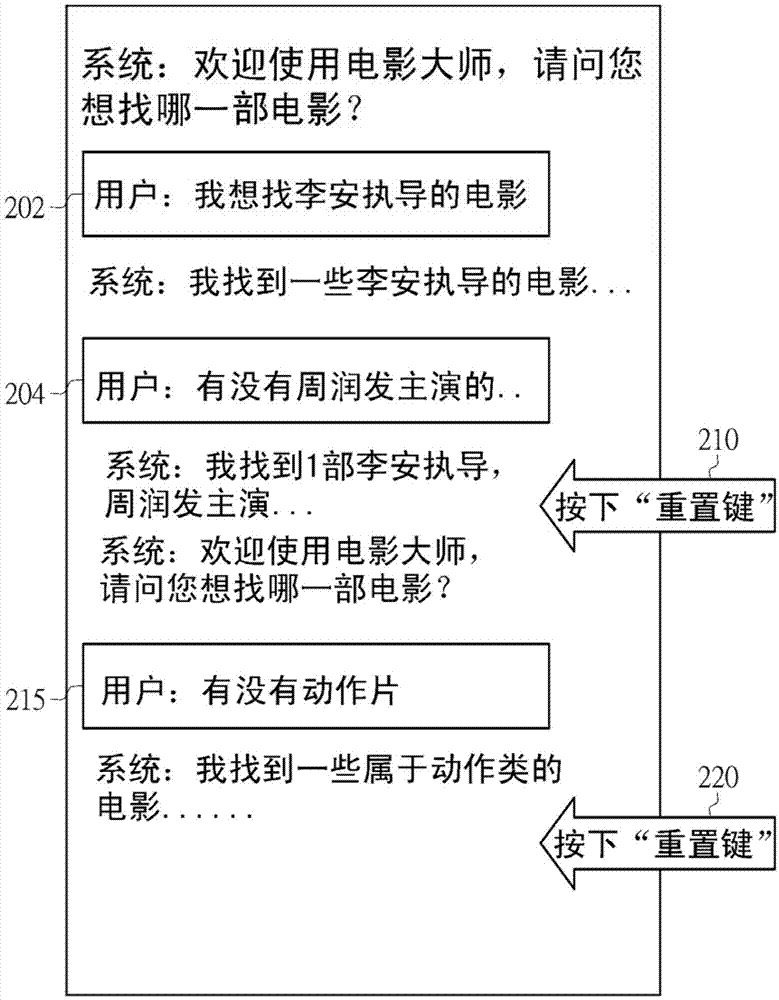
图2为根据本发明一实施例的网络问答方法的收集用户对话记录与用户语境结束事件的一例。网络问答系统收集用户对话记录202、204与215,且收集使用者语境结束事件210与220。
于步骤125中,网络问答系统判断所收集的语境结束标记的数量是否足够用于训练语境标记模型。如果足够的话,则流程接续至步骤130;如果不足够,则流程回至步骤120。
在步骤130中,训练语境标记模型150。如上述般,将使用者语境结束事件与用户对话记录当成训练数据。于语境标记时,可将每一个语境标记成语境结束(Discourse End,DE)与语境继续(Discourse Continue,DC),并标记相关信心值。亦即,在用户实际与网络问答系统进行问答时,对于每一个使用者语句的语境,将此用户语句的语境标记成“语境结束(DE)”或“语境继续(DC)”,且一并标记出信心值。
现将说明训练语境标记模型150的细节。
训练数据(包括用户语境结束事件与用户对话问答记录)的一例如表1所示。
表1
在本发明实施例中,“对话回合”为用户与对话网络问答系统对话互动过程的每一个语句,而与语句所对应的就是语境标记。例如上表1的语句1(使用者:我想找史蒂芬斯皮尔伯格执导的电影)的语境标记为DC。
训练好的语境标记模型的输入为目前语句与之前语句的集合,例如语句4与之前的语句集合(语句1、2、3)。或者,输入可以包括目前语句但不包括之前语句集合。
在本发明实施例中,语境标记模型的训练步骤包括但不受限于下列步骤:特征撷取(feature extraction)步骤、特征权重转换(feature weight transformation)与模型参数学习(model parameters learning)步骤。
在本发明实施例中,特征分类为语言特征(Linguistic feature)与元特征(Meta feature)。特征撷取(feature extraction)步骤从语句集合中撷取出语言特征及/或元特征。
语言特征就是语句集合中可以透过文字表现出来的特征,包括,例如但不受限于:(1)本语句所含的关键词、词性、语意概念、语句类型、隐含主题等不限于此;(2)本语句是否有提到演员、导演、年代、类型等不限于此;(3)前面回合语句集合中出现的关键词、词性、语意概念、语句类型、隐含主题等不限于此;以及(4)前面回合语句集合中是否有提到演员、导演、年代、类型等不限于此。
元特征则为语境过程中所表达的行为,且非语言所涵盖的特征,包括,例如但不受限于:(1)本次语境结束时间、相关问答回合记录、问答回合次数、用户空闲时间、用户浏览记录、事务历史记录等非语句内文信息,且不限于此;以及(2)前面回合语句集合中,语境结束时间、相关问答回合记录、问答回合次数、用户空闲时间,用户浏览记录、事务历史记录等非语句内文信息,且不限于此。
撷取出了特征之后,可以给予特征不同的权重此为特征权重转换(feature weight transformation),常见的权重可以是二元(Binary)特征,例如,如果有出现「阿诺」这个词的话,则其权重设为1,相反地,如果没有出现「阿诺」这个词的话,则其权重设为0。也可以是带有频率的特征,例如阿诺出现2次,则其权重可设为2除以总词频次数的比值。当然也可以透过TF-IDF(词频-逆向文件频率,term frequency-inverse document frequency)相关权重计算方式等不限于此。
在特征撷取与特征权重转换后,本发明实施例中,训练分类器以进行语境DC或DE的分类。本发明实施例所用的分类器可以是常见的分类器,例如但不受限于,SVM(支持向量机器,support vector machine)、贝氏分类器(Bayesian classifier)、类神经网络(artificial neural network)、判定树(Decision Tree)或最近邻居法(k-nearest neighbors)等不限于此。分类器训练是指,根据语境训练资料,计算在不同类别(class)下(例如DC与DE),特征值所对应的最佳系数。底下以SVM为例来做说明,当知本发明并不限于此。
subject to yi(wTφ(xi)+b)≧1-ξi
ξi≧0,i=1,…,l
于公式(1)中,参数“i”从1到l,代表每一笔训练资料的编号。参数“yi”为1或-1,表示每笔数据的类别(class)标记。每一笔训练资料xi可表达为向量,b为超平面的偏移量,w为最佳超平面中对应的权重向量,ξ为松弛变量(slack variables),代表限制式中可允许的松弛量,参数c用于控制最佳超平面与限制式的松弛量之间的权重。
完成训练语境标记模型,即得到向量W。对于所输入的语句,根据特征撷取步骤与特征权重转换步骤来得到特征权重向量后,利用分类器进行预测使用者所输入的语句的语境属于DC或DE。即是利用向量W与底下公式(2)来计算。
sgn(wTx+b) (2)
其中,x为资料向量,b为超平面的偏移量如同公式(1),w为最佳超平面中对应的权重向量如同公式(1),sgn为一个逻辑函式(sign function)。
公式(1)或(2)中的X向量,即是经过特征撷取(feature extraction)步骤与特征权重转换(feature weight transformation)步骤所得到的特征权重向量。
以表1中所列的语境训练数据为例做说明,可以发现语句之间或语境标记之间常有顺序关系,例如连续三个语境继续(DC)之后,通常下一个语境可能是语境结束。或者前面语句有导演概念词汇,通常后面语句容易有主演演员概念词汇。
因此在本发明实施例中,以利用分类器来训练语境标记模型之外,也可以透过序列学习模型,例如常见的条件随机场(Conditional Random Fields,CRFs)、隐藏式马可夫模型(Hidden Markov Model,HMM)等不限于此。
图3为在本发明以线性条件随机场(linear chain CRFs)模型为实施例,其中得到特征对应系数的示意图。如图3所示,将对话回合语句所包含的语句串行,视为x序列,透过上述特征撷取(feature extraction)步骤与特征权重转换(feature weight transformation)步骤所得的x向量序列,搭配条件随机场模型特定的特征函数(feature function),其中特征可以是如上所述的语言特征与元特征,配合训练数据中所含的语境标记序列y,利用优化计算方法例如梯度下降法(Gradient Descent)不限于此,得到特征对应系数λ,即第3图中的正方形实心方块。
如果以数学式表示的话,则可表示如公式(3)、(3.1)与(3.2)。
在公式(3)、(3.1)与(3.2)中,x为输入的节点集合,代表可被观察到的输入数据点顺序(the input sequence can be observed.),例如一组对话语句序列。y为x所对应的隐藏状态(hidden states)序列亦即其标记序列,例如一个对话语句序列对应的语境标记序列。p(y|x)代表资料序列整体的条件机率。λk∈RK为条件随机场(CRFs)模型所要优化的参数向量。fk为条件随机场(CRFs)模型所使用的特征函式集合。K为特征函式索引。Exp为指数函数。Z(x)为正规化函式(normalization function)。
公式(3)、(3.1)与(3.2)中的λ系数代表特征对应系数(亦即第3图中的正方形实心方块)。利用此类模型更能学习具有序列关系的数据。
因此当收集了具有语境标记的语境训练数据后,根据特征撷取步骤、特征权重转换与模型参数学习步骤(无论透过分类器或序列学习模型等),本发明实施例可以训练得到语境标记模型。
此外,如果训练数据具有少部分语境标记,本发明实施例也可用常见的半监督式学习(semi-supervised learning)处理方法来扩充模型参数学习步骤。或者,如果在收集语境训练资料过程中发现有更多和语境相关的变量可以用以收集并建立模型,本发明实施例可以用常见的一般化机率图论模型(probabilistic graphical model)来扩充序列学习模型。
现请参照图4,其显示根据本发明一实施例的网络问答方法的流程图,应用于网络问答系统。在步骤405中,接收当前回合使用者问句。于步骤410中,线上实时标记当前回合用户问句的语境为语境继续(DC)或语境结束(DE)。例如,根据语境标记模型150来实时标记当前回合用户问句的语境为语境继续(DC)或语境结束(DE),且一并标记出信心值。
图5为本发明一实施例中,进行线上实时标记当前回合用户问句的语境的一例。如图5所示,对于每一回合对话(不论是使用者所提的问句或网络问答系统所回答的答句),本发明实施例可线上实时标记每一回合对话的语境为语境继续(DC)或语境结束(DE)。
于步骤415,判断当前回合用户问句是否被标记为语境结束(DE)。亦即,判断当前回合用户问句被标记为语境继续(DC)或语境结束(DE)。如果步骤415为是(当前回合用户问句被标记为语境结束(DE)),则流程接续至步骤420。如果步骤415为否(当前回合用户问句被标记为语境继续(DC)),则流程接续至步骤425。
于步骤420中,清除旧段落的语境,并进行回答。由于当前回合用户问句的语境被标记为语境结束,清除旧段落的语境并回答使用者的问句。
另外,如果当前回合使用者问句的语境被标记为语境继续,则不清除语境,但仍要回答使用者的问句。亦即,根据该当前回合使用者问句的语境被标记为语境继续或语境结束,决定是否清除旧段落的语境。
请参考图6,其显示根据本发明一实施例的清除旧段落语境,并进行回答的一例。如图6所示,由于将使用者问句的语境610标记为语境结束(DE),所以,网络问答系统清除旧段落620的语境。
所谓的“清除语境”是指,网络问答系统将前一段落620中的语境清除,之后,网络问答系统在回答用户的下一问句时,网络问答系统将不会参考前一段落620中的历史对话回合与语境。
在本发明实施例中,“段落(segment)”是指介于2个连续语境结束(DE)之间的对话回合,这里的语境结束(DE)可以是网络问答系统判断的语境结束(DE),或者是网络问答系统所侦测到的用户语境结束事件(由使用者所触发)。清除旧段落语境即清除旧段落语境信息,包含语言文本信息与元信息。语言文本信息包含段落所含的至少一个语句与语句所含的关键词、词性、语意概念、语句类型、隐含主题与提到演员、导演、年代、类型等信息。而元信息包含本语境对应的语境结束时间、用户空闲时间、用户浏览记录、事务历史记录等非语句内文信息。
以图6为例,网络问答系统将对话回合641-644视为同一段落640,其中,对话回合641-644被标记为语境继续(DC)。所以,例如,在回答由使用者所提出的对话回合643时,网络问答系统的对话回合644考虑对话回合641-643(但不考虑前一段落620中的对话回合)。相反地,如果没有考虑到使用者历史对话回合的话,则网络问答系统在回答用户所提出的问句(有没有阿诺主演的电影),网络问答系统的回答可能会是“我找到1部阿诺主演的电影”,而不会是如同本发明图6的中的对话回合644:“我找到1部史蒂芬斯皮尔伯格执导,阿诺主演的电影”。
在步骤430中,如果使用者于下一回合继续输入问句的话,则比较下一回合使用者问句与旧段落之间的符合程度。
步骤430的比较例如是,透过语境相似度分析层次(分析文字层次,概念层次等)或者是,利用相似度计算算法(例如Jaccard,Cosine等算法)来达成。
在步骤435中,判断下一回合使用者问句与旧段落之间是否符合,以判断上一回合所标记的语境结束是否正确。
如果步骤435为是(下一回合使用者问句与旧段落之间符合,也就是说,下一回合使用者问句乃是使用者接续着旧段落的问句/意思而继续问的),则表示上一回合所标记的语境结束是错误的。在本发明实施例中,将上一回合所标记的语境由语境结束(DE)更正为语境继续(DC)(步骤440),并进行语境标记模型调适(步骤445)。语境标记模型调适的细节将于底下描述。
如果步骤435为否(下一回合使用者问句不是使用者延续着旧段落的问句内容而继续提问),则表示上一回合所标记的语境(如第6图中的语境结束610)是正确的。之后,进行语境标记模型调适,如步骤445所示。
图7为比较下一回合用户问句与旧段落之间的符合程度,以决定是否更正上一回合所标记的语境的一例。如图7所示,将下一回合使用者问句710比较于旧段落720。由图7可看出,下一回合使用者问句710乃是使用者接续着旧段落720的问句内容而继续问的。故而,上一回合将使用者问句的语境730标记为语境结束(DE)是错误的,要将语境730更正为语境继续(DC)。如果下一回合使用者问句与旧段落之间的不符合,则无需更正语境结束(DE)730。
在步骤425中,判断是否侦测到使用者语境结束事件。也就是说,如果网络问答系统将当前回合用户问句的语境标记为语境继续(DC),则网络问答系统根据上述的四种可能使用者行为的任一或其任意组合(1)用户按下重置(reset)键事件;(2)用户交易事件;(3)使用者浏览事件;以及(4)闲置时期超过门坎值事件),来侦测使用者是否主动结束语境。
如果步骤425为是,则表示上一回合所标记的语境继续(DC)是错误的。在本发明实施例中,将上一回合所标记的语境由语境继续(DC)更正为语境结束(DE)(步骤450),并进行语境标记模型调适(步骤445)。也就是说,如果该当前回合使用者问句的该语境被标记为该语境继续且侦测到使用者语境结束事件,则将该当前回合使用者问句的该语境更正为该语境结束。
如果步骤425为否,则表示上一回合所标记的语境继续(DC)是正确的。之后,进行语境标记模型调适(步骤445)。
现将说明本发明实施例如何调整语境标记模型150。
在训练时,对于每一笔训练数据可以搭配不同权重。不同权重对于语境标记模型的训练带来不同的效果,模型训练亦可称为模型参数学习。
在本发明实施例中,可透过语境标记的信心值与符合程度(代表比较目前使用者问句与以前语境之间符合程度),给予加权调整计算而得到权重。例如,网络问答系统判断语境继续的信心值为0.8,而在比较目前使用者问句与以前语境之间符合程度为0.6的话,权重可为这两者的平均值(0.7)。
此外,在本发明实施例中,可透过半监督学习(semi-supervised learning)技术,采取自我学习(Self-training)策略,让线上语境标记模块(将于底下说明),针对标记结果最佳的语句,自动回馈至训练数据集合。
或者,在本发明实施例中,可采取基于图论半监督学习(graph based semi-supervised)方法,透过建立对话语句之间的相似度矩阵,将标记传递(propagation)到其他未标记的对话语句,达成语境标记模型的调适。
另外,本发明实施例也可调整语境标记模型的参数,透过领域调适(Domain Adaptation)或迁移学习(transfer learning)来调整。例如将公式(3)中的λ系数细分为测试领域(即线上语境标记所收集到的对话回合)与原始训练资料领域。对于已收集到的数据,可利用预期最大化算法(Expectation-maximization Algorithm)来优化公式(3),此时所得的测试领域的λ系数,即是领域调适后的系数,可用于语境标记模型,进行语境标记。
优选地,在本发明实施例中,透过可调整式生成特征(adaptive generative feature),例如透过主题模型如潜在狄利克雷分配模型(latent dirichlet allocation,LDA)将未标记的数据和已标记的数据混合,以训练语境标记模型,并将该语境标记模型的参数(例如分布机率),当成新的特征,来扩充原本语境标记模型所需的特征集合,以调适语境标记模型。
本发明另一实施例提供自动侦测语境段落的网络问答系统,其方块图如图8所示。如图8所示,本发明实施例的自动侦测语境段落的网络问答系统800包括:问答记录模块810、用户语境结束事件收集模块820、语境标记模型训练模块830、线上实时对话语境标记模块840、语境清除与回答模块850、比较模块860、语境标记更正模块870、语境标记模型调适模块880与用户语境结束事件侦测模块890。
问答记录模块810收集用户对话记录,以记录用户与网络问答系统之间的问答相关信息。问答记录模块810所收集的用户对话记录系记录至用户对话记录数据库140中。
用户语境结束事件收集模块820收集用户语境结束事件与事件背景信息。使用者语境结束事件例如包括但不受限于:(1)使用者按下重置(reset)键事件;(2)用户交易事件;(3)使用者浏览事件;以及(4)闲置时期超过门坎值事件。用户语境结束事件收集模块820所收集的事件背景信息是指用户语境结束事件的背景信息,包括例如但不受限于,重置时间、相关问答回合记录、用户闲置时期、用户浏览记录、用户事务历史记录等相关信息。用户语境结束事件收集模块820判断所收集的语境结束标记的数量是否足够用于训练语境标记模型。
语境标记模型训练模块830训练语境标记模型150。语境标记模型训练模块830将用户语境结束事件与记录于用户对话记录数据库140中的用户对话记录当成训练数据。
线上实时对话语境标记模块840利用已训练好的语境标记模型150来将用户问句实时标记为语境继续(DC)或语境结束(DE),且一并标记出信心值。
如果当前回合用户问句被标记为语境结束的话,则语境清除与回答模块850清除旧段落的语境并回答使用者的问句。如果当前回合用户问句被标记为语境继续,则语境清除与回答模块850不清除语境,但仍要回答使用者的问句。
比较模块860比较下一回合使用者问句与旧段落之间的符合程度。如果比较模块860判断下一回合使用者问句与旧段落相符合,则表示对该当前回合用户问句标记为语境结束是错误。根据比较模块860的判断结果,语境标记更正模块870决定是否将该当前回合使用者问句的该语境从语境结束(DE)更正为语境继续(DC)。
语境标记模型调适模块880调适语境标记模型150。
用户语境结束事件侦测模块890判断是否侦测到使用者语境结束事件((1)使用者按下重置(reset)键事件;(2)用户交易事件;(3)浏览事件;以及(4)闲置时期超过门坎值))。用户语境结束事件侦测模块890侦测用户是否主动结束语境。
如果线上实时对话语境标记模块840对当前回合用户问句标记为语境继续(DC)但使用者语境结束事件侦测模块890侦测到用户语境结束事件,则代表线上实时对话语境标记模块840将当前回合用户问句标记成语境继续是错误的。语境标记更正模块870将上一回合所标记的语境继续(DC)更正为语境结束(DE)。
图9显示根据本发明一实施例的网络问答方法的流程图。于步骤905中,接收当前回合使用者问句。于步骤910中,根据语境标记模型,线上实时标记该当前回合用户问句的语境为语境继续或语境结束。于步骤915中,根据该当前回合使用者问句的该语境,决定是否清除旧段落的至少一语境。于步骤920中,由该网络问答系统回答该当前回合用户问句。于步骤925中,比较下一回合使用者问句与该旧段落之间的符合程度,以判断所标记的该当前回合用户问句的该语境是否正确,是否要更正该当前回合使用者问句的该语境,以及判断是否要将该当前回合使用者问句用于调适该语境标记模型。
图10显示本发明另一实施例的网络问答系统的方块图。网络问答系统1000包括:线上实时对话语境标记模块1010、语境清除与回答模块1020、比较模块1030、语境标记更正模块1040与语境标记模型调适模块1050。
线上实时对话语境标记模块1010线上实时标记当前回合用户问句的语境为语境继续或语境结束。
语境清除与回答模块1020根据该当前回合使用者问句的该语境,决定是否清除旧段落的至少一语境。语境清除与回答模块1020回答该当前回合使用者问句。
比较模块1030比较下一回合使用者问句与该旧段落之间的符合程度,以判断所标记的该当前回合用户问句的该语境是否正确。
语境标记更正模块1040根据该比较模块的判断结果以决定是否更正该当前回合使用者问句的该语境。
语境标记模型调适模块1050根据该比较模块的判断结果以判断是否将该当前回合使用者问句用于调适该语境标记模型。
本发明一实施例还提出一种内储程序的计算机可读取记录媒体,当计算机加载该程序并执行后,可完成如上述实施例所载的网络问答方法。
现有的网络问答系统(如Wolfram Alpha)与搜寻网站(如Google)虽可提供单次问答服务,但其问答历程不保留/考虑历史对话内容。所以,每次使用者在提问时,使用者都必须提供完整的问答信息,对用户而言相当不便。相反地,本发明实施例的网络问答系统与方法可搜集与分析使用者历史互动问答行为,即便使用者在提问时没有提供完整的问答信息,本发明实施例的网络问答系统与方法仍可准确地回答使用者提问。故而,本发明实施例的网络问答系统与方法对用户而言相当友善。
另外,现有的智能代理人服务(如VoiceBox,Siri)等虽可保留历史对话记录以提供智能化的问答模式。然而,这类的智能代理人服务的回答可能会和使用者问句之间发生语意冲突,使得回答不够精准。相反地,本发明实施例的网络问答系统与方法除了搜集与分析使用者历史互动问答行为之外,更可自动侦测语境段落与自动重置使用者的历史对话状态。故而,本发明实施例的网络问答系统与方法可减少因对话过程不同意图所造成的语意冲突,提供更智能化的问答体验。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!