一种油田开发的专家决策系统的制作方法
本发明涉及油田开发领域,具体地说是一种油田开发的专家决策系统。
背景技术:
油田开发是一项隐蔽的技术工程,具有高投入、高产出、高风险的特点和不可逆性,因此科学的决策尤为重要。同时,油田开发也是专业性和实践性非常强的,有些优秀的专家在长期油田开发中总结的经验是一笔伟大的财富;同时油田进入高含水中后期开发后,随着开采程度的加深,地下油水关系,剩余油分布越来越复杂,非均质性更严重,给油田稳产和跳帧挖潜带来的难度越来越大。油田随着含水率的增加,都要采取各种措施和方案进行综合治理与开采,在这些措施和方法中,如何评价这些措施,从而选择正确的措施提供依据是十分重要的。油田开发也是需要规划长远发展目标、提出实现目标的方案和措施以及方案评价,这样油田开发即遵循自身的规律,又能实现高效、可持续发展。
由于涉及分布在不同领域和众多职能部门,信息种类繁多、数据量大,综合利用这些分散的易购环境的数据源,及时得到准确、科学而有效的决策依据对决策人员至关重要。在现有的油田开发规划理论方法中,信息的组织与处理缺乏集中存储和翻译分析,不能够满足管理人员以及决策人员对信息的分析以及利用。
技术实现要素:
针对现有技术的不足,本发明提供一种油田开发的专家决策系统;不仅集成了油田开发中所需的海量数据,并将其向量化分类,同时运用了支持向量机将其进行分类,最终通过专家决策库进行系统的校验。
本发明为实现上述目的所采用的技术方案是:
一种油田开发的专家决策系统,包括以下步骤:
步骤1:将油田开发中所需的基础数据排列成向量,录入到基础向量表;
步骤2:将基础向量表中的向量进行归一化处理;
步骤3:判断归一化后的向量是否为合理向量,如果是,则判断结束;否则为不合理向量,完成向量分类;
步骤4:将不合理向量导入专家决策库,判断如果合格,则判断结束;否则调整向量参数后返回步骤3。
所述向量的格式符合支持向量机的处理规则,每个数据信息按照由小到大顺序排列,中间以空格分开,每个数据信息前面添加向量维度。
所述向量维度从1到n的正整数。
所述归一化按照最小化-最大化的方法进行标准化,对原始的数据信息进行线性变化,使结果映射到0到1之间,归一化的向量表示为:
x*=(x-min)/(max-min);
其中x为数据信息的值;x*为归一化的向量,max为该数据信息在一定范围内的最大值,min为该数据信息在一定范围内的最小值。
所述向量分类过程先提取一部分归一化向量作为训练数据,然后将训练数据经过支持向量机进行训练,形成分类函数,然后将未分类的向量数据经过分类函数进行分类。
所述合理向量为在油田开发中能够给油田带来经济效益或者实现在开采中节能提效的措施和方法,在向量前用“+1”表示。
所述不合理向量为在油田开发中不能够给油田带来经济收益或者不利于油田再次开发、毁坏地质结构等措施和方法,在向量前用“-1”表示。
所述专家决策库以传统匹配模式为核心匹配模式。
本发明具有以下有益效果及优点:
该系统能够实时并且能支持各种类型的数据查询、分析以及决策,以实现油田开发规划网络化、信息化和管理化,从而全面提高油田开发规则水平,不仅提高了管理人员以及决策人员的工作效率,更加为油田的开采制定了快速、 准确的规划,节约了成本。
附图说明
图1是本发明的工作流程图;
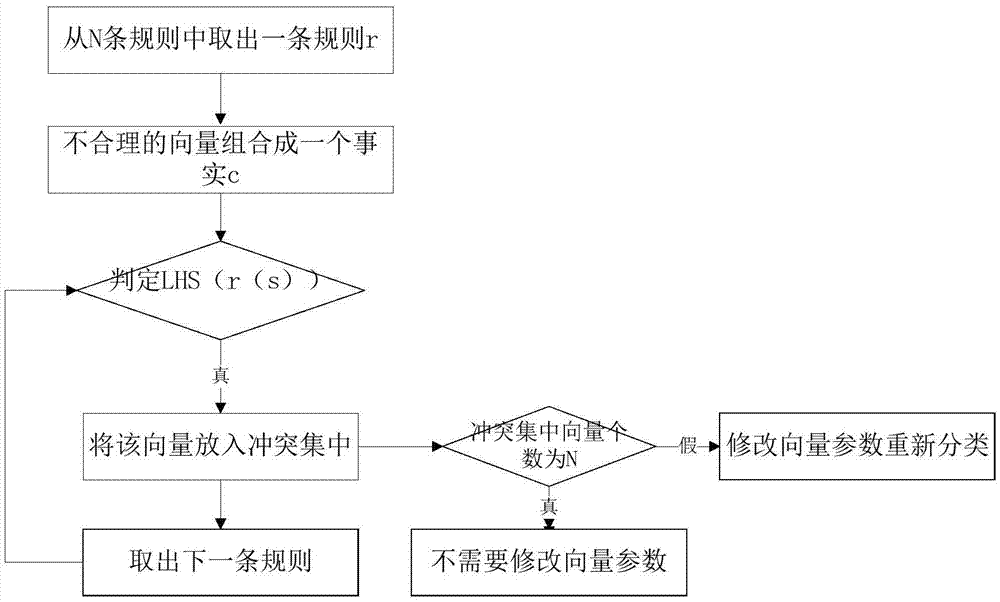
图2是本发明的传统模式匹配流程图;
图3是本发明的支持向量机的分类图;
图4是本发明的支持向量机工作原理图。
具体实施方式
下面结合附图及实施例对本发明做进一步的详细说明。
油田开发专家决策系统包括四个部分:首先是将决策的基础数据录入到基础向量表中;第二将向量表中的数据进行归一化处理;第三,将处理好的向量表通过支持向量机进行分类,将不合理的向量进行提取;第四,将不合理的向量通过专家库的决策筛选,确定最终的决策结果。该方法创建了集专家经验、基础分类以及油田开发实例于一体的决策系统,实现了油田中规划方案、经济效益等评比的智能化,大幅度的节约了在油田开发过程中的时间以及能源。
油田开发专家系统的工作流程图如图1所示
将决策的基础数据录入到基础向量表后,按照最小化-最大化的方法进行归一化,即min-max归一化,对原始的数据信息进行线性变化,使结果映射到0-1之间,其转换函数为:
x*=(x-min)/(max-min)
提取一部分的归一化向量,根据油田专家的专业知识以及知识库,将归一化向量分为两类:合理向量以及不合理向量;通过此方法形成了支持向量机的训练数据。
支持向量机通过训练数据生成了分类函数,其分类图如图3所示;圆形的点为合理的决策向量,方形的点为不合理的决策向量,图中的直线表示区分合理和不合理向量的分界线,即分类函数,分类函数的作用就是把这两种不同颜色的数据点分割开来,在分类函数一边的数据点所对应的向量头为-1,而在另一 边全是+1。通过支持向量机,可以把决策向量进行分类,通过确定了分类函数,再来新的决策向量,可以通过分类函数来判断其是否合理,如果不合理,则需要进行下一步的处理,通过专家决策库进行筛选。支持向量机的运行流程图如图4所示。
决策库的内在核心为传统模式匹配,其具体算法流程如图所示;首先从n条规则中取出一条规则r;其次将不合理的向量组合成一个事实c;最后执行左手规则lhs(r(c))如果为真,则将该向量加入冲突集中;取出下一条规则r重复执行;如果冲突集中的向量个数等于n,则判定该向量为合理向量。
技术特征:
技术总结
本发明涉及一种油田开发的专家决策系统,将油田开发中所需的基础数据排列成向量,录入到基础向量表;将基础向量表中的向量进行归一化处理;判断归一化后的向量是否为合理向量,如果是,则判断结束;否则为不合理向量,完成向量分类;将不合理向量导入专家决策库,判断如果合格,则判断结束;否则调整向量参数后返回步骤3。本发明能够实时并且能支持各种类型的数据查询、分析以及决策,以实现油田开发规划网络化、信息化和管理化,从而全面提高油田开发规则水平,不仅提高了管理人员以及决策人员的工作效率,更加为油田的开采制定了快速、准确的规划,节约了成本。
技术研发人员:张天石;刘阳;佟星;曾鹏;于海斌;李铁栓;顾峰硕
受保护的技术使用者:中国科学院沈阳自动化研究所
技术研发日:2015.12.29
技术公布日:2017.07.07
- 还没有人留言评论。精彩留言会获得点赞!