一种论述型文章的论述主体的自动提取方法与流程
本发明涉及一种论述型文章的论述主体的自动提取方法,属于自然语言处理的计算机技术应用领域。
背景技术:
论述型文章是作者针对某个论述主体,通过撰写表达各种研究、分析的过程和结论的书面表现形式。其中论述主体作为论述型文章的核心对象,包括客观事物、理论、事件、过程、关系等属性实例,能高效清晰定位出对应文章的关注面。论述主体的提取和展现能够将文章的主要展示目标以直观的形式展现出来,有助于阅读人员快速掌握这一对象的相关信息,方便的检索和对比相关内容。
但在当前的论述型文章中,由于不存在论述主体的强制规范表述,写作人员对论述主体的表现形式各异,而文章发布人员出于曝光量和吸引关注度的目的,又常刻意隐藏实际的论述主体(如标题党,刻意扭曲或放大不相关的信息),更多的展现文章的普遍性,从而增加了读者阅读精确的难度。
自动从论述型文章中提取出论述主体,已有的处理方法有很多,其中有基于规则的方法,此方法取得了一定的效果,但由于自然语言句式的多样性,导致该方法并不能覆盖论述主体提取中的所有规则,且不能实时更新,灵活性差。
本发明基于统计条件随机场的序列标注策略,通过分析论文标题中论述主体的语义特点和位置特征,结合训练语料的特性建立常用词语词典和重要词语词典,同时利用词典和词语、位置等信息对论文标题进行序列特征标注,运用标注的语料训练生成模型,可对未知数据进行预测,具有较高的准确率,可有效提高算法的在不同场景下的适用性。
技术实现要素:
本发明是为了解决计算机在自然语言处理中难以直接提取论述型文章的论述主体的难题,提供了一种高效自动的抽取模型的训练和应用方法。
本发明设计的方法由训练模型和应用模型两个阶段组成,它包括以下步骤:
训练阶段
训练步骤一:获取模型训练阶段的依赖资源:获取已做好标记(训练语料的语句中的字符有确定的是否被标注为研究主体的标识)的ns个句子的集合s={s(i)}为训练语料,各句子记为s(i),其中1≤i≤ns,要求ns≥10000;获取人工总结的重要词汇词典di;
训练步骤二:基于训练语句生成常用词词典dc;具体实现步骤为:
训练步骤二一:在每个训练语句的句子中,以此句中的所有论述主体的字符串的起始和截止序位,对此句子进行分割后,形成多个子字符串,并去除每个语句样本的论述主体对应的字符串,取剩下的所有字符串,记为se;
训练步骤二二:对se中所有的字符串做分词处理,并在分词后形成的每个词语中过滤掉所有数字,取剩下的所有词语,记为we;
训练步骤二三:归并we的词语,去除重复的词,剩下的词即组成的常用词词典dz;
训练步骤三:对训练语句s的所有字符进行特征化表示,得到每个字符特征表示结果,记
对标题中每个字符s(i,j),即标题s(i)中第j个字符,对应的特征化结果表示为如下106个特征:
则由多个字组成的整个标题s(i)的特征表示为:
其中len(s)是标题s(i)的字符数,1≤j≤len(s),
训练步骤三一:对语句中每个字符进行标记,即对各个句子s(i)中的每个序位上的字符,建立各字符相应的11个单独特征,分别表示为f0(i,j0),f0(i,j1),f0(i,j2),f0(i,j3),f0(i,j4),f0(i,j5),f0(i,j6),f0(i,j7),f0(i,j8),f0(i,j9),f0(i,j10);符号注释:其中fn(i,j)其中n为字j的相对位置,取值-2,-1,0,1,2等
(1)当前该字符f0(i,j0),也作为一个特征
(2)标记类型特征:
(3)标记常用字典中的词语:
(4)
(5)对语句i分词之后,标记字所在的词语位置:
(6)对语句i分词之后,标记字所在词语的词性:
(7)标记重要词典中的词语:
训练步骤三二:对单个字符的特征进行汇总,建立各序位的字符前后2个字符及当前字符的单独特征,共计55个特征,分别表示为
当前字符的前边第2个字符
当前字符的前边第1个字符
当前字符
当前字符的后边第1个字符
当前字符的后边第2个字符
其中前后2个字的字符为:
训练步骤三三:对各个句子s(i)中的每个序位上的字符,建立各字符对应的unigram和bigram的特征,共7个特征,分别表示为:
其中
训练步骤三四:对各个句子s(i)中的每个序位上的字符,建立字符所在语句i的最后4个字符的特征表示,共44个,分别表示为:
倒数第1个字符
倒数第2个字符
倒数第3个字符
倒数第4个字符
其中最后4个字的字符为:
训练步骤四:对训练语句的各个句子的字符,根据是否是讨论主体的判断标记,进行数字化表示,对应得到各句子s(i)的每个序位上的字符s(i,j)的新词标记表示结果g(s(i,j));
其中:
训练步骤五:基于条件随机场模型,将训练语句中所有字符的特征化结果
应用阶段
应用步骤一:对要提取论述主体的长文,获取长文的文字内容g,模型m,重要词典di,常用词典dz;
应用步骤二:基于自动算法,提取gp的摘要语句,记摘要句总数为ngp,则各摘要句记为t(i),其中0<i<ngp,r(i,j)为对应t(i)的第i个摘要句的第j个字符;
应用步骤三:对各个摘要句t(i)的各个字符r(i,j),提取对应的特征表示结果,对应的特征化结果表示为如下106个特征:
其中len(t(i))是标题t(i)的字符数,1≤j≤len(s),
应用步骤三一:对t(i)中每个字符进行标记,即对各个句子t(i)中的每个序位上的字符,建立各字符相应的11个单独特征,分别表示为f0(i,j0),f0(i,j1),f0(i,j2),f0(i,j3),f0(i,j4),f0(i,j5),f0(i,j6),f0(i,j7),f0(i,j8),f0(i,j9),f0(i,j10);符号注释:其中fn(i,j)其中n为字j的相对位置,取值-2,-1,0,1,2等
(1)当前该字符f0(i,j0),也作为一个特征
(2)标记类型特征:
(3)标记常用字典中的词语:
(4)
(5)对t(i)分词之后,标记字所在的词语位置:
(6)对t(i)分词之后,标记字所在词语的词性:
(7)标记重要词典中的词语:
应用步骤三二:对单个字符的特征进行汇总,建立各序位的字符前后2个字符及当前字符的单独特征,共计55个特征,分别表示为
当前字符的前边第2个字符
当前字符的前边第1个字符
当前字符
当前字符的后边第1个字符
当前字符的后边第2个字符
其中前后2个字的字符为:
应用步骤三三:对各个句子t(i)中的每个序位上的字符,建立各字符对应的unigram和bigram的特征,共7个特征,分别表示为:
其中
应用步骤三四:对各个句子t(i)中的每个序位上的字符,建立字符所在语句i的最后4个字符的特征表示,共44个,分别表示为:
倒数第1个字符
倒数第2个字符
倒数第3个字符
倒数第4个字符
其中最后4个字的字符为:
应用步骤四:将所有字符的特征化结果f(r(i,j))输入已训练好的模型m中,并由模型m进行分类评判,输出各字符对应的分类结果g(r(i,j));
应用步骤五:输出所有g(r(i,j))值为b或e的字符r(i,j)的序位,则在语句t(i)中,提取每个如下情况的字符串:以标为b的字符的作为起始序位,截止到往后的最近的以标为e的字符的作为终止序位,这些截取出的字符串即作为此长文的论述主体。
本发明的优点是:本发明基于统计条件随机场的序列标注策略,通过分析论文标题中论述主体的语义特点和位置特征,结合训练语料的特性建立常用词语词典和重要词语词典,同时利用词典和词语、位置等信息对论文标题进行序列特征标注,运用标注的语料训练生成模型,可对未知数据进行预测,具有较高的准确率,可有效提高算法的在不同场景下的适用性。
本发明有效实现了计算机自动在论述型文章中提取出论述主体,将文章的主要展示目标以直观的形式展现出来,有助于阅读人员快速掌握这一对象的相关信息,方便的检索和对比相关内容,而自动提取后的短语也可进一步供给计算机做后续的各种分析。
附图说明
图1为本发明的模型训练的方法的流程图,图2为应用的方法的流程图。
具体实施方式
下面结合附图图1和图2说明本实施方式。
本发明设计的方法由训练模型和应用模型两个阶段组成,它包括以下步骤:
训练阶段
训练步骤一:获取模型训练阶段的依赖资源:获取已做好标记(训练语料的语句中的字符有确定的是否被标注为研究主体的标识)的ns个句子的集合s={s(i)}为训练语料,各句子记为s(i),其中1≤i≤ns,要求ns≥10000;获取人工总结的重要词汇词典di;
训练步骤二:基于训练语句生成常用词词典dc;具体实现步骤为:
训练步骤二一:在每个训练语句的句子中,以此句中的所有论述主体的字符串的起始和截止序位,对此句子进行分割后,形成多个子字符串,并去除每个语句样本的论述主体对应的字符串,取剩下的所有字符串,记为se;
训练步骤二二:对se中所有的字符串做分词处理,并在分词后形成的每个词语中过滤掉所有数字,取剩下的所有词语,记为we;
训练步骤二三:归并we的词语,去除重复的词,剩下的词即组成的常用词词典dz;
训练步骤三:对训练语句s的所有字符进行特征化表示,得到每个字符特征表示结果,记
对标题中每个字符s(i,j),即标题s(i)中第j个字符,对应的特征化结果表示为如下106个特征:
则由多个字组成的整个标题s(i)的特征表示为:
其中len(s)是标题s(i)的字符数,1≤j≤len(s),
训练步骤三一:对语句中每个字符进行标记,即对各个句子s(i)中的每个序位上的字符,建立各字符相应的11个单独特征,分别表示为f0(i,j0),f0(i,j1),f0(i,j2),f0(i,j3),f0(i,j4),f0(i,j5),f0(i,j6),f0(i,j7),f0(i,j8),f0(i,j9),f0(i,j10);符号注释:其中fn(i,j)其中n为字j的相对位置,取值-2,-1,0,1,2等
(1)当前该字符f0(i,j0),也作为一个特征
(2)标记类型特征:
(3)标记常用字典中的词语:
(4)
(5)对语句i分词之后,标记字所在的词语位置:
(6)对语句i分词之后,标记字所在词语的词性:
(7)标记重要词典中的词语:
训练步骤三二:对单个字符的特征进行汇总,建立各序位的字符前后2个字符及当前字符的单独特征,共计55个特征,分别表示为
当前字符的前边第2个字符
当前字符的前边第1个字符
当前字符
当前字符的后边第1个字符
当前字符的后边第2个字符
其中前后2个字的字符为:
训练步骤三三:对各个句子s(i)中的每个序位上的字符,建立各字符对应的unigram和bigram的特征,共7个特征,分别表示为:
其中
训练步骤三四:对各个句子s(i)中的每个序位上的字符,建立字符所在语句i的最后4个字符的特征表示,共44个,分别表示为:
倒数第1个字符
倒数第2个字符
倒数第3个字符
倒数第4个字符
其中最后4个字的字符为:
训练步骤四:对训练语句的各个句子的字符,根据是否是讨论主体的判断标记,进行数字化表示,对应得到各句子s(i)的每个序位上的字符s(i,j)的新词标记表示结果g(s(i,j));
其中:
训练步骤五:基于条件随机场模型,将训练语句中所有字符的特征化结果
应用阶段
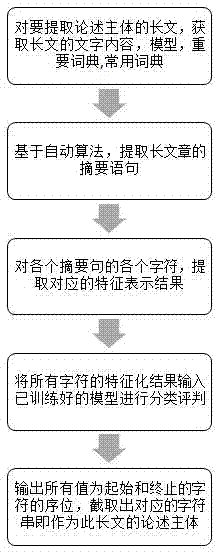
应用步骤一:对要提取论述主体的长文,获取长文的文字内容g,模型m,重要词典di,常用词典dz;
应用步骤二:基于自动算法,提取gp的摘要语句,记摘要句总数为ngp,则各摘要句记为t(i),其中0<i<ngp,r(i,j)为对应t(i)的第i个摘要句的第j个字符;
应用步骤三:对各个摘要句t(i)的各个字符r(i,j),提取对应的特征表示结果,对应的特征化结果表示为如下106个特征:
其中len(t(i))是标题t(i)的字符数,1≤j≤len(s),
应用步骤三一:对t(i)中每个字符进行标记,即对各个句子t(i)中的每个序位上的字符,建立各字符相应的11个单独特征,分别表示为f0(i,j0),f0(i,j1),f0(i,j2),f0(i,j3),f0(i,j4),f0(i,j5),f0(i,j6),f0(i,j7),f0(i,j8),f0(i,j9),f0(i,j10);符号注释:其中fn(i,j)其中n为字j的相对位置,取值-2,-1,0,1,2等
(1)当前该字符f0(i,j0),也作为一个特征
(2)标记类型特征:
(3)标记常用字典中的词语:
(4)
(5)对t(i)分词之后,标记字所在的词语位置:
(6)对t(i)分词之后,标记字所在词语的词性:
(7)标记重要词典中的词语:
应用步骤三二:对单个字符的特征进行汇总,建立各序位的字符前后2个字符及当前字符的单独特征,共计55个特征,分别表示为
当前字符的前边第2个字符
当前字符的前边第1个字符
当前字符
当前字符的后边第1个字符
当前字符的后边第2个字符
其中前后2个字的字符为:
应用步骤三三:对各个句子t(i)中的每个序位上的字符,建立各字符对应的unigram和bigram的特征,共7个特征,分别表示为:
其中
应用步骤三四:对各个句子t(i)中的每个序位上的字符,建立字符所在语句i的最后4个字符的特征表示,共44个,分别表示为:
倒数第1个字符
倒数第2个字符
倒数第3个字符
倒数第4个字符
其中最后4个字的字符为:
应用步骤四:将所有字符的特征化结果f(r(i,j))输入已训练好的模型m中,并由模型m进行分类评判,输出各字符对应的分类结果g(r(i,j));
应用步骤五:输出所有g(r(i,j))值为b或e的字符r(i,j)的序位,则在语句t(i)中,提取每个如下情况的字符串:以标为b的字符的作为起始序位,截止到往后的最近的以标为e的字符的作为终止序位,这些截取出的字符串即作为此长文的论述主体。
- 还没有人留言评论。精彩留言会获得点赞!