一种人脸识别装置的制作方法
本实用新型涉及计算机视觉和模式识别领域,特别是涉及一种人脸识别装置。
背景技术:
近年来由于稀疏表示分类器(Sparse Representation-based classification,简称SRC)方法的提出,人脸识别的研究取得了瞩目的进展。
人脸识别的任务可以这样定义:给定一张人脸图像(测试样本),判断该人脸图像的身份对应事先收集的图像(训练样本集,也称为字典)中的哪一个人。其中训练样本集里面包含多个不同身份的人,每个人有多张训练样本。SRC方法的依据是:对每一个测试样本,它可以通过训练样本集中相同类别的人脸图像的线性组合来表示。这样的话,与测试样本类别相同的训练样本对应的系数不为零,而其他的样本对应的系数为零。因此,这个稀疏的表达向量,可以看成测试样本在训练集上的一种表示,也称之为稀疏表示,并且这种表示很好地反映出了测试图像的身份信息。
SRC方法可以概括为两个步骤:(1)用凸优化的现有解法求解对应测试样本的稀疏表示;(2)根据得到的稀疏表示,利用字典分类器(Dictionary Classifier,简称DC)分类。大量理论研究与实验表明,SRC方法比传统的人脸识别方法(如最近邻法、向量机法等)性能更优越。目前有关SRC方法研究主要集中在训练字典的学习、稀疏重建算法、对遮挡、失配准和单样本场景等方面。
目前人脸识别的难点在于:
(1)表情引起的人脸塑性变形
(2)姿态引起的人脸多样性
(3)年龄引起的人脸变化
(4)发型、胡须、眼镜、化妆等因素引起的人脸模式的多重性
(5)光照的角度、强度以及传感器特性等因素引起的人脸图像的差异性诸多的因素使得人脸识别率大幅度下降。
虽然SRC方法中的DC已经取得了较好的实验效果,但是由于人脸识别问题在现实场景中的复杂性,DC仍然存在很多的局限性,导致识别任务的失败。
技术实现要素:
本实用新型的目的是提供一种人脸识别的方法及装置,目的在于增强现有识别技术的分类能力,提高识别成功率,更好地进行人脸识别。
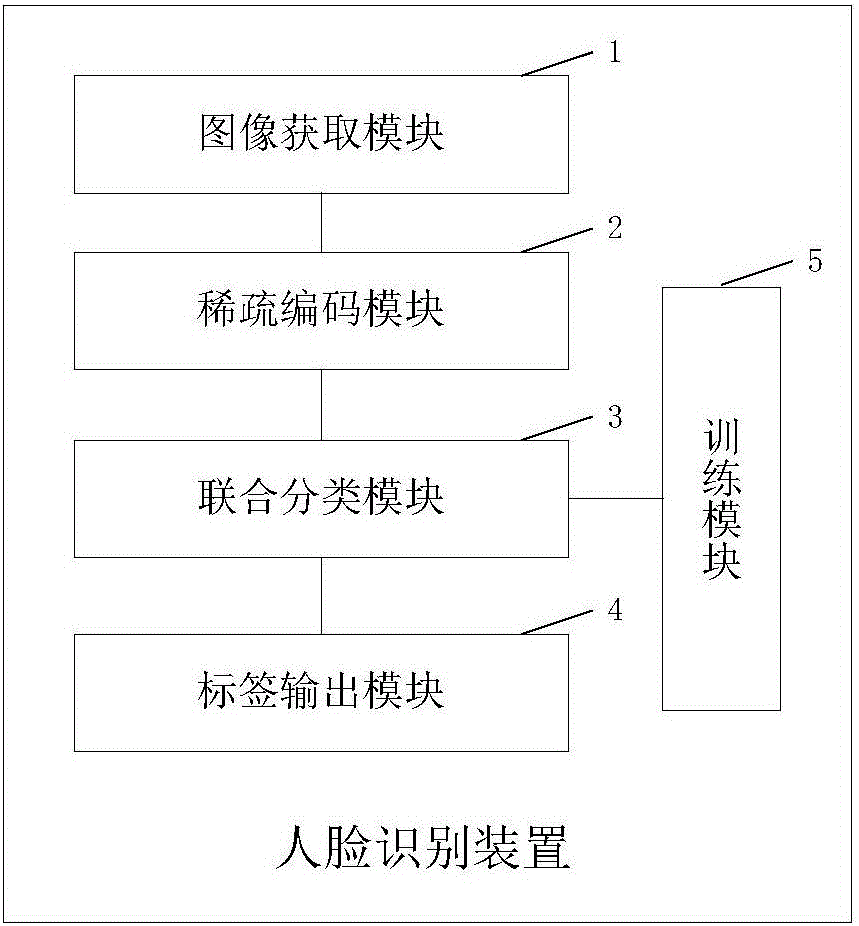
为解决上述技术问题,本实用新型提供一种人脸识别装置,所述装置包括:图像获取模块、稀疏编码模块、联合分类模块和标签输出模块,上述各模块依次顺序连接,其中,
所述图像获取模块,用于将获取得到的人脸图像数据作为测试样本;
所述稀疏编码模块,用于对所述测试样本进行稀疏编码,得到测试样本的稀疏表达;
所述联合分类模块,包括字典分类器和线性分类器,用于对所述测试样本进行联合分类;
所述标签输出模块,用于输出所述测试样本的类别标签。
进一步地,所述装置还包括训练模块,所述训练模块与所述联合分类模块连接,用于预先构造所述字典分类器和训练所述线性分类器。
进一步地,所述训练模块包括:训练样本集建立单元、字典分类器构造单元以及线性分类器训练单元,上述各单元依次顺序连接,其中,
所述训练样本集建立单元,用于建立人脸训练样本集合Y;
所述字典分类器构造单元,用于利用所述人脸训练样本集合Y构造过完备字典D;
所述线性分类器训练单元,用于利用所述人脸训练样本集合Y训练线性分类器W。
进一步地,所述联合分类模块包括:字典分类器、第一判别单元、线性分类器以及第二判别单元,上述各单元依次顺序连接,其中,
所述字典分类器,用于对测试样本进行字典分类;
所述第一判别单元,用于通过构造的第一残差指数RI1判断字典分类器的分类结果是否可靠;
所述线性分类器,用于对测试样本进行线性分类;
所述第二判别单元,用于通过构造的第二残差指数RI2判断线性分类器的分 类结果是否可靠。
进一步地,所述第一残差指数RI1可根据测试样本隶属于目标样本的后验概率构造得到,具体如下:
定义字典分类器的第一残差指数RI1:
其中,用于对RI1进行归一化,μ2是常数。
进一步地,所述第二残差指数RI2可根据测试样本隶属于目标样本的后验概率构造得到,具体如下:
定义线性分类器的第二残差指数RI2:
其中,用于对RI2进行归一化,μ2是常数。
本发明相对于现有技术具有如下的优点及效果:
本实用新型所提出的人脸识别装置,对人脸测试样本进行稀疏编码,得到测试样本的稀疏向量。然后利用字典分类器和线性分类器先后对测试样本进行分类,根据类别判定公式确定测试样本的类别,以达到人脸识别的目的。本实用新型所提供的人脸识别装置,联合字典分类器和线性分类器对测试样本分类,能够更好地利用稀疏向量包含的判别信息,增强分类能力,提高识别成功率。
附图说明
为了更清楚地说明本实用新型实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍。
图1为本实用新型公开的的人脸识别装置的结构框图;
图2为本实用新型公开的的人脸识别装置的另一结构框图;
图3为本实用新型公开的的人脸识别装置中训练模块的结构框图;
图4为本实用新型公开的的人脸识别装置中联合分类模块的结构框图;
图5为三种人脸识别装置的分类精度随着原子数变化曲线图。
具体实施方式
下面将结合本实用新型实施例中的附图,对本实用新型实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本实用新型一部分实施例,而不是全部的实施例。基于本实用新型中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本实用新型保护的范围。
实施例
本实用新型所提供的人脸识别装置的一种具体实施方式的结构框图如图1所示,该装置包括:
图像获取模块1,用于将获取得到的人脸图像数据作为测试样本。
稀疏编码模块2,用于对所述测试样本进行稀疏编码,得到测试样本的稀疏表达。
联合分类模块3,包括字典分类器和线性分类器,用于对所述测试样本进行联合分类,以提高识别成功率。
标签输出模块4,用于输出所述测试样本的类别标签。
在另一优选的实施方式中,本实用新型所提供的人脸识别装置的另一种具体实施方式的结构框图如图2所示,该装置还包括:训练模块5,用于预先构造字典分类器和训练线性分类器,对所述测试样本进行分类,以提高识别成功率。
本实用新型所提供的人脸识别的装置中的训练模块5进一步可以包括:
训练样本集建立单元501,用于建立人脸训练样本集合Y。
字典分类器构造单元502,用于利用所述人脸训练样本集构造过完备字典D。
线性分类器训练单元503,用于利用所述人脸训练样本集训练线性分类器W。上述训练模块5的结构框图如附图3所示。其中,线性分类器训练单元503的工作过程为:
定义线性分类器的目标函数为:
W=argminW,X||Y-DX||F+λ1||X||1+λ2||H-WX||F+λ3||W||F
其中,是训练图像集,是训练图像集的稀疏表示系数矩阵,D是过完备字典,H的列向量hi=[0,0,…,1,…,0,0]T∈Rk×1是训练图像的标签向量,每个类别对应的位置元素不为零,||Y-DX||F是表示误差,||H-WX||F是分类误差,||X||1是稀疏约束项,||W||F是正则化罚项,λ1,λ2,λ3是维持各项平衡的标量。
算法流程为:
(1)初始化Y,D,H;
(2)忽略目标函数的第三项和第四项,通过下式求解表示系数矩阵X:
W=||Y-DX||F+λ1||X||1
(3)忽略目标函数的第一项和第二项,利用求解得到的表示系数矩阵X,通过下式求解线性分类器W:
W=λ2||H-WX||F+λ3||W||F
(4)输出X,W。
在另一优选的实施方式中,本实用新型所提供的人脸识别装置中的联合分类模块3的结构框图如图4所示,该联合分类模块3进一步包括:
字典分类器301,用于对测试样本进行字典分类,并将分类结果输出给第一判别单元302进行可靠性判断;
第一判别单元302,用于通过构造的第一残差指数RI1((Residual Index,简称RI)判断字典分类器的分类结果是否可靠,若分类结果判断为可靠,则转至标签输出模块4,若分类结果判断为不可靠,则转至线性分类器303;
线性分类器303,用于对测试样本进行线性分类,并将分类结果输出给第二判别单元304进行可靠性判断;
第二判别单元304,用于通过构造的第二残差指数RI2判断线性分类器的分类结果是否可靠,若分类结果判断为可靠,则转至标签输出模块4。
进一步地,残差指数RI可以具体为根据测试样本隶属于目标样本的后验概率构造得到:
定义字典分类器的第一残差指数RI1:
其中,用于对RI1进行归一化,μ2是常数;
定义线性分类器的第二残差指数RI2:
其中,用于对RI2进行归一化,μ2是常数。
下面具体介绍本实用新型提供的人脸识别装置的工程流程,在本实施流程 中,Extend Yale B人脸数据库包含了38个人的2432张人脸图像。每张图像在不同的光照条件下拍摄,图像的大小为195×168像素。从数据库随机选择50%作为训练样本,余下的50%作为测试样本,对每幅图像下采样至120维,字典每一类的原子数分别取为4,8,12,16,进行5次试验取平均值。
具体地,本实施例包括构造人脸训练数据集、构造字典分类器和训练线性分类器、以及利用以上两种分类器对图像进行分类的过程,包括以下步骤:
建立人脸训练样本集Y∈Rm×n;
根据人脸训练样本集Y,构造过完备字典D;
根据人脸训练样本集Y,训练线性分类器W;
输入人脸测试样本y;
对过完备字典D和测试样本y,利用如下优化函数:
求解最优的稀疏表示系数x;
将求解得到的稀疏表示系数x,分别代入类别带通函数δi,对测试样本进行重构,得到重构后的样本其中i=1,2,…,k,代表样本类别;
计算重构后的样本与测试样本的类重构误差ri:
将测试样本的类重构误差ri代入类别判定公式:
identity(y)=argmini ri
求得k个残差中的最小值,并将其下标i作为字典分类器的识别结果,用identity(y)表示;
计算字典分类的残差指数RIDC,如果RIDC(y)>τ,输出identity(y)作为识别结果,否则,判别字典分类结果不可靠,继续利用线性分类器进行分类;
获取的线性分类器W,采用下式计算测试样本y相对于每一个类别的加权相似度矩阵:
测试样本y的加权相似度代入类别判定公式:
identity(y)=argmaxizi
求得k个加权相似度中的最大值,并将其下标i作为线性分类器的识别结果,用identity(y)表示;
计算线性分类的残差指数RILC,设置阈值θ∈(0,1),如果RILC(y)>θ,输出identity(y)作为识别结果。
输出待识别人脸图像的类别标签。
这样就完成了对待识别人脸图像的分类。
图5给出了三种算法的分类精度随着维数变化曲线图。三种对比方法分别为:SRC,Discriminative K-SVD(简称DKSVD)以及本实用新型。可以看到在原子数目比较少的情况下,本实用新型的识别率是明显高于其他两种方法的,因此在实现的时候会带来方便。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本实用新型。对实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文所定义的一般原理可以在不脱离本实用新型的精神或范围的情况下,在其他实施例中实现。因此,本实用新型将不会被限制于本文所示的实施例,而是要符合于本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!