神经网络及神经网络训练的方法与流程
此申请主张2014年3月6日提出的美国临时申请案序号第61/949,210号、与2015年1月22日提出的美国临时申请案序号第62/106,389号的权益,所述申请的整体内容以引用方式而纳入本文。
技术领域
本申请内容涉及一种人工神经网络及训练人工神经网络的方法。
背景技术:
在机器学习中,人工神经网络可由也称为动物的中枢神经系统(特别是头脑)的生物神经网络所驱使的系列的统计学习算法。人工神经网络主要使用以估测或大致估计其可取决于大量输入的概括未知的功能。该种神经网络已经用于其为难以使用一般基于规则的程序设计来解决的广泛的种种任务,其包括计算机视觉与语音识别。
人工神经网络是概括呈现为“神经元(neuron)”的系统,其可计算来自输入的值,且由于其适应的性质而为能够机器学习、以及模式识别。每个神经元经常为通过具有神经结权重(weight)的神经结(synapse)而与数个输入连接。
神经网络并非如同典型的软件被程序设计,而是被训练。该种训练典型为经由充分数目个代表示例的分析且通过神经结权重的统计或算法的选择而实现,使得一个指定组的输入图像为对应于一个指定组的输出图像。传统的神经网络的一个常见的缺点在于,对于其训练而言,经常需要可观的时间与其他的资源。
各种的人工神经网络在以下的美国专利中进行了描述:4,979,124;5,479,575;5,493,688;5,566,273;5,682,503;5,870,729;7,577,631;以及7,814,038。
技术实现要素:
一种神经网络包括多个网络输入,从而使每个输入被配置成接收其具有一个输入值的一个输入信号。该种神经网络还包括多个神经结,其中每个神经结被连接到该多个输入的一个且包括多个校正(corrective)权重,其中每个校正权重是由一个权重值所界定。该种神经网络另外包括一组分配器。每个分配器运行连接到该多个输入的一个以供接收相应输入信号且被配置成从和输入值相关的该多个校正权重来选择一个或多个校正权重。该种神经网络还包括一组神经元。每个神经元具有至少一个输出且经由该多个神经结的一个而和该多个输入的至少一个为连接,且被配置成将选择自被连接到相应神经元的每个神经结的所述校正权重的权重值合计且由此产生一个神经元总和。此外,该种神经网络包括一个权重校正计算器,其被配置成接收具有一个值的一个期望输出信号,确定该神经元总和与该期望输出信号值的一个偏差,且使用该确定的偏差来修改相应的校正权重值。将修改的校正权重值合计以确定该神经元总和,使该神经元总和与该期望输出信号值的偏差为最小化,由此提供训练该神经网络。
该神经元总和与该期望输出信号的偏差的确定可包括该期望输出信号值除以该神经元总和,由此产生一个偏差系数。此外,所述相应的校正权重的修改可包括用以产生该神经元总和的每个校正权重乘以该偏差系数。
该神经元总和与该期望输出信号的偏差可为在其间的一个数学差异。在该种情形,所述相应修改的校正权重的产生可包括该数学差异的分摊到用以产生该神经元总和的每个校正权重。该数学差异的该种分摊到每个校正权重意欲将每个神经元总和收敛在该期望信号值上。
该数学差异的分摊也可包括将该确定的差异平均划分在用以产生该神经元总和的每个校正权重之间。
该分配器可另外配置成将多个影响(impact)系数指定到该多个校正权重,从而使每个影响系数是以一个预定的比例而被指定到该多个校正权重的一个以产生该神经元总和。
每个相应的多个影响系数可由一个影响分布函数所界定。该多个输入值可被接收到一个值范围,其根据一个区间分布函数而被划分为区间,从而使每个输入值被接收在一个相应区间内,且每个校正权重对应于所述区间的一个。此外,每个分配器可使用该输入信号的相应接收的输入值以选择该相应的区间。另外,每个分配器可将该相应的多个影响系数指定到其对应于该选择相应的区间的校正权重且到其对应于邻近于该选择相应的区间的一个区间的至少一个校正权重。
每个神经元可配置成将对于经连接到其的所有神经结的该校正权重与指定的影响系数的一个乘积合计。
所述影响系数的预定比例可根据一个统计分布所界定,诸如:使用一个高斯函数。
权重校正计算器可配置成根据由该相应的影响系数所建立的比例而将该确定的差异的一部分施加到用以产生该神经元总和的每个校正权重。
每个校正权重可另外由一组索引所界定。所述索引可包括:一个输入索引,其被设定成识别对应于该输入的校正权重;一个区间索引,其被设定成指定用于该相应校正权重的选择区间;以及,一个神经元索引,其被设定成指定对应于该神经元的校正权重。
每个校正权重可进而由一个存取索引所界定,该存取索引被设定成结算该相应校正权重在该神经网络的训练期间而由该输入信号所存取的次数。
一种训练该种神经网络的方法也被公开。
当结合附图与随附权利要求书来理解时,本公开内容的上述特征与优点、以及其他特征与优点将由用于实行所述的公开内容的实施例与最佳模式的以下详细说明而更为清楚。
附图说明
图1为一种现有技术的传统的人工神经网络的说明图。
图2为具有多个神经结、一组分配器、以及其和每个神经结有关联的多个校正权重的一种“渐进式神经网络”(p网络)的说明图。
图3A为在图2所示的p网络的一部分的说明图,其具有多个神经结与经定位在每个分配器的上游的一个神经结权重。
图3B为在图2所示的p网络的一部分的说明图,其具有多个神经结与经定位在相应的多个校正权重的下游的一组神经结权重。
图3C为在图2所示的p网络的一部分的说明图,其具有多个神经结与经定位在每个分配器的上游的一个神经结权重以及经定位在相应的多个校正权重的下游的一组神经结权重。
图4A为在图2所示的p网络的一部分的说明图,其具有用于一个指定输入的所有神经结的单个分配器与经定位在每个分配器的上游的一个神经结权重。
图4B为在图2所示的p网络的一部分的说明图,其具有用于一个指定输入的所有神经结的单个分配器与经定位在相应的多个校正权重的下游的一组神经结权重。
图4C为在图2所示的p网络的一部分的说明图,其具有用于一个指定输入的所有神经结的单个分配器,且具有经定位在每个分配器的上游的一个神经结权重以及经定位在相应的多个校正权重的下游的一组神经结权重。
图5为在图2所示的p网络中的输入信号值范围的划分为个别区间的说明图。
图6A为用于在图2所示的p网络中的校正权重的影响为数值的分布的一个实施例的说明图。
图6B为用于在图2所示的p网络中的校正权重的影响为数值的分布的另一个实施例的说明图。
图6C为用于在图2所示的p网络中的校正权重的影响为数值的分布的又一个实施例的说明图。
图7为用于在图2所示的p网络的一个输入图像的说明图、以及其用数字码的形式来代表该图像的一个对应表格与其作为一组相应区间来代表该同个图像的另一个对应表格。
图8为在图2所示的p网络的一个实施例的说明图,该p网络被训练以供二个相异图像的辨识,其中该p网络被配置成辨识其包括每个图像的一些特征的一个图像。
图9为在图2所示的p网络的一个实施例的说明图,其具有环绕一个“中央”神经元的神经结权重的分布的一个示例。
图10为在图2所示的p网络的一个实施例的说明图,其描绘在校正权重之间的训练偏差的均匀分布。
图11为在图2所示的p网络的一个实施例的说明图,其运用在p网络训练期间的校正权重的修改。
图12为在图2所示的p网络的一个实施例的说明图,其中基本算法为产生一个主要组的输出神经元总和,且其中该产生组为使用以产生具有保留或增大值的数个“获胜者”总和且其余的总和的贡献为无效。
图13为在图2所示的p网络的一个实施例的说明图,其辨识具有多个图像的元素的一个复杂图像。
图14为使用统一模型化语言(UML)的用于在图2所示的p网络的面向对象程序设计的一个模型的说明图。
图15为在图2所示的p网络的一个概括形成顺序的说明图。
图16为用于在图2所示的p网络的形成的数据的代表性的分析与准备的说明图。
图17为允许在图2所示的p网络和输入数据在训练与p网络应用期间的互动的代表性的输入建立的说明图。
图18为用于在图2所示的p网络的神经元单元的代表性的建立的说明图。
图19为其和神经元单元连接的每个神经结的代表性的建立的说明图。
图20为训练在图2所示的p网络的说明图。
图21为在图2所示的p网络中的神经元单元训练的说明图。
图22为在图2所示的p网络的训练期间的神经元总和的延伸的说明图。
图23为一种用以训练在图2-22所示的神经网络的方法的流程图。
具体实施方式
如图1所示,一种传统的人工神经网络10典型包括:输入装置12、具有神经结权重16的神经结14、神经元18(其包括一个加法器20与致动函数装置22)、神经元输出24以及权重校正计算器26。每个神经元18通过神经结14而连接到二个或多个输入装置12。神经结权重16的值通常使用电阻、导电率、电压、电荷、磁性性质、或其他参数来代表。
传统的神经网络10的受监督的训练概括为基于一组训练配对28的应用。每个训练配对28通常由一个输入图像28-1与一个期望输出图像28-2(也称为一个监督信号)所组成。传统的神经网络10的训练典型地提供如下。以一组输入信号(I1-Im)的形式的一个输入图像进入所述输入装置12,且被转移到其具有初始权重(W1)的神经结权重16。输入信号的值是由所述权重所修改,典型为将每个信号(I1-Im)的值乘以或除以相应的权重。从所述神经结权重16,经修改的输入信号每个转移到相应的神经元18。每个神经元18接收来自关于该所属的神经元18的一群神经结14的一组信号。包括在神经元18之中的加法器20将由所述权重所修改且由该所属的神经元所接收的所有输入信号总计。致动函数装置22接收相应的合成神经元总和,且根据数学函数而修改该总和,因此形成相应的输出图像为如同成组的神经元输出信号(∑F1…∑Fn)。
由神经元输出信号(∑F1…∑Fn)所界定的得到的神经元输出图像和预定的期望输出图像(O1-On),由一个权重校正计算器26来比较。基于在所得到的神经元输出图像∑Fn与期望输出图像On之间的预定差异,用于改变所述神经结权重16的校正信号使用一个预定程序设计的算法所形成。在校正对于所有神经结权重16而进行之后,该组输入信号(I1-Im)再次引入到神经网络10且进行新的校正。上述的循环重复而直到在所得到的神经元输出图像∑Fn与期望输出图像On之间的差异确定为小于某个预定误差。关于所有的个别图像的网络训练的一个循环为典型识别为一个“训练时期”。概括而言,借着每个训练时期,误差的大小降低。然而,视个别输入信号(I1-Im)的数目、以及输入与输出的数目而定,传统的神经网络10的训练可能需要可观数目的训练时期,其在一些情形可能为如同几十万个之大。
存在各种传统的神经网络,其包括:何普菲(Hopfield)网络、限制波兹曼机器(Restricted Boltzmann Machine)、径向基底函数网络、与递归神经网络。分类及聚类的特定任务需要一个特定类型的神经网络,自我组织映像(Self-Organizing Map)仅使用输入图像来作为网络输入训练信息,而对应于某个输入图像的期望输出图像基于具有最大值的一个输出信号的单个获胜(winning)的神经元而在训练过程期间被直接形成。
如上所指出,关于现存的传统神经网络(诸如:神经网络10)的主要关注的一个在于其成功的训练需要可观的时间持续期间。关于传统网络的一些另外关注可为计算资源的大量耗费,其将接着驱使对于强大电脑的需要。另外的关注在没有该网络的完全重新调校的情况下而无法提高该网络的大小,对于如同“网络瘫痪”与“冻结在局部最小量”的该种现象的一个倾向,其使得不可能预测一个特定神经网络是否将能够用一个指定顺序的一个指定组的图像来训练。此外,可能存在关于在训练期间所引入的图像的特定顺序的限制,其中,改变训练图像的引入的顺序可能导致网络冻结,以及无法实行一个已经训练的网络的附加的训练。
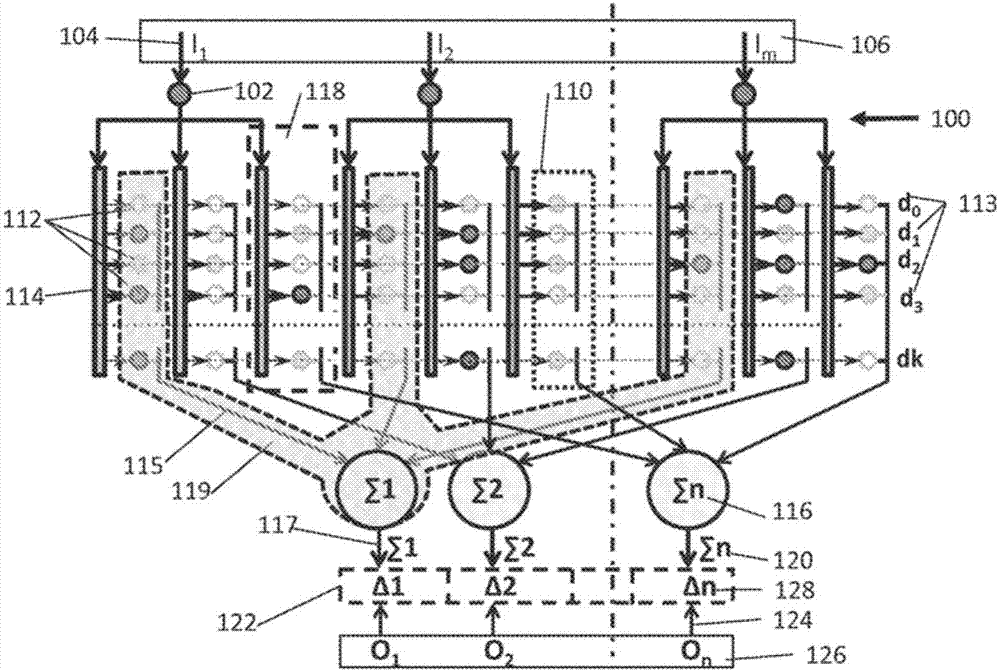
参考其余附图,其中,同样的附图标记表示同样的构件,图2显示此后称为“渐进式网络(progressive network)”或“p网络(p-net)”100的一种渐进式神经网络的示意图。p网络100包括该p网络的多个或一组输入102。每个输入102被配置成接收一个输入信号104,其中所述输入信号在图2被表示为I1,I2…Im。每个输入信号I1,I2…Im代表一个输入图像106的一些特征的一个值,例如:大小、频率、相位、信号极化角度、或和输入图像106的不同部分的关联性。每个输入信号104具有一个输入值,其中该多个输入信号104共同概括描述该输入图像106。
每个输入值可在其置于-∞与+∞之间的一个值范围内且可被设定为数字和/或模拟形式。输入值的范围可取决于一组训练图像。在最简单的情形中,输入值的范围可为在用于所有训练图像的输入信号的最小与最大值之间的差异。为了实际理由,输入值的范围可通过排除其被视为过高的输入值而受限制。举例来说,输入值的范围的该种限制可经由用于变异数缩减的已知统计方法而实现,诸如:重要性取样。限制输入值的范围的另一个示例可为其低于一个预定最小电平的所有信号的指定到一个特定最小值以及其超过一个预定最大电平的所有信号的指定到一个特定最大值。
该p网络100还包括多个或一组神经结118。每个神经结118被连接到多个输入102的一个,包括多个校正权重112,且还可包括一个神经结权重108,如在图2所示。每个校正权重112由一个相应的权重值112所界定。该p网络100还包括一组分配器114。每个分配器114被配置连接到多个输入102的一个以供接收相应的输入信号104。此外,每个分配器114被配置成从和输入值相关的多个校正权重112来选择一个或多个校正权重。
该p网络100另外包括一组神经元116。每个神经元116具有至少一个输出117,且经由一个神经结118而和多个输入102的至少一个连接。每个神经元116被配置成将选择自被连接到相应的神经元116的每个神经结118的所述校正权重112的权重值合计或总计,且由此产生一个神经元总和120,或者被标示为∑n。一个单独的分配器114可使用于一个指定输入102的每个神经结118,如在图3A、3B及3C所示,或单个分配器可使用于所有的所述神经结118,如在图4A、4B及4C所示。在p网络100的形成或设置期间,所有的校正权重112指定的初始值可在p网络的训练过程期间而改变。校正权重112的初始值可如同在传统的神经网络10之中而被指定,举例来说,所述权重可随机选择、在一个预定数学函数的帮助下所计算、从一个预定样板所选择、等等。
该p网络100还包括一个权重校正计算器122。权重校正计算器122被配置成接收其具有一个信号值且代表一个输出图像126的一部分的个期望(即:预定)输出信号124。权重校正计算器122被配置成确定神经元总和120与期望输出信号124的值的一个偏差128,也称:训练误差,且使用该确定的偏差128来修改相应的校正权重值。之后,将修改的校正权重值总计,以确定该神经元总和120使该所属的神经元总和与期望输出信号124的值的偏差为最小化,且结果为有效以供训练该p网络100。
为了类比关于图1所论述的传统的网络10,偏差128也可被描述为在所确定的神经元总和120与期望输出信号124的值之间的训练误差。相比于关于图1所论述的传统的神经网络10,在p网络100之中,输入信号104的输入值仅在一般网络设置的过程中改变,且在该p网络的训练期间为未改变。并非改变该输入值,p网络100的训练通过改变校正权重112的值112所提供。此外,虽然每个神经元116包括一个总计的功能,其中该神经元将所述校正权重值合计,但是神经元116不需要一个致动函数,且实际上其特征为没有一个致动函数,诸如:由传统的神经网络10之中的致动函数装置22所提供。
在传统的神经网络10之中,在训练期间的权重校正通过改变神经结权重16来实现,而在p网络100之中,对应的权重校正通过改变校正权重值112所提供,如在图2所示。相应的校正权重112可被包括在其经定位在所有或一些神经结118之上的权重校正方块110。在神经网络电脑仿真中,每个神经结权重与校正权重可由一个数字装置(诸如:一个内存单元)和/或由一个模拟装置所代表。在神经网络软件模拟中,校正权重112的值可经由一个适当程序设计的算法所提供,而在硬件仿真中,用于内存控制的已知的方法可使用。
在p网络100之中,神经元总和120与期望输出信号124的偏差128可表示为在其间的一个数学计算差异。此外,相应修改的校正权重112的产生可包括该计算的差异的分担到用以产生神经元总和120的每个校正权重。在该种实施例中,相应修改的校正权重112的产生将允许神经元总和120在很少个时期之内而被收敛在期望输出信号值,在一些情形仅需要单个时期,用以快速训练p网络100。在一个特定情形,该数学差异的分担在用以产生神经元总和120的所述校正权重112之间可包括将该确定的差异平均划分在用以产生相应的神经元总和120的每个校正权重之间。
在一个不同的实施例中,神经元总和120与期望输出信号值的偏差128的确定可包括该期望输出信号值除以神经元总和,由此产生一个偏差系数。在该种特定情形,相应修改的校正权重112的修改包括用以产生神经元总和120的每个校正权重乘以该偏差系数。每个分配器114可另外配置成将多个影响系数134指定到该多个校正权重112。在本实施例中,每个影响系数134可为以某个预定比例而指定到该多个校正权重112的一个,以产生相应的神经元总和120。为了对应于每个相应的校正权重112,每个影响系数134可被指定一个“Сi,d,n”命名,如在附图所示。
对应于特定神经结118的该多个影响系数134的每个由一个相应的影响分布函数136所界定。影响分布函数136可对于所有影响系数134或仅对于其对应于一个特定神经结118的多个影响系数134而相同。多个输入值的每个可被接收到一个值范围138,其根据一个区间分布函数140而划分为区间或子划分“d”,从而使每个输入值被接收在一个相应的区间“d”之内且每个校正权重对应于所述区间的一个。每个分配器114可使用相应接收的输入值以选择相应的区间“d”,且将所述相应的多个影响系数134指定到其对应于所选择的相应区间“d”的校正权重112并且到其对应于邻近于所选择的相应区间的一个区间的至少一个校正权重,诸如:Wi,d+1,n或Wi,d-1,n。在另一个非限制的示例中,所述影响系数134的预定的比例可根据一种统计分布而界定。
产生神经元总和120可包括根据输入值102而初始将相应的影响系数134指定到每个校正权重112,且接着将该所属的影响系数乘以相应运用的校正权重112的值。接着,经由每个神经元116,将对于连接到其的所有神经结118的该校正权重112与经指定的影响系数134的个别乘积总计。
权重校正计算器122可被配置成应用相应的影响系数134来产生相应的修改后的校正权重112。明确而言,权重校正计算器122可根据由相应的影响系数134所建立的比例而将在神经元总和120与期望输出信号124之间的计算数学差异的一部分应用到用以产生该神经元总和120的每个校正权重112。此外,在用以产生该神经元总和120的所述校正权重112之间所划分的数学差异可进一步除以相应的影响系数134。随后,神经元总和120除以相应的影响系数134的结果可相加到校正权重112以使神经元总和120收敛在期望输出信号值上。
典型而言,p网络100的形成是在p网络的训练开始之前而发生的。然而,在一个不同的实施例中,若在训练期间,p网络100接收对于其的初始校正权重为不存在的一个输入信号104,则适当的校正权重112可产生。在该种情形,特定的分配器114将确定用于特定输入信号104的适当区间“d”,且一群具有初始值的校正权重112将针对于指定输入102、指定区间“d”、与所有相应的神经元116而产生。此外,对应的影响系数134可被指定到每个新产生的校正权重112。
每个校正权重112可由一组索引所界定,该组索引设定成识别每个相应的校正权重在p网络100之上的一个位置。该组索引可明确包括:一个输入索引“i”,其被设定成识别对应于特定的输入102的校正权重112;一个区间索引“d”,其被设定成指定用于相应校正权重的上述的选择区间;以及一个神经元索引“n”,其被设定成用命名“Wi,d,n”来指定对应于特定的神经元116的校正权重112。因此,对应于一个特定输入102的每个校正权重112被指定该特定索引“i”于下标符号以指出该所属位置。同理,对应于一个特定神经元116与一个相应神经结118的每个校正权重“W”被指定该特定索引“n”与“d”于下标符号,以指出在p网络100之上的该校正权重的所属位置。该组索引还可包括:一个存取索引“a”,其被设定成结算该相应校正权重112在p网络100的训练期间而由输入信号104所存取的次数。换言之,每当一个特定区间“d”与相应的校正权重112从和该输入值相关的多个校正权重而被选择用于训练,存取索引“a”被增量以计数该输入信号。存取索引“a”可被使用以通过采用一个命名“Wi,d,n,a”来进而指定或界定每个校正权重的目前状态。索引“i”、“d”、“n”、与“a”的每个可为在0到+∞的范围中的数值。
将输入信号104的范围划分为区间d0,d1…dm的各种可能性显示在图5中。特定区间分布可为均匀或线性,举例来说,其可通过指定所有的区间“d”为具有相同大小而实现。具有低于一个预定最低电平的其相应输入信号值的所有输入信号104可视为具有零值,而具有大于一个预定最高电平的其相应输入信号值的所有输入信号104可指定到该最高电平,如也在图5所示。特定区间分布也可为非均匀或非线性,诸如:对称、不对称、或无限。当所述输入信号104的范围被视为不切实际地大时,区间“d”的非线性分布可为有用,且该范围的某个部分可包括被视为最关键的输入信号,诸如:在该范围的开端、中间、或末端。该特定区间分布也可由一个随机函数所描述。所有前述的示例是非限制性的,因为区间分布的其他变型也是可能的。
在输入信号104的选择范围内的区间“d”的数目可增加,以使p网络100优化。该p网络100的优化可例如通过在训练输入图像106的复杂度的提高而是期望的。举例来说,相比于单色的图像,对于多色的图像而言,可能需要较大数目个区间,且比起对于简单图像,对于复杂装饰而言,可能需要较大数目个区间。相比于由轮廓所描述的图像,对于其具有复杂的色彩渐层的图像的精确辨识而言,可能需要增大数目个区间,如同对于较大的整体数目个训练图像。假使有高量的噪声、在训练图像的高的变动、以及计算资源的过量消耗,也可能需要区间“d”的数目的降低。
视p网络100所处置的信息的任务或类型而定,例如:视觉或文字数据、来自各种性质的传感器的数据,不同数目个区间与其分布的类型可被指定。对于每个输入信号值的区间“d”,具有索引“d”的指定神经结的对应校正权重可被指定。因此,某个区间“d”将包括其具有关于指定输入的索引“i”、关于指定区间的索引“d”的所有校正权重112;以及对于从0到n的索引“n”的所有值。在训练p网络100的过程中,分配器114界定每个输入信号值,且因此使该所属的输入信号104为关于对应区间“d”。举例来说,若在从0到100的输入信号的范围内有10个相等区间“d”,则具有在30与40之间的一个值的输入信号相关于区间3,即:“d”=3。
对于其和指定输入102为连接的每个神经结118的所有校正权重112,分配器114可根据其关于特定输入信号的区间“d”而指定该影响系数134的值。分配器114也可根据影响系数134的值的一个预定分布(在图6所示)、(诸如:正弦波、正常态、对数分布曲线、或一个随机分布函数)而指定该影响系数134的值。在许多情形,对于关于每个神经结118的一个特定输入信号102的影响系数134或Сi,d,n的总和或积分将具有1(一)的一个值。
∑SynapseСi,d,n=1或∫SynapseСi,d,n=1[1]
在最简单的情形中,最接近对应于输入信号值的校正权重112可指定1(一)的一个值到影响系数134(Сi,d,n),而对于其他区间的校正权重可接收0(零)的一个值。
相比于传统的神经网络10,p网络100针对于在p网络的训练期间的持续时间降低与其他资源使用。虽然在本文所公开作为p网络100的部分的一些组件是由对于熟悉传统神经网络者为已知的某些名称或识别符号来命名,特定的名称为了简化而使用且可能不同于其在传统神经网络的对应者而运用。举例来说,控制输入信号(I1-Im)的大小的神经结权重16在传统的神经网络10的概括设置过程期间而制定且在该传统网络的训练期间而改变。在另一方面,p网络100的训练通过改变校正权重112而实现,而神经结权重108在训练期间不变。此外,如上文所论述的,神经元116的每个包括一个总计或相加构件,而不包括其对于传统神经网络10典型的一个致动函数装置22。
概括而言,p网络100通过训练每个神经元单元119来训练,每个神经元单元119包括一个相应的神经元116与所有连接的神经结118,包括该特定神经元与其和该所属的神经元连接的所有相应的神经结118与校正权重112。因此,p网络100的训练包括改变其贡献到相应的神经元116的校正权重112。对于校正权重112的改变是基于其包括在下文详细揭示的一种方法200的一个群组训练算法而进行的。在所公开的算法中,训练误差(即:偏差128)对于每个神经元而确定,基于哪些校正值来确定且指定到其在确定由每个相应的神经元116所得到的总和而使用的权重112的每个。在训练期间的所述校正值的引入旨在将对于该所属的神经元116的偏差128降低到零。在具有额外的图像的训练期间,关于稍早利用的图像的新的误差可能再次发生。为了消除所述额外的误差,在一个训练时期的完成后,对于整个p网络100的所有训练图像的误差是可计算的,且若所述误差大于预定值,则一个或多个额外的训练时期可进行而直到所述误差成为小于一个目标或预定值。
图23描绘了训练关于图2-22的如上所述的p网络100的方法200。方法200开始于方框202,其中,该种方法包括:经由输入102,接收其具有输入值的输入信号104。接在方框202之后,该种方法前进到方框204。在方框204,该种方法包括:将输入信号104传递到其被运行连接到输入102的分配器114。在方框202或方框204,该种方法可包括:由该组索引来界定每个校正权重112。如以上关于p网络100的结构所述的,该组索引可包括:输入索引“i”,其被设定成识别对应于该输入102的校正权重112。该组索引还可包括:区间索引“d”,其被设定成指定用于相应校正权重112的选择区间;以及神经元索引“n”,其被设定成指定对应于特定神经元116的校正权重112为“Wi,d,n”。该组索引可另外包括:存取索引“a”,其被设定成结算该相应校正权重112在该p网络100的训练期间而由输入信号104所存取的次数。因此,每个校正权重的目前状态可采用命名“Wi,d,n,a”。
在方框204之后,该种方法继续进行到方框206,其中,该种方法包括:经由分配器114,从其定位在连接到该所属的输入102的神经结118之上的和该输入值为相关多个校正权重来选择一个或多个校正权重112。如上所述,每个校正权重112是由其相应的权重值所界定。在方框206,该种方法可另外包括:经由分配器114,将多个影响系数134指定到该多个校正权重112。在方框206,该种方法还可包括:以一个预定比例而将每个影响系数134指定到该多个校正权重112的一个以产生神经元总和120。此外,在方框206,该种方法可包括:经由神经元116,将对于经连接到其的所有神经结118的校正权重112与指定的影响系数134的一个乘积合计。此外,在方框206,该种方法可包括:经由权重校正计算器122,根据由相应的影响系数134所建立的比例而将该确定的差异的一部分施加到用以产生该神经元总和120的每个校正权重112。
如以上关于p网络100的结构所述的,多个影响系数134可由一个影响分布函数136来界定。在该种情形中,该种方法可另外包括:将该输入值接收到值范围138,其根据一个区间分布函数140而被划分为区间“d”,从而使该输入值被接收在一个相应区间内,且每个校正权重112对应于所述区间的一个。此外,该种方法可包括:经由分配器114,使用该接收的输入值以选择该相应的区间“d”且将该多个影响系数134指定到其对应于该选择相应的区间“d”的校正权重112且到其对应于邻近于该选择相应的区间“d”的一个区间的至少一个校正权重。如以上关于p网络100的结构所述的,对应于邻近于该选择相应的区间“d”的一个区间的校正权重112可识别为例如Wi,d+1,n或Wi,d-1,n。
接在方框206之后,该种方法前进到方框208。在方框208,该种方法包括:将经由神经结118而和输入102所连接的特定神经元116所选择的校正权重112的所述权重值合计,以产生该神经元总和120。如以上关于p网络100的结构所述的,每个神经元116包括至少一个输出117。在方框208之后,该种方法继续进行到方框210,其中,该种方法包括:经由权重校正计算器122,接收其具有该信号值的期望输出信号124。接在方框210之后,该种方法前进到方框212,其中,该种方法包括:经由权重校正计算器122,确定该神经元总和120与期望输出信号124的值的偏差128。
如以上在p网络100的说明所公开的,该神经元总和120与该期望输出信号值的偏差128的确定可包括:确定在其间的数学差异。此外,相应的校正权重112的修改可包括:将该数学差异分摊到用以产生该神经元总和120的每个校正权重。替代而言,该数学差异的分摊可包括:将该确定的差异平均划分在用以产生该神经元总和120的每个校正权重112之间。在还有一个不同的实施例中,偏差128的确定还可包括:将该期望输出信号124的值除以该神经元总和120,由此产生该偏差系数。此外,在该种情形,所述相应的校正权重112的修改可包括:将用以产生该神经元总和120的每个校正权重112乘以该产生的偏差系数。
在方框212之后,该种方法继续进行到方框214。在方框214,该种方法包括:经由权重校正计算器122,使用该确定的偏差128来修改相应的校正权重值。经修改的校正权重值可随后被合计或总计且接着被使用以确定一个新的神经元总和120。该总计的修改校正权重值可接着作用以使得神经元总和120与该期望输出信号124的值的偏差为最小化,且因此训练p网络100。接在方框214之后,方法200可包括:返回到方框202以实行附加的训练时期,直到神经元总和120与该期望输出信号124的值的偏差为充分最小。换言之,附加的训练时期可实行以使神经元总和120收敛在期望输出信号124之上而为在预定偏差或误差值之内,从而使该p网络100可视为经训练且准备以供新的图像的操作。
概括而言,所述输入图像106必须作准备以供p网络100的训练。用于训练的p网络100的准备概括开始为一组的训练图像的形成,包括所述输入图像106以及(在大多个情形中)对应于所属的输入图像的期望输出图像126。用于p网络100的训练而由输入信号I1,I2…Im所界定的输入图像106(在图2所示)根据该p网络被指定以处置的任务所选择,例如:人类图像或其他物体的辨识、某些活动的辨识、聚类或数据分类、统计数据的分析、模式识别、预测、或控制某些处理。是以,输入图像106可用其适用于引入到电脑的任何格式来呈现,例如:使用格式jpeg、gif、pptx,用表格、图表、曲线图与图形、种种文件格式、或一组符号的形式。
用于p网络100的训练的准备还可包括:所述选择的输入图像106针对于其统一的转换,其为便于该所属图像由p网络100的处理,举例来说,将所有图像转变为其具有相同数目个信号、或在图像的情形中为相同数目个像素的一种格式。彩色图像可例如呈现为三原色的组合。图像转换还可包括特征的修改,例如:将一个图像在空间移位、改变该图像的视觉特征(诸如:分辨率、亮度、对比、色彩、视角、透视、焦距与焦点)、以及增加符号、标号、或注记。
在该区间数目的选择之后,一个特定输入图像可被转换为以区间格式的一个输入图像,即:实际信号值可被记录为该所属的相应的信号所属于的区间的数目。此程序可实施在用于指定的图像的每个训练时期。然而,该图像也可一次形成为一组的区间数目。举例来说,在图7,初始图像呈现为一个图像,而在表格“用数字格式的图像”之中,相同的图像用数字码的形式来呈现,且在表格“用区间格式的图像”之中,该图像呈现为一组的区间数目,一个单独的区间指定用于各10个值的数字码。
该p网络100的上述结构以及如所描述的训练算法或方法200允许该p网络的持续或反复的训练,因此在训练过程的开始不需要形成一个完整组的训练输入图像106。可能形成一个相当小的起始组的训练图像,且该起始组可随着必要而扩展。输入图像106可划分为独特的类别,例如:一组某人的图像、一组猫的照片、或一组汽车的照片,从而使每个类别对应于单个输出图像、该人的名称或一个特定的标签。期望输出图像126代表数字(其中每个点对应于从-∞到+∞的一个特定数值)或模拟值的一个字段或表格。期望输出图像126的每个点可对应于p网络100的所述神经元的一个的输出。期望输出图像126可用图像、表格、文字、公式、符号集(诸如:条形码)、或声音的数字或模拟的码来编码。
在最简单的情形中,每个输入图像106可对应于一个输出图像,其编码该所属的输入图像。该输出图像的点的一个可被指定一个最大可能值,例如:100%,而所有的其他点可被指定一个最小可能值,例如:零。在该种情形,接在训练之后,以其与训练图像的类似性的一个百分比的形式的各种图像的机率辨识将为致能。图8显示其训练用于二个图像(一个方形与一个圆形)的辨识的p网络100可如何辨识一个图像的一个示例,该图像含有一些特征,其每个图形以百分比来表示且总和不需等于100%。通过界定在用于训练的不同图像之间的类似性的百分比的该种模式识别过程可使用以分类特定的图像。
为了改善准确度且排除误差,编码可使用一组数个神经元输出而非为一个输出来实现(参阅下文)。在最简单的情形中,输出图像可在训练之前准备。然而,也可能具有由该p网络100在训练期间所形成的输出图像。
在p网络100之中,也有将输入与输出图像倒置的可能性。换言之,输入图像106可为数字或模拟的值的一个字段或表格的形式,其中每个点对应于p网络的一个输入,而输出图像可用其适用于引入到电脑的任何格式来呈现,例如:使用格式jpeg、gif、pptx,用表格、图表、曲线图与图形、各种文件格式、或一组符号的形式。造成的p网络100可相当适用于归档系统、以及图像、音乐术语、方程序、或数据组的关联的搜寻。
接在输入图像106的准备之后,典型而言,p网络100必须被形成且/或一个现存的p网络的参数必须被设定成供处置指定的任务。该p网络100的形成可包括以下的指定:
˙p网络100的规模,如由输入与输出的数目所界定的;
˙对于所有输入的神经结权重108;
˙校正权重112的数目;
˙对于输入信号104的不同值的校正权重影响系数(Ci,d,n)的分布;以及
˙训练的期望的准确度。
输入的数目基于输入图像106的尺寸而确定。举例来说,若干个像素可使用于图像,而输出的选择的数目可取决于期望输出图像126的尺寸。在一些情形中,输出的选择的数目可取决于训练图像的分类的数目。
个别的神经结权重108的值可在-∞到+∞的范围中。小于0(零)的神经结权重108的值可意指信号放大,其可被用以加强来自特定输入或来自特定图像的信号的影响,例如:用于在其含有大量不同个体或物体的相片中的人脸的更有效辨识。另一方面,大于0(零)的神经结权重108的值可使用以意指信号衰减,其可被用以降低所需计算的数目且提高该p网络100的操作速度。概括而言,神经结权重的值愈大,则传送到对应的神经元的信号衰减愈多。若其对应于所有输入的所有神经结权重108相等且所有神经元和所有输入为同样连接,该种神经网络将成为通用且将对于一般任务为最有效,诸如:当有关于图像的性质事先极少知道时。然而,该种结构将通常提高在训练与操作期间的所需计算的数目。
图9显示了p网络100的一个实施例,其中,在一个输入与相应的神经元之间的关系是根据统计常态分布而降低。神经结权重108的不平均的分布可造成整个输入信号被传递到对于指定输入的一个目标或“中央”神经元,因此将零的一个值指定到该所属的神经结权重。此外,神经结权重的不平均的分布可造成其他神经元接收降低的输入信号值,例如:使用正常态、对数-正常态、正弦波、或其他的分布。对于其接收降低的输入信号值的神经元116的神经结权重108的值可随着其相距该“中央”神经元的距离的增大而增大。在该种情形中,计算的数目可降低且该p网络的操作可加速。已知的完全连接与非完全连接的神经网络的一个组合的所述网络可对于具有强的内部模式的图像分析为非常有效,例如:人脸或电影影片的连续画面。
图9显示了p网络100的一个实施例,其对于局部模式的辨识是有效的。为了改善一般模式的识别,其中神经结权重108的值为小或零的10-20%的强连接可用一种确定性(诸如:以栅的形式)或随机的方式而分布在整个p网络100之中。意欲用于处置一个特定任务的该p网络100的实际形成使用例如用一种面向对象程序设计语言所撰写的一个程序而实行,其产生该p网络的主要组件,诸如:神经结、神经结权重、分配器、校正权重、神经元、等等,如同软件对象。该种程序可指定在经指出的对象与明确说明其动作的算法之间的关系。尤其,神经结与校正权重可在p网络100的形成的开始而形成,连同设定其初始值。p网络100可在其训练的开始前而完全形成,且如为必要时而在一个稍后的画面被修改或附加,举例而言,当该网络的信息容量成为耗尽或如果发生一个致命的失误时。p网络100的完成也可能在训练继续时。
若p网络100预先形成,在一个特定神经结上的选择校正权重的数目可等于在输入信号的范围内的区间的数目。此外,校正权重可在p网络100的形成后而产生,作为响应于个别的区间的出现的信号。类似于传统的神经网络10,该p网络100的参数与设定的选择提供有一系列的目标实验。所述实验可包括:(1)具有在所有输入的相同神经结权重108的p网络的形成,以及(2)对于选择图像的输入信号值的评估与区间数目的初始选择。举例来说,对于二元(单色)图像的辨识而言,具有仅有2个区间可能为充分;对于8位图的定性的辨识而言,高达256个区间可被使用;复杂的统计相依性的近似估算可能需要许多或甚至数百个区间;对于大的数据库而言,区间的数目可为数千个。
在训练p网络100的过程中,输入信号的值可舍入化整,由于其为分布在特定的区间之间。因此,大于该范围宽度除以区间数目的输入信号的准确度可能不需要。举例来说,若输入值范围设定用于100单位且区间数目为10,较±5为佳的准确度将不需要。所述实验还可包括:(3)在输入信号值的整个范围的区间的均匀分布的选择,且对于校正权重影响系数Ci,d,n的最简单的分布可对于其对应于用于特定输入信号的区间的校正权重而设定等于1,而对于所有其余的校正权重的校正权重影响可设定为0(零)。所述实验可另外包括:(4)用具有预定的准确度的一个、多个、或所有准备的训练图像来训练p网络100。
对于预定准确度的p网络100的训练时间可通过实验来建立。若p网络100的准确度与训练时间是令人满意的,选择的设定可维持或改变,而对于一个更为有效的变型的搜寻是持续的。若所需要的准确度未实现,则为了优化的目的,特定修改的影响可作评估,其可逐个或成群而被实行。该种修改的评估可包括:改变(提高或降低)区间的数目;改变校正权重影响系数(Сi,d,n)的分布的类型,测试其具有区间的不均匀分布的变型,诸如:使用正常态、幂次、对数、或对数-正常态分布;以及改变神经结权重108的值,例如:其转变到不均匀分布。
若针对于一个准确结果所需要的训练时间被视为过量,则具有增大的数目个区间的训练可评估对于其在训练时间上的效应。若结果为训练时间被降低,则在区间数目的提高可重复,直到期望的训练时间在没有损及需要的准确度的情况下而得到。若训练时间随着提高区间数目来增加而非为减少,则附加的训练可用减小的数目个区间来实行。若降低的数目个区间造成减少的训练时间,则区间数目可进而降低,直到期望的训练时间得到。
该p网络100的设定的形成可经由具有预定的训练时间的训练以及训练准确度的实验确定。参数可经由类似于上述者的实验改变而改善。关于多种p网络的实际的实行已经显示的是,设定选择的程序通常为直接而不耗时。
作为在图23所显示的方法200的部分者,p网络100的实际训练开始为将输入图像信号I1,I2…In馈送到网络输入装置102,从该处,所述信号被传送到神经结118,通过神经结权重108且进入该分配器(或一群的分配器)114。基于输入信号值,分配器114设定该指定的输入信号104对应于的区间“d”的数目,且指定对于其和相应的输入102为连接的所有神经结118的权重校正方块110的所有校正权重112的校正权重影响系数Сi,d,n。举例来说,若区间“d”可对于第一输入而设定为3,则对于所有权重W1,3,n,С1,3,n=1设定为1,而对于i≠1且d≠3的所有其他权重,Сi,d,n可设定为0(零)。
对于每个神经元116,在以下的关系式中被识别为“n”,神经元输出总和∑1,∑2…∑n通过将对于贡献到特定神经元的所有神经结118的每个校正权重112(在以下关系式中被识别为Wi,d,n)乘以一个对应的校正权重影响系数Сi,d,n且通过相加所有得到的值而形成:
∑n=∑i,d,nWi,d,n×Сi,d,n[2]
Wi,d,n×Сi,d,n的相乘可由种种的装置所实行,例如:通过分配器114、具有储存的权重的装置或直接通过神经元116。所述总和经由神经元输出117而转移到权重校正计算器122。描述该期望输出图像126的期望输出信号O1,O2…On也被馈送到计算器122。
如上所论述的,权重校正计算器122通过神经元输出总和∑1,∑2…∑n和期望输出信号O1,O2…On的比较而用于计算对于校正权重的修改值的个计算装置。图11显示其贡献到该神经元输出总和∑1的组校正权重Wi,d,1,其乘以对应的校正权重影响系数Сi,d,1,且这些乘积随后由该神经元输出总和∑1所相加:
∑1=W1,0,1×С1,0,1.+W1,1,1×С1,1,1.+W1,2,1×С1,2,1.+…[3]
随着训练开始,即:在第一时期期间,校正权重Wi,d,1不对应于用于训练的输入图像106,因此,神经元输出总和∑1不等于对应的期望输出图像126。基于初始的校正权重Wi,d,1,该种权重校正系统计算该校正值Δ1,其被使用以改变贡献于神经元输出总和∑1的所有的校正权重(Wi,d,1)。p网络100允许对于贡献于一个特定的神经元116的所有校正权重Wi,d,n的集体校正信号的其形成及利用的多种选或变型。
以下对于所述集体校正信号的形成及利用的二个示范而非限制的变型。变型1—基于期望输出信号与得到的输出总和之间的差异,校正信号的形成及利用如后:
˙对于贡献到神经元“n”的所有校正权重的相等校正值Δn的计算根据下式:
Δn=(On-∑n)/S[4],
其中:
On–对应于神经元输出总和∑n的期望输出信号;
S–经连接到神经元“n”的神经结的数目。
˙贡献到神经元“n”的所有校正权重Wi,d,n的修改根据下式:
Wi,d,n修改=Wi,d,n+Δn/Ci,d,n[5]
变型2—基于期望输出信号对得到的输出总和的比值,校正信号的形成及利用如下:
˙对于贡献到神经元“n”的所有校正权重的相等校正值Δn的计算根据下式:
Δn=On/∑n[6]
˙贡献到神经元“n”的所有校正权重Wi,d,n的修改根据下式:
Wi,d,n,修改=Wi,d,n,×Δn[7]
按照任何可利用的变型的校正权重Wi,d,n的修改意欲要通过将其输出总和∑n收敛在期望输出信号的值而降低对于每个神经元116的训练误差。以此方式,对于一个指定图像的训练误差可被降低而直到其成为等于或接近于零。
在训练期间的校正权重Wi,d,n的修改的一个示例显示于图11。校正权重Wi,d,n的值在训练开始之前而设定,以具有权重值被设定为从该校正权重范围的0±10%的随机权重分布的形式,且在训练之后而达到最终的分布。集体信号的所述的计算针对于在p网络100之中的所有神经元116而进行。对于一个训练图像的所述的训练程序可针对于其他训练图像而重复。该种程序可能导致对于一些先前训练图像的训练误差的出现,由于一些校正权重Wi,d,n可能参与在数个图像。是以,用另一个图像的训练可能部分扰乱其针对于先前图像所形成的校正权重Wi,d,n的分布。然而,归因于每个神经结118包括一组的校正权重Wi,d,n的事实,用可能提高训练误差的新图像的训练不删除该p网络100先前针对于其所训练的所述图像。甚者,愈多个神经结118贡献于每个神经元116且在每个神经结的校正权重Wi,d,n的数目为愈多,对于一个特定图像的训练影响对于其他图像的训练为愈少。
每个训练时期通常随着对于所有训练图像的总训练误差和/或局部训练误差的实质收敛而结束。误差可使用已知的统计方法来评估,诸如例如:均方误差(MSE,Mean Squared Error)、平均绝对误差(MAE,Mean Absolute Error)、或标准误差平均(SAE,Standard Error Mean)。若总误差或一些局部误差太高,附加的训练时期可进行而直到误差降低到小于一个预定误差值。借着界定在用于训练的不同图像(在图8所示)之间的类似性的百分比的稍早所述的图像辨识过程本身为沿着先前所界定的类别的图像的分类过程。
对于聚类(clustering),即:将图像划分为其先前并未指定的自然分类或群组,方法200的基本训练算法可用自组织映像(SOM,Self-Organizing Maps)方式来修改。对应于一个指定输入图像的期望输出图像126可直接在训练p网络100的过程中而形成,基于具有输出神经元总和120的最大值的一组的获胜神经元。图22显示了该种方法200的基本算法的使用可如何产生一个主要组的输出神经元总和,其中,该组进而被收敛以从而使数个较大的总和保留其值、或增大,而所有其他总和视为等于零。此转变组的输出神经元总和可被接受为期望输出图像126。
如上所述而形成,该组的期望输出图像126包括聚类或群组。如此,该组的期望输出图像126允许线性不可分离的图像的聚类,此为与传统的网络10有所不同。图13显示所述的方式可如何有助于聚类一个复合的假设图像“猫-汽车”,其中,该图像的不同特征指定到不同聚类-猫与汽车。如所描述而建立的一组的期望输出图像126可使用,例如:用于建立不同的分类、统计分析、图像选择,基于由于聚类所形成的准则。此外,由该p网络100所产生的期望输出图像126可使用作为其也可顺着对于所属的p网络100所述的方式而形成的另一个或附加的p网络的输入图像。因此所形成,期望输出图像126可用于一种多层p网络的一个后续层。
传统的神经网络10的训练概括为经由一种受监督的训练方法所提供,该种方法基于初步准备成对的一个输入图像与一个期望的输出图像。该种概括方法也使用于p网络100的训练,然而,p网络100的提高的训练速度也考虑到借着一个外部训练者的训练。外部训练者的任务可例如由个人或由一个电脑程序来实行。作用为一个外部训练者,该个人可涉及在实行一个实体任务或操作在一个游戏环境中。p网络100接收其形式为关于一个特定情况与对于其变化的数据的输入信号。反映该训练者动作的信号可被引入作为期望输出图像126且允许p网络100为根据基本算法而被训练。以此方式,各种处理的模型化可由p网络100所实时产生。
举例来说,p网络100可被训练以通过接收其有关于路况与驾驶者的动作的信息而驱动一台运载工具。通过模型化大量各种的关键情况,该同个p网络100可由多个不同的驾驶者所训练且累积相比于通常可能由单个驾驶者所为的更多的驾驶技能。p网络100能够在0.1秒内或更快速评估一个特定路况且积累实质的“驾驶经验”,其可加强在各种情况的交通安全。p网络100还可被训练以和一个电脑(例如:和下棋机器)合作。易于从训练模式转移到辨识模式(且反之亦然)的该p网络100的能力考虑到一种“从错误中学习”模式的实现,当p网络100是由一个外部的训练者来训练。在该种情形,部分训练的p网络100可产生其本身的动作,例如:用以控制一个技术过程。训练者可控制p网络100的动作且当必要时而修正彼等动作。因此,p网络100的附加的训练可提供。
该p网络100的信息容量极大,但是并非不受限制。由于该p网络100的设定尺度(诸如:输入、输出、与区间的数目),且由于用来训练该p网络的图像数目的增大,在某数目个图像之后,训练误差的数目与大小也可能增大。当该种在误差产生的增大被侦测时,误差的数目和/或大小可通过提高p网络100的尺寸而降低,由于p网络允许在训练时期之间而提高神经元116的数目和/或跨于p网络或在其构件中的信号区间“d”的数目。p网络100的扩展可通过增加新的神经元116、增加新的输入102与神经结118、改变校正权重影响数Ci,d,n的分布、以及划分现存的区间“d”而提供。
在大多数的情形中,p网络100将被训练以确保其能够辨识图像、模式、以及对于该图像或对于一组图像所固有的相关性。在最简单的情形中,辨识过程重复根据其公开为方法200的部分者的基本算法的训练过程的最初的步骤。尤其是:
˙直接辨识以图像的格式化而开始,根据其为使用来格式化图像以供训练的相同规则;
˙该图像被传送到受训练的p网络100的输入,分配器指定对应于其在训练期间所设定的输入信号值的校正权重Wi,d,n,且所述神经元产生相应的神经元总和,如在图8所示;
˙若代表输出图像126的造成的输出总和完全依从该p网络100被训练所用的图像的一个,则有该对象的确实的辨识;以及
˙若输出图像126部分依从该p网络100被训练所用的数个图像,则结果显示如同一个百分比的关于不同图像的匹配比率。图13展示的是,在其为基于一只猫与一台车辆的图像的组合所作成的复合图像的辨识期间,输出图像126代表指定的图像组合且指出其贡献到该组合的每个初始图像的百分比。
举例来说,若一个特定人士的数个图像被用于训练,则辨识的图像可能90%对应于第一个图像,60%对应于第二个图像,且35%对应于第三个图像。可能的是,辨识的图像具有某个机率而对应于其他人士或甚至是动物的图像,此意指在所述图像之间有一些相似性。然而,该种相似性的机率很可能为较低。基于所述机率,辨识的可靠度可确定,例如:基于贝氏定理(Bayes’theorem)。
通过p网络100,也可能实施多阶段的辨识,其结合算法与神经网络辨识方法的优点。该种多阶段的辨识可包括:
˙通过一个预先训练网络的一个图像的初始辨识,经由使用并非全部而是仅为1%-10%的输入,其在此被称为“基本输入”。该部分的输入可均匀、随机、或由任何其他分布函数而分布在p网络100之内。举例来说,在其包括多个其他对象的照片中的一个人士的辨识;以及
˙选择最提供有用信息的对象或对象部分以供更进一步的详细辨识。该种辨识可根据其预先设定在内存中的特定对象的结构而提供,如同在运算方法之中,或根据图像的色彩、亮度、和/或深度的一个梯度。举例来说,在肖像的辨识中,以下辨识区可作选择:眼睛、嘴角、鼻子形状、以及某些特定特征,诸如:刺青,车牌号码、或门牌号码也可使用类似方式来选择和辨识;以及
˙若必要时,选择的图像的详细辨识也是可能的。
该p网络100的一个电脑仿真的形成及其训练可通过使用任何程序设计语言而基于以上说明来提供。举例来说,一种面向对象程序设计可使用,其中,神经结权重108、校正权重112、分配器114、与神经元116代表程序设计对象或对象类别,关系是经由链接或信息而建立在对象类别之间,且互动的算法设定在对象之间以及在对象类别之间。
该p网络100的软件仿真的形成及训练可包括如下:
1.用于p网络100的形成及训练的准备,尤其是:
˙根据一个指定任务,成组的训练输入图像的转换成为数字形式;
˙造成的数字图像的分析,包括其要被使用于训练的输入信号的参数的选择,例如:频率、大小、相位、或坐标;及
˙设定用于训练信号的一个范围、在该所属范围之内的若干个区间、以及校正权重影响系数Ci,d,n的分布。
2.该p网络的软件仿真的形成,包括:
˙对于该p网络100的一组输入的形成。举例来说,输入的数目可等于在训练输入图像中的信号的数目;
˙一组神经元的形成,其中每个神经元代表一个相加装置;
˙一组其具有神经结权重的神经结的形成,其中每个神经结连接到一个p网络输入与一个神经元;
˙在每个神经结中的权重校正方块的形成,其中所述权重校正方块包括分配器与校正权重,且其中每个校正权重具有以下特征:
○校正权重输入索引(i);
○校正权重神经元索引(n);
○校正权重区间索引(d);及
○校正权重初始值(Wi,d,n)。
˙指定在区间与校正权重之间的一个相关性。
3.用一个输入图像来训练每个神经元,包括:
˙指定校正权重影响系数Ci,d,n,包括:
○确定其对应于由每个输入所接收的训练输入图像的输入信号的个区间;及
○指定对于所有神经结的所有校正权重的校正权重影响系数Ci,d,n的大小。
˙通过将其贡献于该神经元的所有神经结权重的校正权重值Wi,d,n乘以对应的校正权重影响系数Ci,d,n而后相加,计算对于每个神经元“n”的神经元输出总和(∑n):
∑n=∑i,d,nWi,d,n×Ci,d,n
˙经由该神经元输出总和∑n从对应的期望输出信号On的相减而计算该偏差或训练误差(Tn):
Tn=On-∑n
˙经由将训练误差除以其连接到神经元“n”的神经结的数目“S”而计算对于其贡献于神经元“n”的所有校正权重的相等校正值(Δn):
Δn=Tn/S
˙通过将该校正值Δn除以对应的校正权重影响系数Ci,d,n而后相加到每个校正权重,修改其贡献于相应的神经元的所有校正权重Wi,d,n:
Wi,d,n修改=Wi,n,d+Δn/Ci,d,n。
对于其贡献于神经元“n”的所有校正权重而计算该相等校正值(Δn)及修改所述校正权重Wi,d,n的另一种方法可包括下列者:
˙将该期望输出图像的信号On除以一个神经元输出总和∑n:
Δn=On/∑n
˙通过将所述校正权重乘以该校正值Δn,修改其贡献于该神经元的校正权重Wi,d,n:
Wi,d,n修改=Wi,d,n×Δn
4.使用所有的训练图像来训练该p网络100,包括:
˙对于其被包括在一个训练时期中的所有选择的训练图像而重复上述的过程;及
˙确定该特定训练时期的一个或多个误差,将彼等误差和一个预定可接受的误差电平相比较,且重复训练时期而直到所述训练误差成为小于该预定可接受的误差电平。
使用面向对象程序设计的p网络100的软件仿真的一个实际的示例描述在下文且显示在图14-21。
一个“神经元单元(Neuron Unit)”对象类别的形成可包括形成:
˙“神经结”类别的成组的对象;
˙神经元116提出一个变量,其中,相加实行在训练期间;及
˙计算器122提出一个变量,其中,期望神经元总和120的值被储存且校正值Δn的计算实行在训练过程期间。
类别“神经元单元”提供p网络100的训练且可包括:
˙神经元总和120的形成;
˙设定期望总和;
˙校正值Δn的计算;及
˙将计算的校正值Δn相加到校正权重Wi,n,d。
对象类别“神经结(Synapse)”的形成可包括:
˙成组的校正权重Wi,n,d;及
˙指出其连接到神经结118的输入的指标。
类别“神经结”可实行以下功能:
˙校正权重Wi,n,d的初始化;
˙将权重Wi,n,d乘以系数Ci,d,n;以及
˙权重Wi,n,d的校正。
对象类别“输入信号(Input Signal)”的形成可包括:
˙关于其连接到一个指定输入102的神经结118的成组的索引;
˙其包括输入信号104的值的变量;
˙可能的最小与最大输入信号的值;
˙区间的数目“d”;及
˙区间长度。
类别“输入信号”可提供以下功能:
˙该p网络100的结构的形成,其包括:
○在一个输入102与神经结118之间的连接的增加与移除;以及
○设定对于一个特定输入102的神经结118的区间的数目“d”。
˙设定最小与最大的输入信号104的参数;
˙贡献到该p网络100的操作:
○设定一个输入信号104;及
○设定校正权重影响系数Ci,d,n。
对象类别“p网络(PNet)”的形成包括一组的对象类别:
˙神经元单元;及
˙输入信号。
类别“p网络”提供以下功能:
˙设定“输入信号”类别的对象的数目;
˙设定“神经元单元”类别的对象的数目;及
˙对象“神经元单元”与“输入信号”的功能的群组请求。
在训练过程期间,所述循环可形成,其中:
˙等于零的神经元输出总和在该循环开始之前而形成;
˙贡献于指定“神经元单元”的所有神经结被检视。对于每个神经结118:
○基于输入信号104,分配器形成一组的校正权重影响系数Ci,d,n;
○该神经结118的所有权重Wi,n,d被检视,且对于每个权重:
■权重Wi,n,d的值乘以对应的校正权重影响系数Ci,d,n;
■该相乘结果相加到该形成神经元输出总和;
˙校正值Δn计算;
˙校正值Δn除以校正权重影响系数Ci,d,n,即,Δn/Ci,d,n;以及
˙贡献于指定“神经元单元”的所有神经结118被检视。对于每个神经结118,该所属的神经结的所有权重Wi,n,d被检视,且对于每个权重,其值被修改到对应的校正值Δn。
该p网络100的附加的训练的前述可能性允许训练与图像的辨识的结合,致使该训练过程能被加速且其准确度被改善。当通过一组依序改变的图像来训练p网络100,诸如:通过其彼此为稍微不同的影片的连续画面来训练,附加的训练可包括:
˙用第一图像来训练;
˙下个图像的辨识以及在新图像与该网络被初始训练所用的图像之间的类似性的百分比。若辨识误差小于其预定值,附加的训练不需要;及
˙若辨识误差超过预定值,附加的训练提供。
通过上述的基本训练算法的p网络100的训练有效用于解决图像辨识的问题,但未排除其归因于重叠图像的数据的损失或讹误。因此,p网络100的使用于内存目的虽然为可能,但可能非完全可靠。本实施例描述p网络100的训练,其提供对于信息的损失或讹误的防护。另一个限制可被引入到基本网络训练算法,其要求每个校正权重Wi,n,d可被训练仅为一次。在第一训练周期之后,权重Wi,n,d的值维持固定或定值。此可通过输入对于每个校正权重的另一个存取索引“a”而实现,存取索引“a”代表在训练过程期间而对该所属的校正权重Wi,n,d的存取数目的上述的索引。
如上所述,每个校正权重可采用Wi,n,d,a的命名,其中,“a”在训练过程期间而对该所属的权重的存取数目。在最简单的情形中,对于未修改(即:未固定)的权重,a=0,而对于其已经由描述的基本算法所修改或固定的权重,a=1。甚者,当应用基本算法,具有固定值a=1的校正权重Wi,n,d,a可被排除在校正为作成于其的权重之外。在该种情形,式[5]、[6]、与[7]可转变如下:
上述的限制可部分应用到先前训练的校正权重Wi,n,d,a的校正,但是仅为应用到其形成最重要的图像的所述权重。举例来说,在单个人士的一组肖像的训练内,一个特定图像可被宣告为主要者且指定优先等级。在该优先等级的图像的训练后,在训练过程之中为变化的所有校正权重Wi,n,d,a可被固定,即:其中该索引a=1,因此将该权重指定为Wi,n,d,1,且同个人士的其他图像可维持可改变。该优先等级可包括其他图像,例如:经使用作为加密密钥且/或含有关键的数值数据等。
对于校正权重Wi,n,d,a的变化也可能未完全禁止,但是受限于索引“a”的增大。即,权重Wi,n,d,a的每个后续使用可用以降低其变化的能力。一个特定的校正权重Wi,n,d,a愈经常被使用,随着每个存取的权重变化愈小,且因此在后续的图像的训练期间,储存的图像变化较小且遭受降低的讹误。举例来说,若a=0,在权重Wi,n,d,a的任何的变化可能;当a=1,对于该权重的变化的机率可减小到该权重值的±50%;随着a=2,变化的机率可降低到该权重值的±25%。
在达到预定数目个存取之后,如由索引“a”所表示,举例来说,当a=5,权重Wi,n,d,a的进一步的改变可能被禁止。该种方式可提供在单个p网络100之内的高智能与信息安全的结合。使用网络误差计算器构,可允许的误差的阶层可设定,从而使具有在一个预定准确度范围内的损失的信息可储存,其中该准确度范围根据一个特定任务而指定。换言之,针对于视觉图像来操作的p网络100,误差可设定在无法由肉眼所捕捉的阶层,其将提供在储存容量的显著“因子”的增大。上述者可致能视觉信息的高度有效储存的建立,例如:电影。
选择性清除电脑内存的能力可对于p网络100的持续的高阶运行而言为有用。该种内存的选择性清除可通过移除某些图像而未丧失或损坏其余的储存信息来作成。该种清除可提供如后:
˙参与在图像形成的所有校正权重Wi,n,d,a的识别,例如:通过将图像引入到该网络或通过编译用于每个图像的该系列的使用校正权重;
˙对于相应的校正权重Wi,n,d,a的索引“a”的降低;以及
˙当索引“a”降低到零,用零或用其接近对于该所属的权重的可能值的范围的中间的一个随机值来取代校正权重Wi,n,d,a。
索引“a”的一个适当等级与系列的缩减可根据实验选择以识别其隐藏在序列的图像之中的强的模式。举例来说,对于在训练期间所引入到p网络100的每100个图像,可有索引“a”的减小计数1,直到“a”达到零值。在该种情形,“a”的值可对应于新图像的引入而增大。在“a”的增大与减小之间的竞争可导致一个情况,其中随机变化逐渐从内存所移除,而其已经多次使用且确认的校正权重Wi,n,d,a可储存。当p网络100通过具有例如相同对象或类似环境的类似属性的大量图像而训练,经常使用的校正权重Wi,n,d,a不断确认其值且在这些区域中的信息成为非常稳定。此外,随机的噪声将逐渐消失。换言之,具有在索引“a”的逐渐减小的p网络100可作用为一种有效的噪声滤波器。
在没有信息丧失的情况下的p网络100的训练的已述实施例允许建立其具有高容量与可靠度的一种p网络内存。该种内存可使用作为大容量的一种高速电脑内存,其提供比“高速缓存”为更高的速度,但是将不会如同典型关于“高速缓存”系统所为者而提高电脑成本与复杂度。根据已公开的数据,概括而言,当用神经网络来录制电影时,内存可在没有录制质量的重大损失的情况下而压缩数十或数百倍。换言之,一种神经网络能够操作为一种极有效的存盘程序。将神经网络的此能力和该p网络100的高速训练能力结合可允许建立高速的数据传输系统、具有高储存容量的内存、以及高速的解密程序多媒体文件,即:代码变换器(codex)。
归因于事实在于,在p网络100之中,数据储存为一组的校正权重Wi,n,d,a,其为一个类型的码记录,经由现存的方法且在未使用一个同等网络与密钥的情况下的解碼或未授权存取到p网络不太可能。因此,p网络100可提供相当大程度的数据保护。此外,不同于公知的电脑内存,对于p网络100的个别储存组件的损坏呈现微不足道的有害效应,由于其他组件大为补偿丧失的功能。在图像辨识过程中,经使用的图像的固有模式实际为并未由于对于一个或多个组件的损坏而失真。上述者可显著改善电脑的可靠度且允许使用某些内存区块,其在正常情况下将被视为有缺陷。此外,此类型的内存归因于缺少对于在p网络100之中的关键字节的永久地址而较不容易受到黑客攻击,使得其不受到由各种电脑病毒对于该种系统的攻击的影响。
通过在用于训练的不同图像间的类似性百分比的确定的前述图像辨识过程也可运用作为根据先前界定类别的一种图像分类过程,如上所述。对于聚类,其图像的划分为非预先界定的自然分类或群组,基本的训练过程可修改。本实施例可包括:
˙用于训练的一组输入图像的准备,而不包括经准备的输出图像;
˙形成与训练该网络,借着神经元输出总和的形成,如同其根据基本算法所作成;
˙在具有最大输出总和的输出的造成输出图像的选择,即:获胜者输出、或一群的获胜者输出,其可为类似于Kohonen网络而组织;
˙一个期望输出图像的建立,其中,该获胜者输出或该群的获胜者输出接收最大值。同时:
○选择的获胜者输出的数目可预定,例如:在1到10的范围中,或获胜者输出可根据规则“不小于最大神经元总和的N%”而选择,其中,“N”可例如在90-100%之内;以及
○所有其他输出可设定为等于零。
˙根据基本算法的训练,借着使用建立的期望输出图像,图13;以及
˙针对其具有对于不同获胜者或获胜者群的每个图像的形成的其他图像,重复所有程序。
以上述方式所形成的该组的期望输出图像可使用以描述该多个输入图像可自然分开成为其的丛组或群组。该组的期望输出图像可使用以产生不同的分类,诸如:用于根据建立的准则且在统计分析中的图像的选择。上述也可使用于输入与输出图像的前述的倒转。换言之,期望输出图像可使用作为用于另一个(即:附加)网络的输入图像,且该附加网络的输出可为其适用于电脑输入的任何形式所呈现的图像。
在p网络100之中,在通过上述算法的训练的单个循环之后,期望输出图像可产生为有小的输出总和变化,此可能使训练过程减慢且还可能降低其准确度。为了改善p网络100的训练,点的初始变化可被人工提高或延伸,使得所述点的大小变化将涵盖可能输出值的整个范围,例如:-50到+50,如在图21所示。点的初始变化的该种延伸可能为线性或非线性。
一个情况可能发展,其中某个输出的最大值是一个离群值或错误,例如:噪声的一种表现形式。该情况可由其为许多个小信号所环绕的一个最大值的现象来显现。当获胜者输出被选择,小信号值可忽略,通过其为其他大信号所环绕的最大信号的选择作为获胜者。针对此目的,变异缩减的已知的统计技术可使用,诸如:重要性取样。该种方式可允许移除噪声而且维持基本有用的模式。获胜者群组的建立致能线性不可分离的图像(即:关于超过一个丛组的图像)的丛组,如在图13所示。以上可提供在准确度的重大改善且减小丛组误差的数目。
在p网络100的训练的过程中,受到校正的典型误差为:
误差校正也可能为借助于用一个外部训练者来训练的上述的算法。
此详细说明与所述附图支持及描述本公开内容,而本公开内容的范畴仅由权利要求所界定。尽管用于实施所主张的公开内容的一些最佳模式与其他实施例已经详细描述,各种替代设计与实施例存在以供实行在随附权利要求所界定的公开内容。此外,在所述附图所示的实施例或在本说明中所述的种种实施例的特征无须被理解为彼此独立的实施例。更确切而言,可能的是,在一个实施例的示例的一个所述的特征每个可和来自其他实施例的一个或多个其他期望特征作结合,造成其未用文字描述或关于所述附图的其他实施例。是以,所述其他实施例属于在随附权利要求的范畴的体系结构内。
- 还没有人留言评论。精彩留言会获得点赞!