行分割方法与流程
本发明涉及一种行分割方法,以及更具体地,涉及一种应用于OCR系统的行分割方法。
背景技术:
已经公知光学字符识别(OCR)系统。这些系统自动地将纸质文档转化为可搜索文本文档。OCR系统通常由以下三个主要步骤组成:行分割、特征提取以及字符分类。然而,如图1所示,特征提取通常呈现为字符分类的一部分。通过这种方式,从字符串的图像开始,公知的光学字符识别系统首先应用行分割以形成各个字符的图像,随后执行字符分类步骤以对字符进行识别。尽管字符分类技术经过这些年已经具有极强的鲁棒性,然而行分割仍然是OCR的关键步骤,尤其是对于亚洲文本而言。
存在不同的行分割方法(通常还被称为字符分割)。表示文本行的图像被分解成构成字符图像的各个子图像。可以使用不同方法来分割行。一种公知的行分割方法是对字符间断开(break)或单词断开(适合于拉丁字母)进行检测,这些字符断开或词断开是一种将各个字符分隔开的方式。例如,WO2011128777和WO201126755对此进行了描述。
另一公知行分割方法,如WO201142977所述,使用了砍断(chop)行,随后对砍断行进行处理以识别出将字符分开的行。诸如EP0138445B1中的其他方法假定字符间距恒定。
上述行分割方法已知为解剖方法(dissection method)。这类方法对于由亚洲文本和与拉丁文本组合的亚洲文本组成的文本而言是低效的,因为这类文本中字符之间通常没有明确的断开或间距,并且亚洲字符并不是由单一互连成分组成,而是多数情况下由几个互连成分(例如,中文字符的字根(radicals))组成。
另一种类型的行分割方法基于对图像中与特定字母表中的类别相匹配的成分的识别。然而,这类方法需要较长的计算时间。
第三种类型的分割技术使用了前两种技术的组合并且公知为“过度分割”方法。如图2所示,使用了不同的解剖方法对图像进行了过度分割。通过相同或不同的字符分类方法对几个合理的分割解决方案进行分析,从而选出最佳分割解决方案。当分割变得困难时,例如对于亚洲字符的情况,需要对许多可能的分割解决方案进行评估,这会导致需要花费非常长的计算时间来分析所输入的字符串图像。
技术实现要素:
本发明的目的在于提供一种用于对字符串图像中的字符进行分割的方法,该方法提供了快速且精确的行分割。
根据本发明,使用一种用于对字符串图像中的字符进行分割的方法实现了这些目的,该方法示出了第一个独立权利要求的技术特征。根据本发明的用于对字符串图像中的字符进行分割的方法包括如下步骤:
a)对照背景,确定像素的第一起始点坐标;
b)根据最大字符宽度以及字符串图像的与最大字符宽度相对应的部分的特征来生成潜在字符宽度列表;
c)确定字符串图像的与第一起始点坐标和第一宽度相对应的第二部分;
d)对字符串图像的第二部分应用分类方法以提供针对第一宽度的错误可能性和候选字符;
e)将错误可能性与根据速度与准确性之间的折衷确定的第一阈值进行比较;以及
f)如果与第一宽度相对应的错误可能性小于阈值,则选择候选字符作为与第一宽度相对应的字符。
该方法的优点在于:行分割和字符分类是按逐个字符进行的组合过程。这在减少计算时间方面具有较大的优势,因为大大地减小了对字符串图像执行行分割和字符分类而需要的步骤数。结果是该方法提高了速度和准确性。
在根据本发明的其他实施例中,该方法还包括如下步骤:将错误可能性与第二阈值进行比较,第二阈值大于第一阈值,其中,仅仅当错误可能性小于第二阈值时,才执行将错误可能性与第一阈值进行比较的步骤。
第二阈值的优点在于其使得能够快速滤除那些没有机会给出肯定结果的候选项。
在根据本发明的另一实施例中,该方法还包括如下步骤:当与第一宽度相对应的错误可能性小于第二阈值时,计算下一字符的起始点,以及将所计算出的下一字符的起始点存储到存储器中。
在根据本发明的另一实施例中,该方法还包括如下步骤:当与第一宽度相对应的错误可能性小于第一阈值时,对数据库中所包括的字符统计值进行更新。
该数据库包括文本中的字符的最大尺寸和平均尺寸的信息以及参考字符的最大尺寸和平均尺寸的信息。在生成潜在字符宽度列表的过程中估计字符的宽度时使用这些值以便于提高该方法的速度和准确性。
在根据本发明的另一实施例中,潜在字符宽度列表是按照从最有可能到不太可能进行排序的,其中,最有可能宽度是包括最大数量的互连成分的最宽宽度,该最宽宽度不超过数据库中所存储的针对字符的估计最大宽度。
在根据本发明的另一实施例中,潜在字符宽度列表中的两个不太可能的宽度分别为平均全局宽度(average global width)和平均全局宽度的一半,其中,平均全局宽度为针对字符串图像中的第一字符而言字符串图像的高度,以及平均全局宽度是基于先前的平均全局宽度以及数据库中所存储的针对字符串图像中的后续字符串平均字符宽度来计算的。
上述方案的优点在于:平均全局宽度将识别出亚洲字符,而平均全局宽度的一半将识别出拉丁字符,因为亚洲字符的尺寸大约是拉丁字符的尺寸的两倍,因此该行分割方法可以通过这种方式应用于拉丁字符、亚洲字符以及上述两种的组合。
在根据本发明的另一实施例中,当与潜在字符宽度列表中的前一宽度相对应的错误可能性大于第二阈值时,方法还包括如下步骤:
a)确定字符串图像的与起始点坐标和列表中的下一宽度相对应的第二部分;
b)对字符串图像的第二部分应用分类方法以提供这个宽度的错误可能性和候选字符;
c)将错误可能性与数据库中所存储的阈值进行比较;
d)重复步骤a)、b)以及c),直到与该宽度相对应的错误可能性小于阈值为止,或者直到已经完成了对潜在字符宽度列表中所包括的所有宽度的处理为止;
e)当与宽度相对应的错误可能性小于第一阈值时,选择字符候选作为与宽度相对应的字符。
只要没有找到技术方案,那么将行分割与字符分类组合并且一个接着另一个执行,直到找到解决方案为止。这使得能够减小执行这样的方法所需要的步骤的数量并且还提高了方法的准确性。
在根据本发明的另一实施例中,字符串图像是竖直字符串图像,并且所有的宽度是高度。
亚洲字符可以按行书写,也可以按列书写。该方法当然不限定于行,而是可以通过将字符的宽度改变为高度来容易地适用于列,反之亦然。
在另一实施例中,该方法还包括如下步骤:在成功迭代时,使用平均全局宽度值对字符统计数据库进行更新。
在根据本发明的另一实施例中,生成潜在字符宽度列表的步骤是基于从数据库中获取的数据进行的,数据库包括:针对给定字号的参考字符、最大参考字符的宽度、参考字符的平均宽度以及参考字符之间的平均距离的尺寸。
在本发明的另一实施例中,数据库还包括字符的统计值的估值,其中,数据库是在每个成功迭代时被更新的。
在根据本发明的另一实施例中,最大字符宽度是亚洲字符的最大字符宽度。
在本发明的另一实施例中,计算机程序产品包括计算机可用介质,计算机可用介质中存储有控制逻辑,控制逻辑用于使得计算装置对输入图像中的字符串图像进行分割,所控制逻辑包括:
a)第一控制可读程序代码模块,用于对照背景,确定像素的第一起始点坐标;
b)第二控制可读程序代码模块,用于根据最大字符宽度以及字符串图像的与最大字符宽度相对应的部分的特征来生成潜在字符宽度列表;
c)第三控制可读程序代码模块,用于确定字符串图像中的与第一起始点坐标和潜在字符宽度列表中的第一宽度相对应的第二部分;
d)第四控制可读程序代码模块,用于对字符串图像的第二部分应用分类方法以提供针对第一宽度的错误可能性和候选字符;
e)第五控制可读程序代码模块,用于将错误可能性与根据速度与准确性之间的折中(trade-off)确定的第一阈值进行比较;以及
f)第六控制可读程序代码模块,用于当与第一宽度相对应的错误可能性小于阈值时,选择候选字符作为与第一宽度相对应的字符。
附图说明
将借助于下面的描述和附图来进一步对本发明进行阐述。
图1示出了根据现有技术的光学字符识别过程中的不同步骤。
图2示出了本领域技术人员已知为过度分割的一种行分割。
图3示出了根据本发明的实施例的行分割方法。
图4示出了使用字符统计数据库的行分割方法。
具体实施方式
将针对特定实施例并参考某些附图对本发明进行描述,但本发明并非限定于此,而是仅由权利要求书进行限定。所描述的附图仅为示意性的而非限制性的。在附图中,出于示意性目的,一些要素的尺寸可能被扩大而没有按比例绘制。尺寸和相对尺寸不一定与实施本发明的实际缩小比例相对应。
此外,说明书和权利要求书中的术语“第一”、“第二”、“第三”等是用于区分相似元件,而不一定用于描述相继的或时间先后的顺序。这些术语在适当情况下可以互换,本文所描述的本发明的实施例可按照不同于这里所描述或示出的其它顺序操作。
此外,在说明书和权利要求中,术语“顶部”、“底部”、“之上”、“之下”等等用于说明的目的,并且不一定用于描述相对位置。所使用的这些术语在适当情况下可以互换,本文所描述的本发明的实施例可在不同于这里所描述或所示的其它方位操作。
另外,尽管这些被称之为“优选的”的各个实施例被理解为示例性方式,但是本发明可以通过这些示例性方式来实现而并非这些示例性方式用于限定本发明的范围。
权利要求书中所使用的术语“包括”将不被解释为对在其后列出的元件或步骤的限制;它并不排除其他元件或步骤。该术语应被解释为是强调所说明的特征、全局、步骤或部件的存在,而并未排除存在或添加一个或多个其它特征、全局、步骤或部件或其组群的可能性。因此,表达式“包括A和B的设备”的范围不应该限于仅包括部件A和B的设备。而是,就本发明而言,所枚举的设备的部件仅仅是A和B,此外,权利要求书应当解释为包括这些部件的等同物。
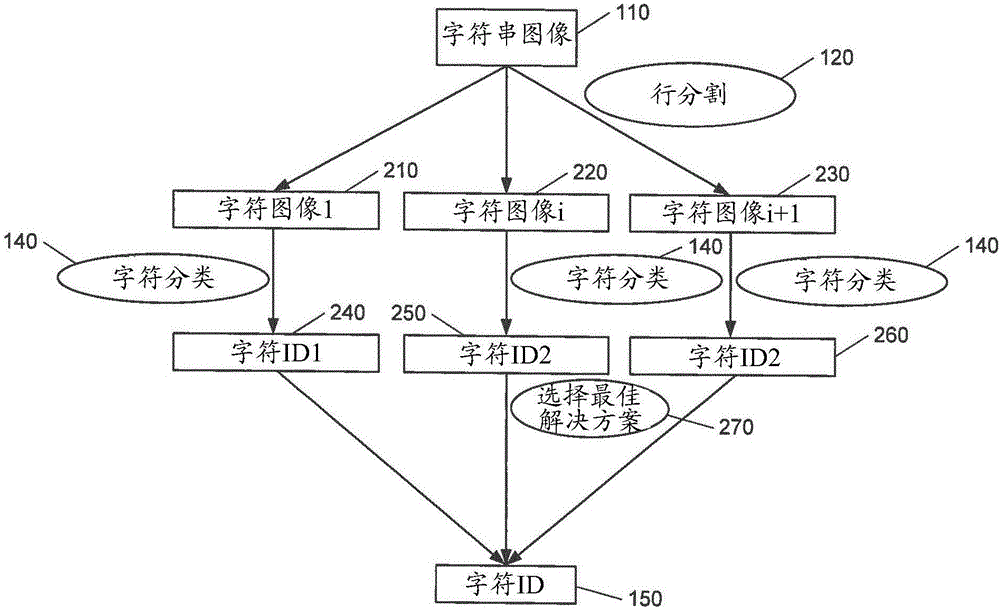
参考图3,图3示出了根据本发明的实施例的光学字符识别(OCR)方法的流程图。该方法的输入是字符串图像110。在第一步骤中,对字符串图像110进行行分割120。对所分析的字符的潜在宽度的初步信息进行计算。字符的潜在宽度的初步信息能够实现一个新的步骤序列,该步骤序列提高了OCR方法的速度。尽管仍然使用过度分割,但是不是所有的潜在解决方案(210,220,230)都需要通过OCR方法进行系统地分析。这些潜在解决方案是借助于候选字符宽度的列表310来生成的,并且按照从最有可能到不太可能进行排序。OCR方法首先对最有可能的潜在解决方案210进行分析。如果满足测量错误的条件320,则对该字符进行分类150,将其他潜在解决技术方案丢弃并且对下一字符进行分析。如果不满足测量错误的条件330,则对下一最有可能的潜在解决方案进行分析220。在如下情况下迭代地重复该过程:只要没有成功地对字符串进行分类或者直到已经完成对所有的潜在解决方案的评估为止。
这里所描述的方法被应用于对文本的行进行分割。然而,同样的方法还可以用于对文本的列进行分割,这对于亚洲文本而言很常见。
如上所述,按照最有可能出现到不太可能出现进行排序的候选字符宽度310的列表是在对字符图像进行分析之前生成的。这个候选字符宽度列表的生成将在本申请的后文中进行描述。该列表包括N+2个候选宽度,其中,前N个宽度是在字符串图像110中不需要进行切割以提取字符串的宽度,以及最后两个宽度是需要进行切割以将字符串图像110中的字符进行分开并提取的宽度。
起始点是x坐标,其用于限定要分析的新字符图像的位置。初始起始点列表是在算法的开始处进行创建的,其中,列表中的第一初始起始点与图像左边的第一个黑色像素相对应。其他预定义起始点与行的末端或最右侧像素相对应。在OCR过程期间,会将其他起始点添加至起始点列表。该方法确保会对列表中存在的所有起始点进行处理。
字符图像完全由起始点坐标和与互连成分的列表有关的宽度进行限定。对于所有字符串而言,行的高度是相同的。在OCR过程的结束处,字符被分类。
一旦创建了潜在解决方案,则将字符分类方法140应用于该潜在解决方案以确定该潜在解决方案是否可以对字符进行分类。在本发明的实施例中,字符串分类方法140是以Gabor函数为基础的。
根据本发明实施例的字符分类方法140需要两个输入:
-字符n的起始点坐标SPn。该起始点坐标是在待分析的字符中位于该字符的左下方处的第一个像素的(x)坐标;以及
-从针对字符n的候选字符宽度列表中选取的候选宽度wi。
输出为错误可能性Perr,该Perr用于计算字符Cn。错误可能性Perr与如下两个阈值参数进行比较:具有低错误可能性的阈值Tlerr和具有高错误可能性的阈值Therr。Tlerr和Therr的值可以根据速度vs准确性需求进行调整。在本发明的优选实施例中,Tlerr和Therr的值被设置为Tlerr=20%以及Therr=99%。具有低错误可能性的阈值Tlerr限定了字符被成功分类的条件。
根据本发明的实施例的行分割方法使用了如图4所示的字符统计数据库400。现在将列出数据库的元素。本申请后续将进一步对如何使用每个元素进行更详细地描述。该数据库包括:
-针对所选择的字号(point size),亚洲字符和拉丁字符的参考尺寸(高度和宽度)库,其存储在存储器中;
-针对所选择的字号,亚洲字符的参考最大尺寸w最大,A,r和拉丁字符的参考最大尺寸w最大,L,r,其存储在存储器中;
-针对所选择的字号,亚洲文本和拉丁文本所具有的相同的参考平均字符间距Sr;
-正被分析的文本中的亚洲字符的预计最大宽度w最大,A,t和拉丁字符的预计最大宽度w最大,L,t;
-正被分析的文本中的亚洲字符或拉丁字符的平均字符间距st;
-亚洲字符的宽度n的局部估值Ln,A和拉丁字符n的宽度的局部估值和Ln,L,该局部估值表示仅针对已经被分类的字符而计算出的相应的参考字符的宽度。这是使用字符n的实际宽度和值来计算出的字符的字号的测量值;
-字符的宽度的全局估值Gn,该全局估值表示仅针对已经被分类的字符而计算出的相应的参考字符的宽度。Gn的值是先前所测量的局部估值Ln的运行平均值(running average),并且从而是平均字符字号的更精确的测量值。这个值是更可靠的,因为其对于被错误地分类的字符而言具有较好的容错性。
参考图4,图4示出了根据本发明的实施例的行分割过程的流程图。该过程是针对对字符Cn的分割进行描述的。生成了针对字符Cn的具有所有N+2个候选字符宽度的列表310,并且从该候选字符宽度列表中选取第一候选字符宽度w1。这两个值SPn和w1为字符分类方法140在步骤420中的输入值410。步骤420的输出是错误可能性Perr。
根据Perr的值,可以有两种选项。如果错误可能性Perr小于具有高错误可能性的错误的阈值Therr421,则字符Cn是潜在解决方案。于是,如果需要,将与第一候选宽度w1相对应的字符Cn保存到存储器中,并且计算出下一字符的起始点并且将该起始点添加至待处理的起始点列表中,SPn+1=SPn+w1+SA,t,425。如果错误可能性Perr进一步还小于具有低错误可能性的错误的阈值Tlerr422,则可以认为字符Cn被成功地分类,并且如随后在说明书中进行说明的那样对字符统计数据库400进行更新。该方法可以移动至下一起始点SPn+1405以确定下一字符Cn+1,而无需针对当前起始点SPn的其他宽度进行处理。如果错误可能性Perr大于具有低错误可能性的错误的阈值Tlerr423,则如下文所描述的那样,使用接下来的第i个候选宽度wi来执行字符分类方法430。
然而,如果错误可能性Perr大于具有高错误可能性的错误的阈值Therr424,则不在存储器中保存与第1个候选宽度w1相对应的字符Cn,并且不对新的起始点进行计算。
使用接下来的第i个候选宽度wi来执行字符分类方法430。同样,根据Perr的值存在两种选项。如果Perr小于Therr431,则如果需要,将字符Cn与宽度wi一起存储,计算出下一字符的起始点并且将该起始点添加至待处理的起始点列表中405,以及,如果Perr还小于Tlerr432,则对字符统计数据库进行更新400。然而,如果Perr大于Tlerr和/或Therr(435,433),则使用接下来的第i+1个候选宽度wi+1来执行字符分类方法,直到已经完成对列表中的所有宽度的处理(i=N)为止,或者直到已经成功地对字符进行分类(Perr<Tlerr)为止。
对于i=N+1,重复同样的过程,但是现在宽度wN+1使得针对宽度值wN+1=w最大,A,t执行第一次切割440。如果对于i=N+1,使用低错误可能性(443或445)Perr<Tlerr,没有字符被分类,则针对i=N+2重复执行该过程,其中,wN+2=w最大,L,t450,同样地,可以有不同的路径,诸如,451采用452,451采用453或454。
为了不对过度分割的所有解决方案都进行分析,按照如下方式生成针对字符n的具有所有N+2个候选宽度{wi}的列表(cn):候选宽度按照从最有可能到不太可能进行排序,以及候选宽度的数量因字符而异,这取决于使用所连接的成分的数量进行测量的潜在字符的几何结构。基于观察认为,对于亚洲字符而言,除了少数字符具有较小的宽度,大多数字符的宽度相同。根据本发明的实施例,可能性最大的宽度对应于其包括连接成分的最大集合的宽度,其并不宽于较宽亚洲字符的估计宽度w最大,A,t与估计平均字符间距(st)之和。
字符可以是非粘连的或粘连的。非粘连字符出现的可能性更大,因此首先考虑非粘连字符。
对于非粘连字符,(不需要进行切割),像素中所计算出的具有指数i的候选宽度(wi)使得具有p个(p≥0)互连成分的集合的第i个最大宽度小于最大亚洲字符(w最大,A,t)与平均估计字符间距(st)的和。宽度wi具有p个互连成分,宽度wi+1具有p个或更少的互连成分并且使得wi+1≤wi。
在字符统计数据库中对最宽亚洲字符w最大,A,t和估计字符间距(st)进行评估。存在N个可能的非粘连字符。
如果两个相邻的字符粘连,则需要执行切割,将在最有可能的位置对字符进行切割,该最有可能的位置是根据字符的平均全局宽度Gn-1来计算的,该平均全局宽度Gn-1可以在对于字符Cn的先前迭代(n-1)处更新的字符统计数据库中找到。指数为N+1的宽度wN+1对应于亚洲字符的平均全局宽度Gn-1与平均间距st之和。指数为N+2的宽度wN+2对应于拉丁字符的平均全局宽度Gn-1/2与平均间距st之和。假定,拉丁字符的宽度为亚洲字符的宽度的一半。
总而言之,在每个迭代中,字符n的输入候选宽度列表是由以下条件给出:
wi=p个互连成分的第i个最大集合的宽度,使得wi=w最大+st,i=1,…,N;N≥0
wN+1=Gn-1+st,
wN+2=Gn-1/2+st
其中,w最大,A,t,Gn-1,st,st是来自字符统计数据库的值,该字符统计数据库在每次对字符进行了分类(或者Perr<Tlerr)时被更新。
数据库包括数据结构,该数据结构存储有按行提取的字符信息和参考字符以及这些字符的统计值的库。在过程的开始处,创建单个数据结构,该结构为空。存储在存储器中的数据结构在每个迭代中进行更新并且其结构类似于图形。
在下表中总结了数据库的所有参数,现在对数据库中的不同参数的估值进行说明。
表1:字符统计数据库的参数
按照如下方式对最大亚洲字符的宽度和最大拉丁字符的宽度进行评估:
其中,比例性比率表示将库中的字符的字号转换为文本中的字符的字号。
分别对亚洲字符的平均尺寸和拉丁字符的平均尺寸进行同样的转化:
这个值表示字符n的宽度的局部估值,并且进一步用于对步骤n处的字符的宽度的全局估值进行评估。使用如下等式计算步骤n处的字符的宽度的全局估值Gn:
G0=行的高度
其中,Gn-1是步骤n-1处所更新的字符的平均宽度的全局估值,Ln是步骤n处字符的平均尺寸的局部估值,n是方法的当前步骤的指数,以及G0是行的高度(假定亚洲字符是方形的)。这个等式对于亚洲字符和拉丁字符都是有效的。假定,对于拉丁字符而言,其宽度的全局估值是亚洲字符的全局估值的一半。
最后,当文本的字号不同于参考字符的字号时,应用同样的比例来对文本st中的字符间距进行评估:
本实施例示出了行分割方法的情况,但是该方法并不限定于行。亚洲文本还可以按列书写并且还可以使用同样的方法。在这种情况下,字符的宽度需要替代为字符的高度,以及起始点坐标是字符串图像的顶部处的字符的首个像素的(y)坐标。
- 还没有人留言评论。精彩留言会获得点赞!