用于控制数据中心中的服务器过高分配的机制的制作方法
本发明涉及一种用于管理数据中心的系统和方法以及一种合并过载管理功能的数据中心。
具体地说,本发明涉及一种用于管理在虚拟化数据中心中的资源过高分配的系统和方法,所述管理包括最佳过高分配比率的估计以及过载管理功能。
背景技术:
云数据中心为远程用户提供通过向数据中心提交计算工作以供数据中心计算来购买将使用的计算资源的可能性。
在云数据中心中,用户提交他希望将被执行的工作。用户可以预先指定该工作的优先度和资源估计,所述资源估计就CPU时间、存储器使用等来详述用户预计该工作将消耗的资源的量。
云数据中心执行该工作,并且将结果返回给用户。
每个工作被封装在虚拟容器——比如虚拟机——中,并且一个或者更多个工作共位于一个物理服务器上。每个工作可以具有限制该工作可以被分配到的物理服务器集合的放置约束。例如,约束可以指定特定的机器架构、特定的操作系统、特定的物理位置或者特定的安全约束集合。
随着共位于一个物理服务器上的虚拟容器的数量增加,虚拟容器之间对于该服务器的物理资源的竞争也增加。高竞争可能导致工作的频繁交换和/或资源的低效使用。该现象,被称为性能干扰,对在虚拟容器中运行的工作的执行速率可能有不利的影响。
已经发现,用户通常过高估计所需资源的量,这可能是期望避免工作由于缺乏分配的资源而被延迟的结果,或者是因为缺乏关于他们的工作在运行时期间的实际要求的准确理解。这导致大量空闲资源,并且影响数据中心的能量效率。为了降低这些负面影响,数据中心管理者可以在知道实际所用资源不应超过物理服务器的容量的情况下手动地过高分配可用资源。使物理资源的容量过载可能导致共处一处的工作的性能降低,因此影响客户的满意度。
本发明的目的是解决上述缺点。
技术实现要素:
根据本发明,提供了一种如所附权利要求书中所述的设备和方法。本发明的其他特征从从属权利要求以及下面的描述将是清晰的。
根据本发明的一方面,提供了一种控制数据中心的方法,所述数据中心包括执行多个工作的多个服务器,所述方法包括:
从用户接收执行工作的请求;
确定在其上执行所述工作的分配的服务器;以及
在所述分配的服务器上执行所述工作,
其中所述确定的步骤包括:
根据所述工作的资源要求来对所述工作进行分类;
选择所述服务器中的满足所述工作的资源要求的子集;
确定可以以有利的能量效率执行所述工作的分配的服务器,
并且其中对时常在所述服务器上运行的所有工作的总资源估计超过所述服务器中的至少一个的资源。
所述多个工作可以是多个异类工作。
来自用户的执行工作的请求可以包括资源估计。所述资源估计可以给出指示,或者可以指定所述工作的资源要求。
所述有利的能量效率可以是最高能量效率,所述最高能量效率可以基于工作的完成速度,工作的完成速度与所用功率的量、因此能量效率相关。
确定可以以最高能量效率执行所述工作的服务器的步骤可以包括:
计算所述服务器子集中的每个服务器的过高分配比率OAR;
在OAR给定的情况下确定每个服务器是否具有可用于执行所述工作的资源;
确定每个服务器的估计能量效率,如果所述工作被分派给所述服务器的话;以及
在具有可用资源以及最高估计能量效率的所述服务器上执行所述工作。
计算OAR的步骤可以包括:计算所述服务器的超卖利润率;建立所述用户的类别;使用超卖利润率(P)从描述所述用户的类别的过高估计模式的统计分布计算OAR。
可以根据以下公式来计算超卖利润率:
其中R是由将所述工作分配给所述服务器引起的能量效率(EE)差,并且其中C是分配之后的EE乘以估计的EE变化。
对所述工作进行分类的步骤可以包括:在历史跟踪日志数据的训练集合上训练决策树分类器;并且用决策树分类器对所述工作进行分类。
选择服务器的子集的步骤可以包括:计算服务器特征集合与工作约束集合之间的空间距离;并且选择相似性程度等于或者大于预定最小相似性值的服务器。
所述方法可以进一步包括:检测所述多个服务器中的至少一个中的过载事件;通过驱逐、暂停或者迁移具有最低优先度、最短运行时间的工作来解决检测到的过载事件。
估计的EE变化可以使用估计的性能干扰来计算。
估计的性能干扰可以是共位于所述服务器上的所述多个工作生成的性能干扰的估计总计,所述估计总计是基于位于所述服务器上的每个工作的种类的。
根据本发明的另一个方面,提供了一种用于管理包括多个服务器的计算机数据中心的计算机管理系统CMS,其中每个服务器包括至少一个虚拟容器VC,所述CMS包括:
协调器服务模块,所述协调器服务模块被配置为:从用户接收执行工作的请求,控制CMS确定在其上将执行所述工作的服务器,并且控制CMS执行所述工作;
工作分类服务模块,所述工作分类服务模块可操作来根据所述工作的资源要求来对所述工作进行分类;
资源描述推理器模块,所述资源描述推理器模块可操作来选择满足所述工作的约束集合的服务器子集;
动态状态主机监视器模块,所述动态状态主机监视器模块可操作来将每个服务器的状态记录在数据中心中;
数据中心通信模块,所述数据中心通信模块可操作来与所述多个服务器进行通信;以及
过高分配策略服务模块,所述过高分配策略服务模块可操作来从所述服务器子集以及所述工作的种类确定可以以有利的能量效率执行所述工作的所述服务器。
所述系统可以另外还包括用户分类服务模块,所述用户分类服务模块可操作来建立用户的类别并且确定描述用户的类别的过高估计模式的统计分布。
所述系统另外还包括过载管理器,所述过载管理器可操作来检测所述多个服务器中的至少一个中的过载事件并且通过驱逐、暂停或者迁移具有最低优先度、最短运行时间的工作来解决检测到的过载事件。
过高分配策略服务可以可操作来:计算服务器子集中的每个服务器的过高分配比率OAR;在OAR给定的情况下确定每个服务器是否具有可用于执行所述工作的资源;确定每个服务器的估计能量效率,如果所述工作被分派给所述服务器的话。
过高分配策略服务可以进一步可操作来:计算所述服务器的超卖利润率;使用超卖利润率(P)从描述用户的类别的过高估计模式的统计分布计算OAR。
过高分配策略服务可以可操作来根据以下公式计算超卖利润率:
其中R是由将所述工作分配给所述服务器引起的能量效率(EE)差,并且其中C是分配之后的EE乘以估计的EE变化。
过高分配策略服务可以使用估计的性能干扰来计算估计的EE变化。
估计的性能干扰是共位于所述服务器上的所述多个工作生成的性能干扰的估计总计,所述估计总计是基于位于所述服务器上的每个工作的种类的。
资源描述推理器可以可操作来:计算服务器特征集合与工作约束集合之间的相似性程度;并且选择相似性程度等于或者大于预定最小相似性值的服务器。
根据本发明的另一个方面,提供了一种包括多个服务器的计算机数据中心,其中每个服务器包括至少一个虚拟容器VC,其中所述计算机数据中心合并前一方面的计算机管理系统CMS。
根据本发明的另一个方面,提供了一种具有计算机可执行组件的计算机可读存储介质,所述计算机可执行组件当被执行时使计算装置执行第一个方面的方法。
附图说明
为了更好地理解本发明以及示出本发明的实施方案可以如何付之实行,现在将以举例的方式参照附图,在附图中:
图1a是图示根据示例性实施方案的云计算数据中心的结构的示意图;
图1b是图示根据示例性实施方案的云管理系统的结构的框图;
图2是根据示例性实施方案的干扰和客户知晓过高分配模块的框图;
图3a是详述根据示例性实施方案的计算过高分配比率的方法的流程图;
图3b是详述根据示例性实施方案的计算过高分配比率的方法的流程图;
图4是详述根据示例性实施方案的将工作分配给服务器的方法的流程图;以及
图5是示出根据示例性实施方案的解决过载事件的方法的流程图。
具体实施方式
图1a示出了包括多个服务器计算机2以及云管理系统(CMS)3的云数据中心1。
云数据中心1可以对应于位于同一个建筑物中或者位于同一个地点处的多个服务器2。可替换地,云数据中心1可以改为包括广泛分散的并且由广域网(比如互联网)连接的多个服务器。
所述多个服务器2中的每个服务器2均可以包括至少一个中央处理单元(CPU)(未示出)、存储器(未示出)以及储存器(未示出)。所述多个服务器2中的每个服务器2进一步包括虚拟容器管理器(未示出)或者管理程序(未示出)。虚拟容器管理器(未示出)或者管理程序(未示出)可以由操作系统(OS)(未示出)(例如Linux或者Windows)托管,或者可以改为直接在服务器2的硬件上运行。
此外,所述多个服务器2中的每个服务器2均包括一个或者更多个虚拟容器21,以下称为VC 21。
每个VC 21是计算机的虚拟的基于软件的仿真,就如同它是物理计算机一样提供可操作来执行至少一个软件程序的模拟的计算机环境。
给定服务器2上多个VC 21的提供使得工作可以并行执行,并且可以提供共享比如CPU和存储器的计算资源的高效手段。
VC 21可以被分配在服务器的资源的可以不被在VC 21中运行的任何软件超过的固定部分上。例如,服务器2可以包括四个VC 21a-21d,每个VC被分配服务器资源的25%。
本领域技术人员将理解,服务器资源的分配可以是不均匀的,例如,服务器2的资源中分配给VC 21a的百分比可以大于VC 21b。本领域技术人员将进一步理解,资源的消耗比率可以随着时间变化。
在根据现有技术的云数据中心中,用户4可以向CMS 3提交他希望将被数据中心1执行的工作。用户4可以预先指定工作的优先度以及资源估计,所述资源估计就CPU时间、存储器使用等来详述用户预计该工作将消耗的资源的量。
根据该估计,CMS 3通过在服务器2上创建执行工作的VC 21来将工作分配给适当的服务器2。该分配可以至少部分基于优先度和资源估计。
依赖于资源估计的常见问题是用户非常经常地大大地过高估计工作所需的资源。最近的研究表明,超过90%的工作被过高估计,并且在一些情况下,分配的资源的多达98%被浪费。
为了解决这个问题,CMS 3可以简单地假定资源估计是过高估计,并且因此过高分配服务器2的资源。
图1a还示出了被过高分配的VC 22。分配给VC 21以及被过高分配的VC 22的资源超过服务器2的实际资源。然而,简单地假定,由于用户4的总额过高估计,服务器2不可能用完物理资源。
过高分配的资源与实际资源的比率被称为服务器的过高分配比率(OAR):
在现有技术(例如由或者Apache CloudStackTM管理的)的数据中心中,OAR对于所有服务器都是均匀设置的,并且是只有系统管理员可以改变的固定值。可以基于电子表格模型或者经验法则来计算OAR。
与此相反,CMS 3可操作来对于至少一个服务器2独立于任何其他服务器改变OAR。CMS 3可操作来至少基于以下中的一个来改变OAR:性能干扰影响、客户过高估计模式以及能量效率度量。
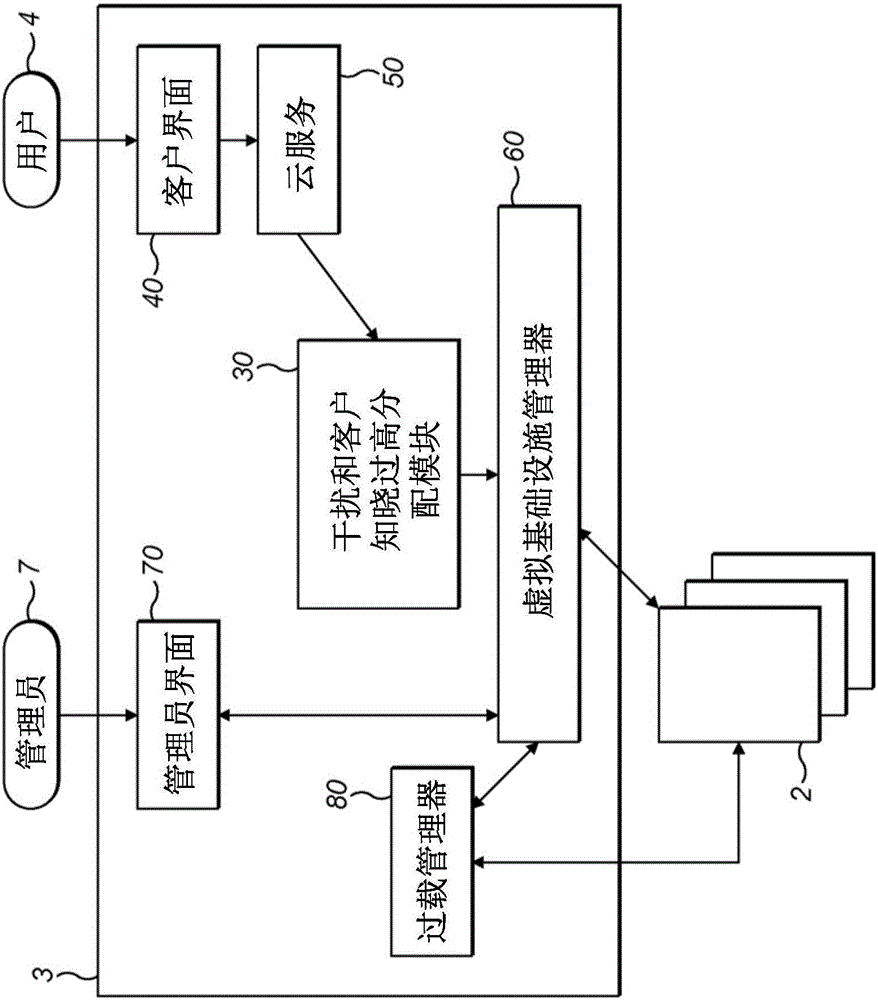
图1b是图示根据本发明的示例性实施方案的CMS 3的框图。
CMS 3包括管理员界面70、客户界面40、云服务50、干扰和客户知晓过高分配模块(ICAO)30以及虚拟基础设施管理器60。
客户界面40可操作来与至少一个用户4进行通信并且从这些用户4接收工作请求。
管理员界面70可操作来与管理员7进行通信。管理员7可以与管理员界面70进行通信,例如以便更新和/或修改许可、访问权限、配额等。
虚拟基础设施管理器60将信息发送到云数据中心1、安置在云数据中心1中的多个服务器2以及安置在所述多个服务器2中的多个VC 21,并且从它们接收信息。该信息可以包括用于控制服务器2和VC 21的控制信息以及关于服务器2和VC 21的状态的状态信息。
虚拟基础设施管理器可操作来管理所述多个服务器2以及安置在所述多个服务器2上的VC 21。具体地说,虚拟基础设施管理器60可以在所述多个服务器2上创建新的VC 21,并且在每个VC 21上执行工作。
云服务器50提供来自用户4的工作请求与CMS 3的其他模块之间的界面。云服务50可操作来从用户4接收工作请求,并且对这些请求进行格式化以使得它们可以被CMS 3的其他模块解释。
ICAO 30可操作来选择在其上执行工作的最高效的服务器2。ICAO 30进一步可操作来请求虚拟基础设施管理器3在最高效的服务器1上创建VC 21并且CMS 3在该VC 21上执行工作。下面参照图2来更详细地描述ICAO 30。
图2示出了根据示例性实施方案的ICAO 30的详细视图。
ICAO 30包括工作分类服务(JCS)31、协调器服务(COS)32、资源描述推理器(RDR)33、过高分配策略服务(OAPS)34、动态状态主机监视器(DSM)35、资源信息服务(RIS)36以及数据中心通信模块(DCM)38。
DCM 38可操作来与虚拟基础设施管理器进行通信,以便将信息发送到云数据中心1、安置在云数据中心1中的多个服务器2以及安置在所述多个服务器2上的多个VM 21并且从它们接收信息。
COS 32可操作来经由云服务50从至少一个用户4接收在数据中心1中执行工作的至少一个请求。COS 32控制ICAO 30的其他模块以便适当地选择在其上执行工作的最高效的服务器2。COS 32随后请求CMS 3在最高效的服务器2上创建VC 2并且CMS 3在该VC 2上执行工作。
工作可以对应于单个软件程序或者多个软件程序。工作不限于任何特定类型的软件程序,并且就它们的目的和它们的资源消耗这二者来说,可以是异类的。
RIS 36提供访问并且利用使用模式数据的界面,该数据是通过监视所述多个服务器2对于JCS 31的资源利用模式而收集的。该数据是经由数据中心通信模块38从所述多个服务器2收集的。该数据可以由监视器(未示出)收集,所述监视器比如允许监视VC 21的资源的Libvirt API。
RIS 36可以进一步包括资源监视数据库(未示出)以便存储资源使用模式。
JCS 31接收描述工作的特性的数据,根据工作的特性来对工作进行分类,并且将分类发送到COS 32。特性数据可以包括关于任务长度、CPU时间和所需存储器的信息。
JCS 31将工作分类为小型的、中等的或者大型的。将理解,JCS 31可以可替换地将工作分类为更多的或者更少的种类。所用种类的数量可以取决于数据中心1的工作负荷特性。
JCS 31使用决策树分类器以便对工作进行分类。决策树分类器是使用历史数据中心跟踪日志信息的数据集合来进行训练的。所用的历史信息是由RIS 36提供的使用模式数据。
将理解,任何适当的算法可以被用来对工作进行分类,包括任何监督或者半监督的机器学习算法或者一套手动制定规则。
在示例性实施方案中,ICAO 30还包括用户分类服务(UCS)39。
UCS 39可以使用统计模型来确定共存的用户4的最小过高估计模式。该统计模型包括多个分布,每个分布对应于用户4的类别。
用户4的类别是通过历史工作和用户数据的分析来建立的。在示例性实施方案中,历史数据的k均值聚类被用来建立用户4的类别。
历史数据包括与用户4所拥有的工作的提交比率、估计的CPU使用以及估计的存储器使用相关的信息。它还包括与用户4所拥有的工作的实际CPU使用和实际存储器使用相关的信息。历史数据可以由RIS 36提供。
将理解,其他算法,比如监视或者半监督的机器学习算法或者一套手动制定规则,可以被用来对用户数据进行归类。该算法然后基于工作特性来选择用户类别。
每个用户类别的过高估计分布可以是不同的,并且可以包括比如广义极值、对数、正态、Wakeby或者3参数对数正态的分布。UCS 39可操作来将拟合优度测试应用于与每个用户类别对应的数据以便为每个用户类别建立适当的分布。
用户和/或对应于他们的分布的类别被周期性地重新计算。分布可以在进一步的数据被产生时被动态地更新。
RDR 33预先选择服务器2中的满足传入的工作的约束的子集。约束可以是前述特性数据和/或任何其他的用户指定的约束。RDR 33包括维护数据中心1中的所有服务器2以及它们的特征的库的案例库(未示出)。
RDR 33获取库中所描述的服务器特征F={f1,f2,f3,...,fn}以及工作约束集合C={c1,c2,c3,...,cn},并且通过使用基于案例的推理(CBR)的检索阶段来确定它们的相似性。
CBR是人工智能技术,其中过去的案例的库被直接用来解决问题,与通过训练数据来形成规则或者归纳、然后使用这些规则或者归纳来解决问题的机器学习技术相反。CBR是四步处理:(1)从案例库检索与当前问题最相似的一个案例或者多个案例;(2)重复使用检索的案例(一个或者更多个)来试图解决当前问题;(3)如果必要,修订并且改动所提出的解决方案;(4)将最终解决方案作为新案例的一部分保留。
RDR 33返回与要求匹配的预选服务器2的列表。可替换地,RDR 33可以返回相似性等于或者大于预定最小相似性值的服务器2的列表。最小相似性值由系统管理员设置,并且可以由系统管理员调整以便增强软约束和硬约束这二者的满足。
将理解,可以使用用于预选服务器2的任何合适的算法,并且可以利用任何相似性计算。
DSM 35将每个服务器2的状态记录在数据中心1中。每次VC 21被部署或者被从特定服务器2移除时,该服务器2的特性就被DSM 35确定,然后被存储。当COS 32请求关于服务器2的特性的数据时,DSM 35可操作来将该数据发送到COS 32。服务器2的特性可以使用散列图结构来存储以使得能够对服务器列表进行索引搜索。
DSM 35确定的特性可以包括资源可用性、能量效率以及组合干扰得分(CIS),所有这些都在下面描述。
服务器s的资源可用性A可以针对每个资源r={CPU,memory,disk,bandwidth}基于最大服务器可用性Max(r,s)以及对于每个部署的VC的Alloc(r,vc)的当前分配的和来确定。最大服务器可用性Max(r,s)考虑到服务器s的物理容量以及对服务器s估计的OAR。可以根据以下公式来计算资源可用性A:
服务器的能量效率EE按照正被计算的工作w(其可以就百万指令数来测量)与以瓦特为单位的所用功率P(u)的比率来计算。可以根据以下公式来计算能量效率:
P(u)=ΔPow.u+(P(α)-ΔPow.α)
其中u是系统使用率,α和β是根据预定服务器剖析处理的使用率下水平和上水平。
CIS是单个物理服务器2上的多个VC 21a-d之间的干扰的测量。随着给定服务器2上的VC 21的数量增加,VC 21之间对于服务器2的物理资源的竞争也增加。高竞争可能导致工作的频繁交换和/或资源的低效使用。因此,性能干扰可能对在VC 21中运行的工作的执行速度有负面影响。
根据以下公式计算CIS:
其中n是共位于服务器s中的VC的总数,Pi是当VCi与其他VC组合时VCi的性能,而Bi是当VCi隔离运行时VCi的性能。
COS 32从JCS 31、RDR 33和DSM 35接收信息,并且将该信息提供给OAPS 34。COS32还可以从UCS 39接收信息,并且将该信息提供给OAPS 34。OAPS 34可操作来确定适合于用户4请求的工作的分配的服务器2。
OAPS 32就过高分配的资源的量计算具有最高预期能量效率的服务器2,并且将工作分配给该服务器。
此外,OAPS 32可操作来确定适合于服务器2的过高分配比率(OAR)。OAR可以参照描述如下比率的统计模型来计算,在该比率,特定类型的客户端过高估计它们的所需资源。
下面参照图3a、3b和4来详细描述OAPS 32用来计算OAR的算法。
图3a是示出计算给定服务器2的OAR的方法的流程图。
首先,在步骤S301中,使用UCS 39来确定用户类别。第二,在步骤S302中,所述算法计算超卖利润率P。最后,在步骤S303中,所述算法从P和用户类别计算过高分配比率。
下面参照图3b来更详细地解释计算OAR的方法。
首先,在步骤S311中,使用UCS 39来确定用户类别。
第二,在步骤S312中,使用JCS 31来确定工作的种类。
第三,在步骤S313中,所述算法计算与超卖相关联的能量效率收益R的估计。R被定义为由将工作分配给给定服务器2引起的能量效率(EE)差:
R=EE(afterAllocation)-EE(current)
其中EE是根据与以上参照DSM 35的函数定义的相同公式来计算的。
第四,在步骤S314中,所述算法计算与超卖相关联的能量效率成本C的估计。
C是分配之后的EE乘以估计的EE变化(EstΔEE)。估计的EE变化(EstΔEE)考虑到就CIS(EstCIS)测量的估计的性能干扰:
C=EE(afterAllocation)*EstΔEE
EstΔEE=EstΔEE(EstCIS)
EstCIS是如果工作被分配给服务器,CIS的估计。具体地说,EstCIS是共位于特定服务器2上的所有工作生成的总计干扰的估计,该估计是基于位于服务器2上的每个工作的种类的。每个工作的种类可以由JCS 31建立。
在示例性实施方案中,通过测量与工作种类的每个可能的配对组合相关联的CIS来推导EstCIS。给定表示小型工作、中等工作和大型工作的三个工作种类,对于以下配对组合来测量CIS:(小型,小型)、(小型,中等)、(小型,大型)、(中等,中等)、(中等、大型)、(大型、大型)。然后从这些配对-组合CIS测量计算特定服务器2的EstCIS。
EstCIS可以通过相关配对的简单加法来计算。例如,具有大型工作、小型工作和中等工作的服务器的EstCIS可以通过测量的与配对组合(小型,大型)、(小型,中等)和(中等,大型)相关联的CIS的加法来计算。
本领域技术人员将理解,任何合适的算法可以可替换地被用来基于共位于特定服务器2上的工作的特性来估计CIS。
随后,在步骤S315中,所述算法计算超卖利润率P。根据以下公式来计算P:
利润率P随后被用作统计模型中的参数,以便计算服务器2的OAR。
随后,在步骤S316中,使用UCS 39来确定考虑到所有的共处一处的用户和新用户的用户类别的最小过高估计模式。
最后,在步骤S317中,根据以下公式来计算OAR:
OAR=1+inverseCDF(minOverestimation,P)
其中inverseCDF是最小用户过高估计模式的分布的逆累积分布函数。
将理解在替换示例性实施方案中,可以从OAR的计算省略UCS 39进行的用户分类。在这些替换示例性实施方案中,可以改为对所有用户都假定单个用户类别。
如图4的流程图所示,OAPS 34计算数据中心1中的每个服务器2的OAR。
首先,在步骤401中,将表示最大EE(afterAllocation)的值设置为-1,该值被称为maxEE。
对于数据中心1中的每一个服务器2,计算OAR(S403)。使用图3b所示的以及在上面描述过的方法来计算OAR。
如果鉴于计算的OAR,服务器2不具有可用于接手工作的资源,则所述方法移到数据中心1中的下一个服务器2(S404)。服务器2的资源的可用性可以由DSM 35建立。
如果另一方面,服务器2具有可用资源,则确定EE(afterAllocation)是否大于目前存储的maxEE(S405)。
如果EE(afterAllocation)小于或者等于maxEE,则所述方法移到下一个服务器2。如果EE(afterAllocation)大于maxEE,则在移到下一个服务器2之前用EE(afterAllocation)的值取代目前存储的maxEE。
当所有服务器2都已经被分析(S402)时,对应于maxEE的服务器2被分配工作(S407)。
由此,具有可用来执行工作的资源和最大EE(afterAllocation)的服务器2被分配工作。
因此,OAPS 34能够以节省数据中心能量消耗并且还考虑到用户4过高估计工作所需资源的趋势以及由竞争工作引起的性能干扰这二者的方式将工作分配给服务器2。
此外,OAPS 34能够计算数据中心2中的每个服务器2的OAR,OAR反映用户资源过高估计。
OAPS 34将将被分配工作的服务器2的身份提供给COS 32。COS 32然后将服务器2的身份提供给CMS 3,CMS 3在服务器2上执行工作。
返回到图1b,CMS 3可以进一步包括过载管理器(OM)80。OM 80负责检测并且缓解过载事件的发生。
当所需资源的量超过给定服务器2上的资源的物理限值时,过载事件发生。
OM 80从数据中心1中的每个服务器2接收数据。该数据包括关于共处一处的工作负荷的资源消耗的信息,并且可以由监视器(未示出)收集,所述监视器比如Libvirt API。
OM 80然后使用该数据来确定服务器2中的哪个(如果有的话)过载。过载然后通过OM 80重复地移除优先度最低的那些工作来停止。如果多于一个的工作具有相同的优先度,则驱逐运行时间最短的工作。
参照图5来描述解决过载事件的方法。
OM 80可以遍历数据中心1中的服务器2的列表来迭代进行。在步骤S501中,开始检查列表上的下一个服务器的过程。
在步骤S502中,确定正被检查的服务器是否正在经历过载事件。
如果服务器过载,则从服务器驱逐优先度最低、运行时间最短的工作(S503)。
如果服务器仍过载,则重复所述处理,直到过载停止为止。
当过载停止时,OM 80移到列表中的下一个服务器,并且开始检查过程。如果没有剩下更多的服务器要检查,则所述处理结束(S504)。
被OM 80驱逐的这些工作可以被重新发送到ICAO 30以供用于重新分配。
本领域技术人员将理解,OM 80识别的工作可以改为被暂停或者被迁移。
OM 80可以被周期性地执行,并且只需要与虚拟基础设施管理器60和所述多个服务器2进行交互来执行所需的驱逐。
上述系统和方法可以有利地使得数据中心1可以通过过高分配物理资源2的容量来克服用户4对于所需资源的过高估计。
有利地,所述系统和方法可以允许对数据中心1中的每个服务器2计算过高分配比率,而不是单个比率应用于整个数据中心1中的每个服务器2。
另外,过高分配比率可以反映数据中心1的用户4的过高分配模式。过高分配比率还可以反映由在服务器2上运行的工作的数量和类型引起的性能干扰。过高分配比率还可以考虑到所做的分配的能量效率,从而便利能量效率更高的数据中心1。
有利地,过载管理器37可以解决由错误的过高分配引起的过载事件,从而改进数据中心1的性能。
本文中所描述的示例实施方案中的至少一些可以部分地或者整个地通过使用专用的特殊用途的硬件来构造。本文中所使用的比如“组件”、“模块”或者“单元”的术语可以包括但不限于执行某些任务或者提供相关联的功能的硬件装置,比如分立组件或者集成组件的形式的电路、现场可编程门阵列(FPGA)或者专用集成电路(ASIC)。
在一些实施方案中,所描述的元素可以被配置为驻留在有形的、持久的、可寻址的存储介质上,并且可以被配置为在一个或者更多个处理器上执行。在一些实施方案中,这些功能元素可以包括举例来说组件(比如软件组件、面向对象的软件组件、类组件以及任务组件)、处理、功能、属性、过程、子例程、程序代码段、驱动器、固件、微代码、电路、数据、数据库、数据结构、表格、数组以及变量。
尽管已经参照本文中所讨论的组件、模块和单元描述了示例实施方案,但是这样的功能元素可以被组合为更少的元素或者被划分为附加的元素。本文中已经描述了可选特征的各种组合,将意识到,所描述的特征可以按任何合适的组合进行组合。具体地说,任何一个实例实施方案的特征可以视情况与任何其他实施方案的特征组合,除了这样的组合相互排斥的情况之外。在整个本说明书中,术语“包括”意指包括所指定的组件(一个或者更多个),但是不排除其他组件的存在。
注意与有关本申请的本说明书同时提交的或者之前提交的并且通过本说明书向公众开放查阅的所有论文和文件,所有这样的论文和文件的内容都通过引用并入本文。
本说明书(包括任何所附权利要求书、摘要和附图)中所公开的所有特征和/或如此公开的任何方法或者处理的所有步骤都可以按任何组合进行组合,除了这样的特征和/或步骤中的至少一些相互排斥的组合之外。
本说明书(包括任何所附权利要求书、摘要和附图)中所公开的每个特征可以被提供相同的、等同的或者相似的目的的替换特征取代,除非另有明确陈述。因此,除非另有明确陈述,所公开的每个特征都仅仅是等同或者相似特征的一般系列的一个实施例。
本发明不限于前述实施方案(一个或者更多个)的细节。本发明扩展到本说明书(包括任何所附权利要求书、摘要和附图)中所公开的特征的任何新颖的发明或者任何新颖的组合以及如此公开的任何方法或者处理的步骤的任何新颖的发明或者任何新颖的组合。
- 还没有人留言评论。精彩留言会获得点赞!