可用于例如量子计算的用于求解问题的系统和方法与流程
背景技术:
本公开总体上涉及以计算方式求解问题并且尤其可以用于经由量子处理器进行量子计算。
求解器
求解器是经由被设计成用于求解数学问题的硬件电路执行的一组基于数学的指令。一些求解器是被设计成用于求解广泛类型或类别的问题的通用求解器。其他求解器被设计成用于求解特定类型或类别的问题。一组非限制性示例性类型或类别的问题包括:线性和非线性方程、线性方程组、非线性组、多项式方程组、线性和非线性优化问题、普通微分方程组、可满足性问题、逻辑问题、约束满足问题、最短路径或旅行商问题、最小生成树问题、以及搜索问题。
存在许多求解器可用,其中大多数被设计成在经典计算硬件上执行,即采用数字处理器和/或数字处理器可读的非瞬态存储介质(例如,易失性存储器、非易失性存储器、基于盘的介质)的计算硬件。最近,被设计成在非经典计算硬件上执行的求解器变得可获得,例如被设计成在模拟计算机(例如包括量子处理器的模拟计算机)上执行的求解器。
绝热量子计算
绝热量子计算典型地涉及通过逐渐改变哈密尔顿算子来将一个系统从一个已知的初始哈密尔顿算子(该哈密尔顿算子是一个运算符,它的本征值是该系统所允许的能量)演算到一个最终的哈密尔顿算子。一个绝热演算的简单示例是:
he=(1-s)hi+shf(0a)
其中,hi是初始哈密尔顿算子,hf是最终哈密尔顿算子,he是演算或瞬态哈密尔顿算子,并且s是控制演算速率的演算系数。随着系统的演算,演算系数s从0到1,这样使得在开始时(即,s=0)演算哈密尔顿算子he等于初始哈密尔顿算子hi,并且在结束时(即,s=1)演算哈密尔顿算子he等于最终的哈密尔顿算子hf。在演算开始之前,典型地将系统初始化为处于初始哈密尔顿算子hi的基态中,并且目标是使系统进行演算的方式为使得在演算结束时所述系统结束在最终的哈密尔顿算子hf的基态中。如果该演算太快,则该系统能够转换到更高的能态,例如第一激发态。总体上,“绝热”演算被认为是满足以下绝热条件的一种演算:
其中,
在绝热量子计算中改变哈密尔顿算子的过程被称为演算。变化速率、例如s变化的速率足够慢而使得所述系统在演算过程中总是处于演算哈密尔顿算子的瞬时基态中,并且避免了在反交叉处(即,当所述间隙大小为最小时)的转变。以上给出了线性演算方案的实例。其他演算方案是可能的,包括非线性的、参数化的等等。在美国专利号7,135,701和7,418,283中描述了关于绝热量子计算系统、装置及方法的进一步细节。
量子退火
量子退火是一种计算方法,所述方法可以被用于找出系统的低能态,典型地优选是基态。与经典的退火概念相类似,该方法所依赖的本质性原理在于自然系统趋向于低能态,因为低能态是更加稳定的。然而,尽管经典退火使用经典的热波动将系统引导到低了能量状态并且典型地到它的全局能量最小值,但量子退火可以使用量子效应(如量子隧道效应)来比经典退火更精确和/或更快速地达到一个全局能量最小值。在量子退火中可能存在热效应和其他噪声以辅助退火。然而,最终低能量状态可以不是全局能量最小值。绝热量子计算因此可以被认为是量子退火的特殊情况,对于量子退火所述系统在理想情况下对于整个绝热演算开始于并保持在它的基态中。因此,本领域的普通技术人员应当理解量子退火系统和方法总体上可以在绝热量子计算机上实现。贯穿本说明书以及所附的权利要求书,任何提及对量子退火之处均旨在包含绝热量子计算,除非上下文中另有要求。
量子退火在退火过程中使用量子力学来作为无序化源。最优化问题被编码在哈密尔顿算子hp中,并且所述算法通过增加与hp不进行交换的无序化哈密尔顿算子hd来引入量子效应。示例性情形为:
he∝a(t)hd+b(t)hp,(0c)
其中a(t)和b(t)是依赖于时间的包络函数。哈密尔顿算子he可以被认为是与以上在绝热量子计算的背景下描述的he相类似的演算哈密尔顿算子。通过去掉hd(即,减小a(t))可以去掉这种离域作用。可以添加并接着去除这种离域作用。因此,由于所述系统以初始哈密尔顿算子开始、并且通过演算哈密尔顿算子演算到最终的“问题”哈密尔顿算子hp(它的基态对于所述问题的解进行编码),所以量子退火与绝热量子计算是相类似的。如果所述演算足够慢,那么所述系统将典型地进入全局最小值(即,精确解)、或进入能量接近所述精确解局部最小值。这种计算的性能可以经由与演算时间相对比的残余能量(与使用目标函数的精确解之间的差异)来进行评定。该计算的时间是生成在某个可接受的阈值以下的一个残余能量所需要的时间。在量子退火中,hp可以对最优化问题进行编码,但是所述系统不一定一直保持在基态中。hp的能量形态可以是精心设计的,这样使得它的全局最小值是有待被求解的问题的答案,并且处于低位的多个局部最小值是多个良好的近似。
稳恒电流
超导通量量子位(例如射频超导量子干涉装置;“rf-squid”)可以包括被至少一个约瑟夫逊结中断的超导材料回路(称为“量子位回路”)。由于量子位回路是超导的,所以它实际上没有电阻。因此,在量子位回路中流动的电流可以不经历损耗。如果电流通过(例如)磁通量信号耦合到量子位回路中,那么这个电流甚至在所述信号源被去除时也可以继续围绕该量子位回路循环。该电流可以无限期地持续直到它被以某种方式所干扰或者直到该量子位回路不再是超导的(例如,由于将该量子位回路加热到了它的临界温度之上)。为了本说明书的目的,术语“稳恒电流”被用于说明在一个超导量子位的量子位回路中循环流动的电流。稳恒电流的符号和幅值可以受多种因素影响,这些因素包括但不限于直接连接到该量子位回路上的通量信号φx以及连接到中断该量子位回路的一个复合约瑟夫逊结上的通量信号φcjj。
量子处理器
量子处理器可以采取超导量子处理器的形式。超导量子处理器可以包括多个量子位以及多个相关联的局部偏置器件。超导量子处理器还可以采用多个耦合器以便在量子位之间提供可调谐的通信连接。量子位和耦合器彼此相似但物理参数不同。一种区别为参数β。考虑rf-squid,被约瑟夫逊结中断的超导回路β是所述约瑟夫逊结的电感与所述回路的几何电感之比。具有较小值的β(大约1)的设计表现得更像简单的感应回路,一种单稳态器件。具有较高值的设计更多地被约瑟夫逊结主导、并且更可能具有双稳态行为。参数β被定义为2πlic/φ0。也就是,β与电感和临界电流的积成比例。可以改变电感,例如,量子位正常地大于其相关联耦合器。较大的器件具有较大的电感,并且因此量子位通常是双稳态器件而耦合器是单稳态的。替代地,可以改变所述临界电流,或者可以改变临界电流与电感的积。量子位通常会具有与之相关联的更多器件。在美国专利7,533,068、8,008,942、8,195,596、8,190,548以及8,421,053中说明了可以与本发明的系统、方法及器件结合使用的示例性量子处理器的进一步的细节及实施例。
使用量子退火来求解计算问题的许多技术涉及:寻找将问题的表示直接映射/嵌入量子处理器的方法。总体上,通过首先将问题转化为所设计的公式(例如,伊辛自旋玻璃问题、qubo等)来求解问题,因为该具体公式直接映射到所采用的量子处理器的具体实施例。具有n个变量或自旋s∈[-1,+1]的qubo可以被写成以下形式的成本函数:
其中hi和jij是规定所希望的伊辛自旋玻璃情形的无量纲的量。求解这个问题涉及寻找针对所提供的具体一组hi和jij将e最小化的自旋配置si。在一些实现方式中,所允许的范围是hi∈[-2,2]以及jij∈[-1,1]。出于后文描述的原因,hi和jij在优化过程中没有完美表示在硬件上。这些歪曲可以被限定为控制误差:
hi→hi±δhi(2a)
jij→jij±δjij(2b)
控制误差δh和δj从多个来源产生。一些误差来源是依赖于时间的并且其他是静态的、但取决于h和j值的具体组合。
固有/控制误差(ice)
量子处理器可以实施以下形式的依赖于时间的哈密尔顿算子:
其中γi(t)是描述单一自旋量子隧道效应的幅度的无量纲的量,并且jafm(t)是总能量尺度。方程式3a是所希望哈密尔顿算子或目标哈密尔顿算子。通过引导系统经过从t=0时的离域的基态(满足γi(t=0)>>hi,jij)到t=tf时的局部自旋状态(满足γi(tf)<<hi,jij)的量子相变来实现量子退火。关于这种演算的进一步细节可以见于以下文献中:哈里斯(harris)等人,experimentalinvestigationofaneight-qubitunitcellinasuperconductingoptimizationprocessor,phys.rev.b,vol.82,issue2,024511,2010(“harris2010b”)。可以通过使用电感耦合的超导通量量子位与耦合器的网路在量子退火处理器上实施方程式3a给出的哈密尔顿算子,例如在在以下文献中描述的:哈里斯(harris)等人,compoundjosephson-junctioncouplerforfluxqubitswithminimalcrosstalk,phys.rev.b,vol.80,issue5,052506,2009(“harris2009”)和harrisetal.,experimentaldemonstrationofarobustandscalablefluxqubit,phys.rev.b,vol.81,issue13,134510(“harris2010a”)。如在harris2010b中描述的,无量纲参数hi、jij和γi(t)按以下方式映射到物理设备参数:
其中
在量子处理器上实施的量子退火目的在于实现独立于时间的hi和jij。方程式3c在代入jafm(t)的定义并假定以下内容之后自然地得出独立于时间的量:
为了在方程式3b中从满足以下假定的hi中删去时间依赖性:
向第i个量子位施加以下形式的依赖于时间的通量偏置
应当被施加,其中
方程式3a-3e将无量纲的用户指定的量hi和jij进行关联,这些量对量子位和耦合器的物理性质限定了伊辛自旋玻璃情形。这些硬件元件在设计和制造方面受到实际约束,这些约束最终限制了用户可以对伊辛自旋玻璃参数hi和jij施加的控制量。术语固有/控制误差(ice)限定了在量子处理器(即,芯片)上可以实现一个hi和jij的解析度。可以基于这些来源或误差是否是由于芯片上的具体器件的某种固有非理想性或是它们是否是由于某种控制结构的有限分辨率来对误差来源进行分类。可论证地,控制γi可以达到的解析度对于量子退火的效力可以具有显著负担。出于本系统和方法的目的,假定所有γi(t)是相同的。
可以通过修改以上给出的hi和jij的定义以便包括物理误差源来表征ice的影响:
其中,假定是,全局变量mafm、
如果量子位稳恒电流的偏差
其中在针对δjij的公式中的假定为以下绝对最坏情况:这两个稳恒电流的偏差被相关并且幅度相等。
在所有其他被设定为零时,互感偏差δmi≠0仅影响hi。将方程式4c代入方程式4a中得到了:
同样,在所有其他被设定为零时,量子位退化点的偏差
最后,在所有其他被设定为零时,量子位间耦合互感的偏差δmij仅影响jij,如下文所示:
值得注意的是,量子位稳恒电流的偏差
方程式5a至5e产生作为量子位稳恒电流
表现度量
如与优化启发法共有的,无论是量子的还是经典的,都可以通过计算时间与解品质之间的折中来表征表现。一般更多的时间得到更好的解。可以使用表现度量来量化一种方法的表现。
一个表现度量是sts(得出解的样本)并且是达到最优解的预期样本数量。也可以表示为tts(得出解的时间),为样本数量乘以产生每个样品所花的时间。
另一个表现度量是ste(得出ε的样本)并且是在最优值的距离ε内达到解能量的预期样本数量。通过将样本时间乘以得出ε的样本获得tte(得出ε的时间)。
第三个度量是ttt(达到目标的时间)。当使用量子退火器来求解np-困难优化问题时,例如,计算最优成本并不总是可行的。ttt的优点是,它不需要最优解的知识。在一种途径中,将两个求解器的最小样本能量的会聚性进行比较。
简述
需要能够产生多种多样问题的解或可能解、并且以有时间效率和计算成本效率的方式做到这点。针对具体问题或具体类别的问题选择适当的求解器可能是困难且耗时的,例如选择最适当的硬件可能如此。提供对多个求解器和硬件的访问的自动途径是所希望的。
描述了多种计算系统,至少在一些实现方式中,这些计算系统可以用于提供经由简单接口(例如,应用程序编程接口(api)或基于web的用户界面)来远程访问的服务,以便使用经由在多种硬件(例如,处理器)上执行多种算法而实现的多种求解器来求解问题。该接口采用例如以下中的任一项作为输入:任何qubo矩阵q、指明优化或玻耳兹曼抽样是否被希望的标记、以及用于专家用户的一组参数。该接口还可以采用被公式表示为可满足性(sat)问题、图形模型(gm)或二次分配问题(qap)的问题作为输入。该接口返回最佳解作为输出。
这些系统可以包括用于在qubo上进行求解、优化和抽样的多种多样的算法。这些计算系统可以例如并行地运行或执行这各个算法、并且使用从两个或更多求解器算法返回的最佳答案。这些计算系统可以包括超导或量子硬件、以及经典的非超导或非量子硬件二者。这些计算系统典型地对问题进行预处理、并且对所述求解器处理所述问题的结果进行后处理。这种途径可以以有成本效益的方式提供品质解。
在此描述的这些计算系统、设备、物品和/或方法是利用各种技术并创建新类型的混合算法的混合解。这种途径采用非常适合的求解器和硬件,包括经典的或非量子的计算和量子计算。例如,使用现场可编程门阵列(fpga)运行的禁忌搜索可能比在标准微处理器上运行的禁忌搜索快得多。此外或替代地,这种途径可以使用利用了经典和/或量子计算硬件的专属和/或非专属方法来对结果进行预处理和后处理。此外,这些计算系统可以针对某些任务将计算传递给到处可获得的云资源,例如亚马逊网络服务(aws)或gpu集群,如果具体问题的适当或最优架构是由这样的设置来提供的话。在此描述的这些计算系统、设备、物品和/或方法可以作为软件即服务(saas)递送机制来运行。
一种在计算系统中的操作方法可以被概述为包括:接收问题并且执行迭代次数i直至数目n,其中n是正整数。每次迭代包括:致使由至少一个处理器执行求解器以产生多个样本作为对所述问题的可能解;由至少一个控制器致使由至少一个基于非量子处理器的后处理设备对所述多个样本执行至少一个后处理操作以产生一组后处理结果;并且至少部分地基于所述一组后处理结果来判定是否修改所述问题。在至少部分地基于所述一组后处理结果确定修改所述问题之后,第i次迭代进一步包括致使所述问题被修改并且发起第(i+1)次迭代。
致使由至少一个处理器执行所述求解器以产生多个样本作为对所述问题的可能解可以包括:致使由至少一个处理器所执行的至少一个启发式优化器来优化所述问题以产生多个样本作为对所述问题的可能解。
至少部分地基于所述一组后处理结果来判定是否修改所述问题可以包括:将所执行的所述迭代次数与确定的极限进行比较和/或将所执行的迭代次数与确定的极限进行比较。
在上述方法的一些实现方式中,所述至少一个处理器是非量子处理器,所述非量子处理器包括例如以下各项中的至少一项的至少一个非量子处理器:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、现场可编程门阵列(fpga)、以及专用集成电路(asic)。
在上述在计算系统中的操作方法的一些实现方式中,所述至少一个处理器是量子处理器。
在所述计算系统中的操作方法的任一上述实施例中,致使由至少一个基于非量子处理器的设备执行至少一个后处理操作可以包括致使由以下各项中的至少一项来执行所述至少一个后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、现场可编程门阵列(fpga)、以及专用集成电路(asic)。此外,致使由至少一个基于非量子处理器的设备执行至少一个后处理操作可以包括致使由至少一个数字处理器执行以下各项中的至少一项:多数表决后处理操作、贪婪下降后处理操作、变量钳制后处理操作、变量分支后处理操作、局部场表决后处理操作、局部搜索寻找局部最小值后处理操作、在固定温度的后处理操作中的马尔可夫链蒙特卡罗模拟、以及米特罗波利抽样后处理操作。
在上述在计算系统中的操作方法一些实现方式中,可以对于不同的迭代使用不同的启发式优化器。例如,在第一迭代时由至少一个处理器所执行的第一启发式优化器并且在第二迭代时由至少一个处理器所执行的第二启发式优化器来优化所述问题,其中所述第二启发式优化器不同于所述第一启发式优化器。上述在计算系统中的操作方法,所述方法包括:由所述计算系统的至少一个部件在多种类型的硬件设备之间进行自主选择以用于执行所述启发式优化。所述在计算系统中的操作方法可以包括:由所述计算系统的至少一个部件在多种类型的启发式优化算法之间进行自主选择以用于执行所述启发式优化。
所述在计算系统中的操作方法可以进一步包括:由所述计算系统的至少一个部件向用户发送来自所述一组后处理结果中的一个或多个结果。
在所述在计算系统中的操作方法的一些实施例中,n是大于2的整数,并且对于在2与(n-1)之间的i值,所述由所述至少一个基于非量子处理器的后处理设备对第i多个样本执行至少一个后处理操作以产生第i组后处理结果是与所述由至少一个处理器所执行的至少一个启发式优化器进行优化以产生第(i+1)多个样本在时间上至少部分重叠地发生的。在一些情况下,所述对第i多个样本执行所述至少一个后处理操作以产生第i组后处理结果并未在时间上延伸超过所述由至少一个启发式优化器进行优化以产生第(i+1)多个样本。在一些情况下,所述对第i多个样本执行所述至少一个后处理操作以产生第i组后处理结果的持续时间小于所述由至少一个启发式优化器进行优化以产生第(i+1)多个样本的持续时间。所述由至少一个启发式优化器进行优化以产生所述多个的持续时间对于不同的迭代可以不同。例如,所述由至少一个启发式优化器进行优化以产生第(i+1)多个样本的持续时间可以不同于所述通过至少一个启发式优化器进行优化以产生第i多个样本的持续时间。
在所述在计算系统中的操作方法中,其中n是大于2的整数,对于具有在2与(n-1)之间的i值的迭代,所述方法进一步包括确定所述由至少一个处理器所执行的至少一个启发式优化器进行优化以产生第(i+1)多个样本的时机,并且所述由所述至少一个基于非量子处理器的后处理设备对第i多个样本执行至少一个后处理操作以产生第i组后处理结果可以与所述由至少一个处理器所执行的至少一个启发式优化器进行优化以产生第(i+1)多个样本在时间上至少部分重叠地发生。确定所述由至少一个启发式优化器进行优化的时机可以包括例如确定以下各项中的至少一项:所述通过至少一个启发式优化器进行优化以产生第(i+1)多个样本的开始时间、结束时间、以及持续时间。所述方法可以包括确定所述由所述至少一个基于非量子处理器的后处理设备对第i多个样本执行所述至少一个后处理操作以产生第i组后处理结果的时机。确定所述对第i多个样本执行所述至少一个后处理操作以产生第i组后处理结果的时机可以包括例如确定以下各项中的至少一项:所述对第i多个样本所述至少一个后处理操作的开始时间、结束时间、以及持续时间。
在所述在计算系统中的操作方法的一些实施例中,所述方法进一步包括:由基于处理器的设备来执行对所述问题的预处理评定;并且由所述基于处理器的设备至少部分地基于对所述问题的所述预处理评定从多个启发式优化器中选择所述至少一个启发式优化器。接收所述问题可以包括:确定所述问题的格式;并且判定所述问题的所述确定的格式是否为受支持格式。响应于确定所述问题的所述确定的格式不被支持,所述方法可以进一步包括拒绝所述问题并且由所述计算系统的至少一个部件来向用户提供拒绝所述问题的通知。响应于所述问题的格式受支持,所述方法可以进一步包括由所述基于处理器的设备来产生所述问题的多个表示。针对所述问题的所述表示中的每一个,所述方法可以包括:从所述问题中提取多个特征;至少部分地基于所述提取的特征来评定和/或评估多个启发式优化器中的每一个;基于由所述基于处理器的设备进行的所述评估或该评定中的至少一项来选择一个或多个启发式优化器;并且致使所述所选的一个或多个启发式优化器对所述问题进行操作。基于由所述基于处理器的设备进行的所述评估来选择一个或多个启发式优化器可以包括:基于由所述基于处理器的设备进行的所述评估或所述评定中的至少一者来自主选择一个或多个启发式优化器。至少部分地基于所述提取的特征来评估多个启发式优化器中的每一个可以包括:预测所述多个启发式优化器的每一个启发式优化器在使用所述提取的特征返回所述问题的最优解时将会多么成功。在一些情况下,选择至少两个启发式优化器,并且所述至少两个启发式优化器彼此不同。所述方法可以进一步包括:将来自所述所选的至少两个不同的启发式优化器中的每一个的结果进行比较;并且至少部分地基于所述比较来确定优选解。所述方法可以进一步包括:将所述所选的至少两个不同的启发式优化器中的每一个对所述问题的所述最终结果进行比较;并且至少部分地基于所述比较来确定优选解。所述方法可以进一步包括:针对所述所选的启发式优化器中的每一个,将所述问题分解成多个部分;将所述部分分配给多个计算资源中的相应计算资源;收集针对所述问题的每个部分的结果;并且基于来自所述部分的结果产生所述启发式优化器对所述问题的最终结果。将所述部分分配给多个计算资源的相应计算资源可以包括基于所述问题的相应部分所要求的处理类型来分布所述部分。
一种计算系统可以被概述为包括:至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到至少一个启发式优化器上,所述至少一个启发式优化器在操作中针对一次或多次迭代中的每一次产生多个样本作为问题的可能解。所述至少一个启发式优化器被至少一个处理器执行。所述至少一个基于处理器的控制器操作性地耦合到至少一个基于非量子后处理处理器的设备上。所述至少一个基于处理器的控制器在使用中针对所述一次或多次迭代中的每一次:致使由所述至少一个基于处理器的后处理设备对所述多个样本执行至少一个后处理操作以产生一组后处理结果;至少部分地基于所述一组后处理结果来判定是否修改所述问题;并且在至少部分地基于所述一组后处理结果确定修改所述问题之后,致使所述问题被修改并且发起另一次迭代。
响应于确定所述结果满足确定的满足条件和/或所述迭代次数等于确定的极限,所述至少一个基于处理器的控制器可以致使针对所述问题停止所述迭代。
在所述计算系统的一些实现方式中,执行所述启发式优化器的所述至少一个处理器是量子处理器。所述至少一个基于非量子后处理处理器的设备可以是以下各项中的至少一项:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、现场可编程门阵列fpga)、以及专用集成电路(asic)。所述计算系统可以进一步包括至少一个数字处理器,所述至少一个基于处理器的控制器致使所述至少一个数字处理器执行以下各项中的至少一项:多数表决后处理操作、贪婪下降后处理操作、变量钳制后处理操作、变量分支后处理操作、或局部场表决后处理操作。所述计算系统可以包括通信地耦合到所述量子处理器上的服务器(例如,服务器硬件),其中所述基于处理器的控制器在使用中致使所述服务器将来自所述一组后处理结果中的一个或多个结果发送给用户。所述至少一个启发式优化器可以包括:第一优化器,所述计算系统的所述至少一个基于处理器的控制器致使所述第一优化器在第一迭代时优化所述问题;以及不同于所述第一启发式优化器的第二启发式优化器,所述计算系统的所述至少一个基于处理器的控制器致使所述第二启发式优化器在第二迭代时优化所述问题。所述计算系统可以包括多个硬件设备,所述至少一个基于处理器的控制器选择所述多个硬件设备中的一个来执行启发式优化。
在上述计算系统的一些实施例中,所述至少一个基于处理器的控制器在使用中针对所述一次或多次迭代中的至少一次致使:所述由所述至少一个基于处理器的后处理设备对所述多个样本执行所述至少一个后处理操作以产生一组后处理结果是与所述由至少一个启发式优化器产生紧随其后的多个样本在时间上至少部分重叠地发生的。
一种计算系统可以被概述为包括:至少一个基于处理器的设备,所述至少一个基于处理器的设备包括:至少一个处理器、以及通信地耦合到所述至少一个处理器上的至少一个非瞬态处理器可读介质。所述至少一个非瞬态处理器可读介质存储了处理器可执行指令或数据中的至少一者。所述至少一个非瞬态处理器可读介质在被所述至少一个处理器执行时致使所述至少一个处理器针对多个问题中的每一个:由基于处理器的设备来执行对所述问题的预处理评定;由所述基于处理器的设备至少部分地基于对所述问题的所述预处理评定从多个启发式优化器中选择至少一个启发式优化器;并且致使由所述至少一个所选启发式优化器来优化所述问题。在一些实现方式中,所述至少一个处理器是量子处理器。所述至少一个基于处理器的设备可以是基于非量子处理器的设备。所述基于非量子处理器的设备可以是以下各项中的至少一项:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、现场可编程门阵列fpga)、以及专用集成电路(asic)。
一种在计算系统中的操作方法可以被概述为包括:针对多个问题中的每一个并且针对通过至少一个处理器所执行的至少一个启发式优化器作为所述多个问题中的相应计算资源的结果所产生的多个样本中的每一个:通过至少一个控制器致使经由至少一个基于非量子处理器的后处理设备对相应样本执行至少一个后处理操作;至少部分地基于所述后处理的结果来判定是否修改所述原始问题;针对至少一个问题的至少一次迭代,修改所述问题;并且致使由这些启发式优化器中的一个来优化所述修改后的问题。
至少部分地基于所述后处理的结果来判定是否修改所述原始问题可以包括:判定是否达到满足条件。
所述在计算系统中的操作方法可以进一步包括:判定是否已达到修改所述问题的最大迭代次数;并且响应于确定已达到所述最大迭代次数而停止修改所述问题。
所述启发式优化器可以被量子处理器执行、并且可以进一步包括接收经由所述量子处理器所执行的启发式优化所产生的样本。所述启发式优化器可以经由至少一个选自以下各项中的至少一项的非量子处理器被执行:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且可以进一步包括接收经由所述微处理器、dsp、gpu、或fpga中的所述至少一者所执行的启发式优化所产生的样本。致使由至少一个基于非量子处理器的设备执行至少一个后处理操作可以包括致使通过以下各项中的至少一项来执行所述至少一个后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga)。致使由所述至少一个基于处理器的设备执行至少一个后处理操作可以包括致使通过至少一个数字处理器来执行以下各项中的至少一项:多数表决后处理操作、贪婪下降后处理操作、变量钳制后处理操作、变量分支后处理操作、或局部场表决后处理操作。所述计算系统可以包括执行所述启发式优化器的所述至少一个处理器、并且可以进一步包括通过所述至少一个处理器对相应问题执行所述启发式优化。所述计算系统可以包括至少一个采用选自以下各项中的至少一项的非量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且可以进一步包括通过所述至少一个非量子处理器对相应问题执行启发式优化。所述计算系统可以包括处于至少一个量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器,并且可以进一步包括通过所述至少一个量子处理器对相应问题执行所述启发式优化。致使通过这些启发式优化器中的一个来优化所述修改后的问题可以包括:使用这些启发式优化器中的第一个来优化相应问题并且使用这些启发式优化器中的第二个来优化所述修改后的问题,这些启发式优化器中的第二个不同于这些启发式优化器中的第一个。
所述在计算系统中的操作方法可以进一步包括:在对于所述问题中的至少一个问题的多次迭代之间在这些启发式优化器之间进行切换。
所述在计算系统中的操作方法可以进一步包括:由所述计算系统的至少一个部件在多种类型的硬件设备之间进行自主选择以用于执行所述启发式优化。
所述在计算系统中的操作方法可以进一步包括:由所述计算系统的至少一个部件在多种类型的启发式优化算法之间进行自主选择以用于执行所述启发式优化。
一种计算系统可以被概述为包括:至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到至少一个启发式优化器上,所述至少一个启发式优化器在操作中产生多个样本作为问题的可能解,所述至少一个基于处理器的控制器操作性地耦合到至少一个基于处理器的后处理设备上,所述至少一个基于处理器的控制器在使用中:针对多个问题中的每一个并且针对由至少一个处理器所执行的启发式优化器作为所述多个问题中的相应计算资源的可能解所产生的多个样本中的每一个:致使由所述至少一个基于处理器的后处理设备对相应样本执行至少一个后处理操作;至少部分地基于所述后处理的结果来判定是否修改所述原始问题;针对至少一个问题的至少一次迭代,修改所述问题;并且致使由这些启发式优化器中的一个来优化所述修改后的问题。
所述至少一个基于处理器的控制器可以至少部分地基于所述后处理的结果来判定是否达到了满足条件,以便判定是否修改所述原始问题。所述至少一个基于处理器的控制器可以进一步:判定是否已达到修改所述问题的最大迭代次数;并且响应于已达到所述最大迭代次数来对相应问题停止迭代。所述启发式优化器可以被量子处理器执行,并且所述至少一个基于处理器的控制器可以进一步包括接收经由所述量子处理器所执行的启发式优化所产生的样本。所述启发式优化器可以经由至少一个选自以下各项中的至少一项的非量子处理器被执行:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且所述至少一个基于处理器的控制器可以进一步包括接收经由所述微处理器、dsp、gpu、或fpga中的所述至少一者所执行的启发式优化所产生的样本。所述至少一个基于处理器的控制器可以致使通过以下各项中的至少一项来执行所述至少一个后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga)。所述至少一个基于处理器的设备可以致使通过至少一个数字处理器来执行以下各项中的至少一项:多数表决后处理操作、贪婪下降后处理操作、变量钳制后处理操作、变量分支后处理操作、或局部场表决后处理操作。所述计算系统可以包括执行所述启发式优化器的所述至少一个处理器,并且所述至少一个处理器可以通过所述至少一个处理器对相应问题执行所述启发式优化。所述计算系统可以包括至少一个采用选自以下各项中的至少一项的非量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且所述至少一个非量子处理器可以对相应问题执行启发式优化。所述计算系统可以包括处于至少一个量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器。所述计算系统的所述至少一个基于处理器的控制器可以致使这些启发式优化器中的第一个来优化相应问题并且致使这些启发式优化器中的第二个来优化所述修改后的问题,这些启发式优化器中的第二个不同于这些启发式优化器中的第一个。所述计算系统的所述至少一个基于处理器的控制器可以进一步在对于所述问题中的至少一个问题的多次迭代之间在这些启发式优化器之间进行切换。所述计算系统的至少一个基于处理器的控制器可以在多种类型的硬件设备之间进行自主选择以用于执行所述启发式优化。所述计算系统的至少一个基于处理器的控制器可以在多种类型的启发式优化算法之间进行自主选择以用于执行所述启发式优化。
使用包括含有多个量子位的量子处理器的模拟计算机以及相关联设备来求解问题的方法、系统、以及计算机可读指令可以被概述为包括:以实施了初始化哈密尔顿算子的第一配置来初始化所述量子处理器;使所述量子处理器演算而持续时间t,因此用近似于问题哈密尔顿算子的第二配置来描述其;并且读出所述量子处理器的状态;将所述状态存储在计算机可读介质中。
一种在计算系统中的操作方法,所述计算系统包括至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到在操作中产生多批样本的至少一个量子处理器上、并且操作性地耦合到至少一个基于处理器的后处理设备上,所述操作方法可以被概述为包括:对于从1到数字n的多次迭代i,其中n是大于2的整数:确定通过至少一个量子处理器产生的第(i+1)批样本的产生的时机;并且致使通过所述至少一个基于处理器的后处理设备对第i批样本执行至少一个后处理操作,其中所述对第i批样本的至少一个后处理操作是与针对在第一迭代与最后迭代之间(不包含所述第一迭代和最后迭代)的迭代来产生第(i+1)批样本在时间上至少部分重叠地发生的。
致使执行所述至少一个后处理操作可以包括:致使所述执行所述至少一个后处理操作的时机使得,所述对第i批样本的至少一个后处理操作并未在时间上延伸超过针对在第一迭代与最后迭代之间(不包含所述第一迭代和最后迭代)的迭代来产生第(i+1)批样本。确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机可以包括:通过所述基于处理器的控制器确定所述至少一个量子处理器已产生了所述第(i+1)批样本。确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机可以包括:通过所述基于处理器的控制器确定所述至少一个量子处理器已产生了所述第i批样本。
所述在计算系统中的操作方法,所述计算系统包括至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到在操作中产生多批样本的至少一个量子处理器上、并且操作性地耦合到至少一个基于处理器的后处理设备上,所述操作方法可以进一步包括:对于从1到数字n的所述多次迭代i,通过所述基于处理器的控制器接收由至少一个量子处理器产生的第i批样本;并且至少部分地基于接收到由所述至少一个量子处理器产生的第i批样本而确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机。
确定通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机可以包括:至少部分地基于通过所述计算系统的除所述基于处理器的控制器之外的至少一个部件接收到所述第i批样本,确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机。确定通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机可以包括:至少部分地基于发出了致使通过所述至少一个量子处理器来产生第(i+1)批样本的至少一个信号,确定所述通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。确定通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机可以包括:至少部分地基于发出了致使通过所述至少一个量子处理器来产生第i批样本的至少一个信号、以及通过所述至少一个量子处理器来产生所述第i批样本所需要的时间量,确定所述通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。确定通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机可以包括:确定与从所述至少一个量子处理器读出多个值所需要的时间与对于所请求的样本数量进行退火所需要的总时间之和成比例的时间周期。致使通过至少一个基于处理器的后处理设备对第i批样本执行至少一个后处理操作可以包括:发送致使通过至少一个基于处理器的设备对所述第i批样本进行后处理的至少一个信号。
所述在计算系统中的操作方法,所述计算系统包括至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到在操作中产生多批样本的至少一个量子处理器上、并且操作性地耦合到至少一个基于处理器的后处理设备上,所述操作方法可以进一步包括:对于从2到n-1的多次迭代i,将执行所述至少一个后处理操作的时间限制为不大于从所述量子处理器产生所述第(i+1)批样本所需要的时间。
所述在计算系统中的操作方法,所述计算系统包括至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到在操作中产生多批样本的至少一个量子处理器上、并且操作性地耦合到至少一个基于处理器的后处理设备上,所述操作方法可以进一步包括:确定从所述量子处理器接收一批样本所需要的时间;并且确定在所确定的时间内可执行的一组后处理操作。
致使通过所述至少一个基于处理器的设备执行至少一个后处理操作可以包括致使通过至少一个数字处理器来执行以下各项中的至少一项:量子位链多数表决后处理操作、局部搜索寻找局部最小值后处理操作、或在固定温度的后处理操作中的马尔可夫链蒙特卡罗模拟。致使通过至少一个基于处理器的设备执行至少一个后处理操作可以包括致使通过以下各项中的至少一项来执行所述至少一个后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga)。所述至少一个控制器可以包括通信地耦合到所述量子处理器上的服务器。
所述在计算系统中的操作方法,所述计算系统包括至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到在操作中产生多批样本的至少一个量子处理器上、并且操作性地耦合到至少一个基于处理器的后处理设备上,所述操作方法可以进一步包括:经由所述服务器将多个经后处理的样本发送给用户,其中所述进行所述后处理可以在将所述经后处理的样本发送给用户之前进行。
所述多次迭代可以对于多个问题中的每一个问题的相应问题执行并且可以进一步包括:针对所述多个问题中的每一个问题,至少部分地基于在针对相应问题的相应迭代过程中产生的多批样本中的至少一些来确定相应结果。对于所述多个问题中的第一问题的数目n可以不同于对于所述多个问题中的第二问题的数目n。所述至少一个基于处理器的控制器可以包括通信地耦合到所述量子处理器上的服务器(例如,服务器硬件)并且可以进一步包括经由所述服务器将多个结果发送给用户。
一种计算系统可以被概述为包括:至少一个基于处理器的控制器,所述至少一个基于处理器的控制器通信地耦合到至少一个量子处理器上,所述至少一个量子处理器在操作中产生多批样本,所述至少一个基于处理器的控制器操作性地耦合到至少一个基于处理器的后处理设备上,所述基于处理器的控制器在使用中将通过所述至少一个基于处理器的后处理设备对所产生的多批样本执行的至少一个后处理操作、与通过至少一个量子处理器产生相继多批样本以时间重叠的方式进行协调。
对于从1到数字n的多次迭代i,其中n是大于2的整数,所述基于处理器的控制器可以:确定通过至少一个量子处理器产生的第(i+1)批样本的产生的时机;并且致使通过所述至少一个基于处理器的后处理设备对第i批样本执行所述至少一个后处理操作,其中所述对第i批样本的至少一个后处理操作可以与针对在第一迭代与最后迭代之间(不包含所述第一迭代和最后迭代)的迭代来产生第(i+1)批样本在时间上至少部分重叠地发生。所述基于处理器的控制器可以:致使所述执行所述至少一个后处理操作的时机使得,所述对第i批样本的至少一个后处理操作并未在时间上延伸超过针对在第一迭代与最后迭代之间(不包含所述第一迭代和最后迭代)的迭代来产生第(i+1)批样本。所述基于处理器的控制器可以确定所述至少一个量子处理器已产生了所述第(i+1)批样本,以便确定通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。所述基于处理器的控制器可以确定所述至少一个量子处理器已产生了所述第i批样本,以便确定通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。对于从1到数字n的所述多次迭代i,所述基于处理器的控制器可以进一步:接收通过至少一个量子处理器产生的第i批样本;并且至少部分地基于接收到所述第i批样本而确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机。所述基于处理器的控制器可以至少部分地基于通过所述计算系统的不同于所述基于处理器的控制器的部件接收到所述第i批样本,确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机。所述基于处理器的控制器可以至少部分地基于发出了可以致使通过所述至少一个量子处理器来产生第(i+1)批样本的至少一个信号,确定所述通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。所述基于处理器的控制器可以至少部分地基于发出了致使通过所述至少一个量子处理器来产生第i批样本的至少一个信号、以及通过所述至少一个量子处理器来产生所述第i批样本所需要的时间量,确定所述通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。所述基于处理器的控制器可以发送致使通过至少一个基于处理器的设备对第i批样本进行后处理的至少一个信号,以便致使通过至少一个基于处理器的后处理设备对所述第i批样本执行所述至少一个后处理操作。所述基于处理器的控制器可以确定与从所述至少一个量子处理器读出多个值所需要的时间与对于所请求的样本数量进行退火所需要的总时间之和成比例的时间周期,以便确定通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。对于从2到n-1的所述多次迭代i,所述基于处理器的控制器可以进一步:将执行所述至少一个后处理操作的时间限制为不大于从所述量子处理器接收一批样本所需要的时间。所述基于处理器的控制器可以进一步:确定从所述量子处理器接收一批样本所需要的时间;并且确定在所确定的时间内可执行的一组后处理操作。所述基于处理器的控制器可以致使通过以下各项中的至少一项来执行所述至少一个后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga)。所述至少一个控制器可以包括通信地耦合到所述量子处理器上的服务器、并且可以进一步将多个经后处理的样本发送给用户,其中进行所述后处理是在这些经后处理的样本被发送给用户之前进行的。所述多次迭代可以对于多个问题中的每一个问题的相应问题执行,并且至少一个基于处理器的控制器可以进一步包括:针对所述多个问题中的每一个问题,至少部分地基于在针对相应问题的相应迭代过程中产生的多批样本中的至少一些来确定相应结果。对于所述多个问题中的第一问题的数目n可以不同于对于所述多个问题中的第二问题的数目n。所述至少一个基于处理器的控制器可以包括通信地耦合到所述量子处理器上的服务器,并且所述于处理器的控制器可以进一步经由所述服务器将多个结果发送给用户。
一种在计算系统中的操作方法可以被概述为包括:针对多个问题中的每一个问题,由基于处理器的设备来执行所述问题的预处理评定和/或评估;由所述基于处理器的设备至少部分地基于所述问题的预处理评定和/或评估从多个启发式优化器中选择至少一个启发式优化器。并且致使通过所述至少一个所选启发式优化器来优化所述问题。
所述方法可以进一步包括:接收所述问题;确定所述问题的格式;并且判定所述问题的所述确定的格式是否为受支持格式。
所述在计算系统中的操作方法可以进一步包括:如果所述问题的所述确定的格式不被支持则拒绝所述问题;并且提供拒绝所述问题的通知。
所述在计算系统中的操作方法可以进一步包括:响应于所述问题的格式受支持,产生所述问题的多个表示;针对所述问题的表示中的每一个表示,从所述问题中提取多个特征;至少部分地基于所述提取的特征来评定和/或评估多个求解器中的每一个;基于通过所述基于处理器的设备进行的所述评定和/或评估来选择一个或多个求解器;并且致使所述所选的一个或多个求解器对所述问题进行操作。
基于通过所述基于处理器的设备进行的所述评定和/或评估来选择一个或多个求解器可以包括:基于通过所述基于处理器的设备进行的所述评定和/或评估、在没有人类交互的情况下通过系统硬件来自主选择一个或多个求解器。至少部分地基于所述提取的特征来评定和/或评估多个求解器中的每一个可以包括:预测所述多个求解器的每一个求解器在使用所述提取的特征返回所述问题的最优解时将会多么成功。致使所述所选的一个或多个求解器对所述问题进行操作可以包括将所述问题发送至所选的求解器。可以选择至少两个求解器,所述两个求解器彼此不同,并且可以进一步包括:将来自所述所选的至少两个求解器中的每一个的结果进行比较;并且至少部分地基于所述比较来确定最佳解。
所述在计算系统中的操作方法可以进一步包括:经由网络接口返回所确定的最佳解给用户。
所述在计算系统中的操作方法可以进一步包括:针对所述所选的求解器中的每一个,将所述问题分解成多个部分;将所述部分分配给多个计算资源中的相应计算资源;并且基于来自所述部分的结果产生相应求解器对相应问题的最终结果。
基于来自所述部分的结果产生相应求解器对相应问题的最终结果可以包括:收集相应问题的每个部分的结果;并且将所收集的相应问题的每个部分的结果进行组合以产生相应求解器对相应问题的最终结果。
将所述部分分配给多个计算资源中的相应计算资源可以包括:基于所述问题的相应部分所要求的处理类型,将所述部分分配给多个计算资源的相应计算资源。可以选择至少两个求解器,所述两个求解器彼此不同,并且可以进一步包括:针对所述所选的至少两个求解器中的每一个将相应求解器对相应问题的最终结果进行比较;并且至少部分地基于所述比较来确定最佳解。
所述在计算系统中的操作方法可以进一步包括:经由网络接口返回所确定的最佳解给用户。
从多个启发式优化器中选择至少一个启发式优化器可以包括:通过系统硬件、至少部分地基于所述问题的评定和/或评估、在没有人类交互的情况下从多个启发式优化器中自主地选择至少一个启发式优化器。从多个启发式优化器中自主选择一个启发式优化器可以包括:至少部分地基于所述问题的评定和/或评估、在不参考除相应问题和问题类型之外的任何用户输入的情况下自主地选择至少两个彼此不同的启发式优化器。
所述在计算系统中的操作方法可以进一步包括:致使通过至少一个基于处理器的后处理设备对于从对所述问题执行的所述启发式优化得到的多个样本执行至少一个后处理操作。
致使执行至少一个后处理操作可以包括:致使通过所述至少一个基于非量子处理器的设备来执行所述至少一个后处理操作。致使通过至少一个基于非量子处理器的设备执行至少一个后处理操作可以包括:致使由选自以下各项中的至少一项来执行所述至少一个后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且可以进一步包括接收经由所述微处理器、dsp、gpu、或fpga中的所述至少一者所执行的启发式优化所产生的样本。所述计算系统可以包括以下各项中的至少一项:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且致使通过至少一个基于处理器的设备来执行至少一个后处理操作可以包括:致使通过所述微处理器、dsp、gpu、或fpga中的至少一者来执行所述至少一个后处理操作。致使通过所述至少一个基于处理器的设备执行至少一个后处理操作可以包括致使通过至少一个数字处理器来执行以下各项中的至少一项:量子位链多数表决后处理操作、局部搜索寻找局部最优值后处理操作、或在固定温度的后处理操作中的马尔可夫链蒙特卡罗模拟。所述计算系统可以包括执行所述启发式优化器的所述至少一个处理器、并且可以进一步包括通过所述至少一个处理器对相应问题执行所述启发式优化。所述计算系统可以包括至少一个采用选自以下各项中的至少一项的非量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且可以进一步包括通过所述至少一个非量子处理器对相应问题执行启发式优化。所述计算系统可以包括处于至少一个量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器,并且可以进一步包括通过所述至少一个量子处理器对相应问题执行所述启发式优化。
一种计算系统可以被概述为包括:针对多个问题中的每一个问题,由基于处理器的设备来执行所述问题的预处理评定和/或评估;由所述基于处理器的设备至少部分地基于所述问题的预处理评定和/或评估从多个启发式优化器中选择至少一个启发式优化器。并且致使通过所述至少一个所选启发式优化器来优化所述问题。
所述基于处理器的设备可以进一步:接收所述问题;确定所述问题的格式;并且确定所述问题的所述确定的格式是否为受支持格式。所述基于处理器的设备可以进一步:如果所述问题的所述确定的格式不被支持则拒绝所述问题;并且通过网络提供拒绝所述问题的通知。所述基于处理器的设备可以进一步:响应于所述问题的格式受支持,产生所述问题的多个表示;针对所述问题的表示中的每一个表示,从所述问题中提取多个特征;至少部分地基于所述提取的特征来评定和/或评估多个求解器中的每一个;基于通过所述基于处理器的设备进行的所述评定和/或评估来通过所述系统硬件自主地选择一个或多个求解器;并且致使所述所选的一个或多个求解器对所述问题进行操作。所述基于处理器的设备可以基于通过所述基于处理器的设备进行的所述评定和/或评估、在没有人类交互的情况下自主地选择所述一个或多个求解器。所述基于处理器的设备可以至少部分地基于所述提取的特征、在没有人类交互的情况下自主地预测所述多个求解器的每一个求解器在使用所述提取的特征返回所述问题的最优解时将会多么成功,以便评定和/或评估多个求解器中的每一个。所述基于处理器的设备可以将所述问题发送至所选的求解器,以便致使所选的一个或多个求解器对所述问题进行操作。可以选择至少两个求解器,所述两个求解器彼此不同,并且所述基于处理器的设备可以进一步:将来自所述所选的至少两个求解器中的每一个的结果进行比较;并且至少部分地基于所述比较来确定最佳解。所述基于处理器的设备可以进一步经由网络接口将所确定的最佳解返回至用户。所述基于处理器的设备可以进一步:针对所述所选的求解器中的每一个,将所述问题分解成多个部分;将所述部分分配给多个计算资源中的相应计算资源;并且基于来自所述部分的结果产生相应求解器对相应问题的最终结果,这可以在没有人类交互的情况下自主地进行。为了基于来自所述部分的结果产生相应求解器对相应问题的最终结果,所述基于处理器的设备可以:收集相应问题的每个部分的结果;并且将所收集的相应问题的每个部分的结果进行组合以产生相应求解器对相应问题的最终结果。所述基于处理器的设备可以:基于所述问题的相应部分所要求的处理类型,将所述部分分配给多个计算资源的相应计算资源。可以选择至少两个求解器,所述两个求解器彼此不同,并且所述基于处理器的设备可以进一步:针对所述所选的至少两个求解器中的每一个将每一个相应求解器对相应问题的最终结果进行比较;并且至少部分地基于所述比较来确定最佳解。所述基于处理器的设备可以进一步经由网络接口将所确定的最佳解返回至用户。所述基于处理器的设备可以:至少部分地基于所述问题的评定和/或评估、在没有人类交互的情况下从多个启发式优化器中自主地选择所述至少一个启发式优化器。所述基于处理器的设备可以:至少部分地基于所述问题的评定和/或评估、在不参考除相应问题和问题类型之外的任何用户输入的情况下自主地选择至少两个彼此不同的启发式优化器。所述基于处理器的设备可以进一步:通过至少一个基于处理器的后处理设备对于从对所述问题执行的所述启发式优化得到的多个样本执行至少一个后处理操作。所述基于处理器的设备可以:致使通过至少一个基于非量子处理器的设备执行所述至少一个后处理操作。所述基于处理器的设备可以:致使由选自以下各项中的至少一项来执行所述至少一个后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且可以进一步接收经由所述微处理器、dsp、gpu、或fpga中的所述至少一者所执行的启发式优化所产生的样本。所述计算系统可以包括以下各项中的至少一项:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且可以致使所述微处理器、dsp、gpu、或fpga中的至少一者执行所述至少一个后处理操作。所述至少一个基于处理器的设备可以致使通过至少一个数字处理器来执行以下各项中的至少一项:量子位链多数表决后处理操作、局部搜索寻找局部最优值后处理操作、或在固定温度的后处理操作中的马尔可夫链蒙特卡罗模拟。所述计算系统可以包括执行所述启发式优化器的所述至少一个处理器。所述计算系统可以包括至少一个处于选自以下各项中的至少一项的非量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),并且可以进一步包括通过所述至少一个非量子处理器对相应问题执行启发式优化。所述计算系统可以包括处于至少一个量子处理器的形式的、执行所述启发式优化器的所述至少一个处理器。
附图视图的简要说明
在这些附图中,相同的参考号标识相似的元件或者动作。附图中元件的尺寸和相对位置不一定是按比例绘制的。例如,不同元件的形状以及角度不一定按比例绘制,并且这些元件中的一些被任意地放大和定位以提高附图的易读性。另外,所绘出的这些元件的特定形状不一定旨在传递与这些特定元件的实际形状有关的任何信息,而只是为了方便在图中识别而选取的。
图1a和1b是根据当前描述的系统、设备、物品和方法,用户可以在其中经由一个或多个网络来访问系统的一种环境的示意图,展示了不同的硬件结构以及它们之间的互连。
图2是根据当前描述的系统、设备、物品和方法在图1a和1b中实施的预处理、处理、后处理、以及可选的辅助处理之间的关系的高层次示意图。
图3a和3b是根据当前描述的系统、设备、物品和方法显示了图1a和1b的系统所实施的处理器可读指令、过程、和抽象层(例如工作管理器指令、资源管理器指令、求解器指令、预处理和后处理指令)的示意图。
图4是根据当前描述的系统、设备、物品和方法显示了在包含对于问题执行预处理、处理和后处理的一个或多个处理器的一种计算系统中的高层次操作方法的流程图。
图5是根据当前描述的系统、设备、物品和方法显示了包括自主选择启发式优化算法和硬件的一种在计算系统中的低层次操作方法的流程图,并且所述方法可以作为图4的方法的一部分执行。
图6是根据当前描述的系统、设备、物品和方法显示了包括确定何时停止迭代次数的一种在计算系统中的低层次操作方法的流程图,并且所述方法可以作为图4的方法的一部分执行。
图7是根据当前描述的系统、设备、物品和方法显示了包括通过一个或多个量子处理器执行处理的一种在计算系统中的高层次方法的流程图,并且所述方法例如可以作为图4的方法的一部分执行。
图8是根据当前描述的系统、设备、物品和方法显示了将执行后处理与处理操作进行协调或重叠的时机图。
图9是根据当前描述的系统、设备、物品和方法显示了用于将执行后处理与处理操作进行协调或重叠的一种在计算系统中的高层次操作方法的流程图。
图10是根据当前描述的系统、设备、物品和方法显示了用于将执行后处理与处理操作进行协调或重叠的一种在计算系统中的低层次操作方法的流程图,所述方法可以作为执行图9的方法的一部分被执行。
图11是根据当前描述的系统、设备、物品和方法显示了包括对问题进行预处理、处理和后处理(包括针对问题、基于有待求解的问题的特性或特征来评定或评估并且选择一个或多个启发式求解器)的一种在计算系统中的高层次操作方法的流程图。
图12是根据当前描述的系统、设备、物品和方法显示了一种在计算系统中的高层次操作方法的流程图,所述方法包括检查问题的格式是否受该计算系统的支持并且如果不被支持则拒绝所述问题或者如果被支持则产生所述问题的表示,并且所述方法可以作为图11的方法的一部分执行。
图13是根据当前描述的系统、设备、物品和方法显示了包括提取特征、评定或评估求解器、并且基于所述评定或评估来选择求解器的一种在计算系统中的低层次操作方法的流程图,并且所述方法可以作为图11的方法的一部分执行。
图14是根据当前描述的系统、设备、物品和方法显示了包括将两个或更多求解器的结果进行比较、确定并返回最佳解的一种在计算系统中的低层次操作方法的流程图,并且所述方法可以作为图11的方法的一部分执行。
图15是根据当前描述的系统、设备、物品和方法显示了包括将问题分解为多个部分、将这些部分分布到相应硬件资源、并且产生最终结果的一种在计算系统中的低层次操作方法的流程图,并且所述方法可以作为图11的方法的一部分执行。
图16是根据当前描述的系统、设备、物品和方法显示了包括收集来自被分解的问题的每个部分求解的结果、并且组合所收集的结果的一种在计算系统中的低层次操作方法的流程图,并且所述方法可以作为图15的方法的一部分执行。
详细说明
在以下说明中,包括了一些特定的细节来提供对不同的公开实施例的全面理解。然而,相关领域的技术人员将认识到,各实施例可以在不具有这些特定细节中的一个或多个的情况下实践,或者可以利用其他方法、部件、材料等来实践。在其他情形中,还没有详细示出或描述与数字处理器相关联的众所周知的结构,例如数字微处理器、数字信号处理器(dsp)、数字图形处理单元(gpu)、现场可编程门阵列(fpga);模拟或量子处理器,例如量子器件、耦合器件;以及相关联的控制系统,包括微处理器、处理器可读非瞬态存储介质、以及驱动电路,以避免不必要地妨碍对本发明的实施例的说明。
除非上下文要求,否则贯穿本说明书和所附权利要求书,单词“包括(comprise)”及其变体诸如“包括(comprises)”和“包括(comprising)”是在开放的、包含的意义上进行解释的,即“包括,但不限于(including,butnotlimitedto)”。
贯穿本说明书提及的“一个实施例”、或“一种实施例”或“另一个实施例”是指联系该实施例所说明的一个具体的指示特征、结构或特性包括在至少一个实施例中。由此,贯穿本说明书在不同的地方出现的短语“在一个实施例中”、或“在一种实施例中”“另一个实施例”并不必全部是指同一个实施例。此外,这些具体的特征、结构、或特性能够以任何适当的方式结合在一个或多个实施例中。
应当注意,如在本说明书和所附的权利要求书中所使用的,单数形式的“一个”、“一种”和“该”包括复数对象,除非内容另外明确指明。因此,例如,提及一个包括“一个量子处理器”的求解问题的系统包括一个单个的量子处理器或者两个或更多个量子处理器。还应注意,术语“或者”总体上所使用的意义包括“和/或”,除非内容另外明确指明。
在此给予的小标题仅为了方便起见,而并非解释这些实施例的范围或意义。
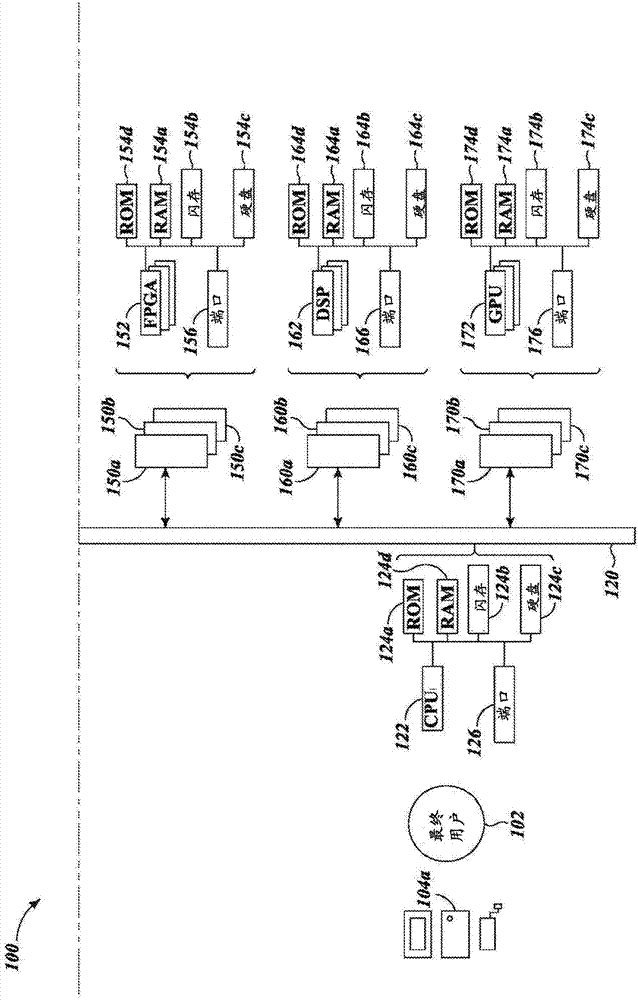
图1a和1b示出了根据当前描述的系统、设备、物品和方法的示例性的联网环境100,其中多个最终用户102(仅示出了一个)操作基于处理器的最终用户设备104a-104n(统称为104)以便经由一个或多个通信通道例如网络108来访问计算系统106。
这些基于处理器的最终用户设备104可以采取各种各样的形式,包括台式计算机或工作站104a、膝上型计算机104b、平板计算机(未示出)、笔记本计算机(未示出)、和/或智能电话(未示出)。
计算系统106可以包括基于处理器的前端设备,例如web服务器计算机系统110等服务器计算机系统,所述服务器计算机系统包括一个或多个处理器(未示出)、非瞬态处理器可读介质(未示出)并且执行处理器可执行服务器指令或软件。所述前端服务器或web服务器计算机系统110与外部世界进行通信。例如,web服务器计算机系统110提供了通过基于处理器的最终用户设备104提交有待求解的问题的接口(服务器应用编程接口或sapi)。而且例如,web服务器计算机系统110将问题求解的结果提供给基于处理器的最终用户设备104。web服务器计算机系统110可以提供用户友好型用户界面,例如基于web的用户界面、web门户或web服务接口。web服务器计算机系统110可以例如处理用户的账户,包括验证和/或授权来访问各个资源。web服务器计算机系统110还可以在计算系统106的其余部分与外部世界(例如,基于处理器的最终用户设备104)之间实施防火墙。
sapi接受更宽范围的问题,包括伪布尔优化问题、约束满足问题、抽样问题等等。最终用户可以例如指示所述求解是否应当确认最小值或者应当以玻尔兹曼概率进行抽样。sapi还支持任意连接性的未受约束的qubo。这接受具有与工作图不同的连接性的逻辑图。sapi还接受图形模型,例如在二进制取值变量上限定的无向图形模型的因子图描述。sapi可以允许描述用所述因子的范围和因子值的外延清单规定的因子。优选地针对约束满足问题(csp)向将输入映射到浮点值并且映射到布尔值的因子提供支持。sapi还接受二次分配问题(qap),因为许多实践问题涉及分配约束。sapi可以接受可满足性问题(sat),例如:k-sat、csp;或最大(加权)sat、相关的优化问题。这些类型的问题存在标准的dimacs格式。
所述计算系统106可以包括管理工作(即,提交的问题和问题求解结果)的工作管理器硬件112。所述工作管理器硬件112可以被实施为独立式计算系统,所述独立式计算系统可以包括一个或多个处理器114、处理器可读非瞬态存储介质116a-116d(示出了四个,统称为116)以及通信端口118a、118n(示出了两个,统称为118)。所述(多个)处理器114可以采取各种形式,例如一个或多个微处理器,每个微处理器具有一个或多个核或cpu、寄存器等。所述工作管理器硬件112可以包括易失性介质或存储器,例如静态随机存取存储器(sram)或动态随机存取存储器(dram)116a。所述工作管理器硬件112可以包括非易失性介质或存储器,例如只读存储器(rom)116d、闪存存储器116b、或基于盘的存储器例如硬磁盘、光盘116c、磁带盒等。本领域技术人员将了解的是,一些计算机架构合并了易失性存储器和非易失性存储器。例如,易失性存储器中的数据可以被缓存到非易失性存储器。或采用集成电路来提供非易失性存储器的固态盘中。一些计算机传统地将数据存储在盘存储器上。而且,传统地被认为是易失性的一些介质可以具有非易失性的形式,例如双串列式内侧模块的非易失性双串列式内侧模块变体。所述处理器可读非瞬态存储介质116存储了至少一组处理器可执行指令和/或数据(例如,工作管理器指令306,图3a和3b)以用于管理问题求解工作,所述指令和/或数据在被工作管理器硬件112执行时实施工作管理(图3a和3b)。
所述计算系统106可以包括资源管理器硬件120,所述资源管理器硬件管理用于通过多个求解器来求解问题的硬件资源(例如,处理器)。所述资源管理器硬件120可以被实施为独立式计算系统,所述独立式计算系统可以包括一个或多个处理器122,每个处理器具有一个或多个核、处理器可读非瞬态存储介质124a-124d(示出了四个,统称为124)以及一个或多个通信端口126。所述(多个)处理器122可以采取各种形式,例如一个或多个微处理器,每个微处理器具有一个或多个核或cpu、寄存器等。所述资源管理器硬件120可以包括非易失性介质或存储器,例如只读存储器(rom)124a、闪存存储器124b、或基于盘的存储器例如硬磁盘124c、光盘等。所述资源管理器硬件120可以包括易失性介质或存储器,例如静态随机存取存储器(sram)或动态随机存取存储器(dram)124d。所述处理器可读非瞬态存储介质124存储了至少一组处理器可执行指令和/或数据(例如,资源管理器指令324,图3a和3b),所述指令和/或数据在被所述资源管理器硬件120执行时实施资源管理器来管理硬件资源,例如下文马上阐述的各个非量子处理器系统和/或量子处理器系统和/或数字计算机系统和/或模拟计算机系统。所述资源管理器可以例如管理处理器资源(例如,(多个)量子处理器)的分派,以用于通过一个或多个求解器来求解提交的问题。
如上文指出的,所述计算系统106可以进一步包括多个求解器处理器系统,所述求解器处理器系统执行求解器指令或软件来实施多个求解器以便求解适当类型的问题(例如,qubo矩阵、可满足性(sat)问题、图形模型(gm)或二次分配问题(qap))。
所述求解器处理器系统可以例如包括一个或多个模拟计算机130a-130c(展示了三个,统称为130,仅详细示出了一个),包括一个或多个量子处理器。量子处理器系统130可以采取各种形式。典型地,量子处理器系统130包括由多个量子位132a和耦合器132b(例如,可调谐的zz-耦合器)的一个或多个量子处理器132,这些可控制来设定相应对的量子位132a之间的耦合强度从而在量子位之间提供成对的耦合。所述量子处理器系统10可以被实施来通过将所述系统在初始哈密尔顿算子所偏爱的初始状态下初始化并且将所述系统演算到问题哈密尔顿算子所偏爱的最终状态而物理地实现量子退火(qa)和/或绝热量子退火(aqc)。
所述量子处理器系统130典型地包括多个接口134,所述接口可操作来时不时地设定或建立所述量子位132a和耦合器132b的条件或参数、并且读出所述量子位132a的状态。所述接口134可以包括局部偏置接口,以用于向量子位132a提供可控的局部偏置(例如,可调谐的局部对角线偏置)。所述接口134各自可以由作为编程子系统和/或演算子系统的一部分的相应电感耦合结构实现。用于读出状态的接口可以例如采取dc-squid磁强计的形式。这样的编程子系统和/或演算子系统可以与量子处理器130是分开的,或者它可以被包含在本地(即,与量子处理器130在芯片上),如在例如美国专利7,876,248和8,035,540中描述的。
所述量子处理器系统130典型地各自包括被操作来配置所述量子处理器132的控制器136,例如数字计算机系统。所述量子处理器系统130典型地各自包括制冷系统138,所述制冷系统可操作来将所述量子处理器132的温度降低到位于或低于所述量子处理器132的各个元件(例如,量子位132a、耦合器132b)进行超导的点。超导量子计算机一般地在毫开尔文的温度下工作,并且通常在一种稀释制冷机中工作。稀释制冷器的实例包括oxfordinstrumentstriton400(oxfordinstrumentsplc,tubneywoods,abingdon,oxfordshire,uk)以及blueforsld400(blueforscryogenicsoyltd,arinatie10,helsinki,finland)。量子处理器的所有或一部分部件可以被容纳在稀释制冷器中。
在量子处理器系统130的操作中,接口134可以各自用于将通量信号耦合到量子位132a的相应复合约瑟夫逊结中,由此实现系统哈密尔顿算子中的隧道效应项(也称为δi项)。这种耦合提供了所述哈密尔顿算子的非对角线项((σx项),并且这些通量信号是“离域信号”的实例。所述接口134中的其他一些可以各自用于将通量信号耦合到量子位132a的相应量子位回路中,由此实现系统哈密尔顿算子中的局部偏置项(也称为hi项)。这种耦合提供了对角线项(σz项)。此外,一个或多个接口134可以用于将通量信号耦合到耦合器132b中,由此实现系统哈密尔顿算子中的(多个)ji,j项。这种耦合提供了对角线项(σziσzj项)。因此,遍布本说明书和所附权利要求书,术语“问题公式”以及“多个可编程参数的配置”用于提及例如经由例如接口134具体地指派超导量子处理器的系统哈密尔顿算子中的hi和jij项。
这些求解器处理器系统可以例如包括一个或多个非量子处理器系统。非量子处理器系统可以采取各种形式,在下面马上讨论其中的至少一些。
例如,这些非量子处理器系统可以包括一个或多个基于微处理器的系统140a-140c(展示了三个,统称为140,仅详细示出了一个)。典型地,基于微处理器的系统140将各自包括一个或多个微处理器142(示出了三个,在图3a和3b中仅绘出了一个)、处理器可读非瞬态存储介质144a-144d(示出了四个,统称为144)以及一个或多个通信端口146。所述一个或多个处理器142可以采取各种形式,例如一个或多个微处理器,每个微处理器具有一个或多个核或cpu以及相关联的寄存器、算术逻辑单元等。所述基于微处理器的系统140可以包括非易失性介质或存储器,例如只读存储器(rom)144d、闪存存储器144b、或基于盘的存储器例如硬磁盘144c、光盘等。所述基于微处理器的系统140可以包括易失性介质或存储器,例如静态随机存取存储器(sram)或动态随机存取存储器(dram)144a。所述处理器可读非瞬态存储介质144存储了至少一组处理器可执行指令和/或数据,所述指令和/或数据在被所述基于微处理器的系统142执行时实施基于微处理器的求解器来求解所提交的问题。
而且例如,这些非量子处理器系统可以包括一个或多个基于现场可编程门阵列(fpga)的系统150a-150c(展示了三个,统称为150,仅详细示出了一个)。典型地,基于fpga的系统150将各自包括一个或多个fpga152、处理器可读非瞬态存储介质154a-154d(示出了四个,统称为154)以及一个或多个通信端口156。这些fpga152可以采取各种形式,例如一个或多个fpga152。所述基于fpga的系统150可以包括非易失性介质或存储器,例如只读存储器(rom)154d、闪存存储器154b、或基于盘的存储器例如硬磁盘154c、光盘等。所述基于fpga的系统150可以包括易失性介质或存储器,例如静态随机存取存储器(sram)或动态随机存取存储器(dram)154d。所述处理器可读非瞬态存储介质154存储了至少一组处理器可执行指令和/或数据,所述指令和/或数据在被所述基于fpga的系统150执行时实施基于fpga的求解器来求解所提交的问题。
而且例如,这些非量子处理器系统可以包括一个或多个基于数字信号处理器的系统160a-150c(展示了三个,统称为160,仅详细示出了一个)。典型地,基于dsp的系统160将各自包括一个或多个dsp162、处理器可读非瞬态存储介质164a-164d(示出了四个,统称为160)以及一个或多个通信端口166。所述dsp162可以采取各种形式,例如一个或多个dsp,每个dsp具有一个或多个核或cpu、寄存器等。所述基于dsp的系统160可以包括非易失性介质或存储器,例如只读存储器(rom)164d、闪存存储器164b、或基于盘的存储器例如硬磁盘164c、光盘等。所述基于dsp的系统160可以包括易失性介质或存储器,例如静态随机存取存储器(sram)或动态随机存取存储器(dram)164a。所述处理器可读非瞬态存储介质164存储了至少一组处理器可执行指令和/或数据,所述指令和/或数据在被所述基于dsp的系统160执行时实施基于dsp的求解器来求解所提交的问题。
例如,这些非量子处理器系统可以包括一个或多个基于图形处理单元(gpu)的系统170a-170c(展示了三个,统称为170,仅详细示出了一个)。典型地,基于gpu的系统170将各自包括一个或多个gpu172、处理器可读非瞬态存储介质174a-174d(示出了四个,统称为174)以及通信端口176。所述gpu172可以采取各种形式,例如一个或多个gpu,每个gpu具有一个或多个核或cpu、寄存器等。所述基于gpu的系统170可以包括非易失性介质或存储器,例如只读存储器(rom)174d、闪存存储器174b、或基于盘的存储器例如硬磁盘174c、光盘等。所述基于gpu的系统170可以包括易失性介质或存储器,例如静态随机存取存储器(sram)或动态随机存取存储器(dram)174a。所述处理器可读非瞬态存储介质174存储了至少一组处理器可执行指令和/或数据,所述指令和/或数据在被所述基于gpu的系统170执行时实施基于gpu的求解器来求解所提交的问题。
微处理器提供相对较少的核,其中每个核具有大量的快速内存。微处理器在本文所讨论的这四种非量子技术中是在发展的意义上最灵活的平台。微处理器还具有本文所讨论的这四种非量子技术中最快的时钟速度以及最广的指令集,其包括向量操作。当前可获得的运行8核、具有3.1ghz的时钟速度的高性能微处理器的实例是由英特尔公司(intelcorporation)提供的xeonprocessore5-2687w。
dsp在本文所讨论的这四种非量子技术中在特性和能力方面最接近微处理器。dsp的主要优点是,与微处理器相比,其针对像乘法累加(mac)的特殊数字运算进行优化的先进的alu单元。运行8核、具有1.4ghz的时钟速度的高性能dsp的实例是由德州仪器公司(texasinstruments)提供的tms320c6678多核定点和浮点dsp处理器(multicorefixedandfloatingpointdspprocessor)。创建具有多个dsp的定制板典型地比创建使用微处理器的定制板更简单。最先进的dsp提供了简化任务管理和与其他设备的接口连接的内置功能。
gpu在单一单元中提供最大量的便宜核(例如,在由英伟达公司(nvidiacorporation)提供的可商购的geforcetitanz中多达超过5000个核)。gpu的时钟速度与dsp处理器可比(例如,在1ghz范围内)、但每个核的共有存储器的数量有限。gpu实施单指令多数据(simd)的架构,这致使所有的核在每个周期中运行相同的指令。因此,对于相同总量的工作而言,在少量并行工作之后要求一些串行工作的方法与完全并行的途径相比实现显著更低的性能。运行1536个核、时钟速度为1ghz的可商购gpu的实例是由英伟达公司(nvidia)提供的geforcegtx770。然而,nvidia强烈推荐使用teslagpu进行高性能计算。
fpga包括多个逻辑门、存储器块、以及可以通过编程来“连线”的dsp单元。fgpa提供了大量快速分布存储器和dsp单元。fgpa的时钟速度取决于所实施的电路、但典型地低于本文讨论的其他三种非量子技术。例如,在许多情况下约200mhz的时钟速度是合理的时钟速度。对于fpga可以被编程的次数具有相对小的限制(大致100,000次),因此要求在多种设计之间按需切换的应用应当利用多个fpga。当前可获得的高性能fpga的实施例是赛灵思公司(xilinx)的xc7vx485t,其具有大致五十万个逻辑单元和触发器、多于一千个36kb储存器块、以及2800个dsp单元。
图2示出了图1a和1b的计算系统的操作的各个方面之间的高层次关系200。
具体地,所述计算系统典型地通过一个或多个求解器、例如通过硬件资源执行的多个启发式优化器中的一个或多个来以求解所提交的问题204的形式执行处理202。
在准备对每个问题204执行所述处理202时,所述计算系统可以执行预处理206。如参照其他图(例如,图3a和3b)详细讨论的,预处理206可以例如包括格式检查、产生问题表示、求解器选择、和/或接口转换中的一项或多项。如参照其他图(例如,图3a和3b)详细讨论的,预处理206可以例如由多个不同的处理器或系统来执行、和/或由指令集中的多个不同的逻辑抽象来执行。例如,一些预处理206可以由执行工作管理器软件的工作管理器硬件来执行,而其他预处理可以由执行求解器特异性预处理指令的求解器硬件来执行。
在对每个问题204或其表示执行了所述处理202之后,所述计算系统可以执行后处理208。如参照其他图(例如,图3a和3b)详细讨论的,后处理208可以例如包括评估多个不同的样本或临时响应或答案210以便针对对问题执行的每次求解迭代来确定解、和/或评估不同的可能解以便确定所述问题204的最佳解212。在一些实现方式中,可以对样本进行加权。如参照其他图(例如,图3a和3b)详细讨论的,后处理208还可以包括至少部分地基于前一次处理的结果214来修改所述问题204以进行下一次处理迭代。在此背景下,所述问题包括状态。如参照其他图(例如,图3a和3b)详细讨论的,后处理208可以例如由多个不同的处理器或系统来执行、和/或由指令集中的多个不同的逻辑抽象来执行。例如,一些后处理208可以由执行工作管理器软件的工作管理器硬件来执行,而其他后处理208可以由执行求解器特异性预处理指令的求解器硬件来执行。
在一些实现方式中,所述计算系统可以评定不同求解器对不同类型的问题的表现,所述表现可以用于精细化或改进对于用于随后提交的问题的求解器的选择。在一些实现方式中,所述计算系统可以结合重要性抽样。
图3a和3b展示了根据当前描述的系统、设备、物品和方法的用于由所述计算系统100(图1a和1b)执行以便求解问题的不同的处理器可读指令集以及过程(统称为300),包括不同的抽象层。
可以通过例如服务器硬件110(图1a和1b))来执行服务器指令302以便实施服务器,例如web服务器。所述web服务器允许提交不同类型的问题、并且提供所提交问题的结果和/或解。所述web服务器可以通过预处理、处理和后处理来将所提交的问题304进行排队以便求解。
可以例如通过工作管理器硬件112(图1a和1b)来执行工作管理器指令集306以便实施工作管理器。所述工作管理器可以通过问题排队、通过预处理器和后处理来对所提交的问题执行工作管理。它还可以至少通过一个或多个求解器、依靠一个或多个求解器资源130、140、150、160、或170来对问题进行处理或对问题的表示进行处理(图1a和1b)。
所述工作管理器可以验证每个所提交问题的格式,从而判定所述问题是否适合通过所述计算系统来求解。所述工作管理器可以标识出每个所提交问题的(多个)最适合求解器。如之前解释的,所述工作管理器可以使用关于之前尝试基于问题类型或特征来选择将并行允许的求解器组合的信息。在一些情形中,所述工作管理器可以针对具体问题选择两个或更多求解器、并行运行所选的求解器并且返回答案。在所述工作管理器可以收集来自这些求解器的处理结果的情况下,所述工作管理器可以选择最佳答案。最佳答案可以是例如来自首先以令人满意的解结束的求解器的答案、或者是来自在固定时间内给出最佳或最接近的解的求解器的答案。此外,所述工作管理器可以切分工作并且在各个求解器之间进行高层次通信。
具体地,所述工作管理器指令306可以包括格式检查指令集308。所述格式检查指令集308对每个所提交问题执行预处理,从而分析所提交问题以便确定所提交问题是否是对于所述计算系统而言的适当问题类型。如果所提交问题不是对于所述计算系统而言的适当问题类型,则格式检查指令集308可以向例如经由web服务器指令302提交相应问题的最终用户102(图1a和1b)或最终用户设备104(图1a和1b)提供适当的通知。
所述工作管理器指令306可以包括多表示发生器指令集310。所述多表示发生器指令集310对每个所提交问题执行预处理,从而产生所提交问题的多个表示。
所述工作管理器指令306可以包括依赖于类型的任务调度程序指令集312。所述依赖于类型的任务调度程序指令集312致使向求解器发送所提交问题的所述各个表示以便求解。所述依赖于类型的任务调度程序指令集312可以例如针对每个所提交问题选择适当的一个或多个求解器,这些求解器是从多个可获得的求解器中选择。选择适当的求解器可以包括:选择特定求解器方法以及选择特定类型的硬件资源(例如,量子处理器130、微处理器140、fpga150、dsp160、gpu170(图1a和1b))以便执行所选的求解器方法。可以使用其他适合的硬件资源,例如专用集成电路(asic),以执行所选的求解器方法。
所述工作管理器指令306可以包括选择解指令集314。选择解指令集314针对每个所提交问题对于结果或解执行后处理,从而从返回的结果中产生一个或多个最佳结果。选择解指令集314可以采用各种技术来选择最佳解,这些技术是在此总体上讨论过的。例如,一种技术可以包括从对于具体问题执行的多个求解器迭代中选择中等解。
所述工作管理器指令306可以包括修改问题指令集316。所述修改问题指令集316可以基于对问题执行的前一次处理或求解迭代的结果或样本来修改所述问题。这样,所述修改问题指令集316可以被认为是后处理,因为来自前一次迭代的信息被用于将所述问题或所述问题的表示精细化、并且如图3a和3b中所示。所述修改问题指令集316也可以被认为是后处理,因为所述问题在被修改或重新表示以便通过一个或多个求解器来求解。将所述修改问题指令集316称作预处理或后处理不应被认为是限制性的。
所述工作管理器指令306可以可选地包括评定及改进选择指令集318。评定及改进选择指令集318可以采用不同的技术。这样可以例如改进随后选择用于随后提交的问题的求解器。这样,所述评定及改进选择指令集318可以被认为是后处理,因为来自前一次迭代的信息被用于将所述问题或所述问题的表示精细化、并且如图3a和3b中所示。将所述评定及改进选择指令集318称作预处理或后处理不应被认为是限制性的。
所述工作管理器可以进行繁重的计算工作(例如,进行评级以便预测求解器表现、产生所提交问题的多个表示等)。所述工作管理器执行的其他操作,例如关于求解器的预处理操作(例如,格式检查)以及关于求解器的后处理操作(例如,选择解或最佳解)与这些求解器执行的预处理和后处理操作相比趋向于更简单。
所述工作管理器306可以被认为是计算系统100的整个计算方案中的抽象层。因此,虽然在图3a和3b中将一些功能展示位是经由工作管理器306来执行的,但在一些实现方式中,这些功能也可以由另一个抽象层或另一组处理器可读指令来执行。因此,将功能或处理器可读指令集称作在工作管理器306内不应被认为是限制性的。
可以例如通过求解器硬件130、140、150、160、或170(图1a和1b)来执行接口转换指令集320。所述接口转换指令320可以特异于所选的(多个)求解器、并且可以将问题的表示转换成适合于所选的(多个)求解器的格式或形式。所述接口转换指令集320准备所述问题,以通过相应求解器来处理或求解。因此,将所述接口转换指令集320称作形成了计算系统100的预处理部分的一部分(图1a和1b)。
可以例如通过求解器硬件130、140、150、160、或170(图1a和1b)来执行求解器指令集322a-322d(统称为322),以便处理或求解经预处理的问题。如之前指出的,所述工作管理器指令306可以针对任何具体问题选择一个或多个特定求解器322。示例性求解器包括qubo求解器322a、可满足性求解器322b、图形模型求解器322c等322d。
不旨在进行限制,下文阐述了多种求解器方法和技术。计算系统100/300的求解器(即,被求解器硬件资源例如130、140、150、160、或170所执行的求解器指令322)可以实施这些求解器方法或技术中的任一种、多种、或所有。计算系统100/300可以通过在不同的求解器硬件平台上利用多个求解器硬件资源来运行给定的问题。这些求解器可以包括在不同平台上运行的子求解器,这些子求解器最终负责求解这些工作或问题。
给定了具体格式的问题时,计算系统100/300可以提供所述问题的替代的类型、格式或类别以便发起所述问题的求解。计算系统100/300可能能够求解各种不同类型或格式的问题。两种类型、格式或类别的问题是二次无约束二元优化(“qubo”)问题和可满足性(sat)问题。另一种类型、格式或类别的问题是图形模型(gm)问题。图形模型对于在所述问题的多个变量中存在的条件独立性进行编码,其中每个变量代表耦合在一起成为链的一组量子位。所述图形模型问题允许在组或链的层级上用于额外的技术或方法。
下文来讨论所述计算系统可以采用以求解qubo、sat和/或图形模型问题的多种技术。
全局平衡搜索(ges)
ges是与模拟退火方法或途径共享一些相似度的元启发式方法。所述ges方法累积关于搜索空间的紧凑的一组信息,以便产生用于要求启动解的各种技术(例如局部搜索或禁忌搜索)的有前途起始解。所述ges方法适用于许多离散的优化问题:qubo、max-sat、qap等并且在计算时间和解品质方面提供了现今最好的表现。所述ges方法可以自然扩展到用于并行计算,因为所述ges方法在解空间的离散区域中同时进行搜索。
标准模拟退火(sa)方法是一种无记忆优化途径,其中在解之间的过渡是独立于之前的搜索状态的。所述ges方法试图通过使用自适应存储器结构来收集关于被访问解的信息、使用这种知识来控制未来的过渡而减轻这个缺点。
sa方法的一个变体是提供与开采所述问题的能量形态中的特定区域的重要性相对应的权重。这样的途径,被称为“退火重要性抽样”,可以允许系统避免变成偏置到局部最优值并且因此执行更完全的搜索。
局部搜索的一个变体可以涉及使用由量子处理器硬件返回的样本来快速运行模拟退火。这个途径应当远好于纯经典途径,并且如果是通过将处理与后处理进行协调或重叠而实施,则应当采用沃霍尔(warhol)模拟退火的不大于两倍长,假定允许量子处理的运行时间不比所述经典方法长。在所述量子处理器硬件在所允许的时间内返回比受到沃霍尔模拟退火的可能的样本更多样本的情况下,可以使用具有最低能量的子集作为种子。
计算系统100/300可以采用通过一个或多个fpga或gpu进行的后处理来自动地固定量子处理硬件的解,因为这些硬件解是从所述量子处理器硬件读取的。优选的是这样的后处理不增加或不显著增加所述计算系统的工作周期。换言之,优选的是所述后处理比单一解读出花的时间更少。例如,利用当前的量子处理器,后处理时间应当为0.1ms或更少。未来的量子处理器的处理时间可能甚至更少。因此,可以采用其他后处理选项,例如通过横向汉明距离进行搜索、或通过能量贪婪地搜索。
当使用gpu时,对多个批次的矩阵-矩阵操作比对单一样本的矩阵-向量操作有效得多。因此,可能有利的是一次对整个抽样批次而不是一个样本接一个样本进行后处理。
迭代禁忌搜索(its)
所述its途径是多启动禁忌搜索方法,然而这些起始解不是随机产生的、而是以特定方式从找到的“好”解发生微扰。这种微扰确保了实施所述方法的硬件移动到解空间的不同区域、同时试图在解向量中保留“好”图案。
快速半定规划(sdp)
可以基于qubo的sdp公式产生近似。对原始qubo的半定松弛的对偶问题求解,并且接着使用一些简单的启发法来将所获得的(连续)解离散化。所述方法可以比常规sdp公式更快,然而不清楚这种途径与禁忌类型的方法相比可以多快。
吞噬、消化、整理启发法(ddt)
ddt途径采用贪婪启发阀,其中在每个步骤中基于某个指标来固定解向量的某些比特。一次可以固定不超过2个比特。一旦比特被固定,所述比特不能再次被翻转。因此,在ddt中对解的一组可能修改是在具有2号邻域的局部搜索方法中的可能修改的子集。ddt流程或方法挑选的每次移动对应于改进的解,然而所述改进的解不一定对应于所述邻域中的最佳解,因为没有考虑所有可能的移动。一旦进行移动,解的对应比特就永远变成“禁忌”,因此消除可能进行改进的移动的子集。
因此,ddt流程有可能产生与简单的局部搜索相比品质差的解,但这样的途径可以更快速地返回结果。在一些实现方式中,可以使用ddt来产生用于其他方法的快速初始解,即,比单纯的随机初始解更换的快速初始解。ddt途径有可能更适合大规模问题。
混合启发式方法(hma)
hma是基于与ges相似的原理。所述方法正常地由两个“层级”的操作或两种方法组成。被设计成用于强烈开采解空间的特定区域,采取常规的基于局部搜索的方法的形式(例如,禁忌搜索)。较高层级方法接收所述较低层级方法获得的信息并且接着指导并协调跨所述解空间的搜索努力的分布,例如尝试识别有前途区域、决定将开采这些有前途区域中的哪一个以及在什么程度上开采。所述较高层级方法从所述较高层级方法确定的解开始运行所述较低层级方法。所述较高层级方法维持保有关于hma方法在搜索过程中遇到的解的信息的自适应存储器结构。
在一些实现方式中,所述较高层级方法被实施为演算类型的技术。维持在搜索过程中找到的一组最佳离散解,并且通过将来自这个组的两个“目”解的分量进行组合来挑选用于较低层级方法的新的起始解。所述组合策略是通过路径-重新链接实施的。基于通过较低层级方法获得的新的解的“好”来评估这些解并且要么将其添加到这些解的精英集合中或者将其抛弃。可以通过将目标函数值与同所述精英集合中已经存在的解的差异性进行组合来限定解的“好”。可以简单地通过汉明距离、或更加创造性地通过考虑每个变量对目标函数值的贡献(例如,如果变量被翻转,目标值将改变多大)来限定两个解向量之间的距离。所述较低层级方法可以用禁忌搜索来实施。
低树宽大邻域局部搜索(ltlnls)
使用ltlnls技术可以接近稀疏qubo。从初始配置开始,识别具有低树宽的变量子集并精确地在这个子集中最小化。所述精确变量子集可以是动态的,具有通过超过其他交互来利于某些交互(例如,在任何树中尚未出现的交互)而确定的低树宽子图。
阻塞与坍缩
可以如以下文章中描述的来概括ltlnls途径:venugopal,deepak;gogate,vibhav,dynamicblockingandcollapsingforgibbssampling,在网页www.hlt.utdallas.edu/~vgogate/papers/uai13-2.pdf上可获得。这种途径应用了大邻域局部搜索(在该文章中称为“阻塞”)与消元法(在该文章中称为“坍缩”)的组合。例如,在二分图的情况下,由于自然出现两个分离集,通过分析法消除一半的变量。
并行回火
还可以包括并行回火的有效实现方式,并且所述有效实现方式可以包括适当的一组温度(通常包括一个较低温度和一个较高温度),将从所述一组温度中抽样多个链。这种途径允许在不同温度下进行的多个道次之间交换信息并且可以提供从对于所述问题的能量形态的更完整调查中获得的解。与并行回火相关的途径是模拟退火,其中考虑仅一个链。
预处理例程
在作者为gabrieltavares(2008)、从rutgerselectronicthesesanddissertations服务可获得的或通过搜索rutgers-lib-25771-pdf-1.pdf而经由web可获得的论文中提出的预处理流程使用了来自ddt和其他一遍方法的观念来将问题中的其中一些变量固定为0和1。这证明了最优的解必须具有具备那些值的变量。该途径还推导出了变量之间的关系(例如,等式)。这再次证明了在最优的解中必须存在这样的关系。该流程可以帮助减小所述问题的有效维度并且可以改进计算时间。
可以例如通过资源管理器硬件120(图1a和1b)来执行资源管理器指令集324以便实施资源管理器。所述资源管理器可以通过求解器硬件资源130、140、150、160、或170(图1a和1b)中的各个资源来对这些求解器的操作进行资源管理。例如,所述资源管理器可以将硬件资源进行划分和/或规划(例如,硬件资源上的计算时间)到这各个求解器322,因为过程326a-326e(在图3a和3b中展示了十五个,仅绘出了五个)在求解器硬件资源130、140、150、160、或170(图1a和1b)上执行。
可以例如通过求解器硬件130、140、150、160、或170(图1a和1b)来执行后处理指令集328a-328h(仅示出了八个,统称为328)。所述后处理指令328可以特异于所选的求解器、并且将对于所述问题或问题表示进行处理的样本或结果转换成解。所述后处理指令328在这些求解器进行的处理的输出(例如,样本,结果)上进行操作并且因此被称作形成了计算系统100的后处理部分的一部分。
对微小嵌入问题进行工作的启发式优化器通常返回是局部非最优的或不在代码空间内(即,没有实现嵌入链保真度)的所提出的解。出于这个原因,所述计算系统提供了采用“黑盒”启发式优化器和有效启发式后处理器的混合优化途径,所述有效启发式后处理器清除所述启发式优化器的结果并编码所述结果。采用术语“黑盒”来指示在许多情形中,最终用户不限于知道采用的是哪个特定的启发式优化器或所述启发式优化器如何操作。
执行后处理来确定未嵌入的问题的、对应于启发式优化器所返回的嵌入问题的提出解的解。执行这种后处理的最直截了当的方式是通过拒绝,例如通过拒绝所述启发式优化器返回的、不在嵌入映射的域内的任何样本(例如,具有断裂链的任何样本)。
另一种途径是多数表决。存在其他在计算方面偏移且有效的后处理方案。例如,为了对sat问题的解进行后处理,可以采用贪婪下降和局部搜索。变量钳制后处理操作也是可用的。
不旨在进行限制,下文阐述了多种后处理方法和技术。被计算系统100/300的求解器硬件资源130、140、150、160、和170执行的后处理指令328可以实施这些后处理方法或技术中的任一种、多种、或所有。计算系统100/300可以彼此并行地运行这些后处理方法中的两种或更多种。
多数表决
多数表决指令328a可以实施多数表决方法,例如其中选择最常见的样本或结果作为最佳解。替代地,多数表决方法可以涉及误差纠正,其目的是保留编码的子空间。例如,在铁磁性耦合的量子位的断裂链的情况下,假定重复编码,确定最常出现的值(“多数”)为正确值。这样的途径典型地是实施起来容易且快速的,然而当考虑的值的数量小时可能易于出现误差,从而导致不正确值被确定为正确的潜在高可能性。如同在花费有限努力的任何后处理策略的情况下,多数表决方法所提供的结果的品质可能过度受限。因此,可以单独地或者与多数表决方法相结合地采用其他后处理方法。
局部搜索
局部搜索指令328b可以实施多数表决与贪婪局部搜索的组合。在应用多数表决或另一种后处理方法之后,通过在未嵌入问题空间内使用具有任意复杂性的局部搜索方法(例如,禁忌搜索)、使用所述硬件的所提出解作为初始条件可以精细化所述结果。如果所述局部搜索方法的运行时间受限,则这可以在少量时间内提供显著改进。取决于具体的应用,所述局部搜索方法可以知道或不知道未嵌入问题的结果。例如,可以使用局部搜索sat求解器作为sat情形的后处理器,并且其对问题结构的了解可以使之比与上下文无关的求解器更有效。
马尔可夫链蒙特卡罗(mcmc)
所述mcmc指令集328c可以实施马尔可夫链蒙特卡罗方法。
在基于抽样的使用情况下,目标是以编程的伊辛能量函数来得出(经典的)玻尔兹曼样本。将大多数真实世界的问题映射到其拓扑结构实施二分图的量子处理器中通常要求增大芯片或量子处理器上的连接性。可以通过实施逻辑量子位或量子位“链”的概念来增大连接性,其中多个量子位强力耦合在一起并且代表单一问题变量、并且在此被称作逻辑量子位,因为任何给定的链中的多个物理量子位作为单一量子位进行操作或起作用,尽管单一物理量子位以其他方式可获得更高的连接性。例如,参见美国专利申请序列号14/339,289,在2014年7月23日提交,现在是美国专利申请公开2015-0032993。这些逻辑量子位或强力耦合的量子位链可以支持能量函数中的长程交互。然而典型地,我们对于使链断裂的激发态不感兴趣,因为链是为了在其拓扑结构实施二分图的量子处理器上实施而需要的人工产品。不像之前描述的优化实例,涉及mcmc的后处理试图通过在硬件样本上运行块吉布斯抽样来使样本接近更加玻尔兹曼的分布。这“清理”了硬件样本,由此使得进一步的下游处理更可能成功。
样本越近地重现玻尔兹曼分布,马尔可夫链蒙特卡罗方法就可以表现得越好。以极少的额外成本,可以获得接近玻尔兹曼分布的样本,从而使得后续处理更有效。这可以对于配分函数、基态数量、预期等等的mc近似获得更好的估计值。
另一种途径是运行基于从量子处理器(例如一个或多个量子处理器132(图1a和1b))返回的样本被初始化的扩展的mcmc链,从所述量子处理器得出多个样本。假定对同一问题运行多个量规,每个新的量规的编程时间是显著的,并且例如10^4个样本的退火和读出远不是瞬时的。在这个时间期间,gpu或fpga实现方式、例如gpu172或fpgas152(图1a和1b)可以运行从最后一批一万(104)个样本初始化的块吉布斯抽样。假定可以在完全提取下一量规的结果所需要的时间内运行多次迭代的块吉布斯抽样,对于所述硬件产生的每个样本,通过这种经典的mcmc产生的多个去相关的样本可以被返回给用户。
米特罗波利斯抽样
米特罗波利斯抽样(也称为米特罗波利斯-郝斯汀)是mcmc方法的实例。可以使用米特罗波利斯抽样来使得样本分布更靠近目标玻尔兹曼分布。在此情况下所述后处理操作使用原解作为以下过程的种子:所述过程随机开采解的邻域来创建更靠近目标分布的新样本。理想地,米特罗波利斯抽样之后的样本中值与参数化的玻尔兹曼分布的对应样本中值紧密匹配。
贪婪下降
在应用任何其他后处理方法来进一步精细化所述结果之后可以采用贪婪下降指令328d。所述贪婪下降方法迭代地进行比特翻转,这改进了目标或评估函数,直到不可能进行更多的比特翻转。关于经量子处理的解进行贪婪下降的方法例如包括用于进行以下内容的指令:
1.确定一组量子位,所述量子位在被单个地翻转时可以改进解;
2.以50%的概率随机翻转这些量子位中的每一个;
3.重复这个过程直到它会聚到或达到最大迭代次数(例如,量子位数量的五倍);
4.返回在该下降的过程中找到的最佳解。
局部场表决
局部场表决指令328h可以实施局部场表决方法,这是贪婪下降所包含的途径。如果硬件资源(例如,微处理器140、fpga150、dsp160、gpu170(图1a和1b))返回包含断裂链的解,其相邻链都是完好的,则在所述断裂链中的相应变量的最优值可以基于相邻链中的类似变量的固定值来决定。如果一些相邻链不是完好的,也可以使用这种途径。所述方法可以是迭代的。
变量钳制
变量钳制指令328e可以实现变量钳制方法。如果硬件资源(例如,微处理器140、fpga150、dsp160、gpu170(图1a和1b))返回涉及始终或几乎始终完好的链、并且超过其他配置而利于一种具体配置的解,我们可以在所述链中“钳制”变量并且重新运行所述问题(即,将一个或多个变量保持在具体值而允许其他变量适应这些固体变量)。这种途径可以重新运行多次,直到满足指标被满足。例如,所述系统可以:(1)对链中的成员应用局部h以便使之是不灵活的,或者(2)在伊辛问题中将其设定为常数、并且在与所钳制的变量耦合的那些链上将输入的j录入项转换成h录入项。所述系统可以重复这个途径,直到令人满意地决定所有的链。
变量分支
变量分支指令328f可以实施变量分支方法。如果硬件资源(例如,微处理器140、fpga150、dsp160、gpu170(图1a和1b))返回包含至少一个不是令人满意地决定的变量的解,我们可以对其进行分支,从而将问题拆分为两个子问题:第一子问题,其中假定变量采取具体的二进制值;以及第二子问题,其中假定变量采取与第一子问题中相反的二进制值。这种方法在某些情形下、包括所述方法仅对非常少量的变量进行分支的实现方式中是可行的。
拒绝
拒绝指令328g可以实施拒绝方法,例如,其中来自启发式优化器的、不在嵌入的映射的域内的任何样本(即,具有断裂链的任何样本)被拒绝或者不被进一步考虑。在例如由于断裂链而拒绝返回样本的概率高的情况下,可以采用如在此讨论的用于执行误差纠正或修补断裂链的替代性途径。
实例
一些示例性的可满足性(sat)问题包括:nae3sat(not-all-equal-3-sat)以及2in4sat(2-in-4-sat)。在给定了一系列子句而每个子句准确包含三个文字的情况下,nae3sat问题可以被定义为寻找一种指派,使得每个子句包含至少一个真文字以及至少一个假文字。在给定了一系列子句而每个子句准确包含四个文字的情况下,2in4sat问题可以被定义为寻找一种指派,使得每个子句准确包含两个真文字以及两个假文字。
nae3sat和2in4sat是可以嵌入量子处理器硬件上的两种类型的约束性满足(即,可满足性)问题。可以采用量子位链或逻辑量子位来将这样的问题嵌入其拓朴结构实施二分图的量子处理器中,但对于可以嵌入的问题的大小存在限制。计算系统100(图1a和1b)可以对太大而不能嵌入量子处理器硬件上的问题进行分解。
以上描述的各种后处理技术对于改进包括断裂链的结果也是特别有用的。多个因子可能导致链断裂,例如,所述链的量子位之间的耦合强度可能被设定在太低而不能维持所述链的值。因此在实践中,在从硬件资源返回的结果中通常存在断裂的链。后处理技术可以改进这样的结果,例如通过拒绝(即,抛弃包含断裂链的结果)或通过误差纠正。
而且例如,在误差纠正中可以采用多数表决后处理,例如用于通过向大多数链构成成员给出的值指派对应的逻辑变量来修补断裂链,其中值之间的任何联系都可以被随机决定。而且例如,在多数表决后处理之后或与之相结合,可以应用贪婪下降后处理。这样的途径可以在未嵌入的问题中应用单比特翻转、并且选择改进了目的或评估功能的那些配置。可以贪婪地进行这些翻转,直到不可能有更多的局部改进。
作为另一个实例,可以采用局部搜索后处理。例如,可以调用局部搜索方法来进一步改进或精细化从硬件资源接收的结果。所述局部搜索方法的运行时间理想地应当相对小。
例如,如果应用局部改变涉及到决定如何指派由链x表示的逻辑变量,则每个相邻的链y对x指定一个值j,这可以基于y的多数表决或者通过y的比例表示来推断。
以上“猜测”方法可以进行更远,从而将所述问题减小成仅基于断裂链所表示的变量的伊辛模型。如果例如两个断裂链彼此之间具有至少一个连接,则可以在对应的逻辑变量之间添加伊辛交互,并且接着可以作为软件中的后处理的一部分来求解被减小的伊辛问题。
可以采用的后处理操作的其他实例包括遗传算法(模拟自然选择的搜索启发法)、扩展集成(mcmc的实例)、以及模拟退火。
还可以使用后处理操作进行列举,即,当目标是寻找(或计数)问题的所有最优解而不是仅寻找单一最优解时。在此描述的优化后处理技术中的许多都适用于列举。
此外,在一种途径中,所述计算系统寻找最优解、并且接着使用单比特翻转和宽度优先搜索来寻找其他解。比特翻转可以按类似于贪婪下降的方式进行,如果能量不变则接受移动、并且产生新的解。可以使用宽度优先搜索或深度优先搜索来寻找和记录使用单比特翻转可以得到的所有解。
在抽样中找到的最优解的统计结果可以用于提供对最优解的估计或界定。可以递归地应用所述途径。
所述后处理可以在所述计算系统中的不同点处的多种不同的硬件上进行。例如,所述后处理可以在量子处理器应用编程接口(qpapi—)层级、sapi层级、或在非量子处理器层级(例如,fpga)上进行。qpapi是暴露量子处理器指令作为web服务的web服务api。
如以上实例所指示的,将大多数真实世界问题映射到其拓朴结构实施二分图的量子处理器中要求增大芯片上的连接性,这目前是通过引入链来完成的,如之前描述的。如之前讨论的,在现实中,链通常可能由于多种原因而断裂。
当链上发生断裂时,对应的样本可以被抛弃或映射到“接近可行状态”(即,无断裂的状态)。前一种选择导致在实现可行状态之前浪费了样本。后一种选择引入了一些开销以便通过后处理来固定或改进样本,如之前讨论的。例如,可以执行链的多数表决来将断裂链映射到其最接近的(在汉明距离的意义上)可行状态。
在实践中,所述硬件(例如,量子处理器)返回的样本中的一些可能不是局部最优的。对于目标是确定全局最优值或至少局部好的最优值的优化问题,仅考虑局部最优的状态。类似于断裂链,非局部最优的样本提供了两个选项:i)抛弃样本;ii)执行局部搜索以固定所述样本。关于后一个选项,将非局部最优状态映射到候选解的后处理途径的实例是运行局部搜索以找到接近的局部最优状态。
在替代性途径中,可能能够在不引入任何开销的情况下固定断裂链和非局部最优的样本。这可以通过在样本到达时对所述以便进行后处理来实现。由于所述样本是一次到达一个,因此可以在产生下一个样本的同时进行后处理。所述样本的后处理可以例如在通信地耦合到所述样本的来源(例如,量子处理器)上的一个或多个fpga上进行。
sapi和qpapi可以被配置来适应这样的途径,例如通过使用标志来告知从硬件返回的样本有待进行后处理以便确保所述样本是局部最优的。默认地,所述标志可以被设定为真(即,将每个样本标记成有待进行后处理以确保它是局部最优的)。可以标记具有断裂链的样本。可以对标记的样本进行后处理以确保局部最优性。例如,被标记为非局部最优的断裂链看被发送至非量子硬件资源(例如,fpga),并且接着可以对所述链执行多数表决以便修补所述断裂链,并且此外可以调用从经修补的链的局部下降。
在修补断裂链的另一种途径中,选择使能量最小化的值(例如,0或1、+1或-1)。可以类似于多数表决,贪婪地或递归地应用这种途径。这种途径在一些方面类似于跟随局部场、并且在特殊情况下是最优的(即,如果断裂链不是邻居的话,它将始终提供最小能量解)。
如果在量子硬件上求解的问题是具有小的局部约束的csp类型问题,则链典型地由于采用不同的值来试图满足不同的约束而断裂。例如,在nae3sat问题中,硬件资源例如量子处理器可以通过将变量设定为0来满足第一子句并且将同一变量设定为1来满足第二子句而使链断裂。在此情况下,通过观察相邻链的值来对链重新求解不太可能是有用的途径。nae3sat和2in4sat问题具有到伊辛问题的相对直接的转换。然而,3sat可以立即从将硬件结果映射到“附近”有效3sat答案的策略中获益。
此外,qpapi或量子处理器可以测量局部激发值,例如用于针对给定的一组解来确定可以独立地翻转以便改进能量的自旋的百分比。这个值提供了改进通过后处理产生的答案的机会。这个值还提供了衡量具体问题或具体类型的问题的误差敏感度、以及衡量可能的读出误差的机会。这可以用来进行更好选择以求解将来的问题。
可选地,可以例如通过硬件资源(例如,微处理器140、fpga150、dsp160、gpu170(图1a和1b))来执行指令集330,以便将后处理操作与处理操作(即,通过(多个)量子处理器产生样本)进行协调。所述指令集330可以致使后处理操作至少部分地、或甚至完全与样本的产生重叠。例如,所述指令集330可以致使在所述量子处理器产生第n+1样本或结果的同时对于来自所述量子处理器的第n样本或结果执行后处理。所述指令集330可以对所述后处理进行定时,使得每次迭代与求解的迭代部分地重叠。所述指令集330可以控制对于第n样本或结果的后处理在所述量子处理器产生第n+1样本完成之前或之时完成。这种途径可以显著减小产生答案或解的总时间。
例如,在运行基于来自量子处理器硬件的样本被初始化的扩展的mcmc链时可以应用处理与后处理的协调操作,从所述量子处理器硬件得出多个样本。例如,如果对同一问题运行多个量规,则每个新的量规的编程时间是显著的,并且例如一万(104)个样本的退火和读出远不是瞬时的。在这个时间期间,gpu或fpga实现方式可以运行从最后一批一万(104)个样本初始化的块吉布斯抽样。假定可以在完全提取下一量规的结果所需要的时间内运行多次迭代的块吉布斯抽样,对于所述量子处理器硬件产生的每个样本,通过这种经典的mcmc产生的多个去相关的样本可以被返回给用户。优选地,所述后处理操作不会增加所述计算过程的工作周期,所述后处理操作与从量子处理器读出单一解相比花费更少的时间(例如,少于0.1ms)。由于对多个批次的gpu矩阵-矩阵操作比对单一样本的矩阵-向量操作有效得多,因此可能有利的是一次对整个抽样批次而不是单个样本地进行后处理。
在许多情形中,量子处理器可以非常快速地产生高品质或可靠的结果。简要而言,所述量子退火硬件可以非常快速地找到在与最优值的小差别之内的解,但是由于ice和噪声,从到最优解的成本获得可以相对高。小差别是基于由于ice造成的误差模型的数并且是与
有可能让量子处理器演算长时间以达到问题哈密尔顿算子的基态、或者让量子处理器演算较少时间并达到一种缺乏基态的不同状态。这种不同状态可以近似于基态。一种包括找出近似基态的量子处理器的模拟计算机是有用的。这些近似基态可以使用在此描述的后处理方法、以在此被称为“接近ε”的技术来引导计算机找到基态。问题是,为了使结果有用,需要基态的近似有多好。
在基态的可量化距离内的解是在问题哈密尔顿算子中体现的问题的有用近似解。所述问题哈密尔顿算子包括基态,并且其中基态具有在所述问题哈密尔顿算子的状态中的最低能量。然而,基态可以是退化的或不是。
使量子处理器演算一段时间t可以包括使量子处理器演算一段时间t,其中时间t不足以达到所述问题哈密尔顿算子的基态、但是足以达到高于基态的一组激发态。
使量子处理器演算一段时间t可以包括使量子处理器演算一段时间t,其中所述时间足以达到问题哈密尔顿算子的基态附近的一种或多种状态。在此,术语“附近”在离开基态的一定量的能量之内er。
可以在不同的假定下使用许多不同的方式来计算离开基态的能量的量。在一个实例中,离开基态的能量的量是与一个常数、描述误差模型的项、以及描述器件参数中的误差的项的乘积成比例的。器件可以包括在模拟处理器中的量子位或耦合器。例如,
er∝k·em·ed(31)
在此k是常数,em概括了误差模型,并且ed概括了设备中的误差。常数k的实例为1阶。误差模型项的实例包括与量子处理器中的器件数量成比例的表达。误差模型项的实例包括与量子位数量次线性地、与量子位数量线性地、以及与量子位数量多项式地成比例的表达。对于硬件图,误差模型项的实例包括假定量子处理器的哈密尔顿案子中的误差为不相关的项。不相关的误差的总和得到了与所述总和中的项数的平方根成比例的总因子。实例为:
em∝(m)1/2(32)
其中m大致是硬件图中的量子位和耦合器的数量。对于其拓扑结构实施二分图的示例性量子处理器的硬件图,误差模型项的实例包括:
em∝(4n)1/2(33)
其中4n在量子位数量n的意义上大致是硬件图中的量子位和耦合器的数量。对于完整的硬件图,误差模型项的实例kn包括
误差模型项的实例包括与器件数量成比例的表达。对于其拓扑结构实施二分图的示例性量子处理器的硬件图,误差模型项的实例包括:
其中δ是小于一且大于零的值。所述表达的平衡是所述模拟过程的最大能量尺度,并且确切地示出了对于由rf-squid量子位和耦合器构成的超导量子处理器的能量尺度。
δ的实例包括0.01、0.05和0.1。项δ是量子处理器的参数规范中的误差。例如,对于单一量子位偏置项h,偏置的误差为δh。
计算系统100/300可以进一步包括可操作来产生伪随机或真随机数的随机数发生器332。随机数可能对于驱动概率性计算、例如后处理中的那些是有用的。具体地,可以通过经典计算机程序(例如,通过调用在matlab、python等中提供的随机数发生器函数、或专属经典函数)提供伪随机数。可以通过量子源提供真随机数。量子随机数发生器可以产生随机比特的均匀分布。量子随机数发生器可以通过从随机比特分布中收集连续的比特子序列来产生真随机真实数的分布。量子随机数发生器的实例包括商业设备,包括来自quintessencelabsacton,act0200,australia的qstream计算器具以及来自idquantiquesa,carougege,switzerland的计算机外围设备quantis系列(例如,usb器件和pci卡)。例如,量子随机数发生器可以采取与量子处理器系统集成的外部硬件(例如,usb、pci、pciexpress等)的形式和/或采取计算系统100的量子处理器130之一的形式(图1a和1b)。可以采用任何种类的随机数发生器。
计算系统100/300可以进一步包括量子处理器误差纠正指令集334,所述指令集执行量子处理器的误差纠正,有时称为“匀场”。量子处理器误差纠正指令集334可以例如识别量子器件中朝+1或–1状态的偏置、并且针对这样的偏置进行纠正。量子处理器误差纠正指令集334可以由各种基于处理器的设备、例如与具体量子处理器(是误差纠正的主题)相关联的控制系统或计算机执行。
图4示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法400。
方法400例如响应于提交了问题或者响应于被另一个例程调用而在402开始。方法400或其一部分可以由一个或多个基于处理器的部件、例如经由工作管理器的一个或多个基于处理器的控制器(图1a和1b)(例如,图3a和3b中展示的工作管理器指令或软件模块306)来执行,所述部件通信地耦合到经由适当的硬件电路实施的一个或多个启发式优化器或求解器(例如,量子处理器、非量子处理器)上。
在404中,至少一个基于处理器的控制器对问题执行至少一个预处理操作、然后将所述问题提交到一个或多个求解器(例如,启发式优化器)。这样可以例如包括检查或确认所提交问题具有的格式对于经由该系统可执行的各个求解器而适合的或可接受的。此外或替代地,这样可以例如包括产生所提交问题的一个或多个表示。如下文参照图4详细解释的,此外或替代地,这样可以包括选择一个或多个启发式优化器和/或硬件处理器(例如,如图1a和1b中展示的微处理器140、fpga150、dsp160、或gpu170)来执对所述问题的表示执行启发式优化。
在406中,至少一个基于处理器的控制器致使经由一个或多个启发式优化器来优化经预处理的问题、或其表示。例如,所述至少一个基于处理器的控制器可以将经预处理的问题、或其表示提交到一个或多个启发式优化器。
例如,可以经由(多个)量子处理器执行所述一个或多个启发式优化器。所述量子处理器可以选自各种不同类型的量子处理器,例如被设计用于aqc和/或量子退火的一个或多个超导量子处理器。
而且例如,可以经由(多个)非量子处理器执行所述一个或多个启发式优化器。所述非量子处理器可以选自以下各项中的至少一项:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、和/或现场可编程门阵列(fpga)。例如,可以由一个或多个微处理器、例如由两个或更多微处理器并行地执行启发式优化器。而且例如,可以由一个或多个dsp、例如由两个或更多dsp并行地执行启发式优化器。而且例如,可以由一个或多个gpu、例如由两个或更多gpu并行地执行启发式优化器。而且例如,可以由一个或多个fpga、例如由两个或更多fpga并行地执行启发式优化器。此外或者替代地,可以由一个或多个微处理器以及一个或多个dsp、gpu和/或fpga、例如由这些微处理器和dsp、gpu和/或fpga并行地执行启发式优化器。此外或者替代地,可以由一个或多个dsp以及一个或多个gpu和/或fpga、例如由这些dsp和gpu和/或fpga并行地执行启发式优化器。此外或者替代地,可以由一个或多个gpu、一个或多个fpga、例如由这些gpu和fpga并行地执行启发式优化器。可以采用非量子处理器的、适合于有待求解的具体问题以及有待采用的启发式优化器的任何其他组合或排列。
而且例如,可以经由(多个)量子处理器并且经由一个或多个非量子处理器执行所述一个或多个启发式优化器。同样,可以采用非量子处理器的、适合于有待求解的具体问题以及有待采用的启发式优化器的任何组合或排列。
在408中,至少一个基于处理器的控制器接收通过所述(多个)启发式优化器在硬件资源(例如,(多个)非量子处理器、(多个)量子处理器)上执行一个或多个启发式优化所得到的结果或样本,并且致使通过所述至少一个基于非量子处理器的后处理设备对相应样本执行至少一个后处理操作。在一些实现方式中,可以经由(多个)量子处理器执行一个或多个启发式优化器,并且所述至少一个基于处理器的控制器接着接收经由所述量子处理器所执行的启发式优化所产生的样本。在一些实现方式中,可以经由所述(多个)非量子处理器执行所述一个或多个启发式优化器,并且所述至少一个基于处理器的控制器接着接收经由所述非量子处理器所执行的启发式优化所产生的样本。在一些实现方式中,可以经由一个或多个非量子处理器以及一个或多个量子处理器执行所述一个或多个启发式优化器,并且所述至少一个基于处理器的控制器接着接收经由所述非量子处理器和量子处理器所执行的启发式优化所产生的样本。在另外的其他实现方式中,所述至少一个基于处理器的控制器本身可以执行所述启发式优化、并且不接收所述启发式优化的结果,因为所述至少一个基于处理器的控制器已经具有所述启发式优化的结果。
所述(多个)后处理操作可以例如包括经由执行对应指令或软件模块的至少一个数字处理器来执行以下各项中的一项或多项:多数表决后处理操作、贪婪下降后处理操作、变量钳制后处理操作、变量分支后处理操作、或局部场表决后处理操作。
在410中,至少一个基于处理器的控制器回顾所述启发式优化的经后处理的结果。例如,所述至少一个基于处理器的控制器可以关于满足最终条件来回顾所述结果。
在412中,至少一个基于处理器的控制器至少部分地基于所述后处理的结果来判定是否修改所述原始问题。例如,所述至少一个基于处理器的控制器可以确定最终条件是否已被满足。
如果已确定所述最终条件已被满足,则控制前进到416,此时方法400可以终止。
如果已确定所述最终条件未被满足,则在414中所述至少一个基于处理器的控制器修改所述问题或致使所述问题被修改。所述至少一个基于处理器的控制器致使例如通过将控制返回到404或可选地406、通过所述启发式优化器之一来优化经修改的问题。所述至少一个基于处理器的控制器可以将经修改的问题返回到前一次迭代中使用的相同启发式优化器。替代地,所述计算系统的所述至少一个基于处理器的控制器可以例如在对所述问题执行的不同迭代之间在不同的启发式优化器之间进行切换。例如,所述计算系统的所述至少一个基于处理器的控制器可以致使这些启发式优化器中的第一个来优化相应问题并且致使这些启发式优化器中的第二个来优化所述修改后的问题,其中这些启发式优化器中的第二个不同于这些启发式优化器中的第一个。
方法400的操作可以重复一次或多次,从而迭代地修改所述问题并对经修改的问题执行优化,直到达到或满足最终条件。
图5示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法500。方法500可以例如作为方法400(图4)的执行至少一个后处理操作408的进行或执行的一部分被执行。
在502中,所述计算系统的所述至少一个基于处理器的控制器在多种类型的启发式优化算法之间进行自主选择以用于执行所述启发式优化。
在504中,所述计算系统的所述至少一个基于处理器的控制器在多种类型的硬件设备之间进行自主选择以用于执行所述启发式优化。在一些情形中,硬件设备的选择可以由所选择或采用的具体后处理途径决定。
图6示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法600。方法600可以例如作为判定最终条件是否已被满足的进行或执行的一部分、作为方法400(图4)的判定是否修改所述问题412的一部分被执行。
如之前指出的,在602中,所述至少一个基于处理器的控制器可以至少部分地基于所述后处理的结果来判定是否达到了满足条件,以便判定是否修改所述原始问题。如果在602中达到满足条件,则控制前进到608,此时中止对所问题的迭代。如果在602中没有达到满足条件,则控制前进到604。
在604中,至少一个基于处理器的控制器判定是否已达到修改所述问题的最大迭代次数。如果在604中已达到修改所述问题的最大迭代次数,则控制前进到608,此时中止对所述问题的迭代。如果在604中没有达到修改所述问题的最大迭代次数,则控制返回到606,此时重复方法600。
图7示出了根据一个所展示实施例使用量子处理器通过使用被称作“得到ε的时间”途径的途径来确定问题的解的方法700。方法700包括多个动作,但本领域技术人员应了解的是,在替代性实施例中,在方法700的不同应用中可以添加额外的动作或者省略一些动作。在702中,产生问题的表示。在一些实例中,这是在与模拟计算机相关联的数字计算机中完成的。所述表示可以包括例如图形表示、二进制表示、二次无约束二元表示、伊辛模型表示等等。在704中,可以将所述量子处理器的元件编程为体现初始化哈密尔顿算子的第一配置。在一些实例中,这种编程可以通过使用包含多个元件特异性编程接口的操作子系统来实现。在706中,所述模拟计算机持续时间t地演算所述量子处理器的状态。演算所述量子处理器的状态可以包括例如:执行量子计算,例如绝热量子计算,或者实施量子退火。时间t足够长到使得所述量子处理器的状态位于基态的er之内。也就是,通过近似于问题哈密尔顿算子的第二配置来描述所述量子处理器。所述问题哈密尔顿算子对计算问题进行编码。在708中,模拟计算机读出所述量子处理器的状态。在一些实例中,所述量子处理器可以包括被配置成用于读出所述问题的第一解的读出子系统。状态代表在问题哈密尔顿算子中体现的所述问题的解。预期所述解一般是近似解、但可以是真实解。在710中,存储量子处理器的状态。在一些实施例中,可以将量子处理器的状态存储在与模拟计算机相关联的计算机可读/可写存储装置中。
图8是根据当前描述的系统、设备、物品和方法显示了以重叠的方式来协调处理操作和后处理操作的时间线800。
所述计算系统100以依次获取样本批次的形式执行多个处理操作802a-802e(示出了五个,统称为802)。这些处理操作802可以采取各种形式,例如对于问题哈密尔顿算子进行的绝热量子处理器操作。在每个处理操作802之后,所述计算系统100对之前获取的样本批次中的最新一个执行后处理操作804a-804e(示出了五个,统称为804。值得注意的是,后处理操作804a-804e的每一个与处理操作802中的相应一个在时间上重叠。例如,这些后处理操作804是在这些处理操作802的过程中发生。这种途径有利地减少了确定解或最佳解的总计时间或总时间,所述总计时间或总时间是执行所述处理(例如,获取样本的获取时间)和后处理的时间之和,后处理时间可以例如等于对单一样本或单一一批样本进行后处理的时间。
如图8所示,每个后处理操作可以短于这些处理操作中与所述后处理操作重叠的相应随后处理。在其他实现方式中,每个后处理操作可以具有与这些处理操作中与所述后处理操作重叠的相应随后处理的持续时间相等、大致相等、或更短的持续时间。虽然不够有利,但在又其他实现方式中,每个后处理操作可以具有比这些处理操作中与所述后处理操作重叠的相应随后处理的持续时间更长的持续时间。在一些实现方式中,获取样本或样本批次所花的时间还可以包括对问题进行预处理所花的时间。
虽然这各个处理操作被展示为各自具有相同的持续时间,但在一些实现方式中,相应处理操作的持续时间可以与这些处理操作中的一些或所有其他处理操作不同。虽然这各个后处理操作被展示为各自具有相同的持续时间,但在一些实现方式中,相应后处理操作的持续时间可以与这些后处理操作中的一些或所有其他后处理操作不同。
图9示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法900。所述计算系统可以例如采取在图1-3中展示且参照这些图描述的计算系统的形式。
方法900例如响应于提交了问题或者响应于被另一个例程调用而在902开始。方法900或其一部分可以由一个或多个基于处理器的部件、例如经由工作管理器的一个或多个基于处理器的控制器(例如,图3a和3b中展示的工作管理器指令或软件模块306)来执行,所述部件通信地耦合到经由适当的硬件电路实施的一个或多个启发式优化器或求解器以及后处理器(例如,图1a和1b中展示的量子处理器、非量子处理器)上。
方法900包括在从起始值(例如,0)到数目n的迭代次数i上执行的迭代循环,其中n是大于2的整数。因此在904中,将计数器i设定为初始值(例如,i=0)。在906中,将计数器i增量(例如,i=i+1)。替代地,在906中可以将计数器减量、但为了方便讨论是以增量的方式呈现。
在908中,至少一个基于处理器的控制器判定迭代次数是否在一组边界之内,例如判定计数器i是否大于1并且i是否小于n。如果在这些边界之内(例如,是),则控制前进到910。如果不在这些边界之内,则控制前进到920,在此方法900可以终止。
在910中,至少一个基于处理器的控制器确定通过一个或多个量子处理器、例如被设计用于aqc和/或量子退火的一个或多个超导量子处理器产生的样本例如,多批样本)的产生的时机。
在许多实现方式中,所述至少一个基于处理器的控制器将使用第(i+1)样本的产生的时机来将第i样本的后处理同步成至少部分地在后续样本(即,第(i+1)样本)的产生过程中发生。在其他实现方式中,所述至少一个基于处理器的控制器将使用其他样本的产生的时机(例如,第i样本的产生的时机)来将第i样本的后处理同步成至少部分地在后续样本(即,第(i+1)样本)的产生过程中发生。在这样的情形中,所述至少一个基于处理器的控制器考虑在第i样本与第(i+1)样本的产生之间的延迟。
确定产生的时机可以包括确定产生和/或接收样本所需要的时间量、并且可以在产生样本的这种处理发生之前确定。在所述处理之前已知的或确定的时间量可以用于同步这些后处理操作的时机,以便以至少部分重叠的方式来协调后处理与处理。替代地或此外,确定产生的时机可以包括检测所述产生和/或接收通过所述处理而产生的样本。通过检测所述产生或接收来自所述处理的样本来“在飞行中”确定时机可以用于同步这些后处理操作的时机,以便以至少部分重叠的方式来协调后处理与处理。在下文中、并且在本文的其他地方和/或在通过援引并入本文的申请中描述了实施这种先验和后验性时机确定的各种途径。
为了确定第(i+1)批样本的产生的时机,所述至少一个基于处理器的控制器可以例如确定对于给定量子处理器和/或有给定类型的问题或待确定的给定数量的样本而言产生和/或返回样本一般需要的时间量。如上文指出的,可以在量子处理器进行处理之前先验性地确定这种时机。
替代地,为了确定第(i+1)批样本的产生的时机,所述至少一个基于处理器的控制器可以例如后验性地确定这种时机,通过检测所述产生和/或接收所述量子处理器进行的处理。
为了确定第(i+1)批样本的产生的时机,所述至少一个基于处理器的控制器可以例如确定所述至少一个量子处理器已产生了所述第(i+1)批样本,以便确定通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。
替代地,所述至少一个基于处理器的控制器可以例如确定所述至少一个量子处理器已产生了所述第i批样本,以便确定通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。
替代地,所述至少一个基于处理器的控制器可以例如至少部分地基于通过所述至少一个基于处理器的控制器接收到所述第i批样本,确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机。
替代地,所述至少一个基于处理器的控制器可以例如至少部分地基于通过所述计算系统的不同于所述基于处理器的控制器的部件接收到所述第i批样本,确定所述通过所述至少一个量子处理器产生的第(i+1)批样本的产生的时机。
替代地,所述至少一个基于处理器的控制器可以例如至少部分地基于发出了致使通过所述至少一个量子处理器来产生第(i+1)批样本的至少一个信号,确定所述通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。
替代地,所述至少一个基于处理器的控制器可以例如至少部分地基于发出了致使通过所述至少一个量子处理器来产生第i批样本的至少一个信号、并且基于通过所述至少一个量子处理器来产生所述第i批样本所需要的时间量,确定所述通过所述至少一个量子处理器产生的所述第(i+1)批样本的产生的时机。
在912中,至少一个基于处理器的控制器可以例如致使对第i批样本执行一个或多个后处理操作是与通过一个或多个量子处理器产生的第(i+1)批样本的产生在时间上至少部分重叠地进行。例如,所述至少一个基于处理器的控制器可以致使对第i样本执行所述一个或多个后处理操作的时间不延伸超过通过所述一个或多个量子处理器产生所述第(i+1)样本所持续的时间。所述至少一个基于处理器的控制器可以例如发送致使通过至少一个基于处理器的设备对所述第i批样本进行后处理的至少一个信号。
所述后处理操作可以例如包括通过执行对应指令集或软件模块的至少一个数字处理器来执行以下各项中的一项或多项:量子位链多数表决后处理操作、局部搜索寻找局部最优值后处理操作、或在固定温度的后处理操作中的马尔可夫链蒙特卡罗模拟。致使执行后处理操作可以例如包括致使通过以下各项中的一项或多项来执行后处理操作:微处理器、数字信号处理器(dsp)、图形处理单元(gpu)、或现场可编程门阵列(fpga),例如是通过一个或多个微处理器140、fpga150、dsp160、或gpu170(如图1a和1b所示)。
可选地在914中,将多个经后处理的样本发送给用户,例如经由服务器发送。所述后处理可以在将经后处理的样本发送给用户之后进行。
可选地在916中,对于所述多个问题中的每个问题,通过至少一个基于处理器的设备(例如,至少一个基于处理器的控制器)至少部分地基于在针对相应问题的相应迭代过程中产生的多批样本中的至少一些来确定相应结果。在一些情形中,针对所述多个问题中的第一个问题的迭代总次数n不同于针对所述多个问题中的第二个问题的迭代总次数n。
可选地在918中,例如经由服务器将结果发送给用户,所述服务器可以将所述结果转发至提交所述问题的最终用户。
方法900可以在920终止,例如直到被再次调用。
在一些实现方式中,可以跨多于一个批次来累计信息。总体上,更多的样本可以得到改进的估计。后处理操作可以具有可以基于样本以前馈途径进行适配的参数。
图10示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法1000。所述方法1000可以作为方法900(图9)的一部分或与之一起进行。
所述至少一个基于处理器的控制器可以对于从2到n-1的多次迭代i将执行所述至少一个后处理操作的时间限制为不大于从所述量子处理器产生所述一批样本所需要的时间。
在1002中,所述至少一个基于处理器的控制器确定从所述量子计算机接收一批样本所需的时间。
在1004中,所述至少一个基于处理器的控制器确定在所确定的时间内可执行的一组后处理操作。
图11示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法1100。所述计算系统可以例如采取在图1-3中展示且参照这些图描述的计算系统的形式。
方法1100例如响应于提交了问题或者响应于被另一个例程调用而在1102开始。方法1100或其一部分可以由一个或多个基于处理器的部件、例如经由工作管理器的一个或多个基于处理器的控制器(例如,图3a和3b中展示的工作管理器指令或软件模块306)来执行,所述部件通信地耦合到经由适当的硬件电路实施的一个或多个启发式优化器或求解器(例如,图1a和1b中展示的量子处理器、非量子处理器)上。
在1104中,至少一个基于处理器的设备执行问题的预处理评定。所述预处理评定可以包括确定所述具体问题的问题类型、并且判定所述问题类型是否是适合于经由所述计算系统来求解的类型。例如,所述预处理评定可以包括判定所述问题是可满足性问题还是优化问题。
可选地在1105中,至少一个基于处理器的设备可以产生所述问题的多个表示。
在1106中,所述至少一个基于处理器的设备至少部分地基于对所述问题的所述预处理评定从多个求解器(例如,启发式优化器)中选择至少一个求解器(例如,启发式优化器)。已经参照图1a、1b、2、3a和3b讨论了各个启发式优化器。所述至少一个基于处理器的设备可以选择这些启发式优化器中的任一个或多个来对具体的所提交问题求解。
所述至少一个基于处理器的设备可以至少部分地基于所述问题优化器的评定、在没有人类交互的情况下从多个启发式优化器中自主地选择至少一个启发式优化器。例如,所述至少一个基于处理器的设备可以至少部分地基于所述问题的评定、在不参考除相应问题和问题类型之外的任何用户输入的情况下自主地选择至少两个彼此不同的启发式优化器。例如,所述至少一个基于处理器的设备可以至少部分地基于预测、评估、考虑、或比较每个求解器(例如,启发式优化器)通过使用所述提取的特征对于所述问题将会多么成功来自主地选择至少一个启发式优化器。
在1108中,所述至少一个基于处理器的设备致使通过所选的一个或多个启发式优化器来优化所述问题。这样可以例如包括将所述问题提交或发送到所选的一个或多个启发式优化器和/或以其他方式调用所选的一个或多个启发式优化器。所述至少一个基于处理器的设备可以将这些问题、或其表示依次发送到两个或更多求解器(例如,启发式优化器),一次一个求解器。替代地或此外,所述至少一个基于处理器的设备可以将这些问题、或其表示同时发送到两个或更多求解器(例如,启发式优化器),一次两个或更多。
在1110中,所述至少一个基于处理器的设备致使通过至少一个基于处理器的后处理设备对于从对所述问题执行的所述启发式优化得到的多个样本执行至少一个后处理操作。例如,所述至少一个基于处理器的设备可以致使通过至少一个基于非量子处理器的设备来进行至少一个后处理操作。
例如,至少一个基于处理器的设备可以致使以下各项中的至少一项来执行所述至少一个后处理操作:一个或多个微处理器、一个或多个数字信号处理器(dsp)、一个或多个图形处理单元(gpu)、和/或一个或多个现场可编程门阵列(fpga)。所述至少一个基于处理器的设备接收由微处理器、dsp、gpu、和/或fpga中的所述至少一项所执行的启发式优化而产生的样本。在一些实现方式中,执行所述启发式优化的(多个)微处理器、(多个)dsp、(多个)gpu、和/或(多个)fpga可以形成所述计算系统的一部分。
所述至少一个基于处理器的设备可以致使通过至少一个数字处理器来执行例如选自以下各项中的至少一个后处理操作:量子位链多数表决后处理操作、局部搜索寻找局部最优值后处理操作、或在固定温度的后处理操作中的马尔可夫链蒙特卡罗模拟。所述方法可以采用参照图1-3描述的、或在本申请的其他地方或者通过援引并入本文的申请中描述的各种后处理操作或技术中的任一种。
此外或者替代地,所述至少一个基于处理器的设备可以致使一个或多个量子处理器执行一个或多个后处理操作。例如,所述至少一个基于处理器的设备可以致使被设计用于aqc(和/或量子退火)的至少一个或多个超导量子处理器执行一个或多个后处理操作。
方法1100可以在1112终止,例如直到被再次调用。
图12示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法1200。方法1200可以例如作为对问题执行预处理、例如方法1100的预处理评定操作1104的进行或执行的一部分被执行(图11)。
方法1200例如响应于被另一个过程或线程调用而在1202开始。
可选地在1204中,所述至少一个基于处理器的设备接收问题。所述问题可以例如从最终用户或最终用户设备直接或间接地接收。所述问题可以例如web服务器部件或经由工作管理器部件被接收。
在1206中,所述至少一个基于处理器的设备确定所述问题的格式。例如,工作管理器部件可以将所述问题分类为一种或多种类型或格式,例如约束性满足或可满足性问题、优化问题。例如,所述工作管理器部件可以在没有人类干预的情况下自主地将所述问题分类为一种或多种类型或格式。
在1208中,所述至少一个基于处理器的设备确定所确定的问题格式是否受支持。例如,所述至少一个基于处理器的设备将所述问题的类型或格式与所述计算系统可用的资源、例如求解器和/或硬件资源(例如,非量子处理器、量子处理器)进行比较。如果所述问题的格式不被支持,则在1210中所述至少一个基于处理器的设备拒绝所述问题、并且例如在1212中提供通知或致使所述拒绝的通知被提供。如果所述问题的格式受支持,控制前进到1214。例如,所述至少一个基于处理器的设备可以在没有人类干预的情况下自主地确定所确定的问题格式是否受支持。
在1214中,所述至少一个基于处理器的设备产生问题的多个表示。例如,所述至少一个基于处理器的设备可以产生所述问题的qubo表示、所述问题的sat表示,所述问题的图形模型表示、和/或所述问题的二次分配表示。所述至少一个基于处理器的设备可以产生所述问题的、遵守预定义句法的一种不同表示。同样,在至少一些实现方式中,所述至少一个基于处理器的设备可以在没有人类干预的情况下自主地产生问题的多个表示。
方法1200可以在1216终止,例如直到被再次调用。
图13示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法1300。方法1300可以例如作为对问题执行预处理、例如方法400(图4)的预处理评定操作404的进行或执行的一部分被执行。
方法1300例如响应于被另一个过程或线程调用而在1302开始。
在1304中,至少一个基于处理器的设备从问题的(多个)表示中提取(多个)特征。例如,从qubo问题中,所述至少一个基于处理器的设备可以提前与图论有关的相关特征(例如,图的大小、顶点数量、顶点的最大和最小度数等)。作为另一个实例,从sat问题中,所述至少一个基于处理器的设备可以提取子句特征(例如,子句数量、子句的平均大小、子句中的文字数量等)。作为又一个实例,从图形模型问题中,所述至少一个基于处理器的设备可以提取与依赖性或相关性有关的特征。
在1306中,所述至少一个基于处理器的设备至少部分地基于所提取的特征评定多个求解器。所述至少一个基于处理器的设备可以例如在求解器与提取的特征和/或问题格式或类型之间采用查找表、映射或数据库关系。
在1308中,所述至少一个基于处理器的设备基于由所述基于处理器的设备进行的评定、在没有人类干预的情况下自主地选择一个或多个求解器。在一些实现方式中,选择至少两个求解器,并且这两个所选的求解器彼此不同。替代地,在一些实现方式中,可以基于指示将对具体问题采用的(多个)求解器的用户输入来手动选择所述求解器。
在1310中,所述至少一个基于处理器的设备致使对问题的(多个)表示进行一个或多个求解器的选择。这样可以包括将所述问题表示转发给所选的一个或多个求解器、和/或以其他方式调用所选的一个或多个求解器。
可以对于问题的每个表示重复方法1300。方法1300可以在1312终止,例如直到被另一个过程或线程再次调用。
图14示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法1400。方法1400可以例如作为对问题执行后处理、例如方法400(图4)的后处理评定操作410的进行或执行的一部分被执行。
在1402中,至少一个基于处理器的设备将来自所选求解器中的每一个的结果进行比较。例如,所述至少一个基于处理器的设备将来自至少两个所选求解器中的每一个的结果进行比较。例如,所述至少一个基于处理器的设备将两个或更多所选求解器中的相应求解器对相应问题的最终结果进行比较。所述至少一个基于处理器的设备可以采用多种多样后处理技术中的任一种来比较所述结果,例如关于图1-3所描述的、或在本文其他地方和/或在通过援引并入的申请中描述的各种后处理技术。
在1404中,所述至少一个基于处理器的设备至少部分地基于比较来确定最佳解。同样,所述基于处理器的设备可以采用多种多样后处理技术中的任一种来确定最佳解,例如关于图1-3所描述的、或在本文其他地方和/或在通过援引并入的申请中描述的各种后处理技术。
在1406中,所述至少一个基于处理器的设备经由网络接口将所确定的最佳解返回给用户。例如,可以经由web服务器来返回结果,所述服务器可以对所述问题求解服务实施web门户。
图15示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法1500。方法1500可以例如作为方法1300的致使所选的一个或多个求解器对问题的(多个)表示进行操作1310的进行或执行的一部分被执行(图13)。可以针对所选求解器中的每一个重复方法1500。
可选地在1502中,至少一个基于处理器的设备将问题分解为多个部分。可以对这些部分确定大小或以其他方式进行配置以允许求解器有效地对这些子问题进行操作。例如,可以对这些部分确定大小或以其他方式进行配置以允许给定了具体求解器和求解器硬件资源的情况下有效地嵌入所述子问题。
在1504中,所述至少一个基于处理器的设备将所述部分分配给多个计算资源中的相应计算资源。例如,所述至少一个基于处理器的设备可以基于所述问题的相应部分所要求的处理类型,将这些部分或子问题分配给多个计算资源的相应计算资源。
在1506中,所述至少一个基于处理器的设备基于来自所述部分或子问题的结果产生每个相应求解器对相应问题的最终结果。
图16示出了根据当前描述的系统、设备、物品和方法的一种在计算系统中的操作方法1600。方法1600可以例如作为方法1300的致使所选的一个或多个求解器对问题的(多个)表示进行操作1310的进行或执行的一部分被执行(图13)。
在1602中,至少一个基于处理器的设备收集相应问题的每个部分的结果。
在1604中,所述至少一个基于处理器的设备将所收集的相应问题的每个部分的结果进行组合从而产生相应求解器对相应问题的最终结果。
以上描述的方法、过程、或技术的益处是加速了量子退火而实现相同的结果、或者实现了在相同时间内可实现的改进的结果。例如,可以以低于最优的模式使用抽样器并且与后处理相结合。
以上描述的(多种)方法、(多个)过程、或(多种)技术可以通过存储在一个或多个非瞬态处理器可读介质上的一系列处理器可读指令来实施。以上描述的方法、过程、或技术方法的一些实例部分地是由专用设备例如绝热量子计算机或量子退火器、或对绝热量子计算机或量子退火器进行编程或以其他方式控制其操作的系统(例如包括至少一个数字处理器的计算机)来执行。以上描述的方法、过程、或技术可以包括各种动作,但本领域技术人员应了解的是,在替代性实例中可以省略某些动作,和/或可以添加额外的动作。本领域技术人员还应了解的是,所展示的动作顺序是仅出于示例性目的而示出的并且可以在替代性实例中改变。以上描述的方法、过程、或技术的示例性动作或操作的实例被迭代地执行。以上描述的方法、过程、或技术的一些动作可以在每次迭代的过程中、在多次迭代之后、或在所有迭代结束时执行
对所展示的实施例的以上说明(包括在摘要中所描述的)并非旨在是穷尽的或者旨在把这些实施例限定于所公开的这些确切的形式。尽管为了说明的目的在此描述了多个具体的实施例和实例,但是相关领域的普通技术人员将会认识到,可以做出不同的等价更改而不脱离本公开的精神与范围。在此提供的不同实施例的传授内容可以应用到其他量子计算方法上,并不一定是以上总体性说明的示例性的量子计算方法。
可将以上所描述的各实施例进行组合以提供进一步的实施例。在本说明书中提及的和/或在申请数据表中列出的所有共同受让的美国专利申请公开案、美国专利申请、外国专利、以及外国专利申请,包括但不限于共同受让的:
美国专利号7,303,276;
美国专利申请序列号14/173,101,在2014年2月5日提交,现在是专利申请公开号2014-0223224;
国际专利申请序列号pct/us2014/014836,在2014年2月5日提交,现在是wipo公开号wo2014123980;
美国专利申请序列号14/339,289,在2014年7月23日提交,现在是美国专利申请公开2015-0032993;
美国专利申请序列号14/340,303,在2014年7月24日提交,现在是专利申请公开号2015-0032994;
美国临时专利申请序列号61/858,011,在2013年7月24日提交;
美国临时专利申请序列号62/040,643,在2014年8月22日提交,标题为“systemsandmethodsforproblemsolvingviasolversemployingproblemmodification[通过求解器采用问题修改来求解问题的系统和方法]”(律师案卷号240105.555p1);
美国临时专利申请序列号62/040,646,在2014年8月22日提交,标题为“systemsandmethodsforproblemsolvingviasolversemployingpost-processingthatoverlapswithprocessing[通过求解器采用与处理重叠的后处理来求解问题的系统和方法]”(律师案卷号240105.556p1);
美国临时专利申请序列号62/040,661,在2014年8月22日提交,标题为:“systemsandmethodsforproblemsolvingviasolversemployingselectionofheuristicoptimizer(s)[通过求解器采用启发式优化器选择来求解问题的系统和方法]”(律师案卷号240105.557p1);以及
美国临时专利申请序列号62/040,890,在2014年8月22日提交,标题为:“systemsandmethodsforimprovingtheperformanceofaquantumprocessorbycorrectingtoreduceintrinsic/controlerrors[通过纠正来减小固有/控制误差来改进量子处理器的性能的系统和方法]”(律师案卷号240105.558p1);以及
美国临时专利申请序列号62/048,043,在2014年9月9日提交,标题为:“systemsandmethodsforimprovingtheperformanceofaquantumprocessorviareducedreadouts[通过减少读出来来改进量子处理器的性能的系统和方法]”(律师案卷号240105.554p1),
各自通过援引以其全部内容并入本文。
鉴于以上的详细说明,可以对实施例做出这些和其他改变。总之,在以下权利要求书中,所使用的术语不应当被解释为将权利要求书局限于本说明书和权利要求书中所公开的特定实施例,而是应当被解释为包括所有可能的实施例、连同这些权利要求有权获得的等效物的整个范围。相应地,权利要求书并不受到本公开的限制。
- 还没有人留言评论。精彩留言会获得点赞!