基于对加权统计指标的分析的零件制造方法与流程
本发明涉及统计指标在例如航空工业这样的工业设置中使用,特别地用于方便监视并控制零件制造。
背景技术:
零件、尤其是机械零件在工业设置中的制造遇到了两个相对的限制:具体地,一方面为生产能力和生产量的增加,另一方面为提高的质量要求,在航空领域中更是如此。
如今,很难想象对所制造的全部零件执行质量控制而不大幅降低制造产量。因此,通常使用统计制造指标,根据关于被选为样本的有限数量的零件的特别信息可靠地推断出关于所制造的一组零件的质量的总体信息。
除了在生产结束时可以对具有有限数量的零件的样本进行控制之外,通常也可以在生产期间进行检验以能够可选地调节生产流程,即就是说,调整制造条件以确保制成的零件继续响应所要求的质量准则。在某些情况下,在生产期间的这些统计控制尤其是当所生产的零件呈现出过多的质量缺陷时可以导致生产完全停止,从而制造流程必须完全重新启动。
相对于被制造的零件的特征尺寸来执行质量控制。该特征尺寸可以例如为零件的特定侧、零件的质量或者所述零件的任何其他可测量的特征。
为了执行统计控制,要连续地选取多个样本,每个样本包括制造流程的多个零件,然后测量所选取的样本的每个零件的特征尺寸。为监视生产流程的质量事先选择的统计指标的值根据所选取的样本的零件的特征尺寸的不同测量值来计算。
存在各种可以用来监视零件的制造流程的变化的统计指标,每个统计指标给出了用于以一种方式或另一种方式来调整制造条件的不同信息。
用于监视工业制造过程的大多数统计指标根据所测量的关于多个零件的特征尺寸的均值μ和标准差σ来计算。更准确地,μ与针对特征尺寸相对于用于该特征尺寸的参考参考值测量的偏心均值对应。
一个示例为定心系数,记为cc,其示出了施加在容差区间it内的均值μ的变化量的限制。容差区间it为特征尺寸的极端容差值之间的偏差,因此被计算为所测量的特征尺寸的较大容差ts和较小容差ti之间的差或者it=ts–ti。定心系数cc通常由以下公式限定:
制造过程还可以通过研究表征该过程相对于优选性能的实际性能的能力指数来进行调节。事实上,该指数对制造过程的能力进行测量以制造特征尺寸包括在优选的容差区间it内的零件。
例如可以给表示制造过程的能力的过程能力指数cp设定参考以精确且可重复地生产零件。能力指数cp越大,所制造的零件将越相似,反之,如果能力指数cp较低,则生产将被分散。过程能力指数cp通常由以下公式来定义:
该过程能力指数cp的缺点在于:正结果(即,过程能力指数cp较高)还可以与容差极限值以外的生产对应。事实上,制造流程的工业一致性取决于范围,该范围不仅在于其分散性,而且在于其相对于容差区间it的平均值的位置。因此,所使用的另一能力指数为能力指数cpk,其不仅示出了分散性,而且示出了生产相对于容差极限的中心。在这种情况下,当能力指数cpk较高时,意味着生产可以重复进行并且该生产还以容差区间it为中心,即就是说,零件在容差以外被制造的风险将更小。过程能力指数cpk通常由以下公式来定义:
当然,存在具有特定属性的其它统计指标,并且可以根据需要使用该其它统计指标来调节制造过程。
为了使用统计指标可靠地监视并调节制造过程,通常在两个时间尺度(timescale)内对这些指标进行监视。
事实上,监视这些指标可以基于采用最少数量的零件(通常每次取样至少250个零件)限定的长期尺度,基于该范围能够计算有足够良好的置信区间的诸如cpk之类的统计指标以使它们具有一定的可信度。
监视这些指标也可以基于相对于选取样本之后的时间间隔(通常为每周)进行限定的短期尺度;这使得能够在生产过快的情况下促进反应。
然而,当零件的制造流程不够充实时,即当所选取的样本的零件数量太少和/或在两次连续取样之间大不相同时,这些生产监视方法并不令人满意。
例如,涡轮叶片的生产常常变化很大,其中,各周的样本的大小可能大不相同(每个周期8至300个零件)。
本发明的目的在于提出一种基于对至少一个用于监视具有待采样的可变数量的零件和/或少量的零件的随机生产的有效统计指标的分析的零件制造方法。
本发明的另一目的在于提出一种基于对至少一个统计指标的分析的零件制造方法,该方法应对制造流程中的大幅变化并且足够稳定以应对最微不足道的生产偏差、以及使得能够实现制造流程的整体愿景。
技术实现要素:
为此,提出了一种基于对至少一个表示零件的特征尺寸的统计指标的分析来制造零件的方法,根据该方法:
a)着随时间推移选取多个样本,每个样本包括通过制造设备制成的多个零件;
b)测量样本的每个零件的特征尺寸;
c)针对所选取的每个样本根据以下项的指数加权计算特征尺寸的加权均值和加权标准差
关于选取的所述样本的零件所测量的特征尺寸的均值和标准差,
针对前述选取的样本计算的所述特征尺寸的加权均值和加权标准差;
d)针对所选取的每个样本以上述方式计算的根据加权均值和加权标准差来计算的统计指标的值;
e)将针对所选取的样本以上述方式计算的统计指标的值与参考值进行比较,例如检测统计指标的值与参考值之间的任何标准差。
f)根据比较结果、优选地通过调节用来制造零件的制造设备的调节参数以优化统计指标的值和参考值之间的偏差来调节引导零件的制造。
所呈现的步骤中的每一个优选地是自动实施的。
特征尺寸的测量步骤可以采用例如包括用于执行对零件的具体尺寸进行自动测量的传感器的测量设备来实施。
计算步骤可以通过合适的计算设备来执行,例如,诸如计算机之类的处理计算机数据装置。
调节步骤可以例如通过集成有用于集成并处理源自计算步骤的数据以校正生产中检测到的任何偏差、从而校正生产流程的调节设备来执行。特别地,调节设备设置成校正源自零件的生产设备的输入参数。
因此,调节设备优选地对用来制造零件的制造设备的调节参数进行调节整,例如以减少统计指标的值和参考值之间的偏差。
更一般地,目的在于优化统计指标的值和参考值之间的偏差以使零件的生产符合相关规范的要求。对用于修改或分别校正统计指标的值和参考值之间的偏差的生产参数进行修改。根据所使用的统计指标,优化偏差可以例如包括减小所识别的偏差。
优选地但是非限制性地,本方法的以单独或组合形式的方面如下:
所选取的每个样本中包含的零件的数量不是恒定的,并且为了计算在周期t+1内选取的每个样本的特征尺寸的加权均值和加权标准差,聚集的零件的数量nt+1根据以下公式来定义:
nt+1=λnt+1+(1-λ)nt
其中:
nt+1是在周期t+1内选取的样本中包含的零件的数量;
nt是样本在周期t内的聚集的零件的数量;
λ是介于0和1之间的加权系数。
所选取的每个样本中包含的零件的数量不是恒定的,并且为了针对在周期t+1内选取的每个样本计算特征尺寸的加权均值和加权标准差,聚集的零件的数量nt+1根据以下公式来定义:
nt+1=kλnt+1+(1-λ)nt
其中:
nt+1是在周期t+1内选取的样本中包含的零件的数量;
nt是样本在周期t内的总零件的数量;
λ是介于0和1之间的加权系数;
k是所确定的聚集系数,该系数严格大于1。
针对在周期t+1内选取的每个样本,根据以下公式来计算特征尺寸的加权均值mt+1和加权标准差st+1:
mt+1=λμt+1+(1-λ)mt
其中:
μt+1是有关在周期t+1内选取的样本的零件所测量的特征尺寸的均值;
mt是针对周期t计算的特征尺寸的加权均值;
σt+1是关于在周期t+1内选取的样本的零件所测量的特征尺寸的标准差;
st是针对周期t计算的特征尺寸的标准差;
λ是介于0和1之间的加权系数。
针对在周期t+1内选取的每个样本,根据以下公式来计算特征尺寸的加权均值mt+1和加权标准差st+1:
mt+1=λ*μt+1+(1-λ*)mt
其中:
μt+1是关于在周期t+1内选取的样本所测量的零件的特征尺寸的均值;
mt是针对周期t计算的特征尺寸的加权均值;
σt+1是关于在周期t+1内选取的样本的零件所测量的特征尺寸的标准差;
st是针对周期t计算的特征尺寸的标准差;
λ是介于0和1之间的加权系数;
λ*是由以下公式定义的中间加权系数:
所述至少一个统计指标为能力指数和/或定心系数。
将根据以下公式计算的能力指数cpk选择为统计指标:
其中:
mt+1是样本在周期t+1内的特征尺寸的加权均值,而st+1是特征尺寸的加权标准差;
ts是所测量的特征尺寸的上容差限;
ti是所测量的特征尺寸的下容差限。
将根据以下公式计算的能力指数cp选择为统计指标:
其中:
st+1是样本在周期t+1内的特征尺寸的加权标准差;
ts是所测量的特征尺寸的上容差限;
ti是所测量的特征尺寸的下容差限。
将根据以下公式计算的能力指数cc选择为统计指标:
其中:
mt+1是样本在周期t+1内的特征尺寸的加权均值;
ts是所测量的特征尺寸的上容差限;
ti是所测量的特征尺寸的下容差限。
附图说明
根据以下纯粹说明性而非限制性的、并且必须结合附图来查看的说明,本发明的其他特征和优点将呈现出来,在附图中:
图1为示出了针对多个取样类型的能力指数cpk随着时间推移而变化的图表;
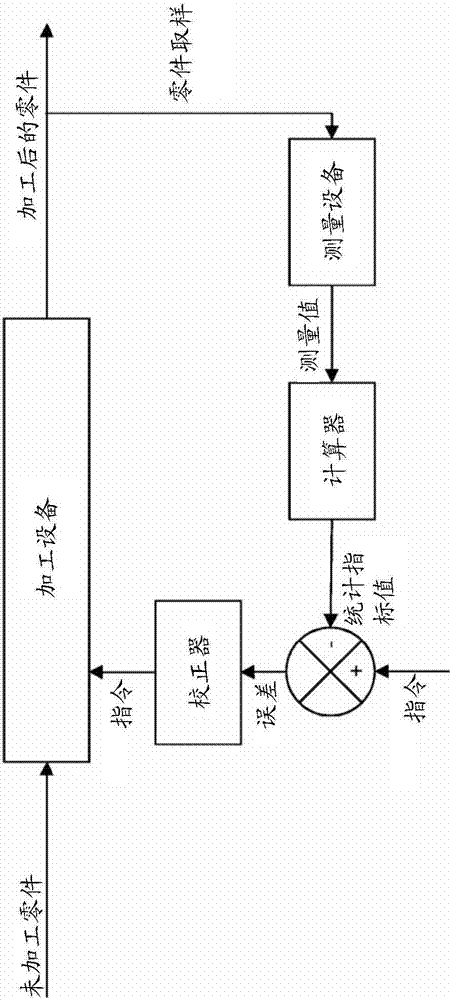
图2为示出了集采用零件取样对生产的控制及调节一体化的生产链的简图。
具体实施方式
为了响应在生产中不仅影响在取样期间测量的特征尺寸的均值、而且影响这些测量值的标准差的变化限制,提出了根据指数加权计算所选取的每个样本的特征尺寸的加权均值和加权标准差。
该计算优选地基于关于所选取的样本的零件所测量的特征尺寸的均值和标准差、以及针对事先选取的样本计算的特征尺寸的加权均值和加权标准差。
例如对均值的加权而言,所监视的指数为生产偏心的加权均值(记为mt),并且在周期t+1内根据周期t+1的偏心数据(记为μt+1)以及在周期t内计算的指数mt如下进行计算:
mt+1=λμt+1+(1-λ)mt
其中,λ∈[0;1]是事先选择的加权系数。
mt+1对应于均值μt+1和mt分别按各自的比例λ和(1-λ)的两个总体的混合。
该加权被称为是指数的,当研究上文中的公式时给出了:
mt+1=λμt+1+λ(1-λ)μt+λ(1-λ)2μt-1+λ(1-λ)3μt-2+λ(1-λ)4μt-3+…
在整个说明书中,与在周期t内选取的样本具体相关的特征对应的值由符合所述特征的小写字母后跟指数t来标注。相反地,与在周期t内选取的样本未具体相关而是与在周期0和t之间选取的所有样本具体相关的特征的值由符合所述特征的大写字母后跟指数t来标注。
因此,μt表示关于在周期t内选取的样本的零件标注的偏心均值,而mt表示根据在周期0和t之间选取的所有样本加权并计算的偏心均值。
以如对均值而言同样的方式,总体的标准差的指标st可以构造成给最后选取的样本赋予较大的权重,并计算为分别为σt+1(周期t+1的数据)和st(周期t的指数)的标准差按各自的比例λ和(1-λ)的两个总体的混合的标准差,具体如下:
实际上,优选地还考虑样本大小的变化。
在周期t内聚集的零件数量(记为nt)可以根据样本在时间t+1处的大小nt+1来定义并进行递归计算。
可能的聚集公式如下:
nt+1=λnt+1+(1-λ)nt
零件数量的该聚集公式给出了未累积的均值:分配给不同样本的系数之和为1。
如果关注于在给定的周数k(例如在所考虑的样本累积最后五次采样的测量值的情况下的k=5)中取样大小的简单求和,则分配给样本的权重之和将会是k(并且当然在没有该操作的情况下,根本没有没办法改变对校正后的均值及标准差的计算)。
该权重之和的挑战在于针对能力指数cpk计算置信区间:如果使用公式nt+1=λnt+1+(1-λ)nt来计算校正后的样本大小,其中取样大小为30个连续样本中的10个,则校正后的样本大小将始终为10,并且所计算的能力指数cpk的置信区间会很大;相反,如果注意到最后五次取样的蓄积大小(nt+1=nt+1+nt+nt-1+nt-2+nt-3),则累积的样本大小恒为50,并且能力指数cpk的置信区间将更佳。
因此,为了进一步改善对制造流程的监视及调节,将使用如下形式的部分蓄积公式来计算校正后的样本大小:
nt+1=kλnt+1+(1-λ)nt
其中,k>1,并且在用户根据他对反应性和累积取样要求在制造方法开始时λ∈[0;1]是固定的。
如果两个样本相对于它们各自的大小n1和n2来完成简单混合,则混合的均值和标准差可以由以下公式来计算:
μ=γμ1+(1-γ)μ2
和
其中
大小nt+1=kλnt+1+(1-λ)nt的“虚”总体与由两个大小分别为kλnt+1和(1-λ)nt的个体组成的群体完全相同。
因此,可以根据以下公式来定义在混合中控制的零件总体(记为λ*):
根据另一实施例,加权均值mt+1和加权标准差st+1可以通过以下公式来计算:
mt+1=λ*μt+1+(1-λ*)mt
和
然后,通过在定义这些统计指标的公式中用加权均值mt+1代替均值μ,用加权标准差st+1代替标准差σ,可以基于关于在样本的零件所测量的特征尺寸的均值和标准差通过使用常用的统计指标来进行对制造流程的监视及调节。
因此,例如能力指数cpk将根据以下公式来计算:
能力指数cp将根据以下公式来计算:
定心指数cc将根据以下公式来计算:
以下针对图1描述的示例示出了基于随机抽样通过根据值mt+1和st+1计算的加权指标带来的相当大的优点。
图1的曲线图示出了:
在曲线ih上,与关于有10个零件的滑动样本计算的能力指数cpk对应的第一指标的变化示出了根据现有技术的准则的短期尺度(表示例如一周的生产);
在曲线im上,与关于有40个零件的滑动样本计算的能力指数cpk对应的第二指标的变化示出了根据现有技术的准则的长期尺度;
在曲线ip上,与根据通过选择参数λ=0.25和k=4来计算的均值及加权标准差的值计算的能力指数cpk对应的第三指标(称为加权指标)的变化,这确保了随着每周取样10个零件,聚集样本将永久地具有等于40个零件的恒定大小nt。
该图示出了由曲线ih示出的指标是反应性的,但是由于有10个零件的样本的置信区间相当大,所以无法令人满意地表征所生产的总体。该曲线的波动也不易于揭示生产监视中的模式。事实上,该曲线趋向于显示对其变化的可读性造成损害的取样(噪声或振荡)的变化,或者趋向于在上升时剧烈波动(jubilant)或者在下降时缓慢波动(pessimistic)。
曲线im示出的指标累积了四周的数据,这使得该曲线显示了40个零件的样本大小,其在该示例中被认为足以表征令人满意的生产。但是显而易见,该曲线具有惰性,使得其对生产中的快速变化作出最小的反应。
曲线ip示出的加权指标也显示了40个零件的聚集样本大小,使得该样本大小足够“巨大”以使制造商具有被认为是令人满意的置信水平来表征生产。此外,这样的大小在面对快速的过度时不伴随有由曲线im示出的第二指标的危害那么大的惰性。经过检查,该曲线仅揭示了生产循环中的向上或向下的趋势。
因此,明显的是,加权指标累积了其它预先存在的指标两者的优点,而不会具有它们的任何缺点。
该曲线简化了对指标的读取和对生产的调节,并且使得其能够更相关以及最好地表征给定周期的总体。
正如根据以上描述呈现出来的那样,对均值和标准差进行加权的、针对总体混合根据类比公式得出的计算公式的结合使用极好地响应了生产监视的需要,为此必须将均值和标准差两者视为变量。
中间加权系数(记为λ*)的引入将所选取的样本的可变大小考虑在内。该中间加权系数的值确切地反应了在整体聚集样本中在前一周期期间受控制的零件的权重。
最后,蓄积系数(记为k)的引入对所测量的样本进行累积以使聚集样本的大小大于所选取的样本的平均大小(当在连续五周内执行监视时,样本的大小等于每周采样的大小的五倍)。
可以在零件的生产链中完全自动或部分自动地执行所提出的方法,这在生产期间控制了对制造流程进行调节,即调整制造条件以确保完成的零件继续响应所要求的质量标准。
图2给出了这种制造链的示例,在该制造链中,使用诸如5轴机床之类的加工设备根据具体指令来制造零件。该具体指令可以例如涉及特定的特征尺寸。代替该加工设备时,当然可以使用不限于零件加工的制造设备。
在该自动生产链中,当零件离开加工设备时对其进行取样以形成样本并将该样本发送到对所选取的样本的每个零件的一个或多个特征尺寸进行测量的测量设备。这种测量设备可以例如是具有自动地测量每个零件的优选特征尺寸的传感器的三维测量机床。
然后,将来自测量设备的测量数据发送给计算设备,该计算设备处理该测量数据以计算表示零件的特征尺寸中的一个特征尺寸的一个或多个统计指标。
然后,将所计算的统计指标的值与关于特征尺寸的参考指令进行比较以管理制造流程。更精确地,该比较结果可选地调整加工设备的输入参数。
如果偏差比较明显,则意味着发生错误,例如如果关于特征尺寸的统计指标的值在参考指令限定的可接受的范围之外,则通过校正器确定正确的测量值以调整加工设备的输入参数。修改加工设备的输入参数的目的在于校正明显的偏差以使关于特征尺寸的统计指标的值回到可接受的范围内。
- 还没有人留言评论。精彩留言会获得点赞!