信息提供系统的制作方法
本发明涉及信息提供系统,该信息提供系统从与提供对象的信息相关联的关键词中提供与由用户说出的关键词相关联的信息。
背景技术:
以往,已知有对通过发布等所获得的信息中、用户所期望并选择的信息进行提供的信息提供装置。
例如,专利文献1涉及的信息提供装置对从外部发布的内容的文本信息进行语言分析并提取关键词,将该关键词作为选项进行画面显示或语音输出,若用户通过语音输入选择关键词则提供该关键词所链接的内容。
已知有生成基于由用户发出的语音识别输入指令的语音识别装置中所使用的语音识别用的辞典数据的辞典数据生成装置。
例如,专利文献2涉及的辞典数据生成装置中,确定在用于显示关键词的显示装置中可显示的关键词的字符数,从与输入指令对应的文本数据中提取所述字符数范围内的字符串并设定为关键词,将与该关键词对应的语音的特征量数据和用于确定与输入指令对应的处理内容的内容数据相关联从而生成辞典数据。
现有技术文献
专利文献
专利文献1:日本专利特开2004-334280号公报
专利文献2:国际公开第2006/093003号
技术实现要素:
发明所要解决的技术问题
然而,例如专利文献1这样的现有技术中,未考虑在将关键词作为选项对用户进行画面显示情况下的显示字符数的限制。因此,在画面上可显示的字符数被限制的情况下,有时只能显示关键词的一部分。由此,用户无法正确地掌握关键词、无法说出正确的关键词,结果会产生无法提供用户通过说话而想要选择的内容的问题。
专利文献1涉及的辞典数据生成装置中,针对从内容中提取的关键词能追加具有近义关系的某一词汇,或能删除关键词的一部分,但不考虑显示字符数的限制而单纯的进行关键词的追加或删除中,与上述情况同样地存在超过在画面上可显示的字符数的可能性,所述问题未得到解决。
尤其是,在利用从外部发布的内容的情况下,具有内容时刻发生变化的特征,由于在信息提供装置侧不明确所发布的是何种含义的内容,因此难以事先确保足够的字符显示区域。
例如专利文献2这样的现有技术中,虽然考虑了可显示的字符数,但由于根据词性单位删除字符串来形成语音识别用的关键词,因此有丢失用于表示内容的重要信息的可能性。由此,存在用户无法正确地掌握在说出什么关键词时会提示出何种内容,无法访问所期望的内容的可能性。例如,针对“アメリカ大統領”(美国大总统)所涉及的内容设定了“アメリカ”(美国)这一关键词的情况下,会发生内容和关键词的背离。
尤其是,在语音输出内容的文本信息的情况下,用户在选择内容时应当利用实际听到的语音来说话。因此,作为识别对象语,不仅将最能准确表示语音输出的内容的含义的原本的关键词,还将与原本的关键词的含义或字符串中至少一方的差异较小的语句也包含在内,对于帮助用户理解识别对象语是有效的。进而,鉴于对关键词进行画面显示,即使假设由于字符串删除的影响而误识别出关键词并说话的情况下,也能有效地提供用户所期望选择的内容。
本发明是为了解决上述问题而完成的,其目的在于即使在画面上可显示的字符数受限的情况下,也能提供用户所期望选择的信息,由此提高操作性和便利性。
解决技术问题的技术方案
本发明涉及的信息提供系统,包括:获取部,该获取部从信息源获取提供对象的信息;生成部,该生成部根据获取部获取到的信息来生成第一识别对象语,并且利用将超过规定字符数的第一识别对象语缩短至该规定字符数后的全部字符串来生成第二识别对象语;存储部,该存储部将获取部获取到的信息、以及生成部生成的第一识别对象语和第二识别对象语进行关联并存储;语音识别部,该语音识别部识别用户的说话语音并输出识别结果字符串;以及控制部,该控制部将由生成部生成的规定字符数以内的字符串构成的第一识别对象语或第二识别对象语输出至显示部,并且在从语音识别部输出的识别结果字符串与第一识别对象语或第二识别对象语一致的情况下,从存储部获取关联的信息并输出至显示部或语音输出部。
发明效果
根据本发明,除了根据提供对象的信息生成第一识别对象语之外,还利用将第一识别对象语缩短至规定字符数后的全部字符串来生成第二识别对象语,因此,即使在被提示了由规定字符数以内的字符串构成的第一识别对象语或第二识别对象语的用户误识别该提示的字符串而说出了第一识别对象语以外的语句的情况下,也能基于第二识别对象语来识别。因此,能提供用户所期望选择的信息,从而提高操作性和便利性。
附图说明
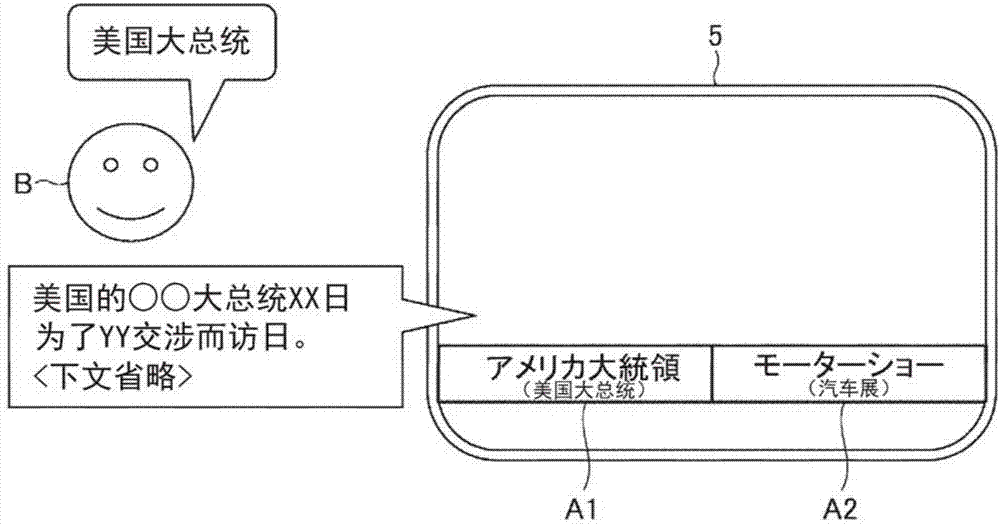
图1是说明本发明的实施方式1所涉及的信息提供系统及其周边设备的概要的图。
图2是说明实施方式1所涉及的信息提供系统的信息提供方法的图,示出了规定字符数为7个字符的情况。
图3是说明实施方式1所涉及的信息提供系统的信息提供方法的图,示出了规定字符数为5个字符的情况。
图4是表示实施方式1所涉及的信息提供系统及其周边设备的主要硬件结构的示意图。
图5是表示实施方式1所涉及的信息提供系统的结构例的功能框图。
图6是表示储存部储存的第一识别对象语、第二识别对象语和内容的一个示例的图。
图7是表示实施方式1所涉及的信息提供系统的动作的流程图,示出了内容获取时的动作。
图8是表示实施方式1所涉及的信息提供系统的动作的流程图,示出了从提示关键词到提供内容为止的动作。
图9是表示实施方式1所涉及的信息提供系统的变形例的功能框图。
具体实施方式
下面,为了更详细地说明本发明,根据附图对本发明的实施方式进行说明。
以下的实施方式中,以将本发明涉及的信息提供系统适用于搭载至车辆等移动体的车载器中的情况为例进行说明,但除了车载器之外,也可以适用于pc(personalcomputer:个人电脑)、平板pc、以及智能手机等移动信息终端。
实施方式1.
图1是说明本发明的实施方式1所涉及的信息提供系统1及其周边设备的概要的图。
信息提供系统1经由网络2从服务器3等信息源中获取内容,提取与内容相关联的关键词,通过在显示器5进行画面显示将关键词向用户进行提示。若关键词被用户说出,则说话语音从话筒6输入至信息提供系统1。信息提供系统1利用根据与内容相关联的关键词生成的识别对象语,识别由用户说出的关键词,通过将与识别出的关键词相关联的内容在显示器5进行画面显示或从扬声器4进行语音输出来提供给用户。
该显示器5是显示部,扬声器4是语音输出部。
例如,在信息提供系统1是车载器的情况下,由于存在对行驶中的显示内容进行限制的准则等,显示器5的画面上可显示的字符数受限。在信息提供系统1为移动信息终端的情况下,也由于显示器5较小、分辨率较低等理由使可显示的字符数受限。
下面,将在显示器5的画面上可显示的字符数称为“规定字符数”。
这里,利用图2和图3,对实施方式1所涉及的信息提供系统1的信息提供方法的概要进行说明。图2示出了在显示器5的字符显示区域a1、a2中可显示的规定字符数为7个字符的情况,图3示出了规定字符数为5个字符的情况。
如图2以及图3那样假设将新闻信息作为内容进行提供的信息提供系统1。假设新闻的标题为“アメリカ大統領がxx日に来日”(美国大总统xx日访日),新闻的正文为“アメリカの○○大統領がxx日、yy交渉のため来日する。<以後略>”(美国的○○大总统xx日为了yy交涉而访日。<下文省略>)。为了方便说明,将新闻正文的后续部分设为(下文省略)。
在该新闻的情况下,表示新闻内容的关键词例如为“アメリカ大統領”(美国大总统),识别对象语例如为“アメリカ大統領(アメリカダイトーリョー)”(美国大总统)。这里,将识别对象语的写法和读法以“写法(读法)”这样的方式记载。
图2中,关键词“アメリカ大統領”(美国大总统)在规定的字符数7个字符以内,因此信息提供系统1将关键词“アメリカ大統領”(美国大总统)直接显示在字符显示区域a1。针对该关键词“アメリカ大統領”(美国大总统)的识别对象语为“アメリカ大統領(アメリカダイトーリョー)”(美国大总统)。若用户b说出“アメリカ大統領(アメリカダイトーリョー)”(美国大总统),则信息提供系统1利用识别对象语识别有用户b说出的关键词,将与识别出的关键词相关联的新闻的正文“アメリカの○○大統領がxx日、yy交渉のため来日する。<以後略>”(美国的○○大总统xx日为了yy交涉而访日。<下文省略>)从扬声器4进行语音输出。信息提供系统1除了语音输出之外、或者代替语音输出,也可以将新闻的标题或新闻正文中的一部分(例如开头)等显示在显示器5。
另一方面,由于图3中规定字符数为5个字符,关键词“アメリカ大統領”(美国大总统)超过了规定字符数。该情况下,信息提供系统1将关键词缩短至规定字符数后的字符串“アメリカ大”显示在字符显示区域a1。针对该关键词“アメリカ大”的识别对象语为第一识别对象语“アメリカ大統領(アメリカダイトーリョー)”、以及第二识别对象语“アメリカ大(アメリカダイ)”等。若用户b说出“アメリカ大統領(アメリカダイトーリョー)”或“アメリカ大(アメリカダイ)”,则信息提供系统1利用识别对象语识别由用户b说出的关键词,与图2的情况同样地将与识别出的关键词相关联的新闻的文本进行语音输出或画面显示。
图2以及图3的示例中,设显示关键词的区域有字符显示区域a1、a2两个,但字符显示区域不限于两个。
图4是表示实施方式1中的信息提供系统1及其周边设备的主要硬件结构的示意图。在总线100连接有cpu(centralprocessingunit:中央处理单元)101、rom(readonlymemory:只读储存器)102、ram(randomaccessmemory:随机存取存储器)103、输入装置104、通信装置105、hdd(harddiskdrive:硬盘驱动器)106、输出装置107。
cpu101通过读取储存在rom102或hdd106的各种程序并执行,从而与各硬件协作来实现信息提供系统1的各种功能。对于cpu101实现的信息提供系统1的各种功能,利用下文所述的图5进行说明。
ram103是在程序执行时使用的储存器。
输入装置104接收用户输入,为话筒、遥控器等操作设备、或触摸式传感器等。图1中作为输入装置104的示例图示出了话筒6。
通信装置105经由网络2与服务器3等信息源进行通信。
hdd106使外部储存装置的一个示例。作为外部储存装置,除了hdd之外,还包含cd、dvd、或usb储存器以及sd卡等采用了闪存的储存器。
输出装置107向用户提示信息,为扬声器、液晶显示器、或有机el(electroluminescence:电致发光)等。图1中作为输出装置107的例子,图示出了扬声器4和显示器5。
图5是表示实施方式1所涉及的信息提供系统1的结构例的功能框图。
该信息提供系统1包括获取部10、生成部11、语音识别辞典16、关联判定部17、储存部18、控制部19以及语音识别部20。获取部10、生成部11、关联判定部17、控制部19以及语音识别部20的功能通过cpu101执行程序来实现。语音识别辞典16以及储存部18是ram103或hdd106。
此外,构成信息提供系统1的获取部10、生成部11、语音识别辞典16、关联判定部17、储存部18、控制部19以及语音识别部20可以如图5所示那样集成在一个装置内,或者也可以分散在网络上的服务器和智能手机等移动信息终端和车载器中。
获取部10经由网络2从服务器3中获取以html(hypertextmarkuplanguage:超文本标记语言)或xml(extensiblemarkuplanguage:可扩展标记语言)形式所记叙的内容。并且,获取部10基于对获取到的内容所赋予的现有的标签信息等来解释含义,去除附带的信息等来抽出主要部分的信息,向生成部11和关联判定部17进行输出。
此外,作为网络2,例如能使用互联网以及移动电话等公用线路。
服务器3是储存新闻等内容的信息源。在实施方式1中,作为“内容”,例示了信息提供系统1经由网络2从服务器3可获取的新闻的文本信息,但不限于此,也可以是单词辞典等知识数据库服务或菜谱等文本信息。也可以是预先存储在信息提供系统1的内部的内容等不需要经由网络2获取的内容。
进而,内容不限定于文本信息,也可以是视频信息、语音信息等。
获取部10例如在服务器3每次进行发布时获取所发布的新闻的文本信息,或根据来自用户的请求获取存储在服务器3的菜谱的文本信息。
生成部11包括第一识别对象语生成部12、显示字符串判定部13、第二识别对象语生成部14以及识别辞典生成部15。
第一识别对象语生成部12从获取部10获取到的内容的文本信息中提取与该内容相关联的关键词,根据关键词生成第一识别对象语。关键词的提取利用词法分析处理等公知的自然语言处理技术等,以将该内容的文本信息中所包含的专有名词、文本信息的标题或文本的开头的名词、文本信息中频繁出现的名词等表示内容含义的重要语进行提取的方法为代表,可以使用任意方法。例如,第一识别对象语生成部12将新闻的标题“アメリカ大統領がxx日に来日”(美国大总统xx日访日)中、开头的名词“アメリカ大統領”(美国总统)提取出作为关键词,将其写法和读法设定为第一识别对象语“アメリカ大統領(アメリカダイトーリョー)”(美国大总统)。第一识别对象语生成部12将生成的第一识别对象语输出至显示字符串判定部13和识别辞典生成部15。关键词和第一识别对象语的写法相同。
第一识别对象语生成部12也可以针对第一识别对象语追加预先设定的字符串。例如将在第一识别对象语“アメリカ大統領”(美国大总统)后面追加了“のニュース”(的新闻)这样的字符串后的“アメリカ大統領のニュース”(美国大总统的新闻)作为第一识别对象语。对第一识别对象语追加的字符串不限于此,此外,在第一识别对象语的前后任一方追加字符串均可。第一识别对象语生成部12可以将“アメリカ大統領”(美国大总统)和“アメリカ大統領のニュース”(美国大总统的新闻)双方均作为第一识别对象语,也可以将其中一方作为识别对象语。
显示文字判定部13基于显示器5的字符显示区域a1、a2的信息判定在该区域可显示的规定字符数。并且,显示字符串判定部13判定第一识别对象语生成部12生成的第一识别对象语是否超过了规定字符数,在超过了的情况下生成将第一识别对象语缩短至规定字符数的字符串,输出至第二识别对象语生成部14。实施方式1中,将第一识别对象语缩短至规定字符数后的字符串、和下文所述的第二识别对象语的写法相同。
字符显示区域a1、a2的信息只要是表示字符数或像素数等区域的尺寸则可以是任何形式。字符显示区域a1、a2可以是预先确定的尺寸,在显示区域或显示画面的尺寸动态变化的情况下,字符显示区域a1、a2的尺寸也可以动态变化。在字符显示区域a1、a2的尺寸动态变化的情况下,例如从控制部19向显示字符串判定部13通知字符显示区域a1、a2的信息。
例如第一识别对象语为“アメリカ大統領(アメリカダイトーリョー)”(美国大总统)的情况下,若假设规定字符数为5个字符,则显示字符串判定部13删除“アメリカ大統領”最后2个字符即“统”从而缩短为从开头起5个字符量的字符串“アメリカ大”。显示字符串判定部13将缩短了第一识别对象语的字符串“アメリカ大”输出至第二识别对象语生成部14。此外,该例子中将第一识别对象语缩短为从开头起5个字符量的字符串,但只要是将第一识别对象语缩短至规定字符串的方法即可。
另一方面,在第一识别对象语为“アメリカ大統領(アメリカダイトーリョー)”且规定字符数为7个字符以内的情况下,显示字符串判定部13将“アメリカ大統領”(美国总统)直接输出至第二识别对象语生成部14。
第二识别对象语生成部14在从显示字符串判定部13接收到将第一识别对象语缩短至规定字符数后的字符串的情况下,生成第二识别对象语。例如在将“アメリカ大統領”(美国大总统)缩短后的字符串为“アメリカ大”的情况下,第二识别对象语生成部14将其写法和读法设定为“アメリカ大(アメリカダイ)”(美国大)。第二识别对象语生成部14例如生成第一识别对象语的读法中、缩短至规定字符数后的字符串的读法来作为第二识别对象语的读法。第二识别对象语生成部14将生成的第二识别对象语输出至识别辞典生成部15。另一方面,从显示字符串判定部13接收到未缩短的第一识别对象语的情况下,第二识别对象语生成部14不生成第二识别对象语。
该示例中,说明了针对一个内容生成一组第一识别对象语和第二识别对象语的情况,但在存在多个与内容相关联的关键词的情况等中也可以针对一个内容生成多组第一识别对象语和第二识别对象语。此外,第一识别对象语的数量和第二识别对象语的数量不需要一致。
识别辞典生成部15从第一识别对象语生成部12接收第一识别对象语,并且从第二识别对象语生成部14接收第二识别对象语。并且,识别辞典生成部15登录至语音识别辞典16从而将第一识别对象语和第二识别对象语包含至识别词汇中。识别辞典生成部15将第一识别对象语和第二识别对象语输出至关联判定部17。
语音识别辞典16可以是任何形式,例如将可识别的单词串作为语法进行记叙那样的网络语法的形式、或将单词的衔接进行概率上的模型化后的统计学语言模型这样的形式等。
话筒6对用户b发出的语音进行收音并输出至语音识别部20,则语音识别部20参照语音识别辞典16对用户b的说话语音进行识别,将识别结果字符串输出至控制部19。语音识别部20的语音识别的方法使用现有技术即可,因此省略说明。
然而,车载导航系统等车载器中搭载的语音识别功能中,为了对信息提供系统1明确地指示用户b开始说话,因此有时设置有指示语音识别开始的按钮。该情况下,语音识别部20在通过用户b按下该按钮之后识别所说出的语音。
在未设置指示语音识别开始的按钮的情况下,例如语音识别部20始终接收话筒6进行收音的语音,检测相当于用户b说出的内容的说话区间,识别说话区间的语音。
关联判定部17接收获取部10获取到的内容的文本信息,并且从识别辞典生成部15接收第一识别对象语和第二识别对象语。并且,关联判定部17判定第一识别对象语、第二识别对象语和内容的对应关系,将第一识别对象语和第二识别对象语与内容的文本信息进行关联并储存至储存部18。
储存部18将当前能提供的内容、第一识别对象语和第二识别对象语进行关联并储存。
这里,图6中示出了储存部18储存的第一识别对象语、第二识别对象语和内容的一个示例。图6是规定字符数为5个字符的情况的例子。将第一识别对象语“アメリカ大統領(アメリカダイトーリョー)”(美国大总统)、第二识别对象语“アメリカ大(アメリカダイ)(美国大)”、和作为内容的新闻正文“アメリカの○○大統領がxx日、yy交渉のため来日する。<以後略>”(美国的○○大总统xx日为了yy交涉而访日。<下文省略>)进行关联。将第一识别对象语“モーターショー(モーターショー)”(汽车展)、第二识别对象语“モーターシ(モーターシ)”、和新闻正文“2年に1度のモーターショーがxx日、開幕する。<以後略>”(两年一度的汽车展在xx日开幕。<下文省略>)进行关联。
在第一识别对象语在规定字符数以内的情况下,不生成第二识别对象语,因此,仅将第一识别对象语和内容进行关联并储存至储存部18。
储存部18储存的内容不限于文本信息,也可以是视频信息、语音信息等。
控制部19将规定字符数以内的第一识别对象语或第二识别对象语输出至显示器5,并且在从语音识别部20输出的识别结果字符串与第一识别对象语或第二识别对象语一致的情况下,从储存部18获取关联的信息,并输出至显示器5或扬声器4。
更详细而言,控制部19获取储存部18中储存的内容的文本信息,作为当前可提供的内容的文本信息向语音识别部20进行通知。控制部19从储存部18获取与当前可提供的内容的文本信息相关联并储存的第二识别对象语,如图3所示,显示在显示器5的字符显示区域a1、a2。第二识别对象语存在于储存部18的情况是第一识别对象语超过规定字符数的情况。
另一方面,储存部18中仅储存与当前可提供的内容的文本信息相关联的第一识别对象语,而没有第二识别对象语的情况是第一识别对象语在规定字符数以内的情况。该情况下,如图2所示,控制部19从储存部18获取第一识别对象语并显示在显示器5的字符显示区域a1、a2。
控制部19从语音识别部20接收识别结果字符串,将该识别结果字符串与储存在储存部18的第一识别对象语和第二识别对象语进行对照,获取与识别结果字符串一致的第一识别对象语或第二识别对象语相关联的内容的文本信息。
控制部19对获取到的内容的文本信息进行语音合成并从扬声器4语音输出。由于语音合成中采用公知技术即可,因此省略说明。
信息的显示方式只要根据该信息的种类使用户能恰当地识别信息即可,例如控制部19可以将文本信息的开头一部分在显示器5上进行画面显示,或通过滚动使文本信息的全文进行画面显示。
在内容为视频信息的情况下,控制部19可以使该视频信息在显示器5上进行画面显示。在内容为语音信息的情况下,控制部19可使该语音信息从扬声器4语音输出。
接下来,利用图7和图8所示的流程图,对实施方式1所涉及的信息提供系统1的动作进行说明。
这里,作为获取从新闻提供服务的服务器3发布的内容的情况进行说明。为了简化说明,设信息提供系统1通过网络2获取到服务器3发布的新闻α、新闻β两个新闻内容。假设新闻α的标题为“アメリカ大統領がxx日に来日”(美国大总统xx日访日),正文为“アメリカの○○大統領がxx日、yy交渉のため来日する。<以後略>”(美国的○○大总统xx日为了yy交涉而访日。<下文省略>)。假设新闻β的标题为“モーターショーが東京で開幕”(汽车展在东京开幕),正文为“2年に1度のモーターショーがxx日、開幕する。<以後略>”(两年一度的汽车展在xx日开幕。<下文省略>)。
接着,利用图7所示的流程图,说明内容获取时的动作。
首先,获取部10经由网络2获取从服务器3发布的内容,通过分析标签等去除内容的附带信息,获取新闻α、β的标题以及正文等主要部分的文本信息(步骤st1)。获取部10将内容的文本信息输出至第一识别对象语生成部12和关联判定部17。
接着,第一识别对象语生成部12从获取部10获取到的内容的文本信息中提取关键词,生成第一识别对象语(步骤st2)。第一识别对象语生成部12将第一识别对象语输出至显示字符串判定部13和识别辞典生成部15。
这里,第一识别对象语生成部12使用词法分析等自然语言处理技术,将新闻的标题的最开始出现的名词(也包含复合名词)提取作为关键词,生成关键词的写法和读法并设定为第一识别对象语。即,若对应于新闻α、β的具体例,则新闻α的第一识别对象语为“アメリカ大統領(アメリカダイトーリョー)”(美国大总统),新闻β的第一识别对象语为“モーターショー(モーターショー)”(汽车展)。
接着,显示字符串判定部13基于显示器5的字符显示区域a1、a2的信息判定在这些字符显示区域a1、a2可显示的规定字符数,判断从显示字符串判定部13接收到的第一识别对象语是否超过规定字符数,即是否能在字符显示区域a1、a2显示第一识别对象语的全部字符(步骤st3)。在无法显示第一识别对象语的全部字符的情况下(步骤st3为“否”),显示字符串判定部13生成将第一识别对象语缩短至规定字符数后的字符串(步骤st4)。显示字符串判定部13将使第一识别对象语缩短至规定字符数后的字符串输出至第二识别对象语生成部14。
这里,设字符显示区域a1、a2的规定字符数为5个字符进行说明。该情况若与上文所述的具体例对应,则由于新闻α、β中第一识别对象语均超过5个字符,因此无法全部显示。因此,显示字符串判定部13将新闻α的第一识别对象语缩短至5个字符成为“アメリカ大”(美国大),将新闻β的第一识别对象语缩短至5个字符成为“モーターシ”(汽车)或“モーターショ”(车展)。下面对缩短为“モーターシ”(汽车)的情况进行说明。
接着,第二识别对象语生成部14从显示字符串判定部13接收将第一识别对象语缩短至规定字符数后的字符串,利用该字符串中包含的全部字符生成第二识别对象语(步骤st5)。第二识别对象语生成部14例如生成第一识别对象语的读法中、缩短至规定字符数后的字符串的读法来作为第二识别对象语的读法。即,若与上文所述的具体例对应,则新闻α的第二识别对象语为“アメリカ大(アメリカダイ)”(美国大),新闻β的第二识别对象语为“モーターシ(モーターシ)”(汽车)。第二识别对象语生成部14将第二识别对象语输出至识别辞典生成部15。
另一方面,在能将第一识别对象语的全部字符以规定字符数以内显示的情况下(步骤st3为“是”),显示字符串判定部13跳过步骤st4、st5的处理前进至步骤st6。
接着,识别辞典生成部15从第一识别对象语生成部12接收第一识别对象语,作为识别对象语登录至语音识别辞典16(步骤st6)。识别辞典生成部15在无法显示第一识别对象语的全部字符的情况下,从第二识别对象语生成部14接收第二识别对象语,除了第一识别对象语以外,也将该第二识别对象语也作为识别对象语登录至语音识别辞典16(步骤st6)。若与上文所述的具体例对应,则第一识别对象语“アメリカ大統領(アメリカダイトーリョー)”(美国大总统)“モーターショー(モーターショー)”(汽车展)、和第二识别对象语“アメリカ大(アメリカダイ)”(美国大)“モーターシ(モーターシ)”(汽车)作为识别对象语登录至语音识别辞典16。
进而,识别辞典生成部15将登录在语音识别辞典16的识别对象语向关联判定部17进行通知。
接着,关联判定部17从获取部10接收内容的文本信息,并且从识别辞典生成部15接收识别对象语的通知,判定内容和识别对象语的对应关系,将两者进行关联并储存至储存部18(步骤st7)。
接下来,利用图8所示的流程图,对从提示关键词到提供内容的动作进行说明。
首先,控制部19参照储存部18,在储存有与当前可提供的内容相关联的第二识别对象语的情况下,获取该第二识别对象语,作为与该内容相关联的关键词显示在显示器5的字符显示区域a1、a2(步骤st11)。控制部19在未储存有与当前可提供的内容相关联的第二识别对象语、而仅储存有第一识别对象语的情况下,获取该第一识别对象语,作为与该内容相关联的关键词显示在显示器5的字符显示区域a1、a2(步骤st11)。如上所述,将与字符显示区域a1、a2的尺寸相对应的第一识别对象语或第二识别对象语作为关键词进行显示,从而对用户b进行提示。
若与上文所述的具体例对应,则由于新闻α、β的第一识别对象语在字符显示区域a1、a2显示不下,因此,作为第二识别对象语的“アメリカ大”(美国大)“モーターシ”(汽车)显示在显示器5的字符显示区域a1、a2。
控制部19通过在步骤st11中提示关键词之前、或与提示关键词一起语音输出新闻α、β的标题或正文开头部分等,从而也可以向用户b通知当前可提供的新闻的概要。
在步骤st11之后,话筒6对用户b的说话语音进行收音,输出至语音识别部20。
语音识别部20接收通过话筒6输入的用户b的说话语音(步骤st12),在有说话语音输入的情况下(步骤st12为“是”),则利用语音识别辞典16识别该说话语音(步骤st13)。语音识别部20将识别结果字符串输出至控制部19。
若与上文所述的具体例对应,则在用户b说出“アメリカ大(アメリカダイ)”(美国大)时,语音识别部20利用语音识别辞典16识别该说话语音,将“アメリカ大”(美国大)作为识别结果字符串输出至控制部19。
接着,控制部19从语音识别部20接收识别结果字符串,将该识别结果字符串作为检索词检索储存部18,获取与识别结果字符串对应的内容的文本信息(步骤st14)。
若与上文所述的具体例对应,则识别结果字符串“アメリカ大”(美国大)与新闻α的第二识别对象语“アメリカ大(アメリカダイ)”(美国大)一致,因此从储存部18获取新闻α的正文“アメリカの○○大統領がxx日、yy交渉のため来日する。<以後略>”(美国的○○大总统xx日为了yy交涉而访日。<下文省略>)。
接着,控制部19语音合成从储存部18获取到的内容的文本信息并从扬声器4将其语音输出,将文本信息的开头一部分在显示器5进行画面显示(步骤st15)。从而,提供用户b所期望选择的内容。
由上文可知,根据实施方式1,信息提供系统1构成为包括:获取部10,该获取部10从服务器3获取提供对象的内容;生成部11,该生成部11根据获取部10获取到的内容生成第一识别对象语,并且利用将超过规定字符数的第一识别对象语缩短至该规定字符数后的全部字符串来生成第二识别对象语;储存部18,该储存部18将获取部10获取到的内容、以及生成部11生成的第一识别对象语和第二识别对象语进行关联并储存;语音识别部20,该语音识别部20识别用户b的说话语音并输出识别结果字符串;以及控制部19,该控制部19将由生成部11生成的规定字符串以内的字符串构成的第一识别对象语或第二识别对象语输出至显示器5,并且在从语音识别部20输出的识别结果字符串与第一识别对象语或第二识别对象语一致的情况下,从储存部18获取关联的内容并输出至显示器5或扬声器4,因此,在被提示了由规定字符数以内的字符串构成的第一识别对象语或第二识别对象语的用户b对该提示的字符串进行误识别而说出了第一识别对象语以外的语句的情况下,也能基于第二识别对象语进行识别。因此,能提供用户b所期望选择的信息,从而提高操作性和便利性。
实施方式1的第二识别对象语生成部14构成为将使作为关键词的第一识别对象语缩短至规定字符数后的字符串直接作为第二识别对象语来使用,但也可以构成为加工该字符串而生成第二识别对象语。
下面,对第二识别对象语的生成方法来说明变形例。
例如,第二识别对象语生成部14也可以针对将第一识别对象语缩短至规定字符数后的字符串生成一个以上的读法来作为第二识别对象语的读法。该情况下,第二识别对象语生成部14例如可以进行词法分析处理来判定一个以上的读法,或者利用未图示的单词辞典等来判定一个以上的读法。
具体而言,作为“アメリカ大”(美国大)这个第二识别对象语的读法,除了与第一识别对象语的读法相同的“アメリカ大(アメリカダイ)”(美国大)之外、或者取而代之,第二识别对象语生成部14还可以赋予“アメリカ大(アメリカオー)”“アメリカ大(アメリカタイ)”这样的读法。
从而,提高了即使在用户b说出了与第一识别对象语的读法不同的读法的情况下,也能提供用户b所期望选择的内容的可能性,进一步提高用户b的操作性和便利性。
此外例如,第二识别对象语生成部14也可以针对将第一识别对象语缩短至规定字符数后的字符串的读法追加其它字符串的读法来作为第二识别对象语的读法。该情况下,第二识别对象语生成部14例如利用未图示的单词辞典等检测该其它字符串即可。所生成的第二识别对象语的读法成为包含缩短后的全部字符串的其它语句的读法。
具体而言,第二识别对象语生成部14针对缩短了“アメリカ大統領”(美国大总统)后的字符串“アメリカ大”(美国大)追加其它字符串“陸”(陆)生成“アメリカ大陸”(美国大陆)这样的字符串,将生成的“アメリカ大陸”(美国大陆)的读法(アメリカタイリク)作为第二识别对象语“アメリカ大”(美国大)的读法。
从而,提高了即使在用户b说出了与第一识别对象语的读法不同的读法的情况下,也能提供用户b所期望选择的内容的可能性,进一步提高用户b的操作性和便利性。
此外例如,第二识别对象语生成部14也可以将第一识别对象语缩短至规定字符数后的字符串置换为规定字符数以内且与第一识别对象语同义的其它字符串,生成其它的第二识别对象语。该情况下,第二识别对象语生成部14例如利用未图示的单词辞典等检索规定字符数以内且与第一识别对象语同义的其它字符串即可。
具体而言,第二识别对象语生成部14针对“アメリカ大統領(アメリカダイトーリョー)”(美国大总统)这个第一识别对象语,将“米国大統領(ベーコクダイトーリョー)”(美国大总统)这一规定字符数5个字符以内且同义的字符串生成为第二识别对象语。第二识别对象语生成部14除了“アメリカ大”之外还将“米国大統領”(美国大总统)设定为第二识别对象语。
由此,提高了即使在用户b说出了与第一识别对象语的读法不同的读法的情况下,也能提供用户b所期望选择的内容的可能性,进一步提高用户b的操作性和便利性。
进而,控制部19也可以不是使对用户b提示的字符串变更为将第一识别对象语缩短至规定字符数后的字符串“アメリカ大”(美国大),而是变更为置换成其他字符串的其它第二识别对象语的写法“米国大統領”(美国大总统)来作为关键词。
例如,第二识别对象语生成部14也可以将多组所述的变形例进行组合,从而生成多个第二识别对象语。
例如,第二识别对象语生成部14也可以基于用户b的说话记录来生成第二识别对象语的读法。图9示出了该情况的信息提供系统1的结构例。
图9中,对信息提供系统1追加记录储存部21。该记录储存部21将语音识别部20的识别结果字符串储存为用户b的说话记录。第二识别对象语生成部14获取储存在记录储存部21的识别结果字符串,设定为第二识别对象语的读法。
具体而言,生成“アメリカ大(アメリカダイ)”(美国大)“アメリカ大(アメリカオー)”(美国大)这两种第二识别对象语,在用户b说出“アメリカ大(アメリカダイ)”(美国大)的情况下,之后第二识别对象语生成部14生成赋予了用户b过去说出的读法“アメリカ大(アメリカダイ)”(美国大)这样的第二识别对象语。
这时,第二识别对象语生成部14也可以构成为不仅单纯地根据用户b过去是否说过,也可以进行频次分布等统计处理,将预先设定的概率以上的读法赋予给第二识别对象语。
从而,能将用户b的说话偏好反映至语音识别处理中,因此在用户b说出与第一识别对象语的读法不同的读法的情况下,也提高了能提供用于b所期望选择的内容的可能性,进一步提高用户b的操作性和便利性。
进而,第二识别对象语生成部14也可以基于每个用户的说话记录,生成与用户匹配的第二识别对象语。该情况下,例如图9所示,用户识别部7识别当前的用户b,将识别结果输出至第二识别对象语生成部14和记录储存部21。记录储存部21与由用户识别部7通知的用户b进行关联,储存识别结果字符串。第二识别对象语生成部14从记录储存部21获取与由用户识别部7通知的用户b进行关联并储存的识别结果字符串,设定为第二识别对象语的读法。
用户识别部7的识别方法可以是针对用户要求用户名和密码等的输入的登录认证、或基于用户的面部或指纹等的生物认证等,只要是可识别用户的方法即可。
此外,通过图7的流程图所示的动作生成的第一识别对象语以及第二识别对象语被登录在语音识别辞典16,但至少对于第二识别对象语,也可以在获取部10获取到新的内容的情况或者服务器3结束旧的内容提供的情况、或者到达预先设定的时间的情况等,在预先设定的定时将所述第二识别对象语删除。
到达预先设定的时间的情况是指,例如从第二识别对象语被登录在语音识别辞典16的时间点起经过了规定时间(例如24小时)的定时,到达规定时刻(例如每天早上6点)的定时等。进一步地,也可以构成为由用户设定从语音识别辞典16中删除第二识别对象语的定时。
从而,能删除用户b说出的可能性较低的识别对象语,变得能降低构成语音识别辞典16的ram103或hdd106中的使用区域。
另一方面,在未删除登录至语音识别辞典16的识别对象语的情况下,为了缩短识别处理的时间,例如也可以使语音识别部20从控制部19获取当前可提供的内容的文本信息,通过将登录至语音识别辞典16的第一识别对象语和第二识别对象语中、与该内容的文本信息对应的第一识别对象语和第二识别对象语有效化从而规定可识别的词汇。
此外,实施方式1的控制部19进行对第一识别对象语或将第一识别对象语缩短至规定字符数后的字符串进行画面显示的控制,但也可以控制显示器5使这些字符串作为用户b能选择的软件键。软件键只要是用户b利用输入装置104可进行选择操作的键即可,例如通过触摸式传感器能进行选择的触摸按钮、或通过操作装置能进行选择的按钮等。
此外,实施方式1所涉及的信息提供系统1中,构成为与识别对象语为日语的情况相匹配,但也可以构成为与日语之外的语言相匹配。
另外,本发明在其发明范围内可以对实施方式的任意结构要素进行变形,或者在实施方式中省略任意的结构要素。
工业上的实用性
本发明涉及的信息提供系统,除了根据提供对象的信息生成第一识别对象语之外,还利用将第一识别对象语缩短至规定字符数后的全部字符串生成第二识别对象语,因此适用于能显示在画面上的字符数受限的车载器以及移动信息终端等。
标号说明
1信息提供系统、
2网络、
3服务器(信息源)、
4扬声器(语音输出部)、
5显示器(显示部)、
6话筒、
7用户识别部、
10获取部、
11生成部、
12第一识别对象语生成部、
13显示字符串判定部、
14第二识别对象语生成部、
15识别辞典生成部、
16语音识别辞典、
17关联判定部、
18储存部、
19控制部、
20语音识别部、
21记录储存部、
100总线、
101cpu、
102rom、
103ram、
104输入装置、
105通信装置、
106hdd、
107输出装置。
- 还没有人留言评论。精彩留言会获得点赞!