数据分析系统、数据分析方法、数据分析程序及存储介质与流程
本发明涉及一种用于分析数据的数据分析系统等。
背景技术:
由于计算机的快速发展,社会的信息化得到进步,其结果是,海量信息(大数据)关系到企业和个人的活动。由此,从大数据中分辨希望的信息的必要性受到重视。
作为用于从大数据中提取希望的信息的途径,例如,存在以下途径:通过将数据预先分类来提取希望的数据的途径、基于简单的文本检索就能够提取希望的数据的途径、基于自然语言处理来提取希望的数据的途径等。
例如,在下述专利文献1中提出了一种装置,其目的在于,提供一种为了从大数据中提取信息,能够基于文件集合中的提取关键词之间的关系,对相关度深的提取关键词灵活且接近地进行配置的结构,针对进行领域分类的文件中包括的关键词计算用于与其他文件辨别的贡献度,并基于该计算出的贡献度利用自身组织化图谱,对所述文件按单元进行分类并显示,然后根据该单元中的所述文件中包括的关键词的出现频率来计算该关键词的配置信息,并配合单元来显示。
现有技术文献
专利文献
专利文献1日本特开2014-056516号公报
技术实现要素:
技术问题
为了从大数据中精确地发现对用户而言所需要的信息,尽管仍需要对仅凭关键词或符号无法掌握用户意图或检索目的、乃至对用户而言的数据整体的印象等的因素加以考虑,然而由于上述现有方法无论如何都并不充分,因此,用户最终需要对庞大的信息逐个分辨,从而无法避免浪费大量的精力和时间。
因此,本发明的目的在于,提供一种能够有效地发现用户所需要的信息的数据分析技术。
技术方案
本发明是涉及评价对象数据的数据分析的发明,其对多个对象数据进行评价,该评价例如可以对应于各对象数据与预定案例的相关性。另外,通过所述评价生成能够使所述多个对象数据序列化的指标,且基于用户给予的输入使所述指标发生变化。
所述多个对象数据的序列例如与基于所述输入而变化的所述指标相对应地变化。所述输入例如基于该参照数据和所述预定案例的相关性,来对与所述多个对象数据不同的参照数据进行分类。该分类例如根据所述参照数据的内容而分为多个分类信息,且所述多个分类信息中的至少一个根据所述输入被赋予至所述参照数据。
本发明例如针对所述参照数据中包括的多个结构要素,来评价对由所述输入控制装置提供的组合分别贡献的程度,由此根据通过所述输入赋予的分类信息,从该参照数据中提取以该参照数据为特征的模式。
本发明例如基于所述提取的模式来评价所述对象数据和所述预定案例的相关性并决定所述指标,将所述决定好的指标设定为所述对象数据,根据所述指标将所述多个对象数据序列化,并将所述序列化后的多个对象数据通知给用户。
根据序列化后的多个对象数据,用户例如可以在多个对象数据之间知道与所述预定案例的相关性的大小。在用户对多个对象数据之间的相关性的大小无法同意的情况下,若变更对参照数据赋予的分类信息,则根据该变更,指标发生变化,进而,根据变化后的指标,使多个对象数据的序列发生变化。用户例如在理解参照数据整体的内容后,根据其内容来决定对参照数据赋予的分类信息。用户视参照数据的内容的情况,有可能会苦恼参照数据中的多个分类信息中哪个分类信息最适合。用户例如可以根据所述序列化后的多个对象数据,来决定应该对参照数据赋予哪个分类信息。
发明的效果
本发明可以实现有效地发现用户所需要的信息的效果。
附图说明
图1是表示数据分析系统的硬件结构的一例的框图。
图2是表示业务服务器的功能结构的一例的功能框图。
图3是表示数据分析系统的动作例的流程图。
图4是表示用于输入对参照数据的分类的界面(输入画面)的一例的示意图。
图5是表示用于输入对参照数据的分类的界面(输入画面)的其他例的示意图。
图6是存储对象数据的管理表的一例。
图7是表示通过对对象数据进行回归解析而获得的指数函数模型的特性例的图表。
图8是表示重新评价指数函数模型而获得的上述指数函数模型的特性例的图表。
图9是表示数据分析系统的管理画面的一例的示意图。
图10是表示多个节点间的相关关系的画面的一例。
图11中,(a)是对象数据的摘要生成概念图,(b)是表示分类结果的显示形式的一例的示意图。
图12是供说明对象概念的概念图。
具体实施方式
下面基于附图对本发明的实施方式进行说明。
[数据分析系统的结构]
图1是表示数据分析系统的硬件结构的一例的框图。如图1所例示,数据分析系统例如具备:能够执行数据分析的主要处理的业务服务器14、能够执行该数据分析的相关处理的一个或多个客户端装置10、具备将成为数据分析的对象的对象数据以及对该对象数据的评价/分类的结果存储的数据库22的存储系统18、对客户端装置10以及业务服务器14提供用于数据分析的管理功能的管理计算机12。
此外,在本实施方式中,“数据”可以是以能够由数据分析系统处理的形式来表现的任意的数据。此时,上述数据例如可以在至少一部分上为结构定义不完整的非结构化数据,且广泛地包括以下内容,即至少在一部分中包括由自然语言所记述的文章的文件数据(例如,电子邮件(包括附件/抬头信息)、技术文件(例如,广泛地包括学术论文、专利公报、产品规格书、设计图等,说明技术类事项的文件)、演示资料、表计算资料、结算报告书、会议资料、报告书、营业资料、合同书、组织图、事业计划书等)、语音数据(例如,对会话/音乐等进行录音后的数据)、图像数据(例如,由多个像素或向量信息构成的数据)、映像数据(例如,由多个帧图像构成的数据)等。此时,数据的“结构要素”可以是构成上述数据的至少一部分的部分数据,例如可以是构成文件的词素、关键词、语句和/或段落,或者是构成语音的部分语音、音量(增量)信息和/或音色信息,或者是构成图像的部分图像、部分像素和/或亮度信息,或者是构成映像的帧图像、运动信息和/或三次元信息。
客户端装置10向具有对数据进行评价/分类的权限的用户(评价权限用户)提供参照数据。上述评价权限用户可以经由客户端装置10输入用于对该参照数据进行评价/分类。此外,在本实施方式中,上述“参照数据”例如可以是由用户关联了分类信息的数据(已分类数据)。另一方面,“对象数据”可以是未关联该分类信息的数据(作为参照数据没有向用户进行提示,且对用户而言没有进行分类的未分类的数据)。此处,上述“分类信息”可以是用于对参照数据进行分类的识别标签。分类信息例如可以是如下信息,即,以表示参照数据作为整体与预定案例相关的“相关”标签、表示二者尤其相关的“高”标签以及表示二者不相关的“非相关”标签的方式将该参照数据分类为三种的信息;或者以“好”、“略好”、“一般”、“略差”以及“差”的方式将该参照数据分类为五个等多个类型的信息。
另外,上述“预定案例”广泛地包括数据分析系统对与数据的相关性进行评价的对象,且其范围不限。例如,预定案例在数据分析系统被实现为搜索支援系统的情况下,可以是要求搜索手续的本案诉讼;在被实现为犯罪搜查支援(取证)系统的情况下,可以是成为搜查对象的犯罪;在被实现为电子邮件监视系统的情况下,可以是不法行为(例如,信息泄露、投标串通等);在被实现为医疗应用系统(例如,药物警戒支援系统、治疗效验高效化系统、医疗风险规避系统、跌倒预测(跌倒防止)系统、治疗后预测系统、诊断支援系统等)的情况下,可以是医药相关的事例/案例;在被时间为互联网应用系统(例如,智能邮件系统、信息聚合(管理)系统、用户监视系统、社交媒体运营系统等)的情况下,可以是互联网相关的事例/案例;在被实现为项目评价系统的情况下,可以是在过去进行的项目;在被实现为市场营销支援系统的情况下,可以是成为市场营销对象的商品/服务;在被实现为知识产权评价系统的情况下,可以是成为评价对象的知识产权;在被实现为不法交易监视系统的情况下,可以是不法的金融交易;在被实现为呼叫中心升级系统的情况下,可以是过去的对应事例;在被实现为信用调查系统的情况下,可以是信用调查的对象;在被实现为驾驶支援系统的情况下,可以是关于车辆的驾驶的事项;以及在被实现为营业支援系统的情况下,可以是营业业绩。
客户端装置10具备公知的计算机硬件资源,例如可以具备存储器(例如,硬盘、闪速存储器等)、控制器(cpu:centralprocessingunit,中央处理机)、总线、输入输出接口(例如,键盘、显示器等)、通信接口。客户端装置10利用lan等通信机构20,经由上述通信接口与业务服务器14和管理计算机12可通信地连接。另外,在上述存储器中存储有使客户端装置10发挥作用的应用程序等,上述控制器通过执行该应用程序,能够针对评价权限用户进行分类和评价的处理所需要的输入和输出。
业务服务器14基于针对参照数据的分类的结果,从该参照数据中学习模式(泛指数据中包括的抽象的规则、意思、概念、样式、分布、样例等,不限于所谓的“特定的模式”),并基于该模式评价对象数据。即,业务服务器14向用户提示参照数据,容许该用户对该参照数据的分类信息的输入,基于用户的输入结果来学习模式,并基于学习结果能够针对对象数据进行评价,由此可以从多个对象数据中分辨用户所希望的数据。业务服务器14与客户端装置10相同地,作为硬件资源,例如可以具备存储器、控制器、总线、输入输出接口、通信接口。另外,上述存储器中存储有使业务服务器14发挥作用的应用程序,上述控制器基于该应用程序执行用于数据分析的处理。
管理计算机12对客户端装置10、存储系统18以及业务服务器14执行预定的管理处理。管理计算机12与客户端装置10相同地,作为硬件资源,例如可以具备存储器、控制器、总线、输入输出接口、通信接口。另外,管理计算机12的存储器中例如存储有用于上述控制器执行管理处理的应用程序。
存储系统18例如可以由磁盘阵列系统构成,且可以具备对对象数据和针对该对象数据的评价/分类的结果进行存储的数据库22。业务服务器14和存储系统18通过das(directattachedstorage,直接附加存储)方式或san(storageareanetwork,存储区域网络)连接(16)。
此外,图1所示的硬件结构归根结底只不过是例示,数据分析系统也可以通过其他硬件结构实现。例如,可以是使在业务服务器14中执行的处理的一部分或全部在客户端装置10中执行的结构,也可以是存储系统18内置于业务服务器14中的结构。本领域技术人员理解为能够实现数据分析系统的硬件结构可以多样化地存在,但不限于其中的某一个(例如,如图1所例示的结构)。
[数据分析系统的功能]
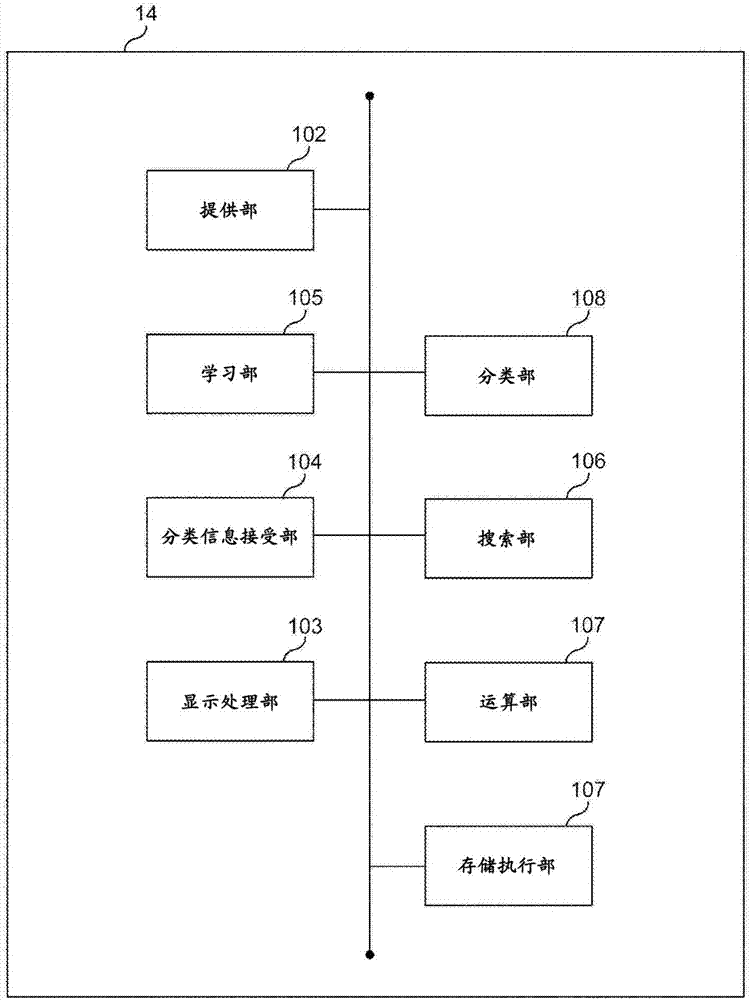
图2是表示业务服务器14的功能结构的一例的功能框图。如图2所例示,业务服务器14例如可以具备:参照数据提供部102,其从保存于数据库22的对象数据中按照预定的基准(例如,随机)对一部分对象数据进行多次采样,并将其提供为参照数据;显示处理部103,其将用于针对参照数据的分类、针对参照数据以外的数据的序列化或分类的信息等输出至客户端装置10的显示机构;分类信息接受部104,其针对参照数据,接受来自持有评价者权限的用户的分类信息的设定(带标签);以及学习部105,其基于分类信息,按分类信息对多个参照数据进行分类,并学习每个分类信息的参照数据中包括的模式。
业务服务器14例如还可以具备:存储执行部201,其使数据库22存储数据的结构要素和该结构要素的评价值;搜索部106,其进行对数据库22的检索处理,并从参照数据以外的对象数据中搜索模式;运算部107,其按对象数据计算表示对象数据与预定案例的相关性的高低的指标,并基于该指标将多个对象数据序列化;以及分类部108,其基于将对象数据序列化后的结果,对该对象数据赋予分类信息。
此外,在上面的描述中,由于标记为****部的结构是通过业务服务器14所具备的控制器执行程序(数据分析程序)而实现的功能结构,因而也可以将****部说成****处理或****功能。另外,由于还可以由硬件资源代替****部,因此本领域技术人员可以理解为这些功能块可以仅由硬件、仅由软件、或由它们的组合来以多种形式实现,但不限于其中某一个。
[数据解析系统的动作]
图3是表示数据分析系统的动作例的流程图。具有管理者权限的管理用户向管理计算机12给出提取(采样)参照数据(提取请求300)的请求。提取请求300例如可以是从存储于数据库22的数据中随机采样预定数量的数据来作为参照数据的请求,或者是从预定范围的数据(例如,数据的更新日期和时间在3日以内)中采样预定数量的数据来作为参照数据的请求。此外,被提取为参照数据的数据的比例或数量可以由管理用户适当设定。
管理计算机12基于提取请求300生成提取命令302,并将该提取命令302发送至业务服务器14。业务服务器14所具备的参照数据提供部102基于来自管理计算机12的提取命令302,从数据库22中提取预定数量的参照数据(304)。
业务服务器14的参照数据提供部102将提取到的参照数据发送至特定的客户端装置10(在提取命令302中确定的客户端装置)(312)。该特定的客户端装置10启动评价分类输入界面,并将评价分类输入画面提示给评价权限用户。图4是该评价分类输入画面的一例。评价分类输入画面例如可以包括参照数据的列表500和表示每个对象数据的分类信息的勾选框502。
若评价权限用户从可浏览多个参照数据的列表中选择一个参照数据,则如图5所示,例如,显示该选择的对象数据的详细说明506。参照数据的详细说明506例如可以由数据的id510、数据的名称512、对象数据的内容(文件数据的文本等)506构成。
评价权限用户在参照参照数据的详细说明506并掌握参照数据的内容后,可以通过勾选表示每个参照数据的标签的勾选框,来对该参照数据进行分类。例如,在评价权限用户认为数据与预定的案例相关的情况下,勾选表示“相关”的勾选框;在认为尤其相关的情况下,勾选表示“高”的勾选框;在认为没关系的情况下,勾选表示“非相关”的勾选框。若勾选勾选框,则其信息被发送至业务服务器(314),业务服务器14将分类信息与参照数据的组合存储至数据库22。
业务服务器14所具备的学习部105参照存储于数据库22的上述组合,并按分类信息从参照数据的集合中提取结构要素(316)。学习部105例如可以将在带有相同分类信息的多个参照数据中提取在预定频率以上出现的词素(关键词)来作为结构要素。
另外,学习部105可以基于预定的评价基准(例如,传递信息量)来评价提取到的结构要素(318)。例如,在学习部105从文件数据(文本数据)中提取关键词来作为结构要素的情况下,基于上述预定的评价基准,通过计算该关键词的评价值来评价该关键词。此处,上述“评价值”例如可以是表示该关键词对参照数据与分类信息的组合有所贡献的程度(结构要素出现于各数据中的分布/频率的、相对应于分类信息的偏向)的特征量。由此,学习部105可以基于用户对参照数据的输入,从该参照数据中取得模式来作为学习的结果。
业务服务器14所具备的存储执行部201使数据库22对学习部105所提取到的结构要素、该结构要素的评价值和阈值进行存储。接下来,业务服务器14对结构要素和对象数据进行比较,对对象数据与预定的案例的相关性的高低进行评价,并将对象数据序列化。具体地,搜索部106从数据库22依次获取多个对象数据,并依次读入该对象数据中包括的多个结构要素,并搜索该对象数据中是否出现各结构要素(320)。在该结构要素出现于对象数据中的情况下,运算部107基于该结构要素的评价值来计算对象数据的指标,由此基于该指标的大小将多个对象数据序列化(322)。此处,序列化是指,例如可以是使对象数据与针对该对象数据计算出的指标相关联。
在该处理中,运算部107生成对有无对象数据中包括的结构要素进行表现的向量(所谓的“bag-of-words,词包”)。例如,在对象数据中包括“价格”这样的关键词的情况下,运算部107在对应于“价格”的该向量的次元设定“1”。运算部107通过计算该向量与各结构要素的评价值(评价值)的内积(下面公式),来计算上述指标。
[数学式1]
s=wt·s,
此处,s表示上述向量,w表示评价值向量,t表示转置。
此外,运算部107如上所述,既可以对每个对象数据计算一个指标,也可以对每个以预定隔断(例如,语句、段落、以预定的长度分割的部分语音、包括预定数量的帧的部分视频等)来划分对象数据的单位计算出一个指标(关于详细说明,将予以后述)。另外,运算部107例如可以将对象数据中事先登记于数据库22中的关键词、相关用语或不包括在学习部105中选定的结构要素的对象数据事先从指标计算的对象中排除。
分类部108基于表示对象数据与预定的案例的相关性的指标(能够基于该相关性使多个对象数据序列化的指标),对对象数据设定分类信息。例如,分类部108在对象数据的指标为预定的阈值以上的情况下,可以对该对象数据设定分类信息。
分类部108例如可以将序列化后的多个对象数据分别提示给用户,容许该用户对该多个对象数据分别设定分类信息的输入,或用户确认自动分类后的分类信息,并能够对其进行变更。这是因为,指标越是上位,对象数据与预定案例相关的期待度就越高,且对对象数据设定“相关”或“高”的标签(分类信息)的可能性也就越高,例如,在对象数据的内容中存在对其妨碍的信息(例如,特定的词语)的情况下,也存在不应该对对象数据设定“相关”的标签的情况。
业务服务器14将对象数据的管理表登记于数据库22。图6是存储对象数据的管理表的一例。针对各个对象数据(数据1,2,3····),例如存储对象数据id、对象数据的名称、指标、分类信息等。业务服务器14中的针对对象数据的评价是指,关于多个对象数据与预定案例的相关性的高低的预定的运算处理,例如为计算对象数据的指标、或基于指标对多个对象数据分别设定标签、或能够基于指标的大小来识别多个对象数据等。
业务服务器14将数据库22中存储的管理表发送至客户端装置10。客户端装置10按指标由大到小的顺序对对象数据排序并进行显示。客户端装置10例如可以提示是自动进行还是手动进行来对对象数据赋予分类信息的输入栏。若用户选择手动赋予,则评价权限用户可以对各对象数据输入“相关”、“高”或“非相关”的标签。管理者例如还可以对序列化后的全部对象数据的上位预定数量、或者预定百分比的对象数据设定用于分类的标签。
[学习的执行模式]
管理者可以对学习部105预先设定学习的执行模式。该执行模式有多个方式,例如,(1)第一方式,即在对由参照数据提供部102提取的全部参照数据输入分类信息后,业务服务器14学习参照数据的模式,并基于该模式对所有对象数据计算指标;(2)第二方式,即业务服务器14在对多个参照数据分别输入分类信息时进行学习,并在进行该学习时计算对象数据的指标(即,一边基于各个参照数据的分类依次更新上述模式,一边计算对象数据的指标);(3)第三方式,即客户端装置10将由参照数据提供部102提取的参照数据以外的数据与分类信息的组合供应至学习部105,业务服务器14一边依次更新上述模式,一边计算对象数据的指标(例如,在评价权限用户对对象数据设定分类信息的情况下,将该对象数据和分类信息的组合反馈至学习部105并更新上述模式)等。在上述第二方式中,由于每当进行向各个参照数据的分类信息的赋予时,对象数据的序列都将有所变更,因此具有分类权限的用户可以确认对象数据的序列的变动趋势。在上述第三方式中,由于对对象数据进行分类后的结果被依次反映于学习部105中获取的模式,因此还将实现可以依次提高评价数据的精度的额外效果。
[结构要素的重新评价]
如上所述,学习部105基于预定的基准(例如,传递信息量),将构成参照数据的至少一部分的多个结构要素对参照数据组(包括多个参照数据和对该参照数据进行分类的分类信息的组合的数据组)中的该组合贡献的程度作为上述评价值来进行评价。
此时,学习部105可以选定结构要素,直至设定为“相关”或“高”的标签的数据的指标变得大于未设定为这些标签的数据的指标为止,并且重复评价该结构要素的评价值,并修正该结构要素的评价值。由此,数据分析系统可以发现出现在附有“相关”或“高”的分类信息的多个数据中、对数据和标签的组合有影响的结构要素。此外,例如使用预定的词语的出现概率和预定的分类信息的出现概率,并根据预定的定义式计算传递信息量。具体地,学习部105例如利用以下数学式来计算结构要素的评价值wgt。
[数学式2]
此处,wgt表示学习前的第i个选定关键词的评价值的初始值。另外,wgt表示第l次学习后的第i个选定关键词的评价值。γ是指第l次学习中的学习参数的意思,θ是指学习效果的阈值的意思。由此,学习部105例如可以评价为计算出的传递信息量的值越大,则结构要素越是表示预定的分类信息的特征。
另外,学习部105可以将设定了“相关”的参照数据的指标的最低值、与设定了“非相关”的参照数据的指标的最高值的中间值作为对对象数据自动判定有无“相关”设定时的阈值(预定的基准值)。
学习部105例如也可以继续评价值的重新评价,直至再现率成为预定的目标值。此处,再现率是表示相对于预定数量的数据应发现的数据所占的比例(包罗性)的指标,例如,在相对于全部数据的30%,再现率为80%的情况下,表示应发现数据(例如,诉讼相关资料)的80%被包含于指标上位30%的数据中。在不使用数据分析系统,而是人对数据进行循览(linearreview,线性评论)的情况下,由于应发现的数据的量与人评论的量成比例,因此距该比例的乖离越大,则系统的数据分析性能越好。运算部107可以具有:再现率计算功能,其基于数据的指标来计算数据与预定案例的相关性的判断所涉及的再现率;以及重新选定功能,其从参照数据中重新选定结构要素。
学习部105在序列化后的对象数据的再现率低于目标值的情况下,从参照数据中重新选定结构要素,直至再现率高于目标值,运算部107基于重新选定的结构要素,对再次执行对象数据的序列化的情况进行重复。在重新选定结构要素的情况下,可以选定除了上次选定的结构要素的结构要素,也可以将上次选定的结构要素的一部分置换成新的结构要素。另外,在运算部107以重新选定的结构要素来计算对象数据的指标的情况下,也可以变更一个或多个结构要素的评价值。另外,运算部107也可以使用重新选定的结构要素和其评价值来计算各数据的指标(第二指标),并由在结构要素的重新选定之前获得的第一指标和第二指标,重新计算再现率。
接着,对重新计算再现率的处理的具体例进行说明。首先,参照数据提供部102从数据库22的对象数据中随机采样用于向评论者(评价权限用户)提示的参照数据。接下来,显示处理部103使客户端装置10的画面显示部输出提取到的参照数据。评论者评论画面显示部中显示的参照数据,并对参照数据赋予分类信息。学习部105解析参照数据,并选定结构要素。具体地,学习部105提取n个在被赋予了共同的分类信息的参照数据中共同出现的结构要素,并对提取到的结构要素分别计算评价值。例如,将第一个提取到的结构要素的评价值设为wgt1,将第二个提取到的结构要素的评价值设为wgt2,将第n个提取到的结构要素的评价值设为wgtn。学习部105利用该wgt1至wgtn的评价值来选定词素。将结构要素按评价值的降序重新排列,并从评价值的上位起依次选择m个词素(结构要素),直至满足下面的公式,且其总和达到目标值(设为k,k是任意的定数)为止。
[数学式3]
k:固有的目标值
wgti:第i个词素的评价值
接下来,运算部107从对象数据中提取包括已选定的m个结构要素的数据,并基于该对象数据中包含的结构要素的评价值来计算各对象数据的指标。运算部107按指标的降序将数据序列化,并决定全部数据的指标上位a%(a是任意的定数)的数据。运算部107在a%中包含的数据中,确定具有预定的基准值以上的指标且被设定为与参照数据相同的“相关”或“高”的标签(分类信息)的数据,并根据a%中包含的数据数量与被设定了标签的数据数量的比,来计算再现率x1(xn:在第n次计算出的再现率)。
接下来,运算部107判定再现率x1是否被计算为目标值k以上。在判定为被计算为目标值k以上的情况下,结束处理。在并非如此的情况下,学习部105重新选定结构要素。具体地,先在已选定的n个结构要素中,从除了所述m个结构要素的结构要素中,由评价值的上位起依次选择i个结构要素,直至满足下面的数学式,且其总和达到目标值为止。
[数学式4]
k:固有的目标值
wi:第i个词素:结构要素
xn:第n个再现率
运算部107提取包括重新选定的结构要素的数据,计算各数据的第二指标s1r,并利用第一次计算出的指标s1与第二指标s1r的残差δ1(δ1=s1r-s1),根据下面的数学式来计算各文件的合成指标s2。
[数学式5]
si:第i个指标
sir:第i个第二指标
δi:第i个指标和第i个第二指标的合成指标
利用合成指标s2,运算部107再次计算再现率,并重复对再现率进行重新计算,直至高于目标值k为止。由此,可以将数据序列化中的精度提高至目标再现率。
此外,上面的描述中,作为“再现率”进行说明的地方也可以是适合率。此处,“适合率”(precisionrate)是相对于由数据分析系统发现的数据,真正应发现的数据所占的比例(准确性)的指标。例如,在表现为“在对全部数据处理30%的时刻,适合率为80%”的情况下,表示相对于指标上位30%的数据,应发现的数据所占的比例为80%。另外,数据分析系统例如可以基于针对对象数据计算出的再现率与指标的排名(例如,该排名除以数据数量的规格化排名)的关系,来计算用户确认该对象数据时所需要的数据数量。
[考虑了结构要素之间的相关度的指标计算]
运算部107也可以考虑对象数据中包含的第一结构要素的评价值(第一结构要素的评价值)与该对象数据中包含的第二结构要素的评价值(第二结构要素的评价值)的相关度(共现),来决定对象数据的指标。例如,在第一结构要素与第二结构要素的联系紧密的情况下,运算部107在第一结构要素出现在对象数据中的情况下,考虑第二结构要素出现于该对象数据中的频率,从而能够计算指标。作为这种相关关系,例如,在将串通/同业联盟等不法检证假设为预定案例的情况下,由于经验上知道投标、价格、调整这样的各关键词容易出现在相同的通信存储数据中,因此只要使各关键词各自的评价值相加后的值,与基于这些数据组合的预定值相加等,来增加对象数据的指标即可。由此,由于数据分析系统还可以考虑多个结构要素间的相关关系来计算指标,因此可以以更高的精度提取与预定案例相关的对象数据。
运算部107可以通过在结构要素的出现信息中反映该结构要素与其他结构要素的相关度(共起等),来计算对象数据的指标。运算部107例如使结构要素的出现管理向量乘以表示与其他结构要素的相关度的相关矩阵。相关矩阵例如是正方行列,其通过相关矩阵的信息来表示在“价格”这样的关键词出现于对象数据中的情况下,相对于“价格”其他关键词(例如“调整”)的出现容易程度(即,相关)。
相关矩阵可以基于参照数据最优化。例如,在对象数据中出现“价格”这样的关键词的情况下,将其他关键词(“调整”)的出现数量在0~1之间进行正规化后的值(即,最大似然估计值)存储至相关矩阵中。因此,数据分析系统可以获得用于使多个结构要素的相关度反映至数据的指标的相关向量。
如下面的数学式所示,运算部107基于对所有相关向量合计后的值来计算数据的指标。更具体而言,运算部107可以如下面的数学式所示,通过对相关向量的合计值与针对关键词的评价值的向量w的内积进行计算,来计算对象数据的指标,从而替代上述数学式。
[数学式6]
指标:
此处,c表示相关矩阵,ss表示第s个关键词向量。另外,tfnorm(合计的值)如下面的数学式所示来进行计算。
[数学式7]
此处,tfi表示第i个关键词的出现频率(termfrequency),sjs表示第s个关键词向量的第j个要素。
总结上述公式,运算部107通过计算下面的数学式,按对象数据计算指标。
[数学式8]
指标:
此处,wi是评价值向量w的第i个要素。
[针对部分分割的各部分数据的指标计算]
运算部107不只是通过计算对象数据整体的指标来将数据序列化,例如,通过将对象数据分割为多个部分(例如,数据中包含的语句或段落(部分对象数据)),并基于学习到的模式来评价各部分数据(即,计算部分对象数据的指标),从而将该部分对象数据序列化。并且,运算部107还可以整合多个部分对象数据的指标(例如,从多个部分对象数据的指标中提取最大值来作为整体数据的指标,或将多个部分对象数据的指标的平均作为整体数据的指标,或将多个部分对象数据的指标按由大到小的顺序选择预定数量并进行合计从而作为整体数据的指标等),并将该整合后的指标作为对象数据的评价结果。由此,数据分析系统可以从对象数据中精确地选择适合有效利用目的的有用数据。
[阶段分析]
数据分析系统可以分析表示预定案例所进展的各步骤的阶段。例如,在预定的案例为串通行为的情况下,由于该串通行为通常以建立关系阶段(建立与其他竞争公司的关系的步骤),准备阶段(交换关于与其他竞争公司的竞争的信息的步骤)、竞争阶段(向顾客提示价格,得到反馈,并与其他竞争公司取得沟通的步骤)的顺序推进(在经验上/理论上已知),因此在上述阶段中可以设定上述三个阶段。数据分析系统针对预先设定好的多个阶段,从分别准备的多个种类的参照数据中分别学习对应于该多个阶段的多个模式,并分别基于该多个阶段来分析对象数据,由此例如可以确定“作为分析对象的组织当前在哪个阶段”。
对数据分析系统确定阶段的流程进行详细说明。首先,数据分析系统参照针对预先设定好的多个阶段而分别准备的多个种类的参照数据,来评价该多个种类的参照数据中分别包含的结构要素,并使该结构要素与评价该结构要素的结果(例如,评价值)相关联,按阶段存储至数据库22(即,分别学习对应于该多个阶段的多个模式)。因此,例如,在“建立关系阶段”(阶段1)中,“日程”、“调整”等的关键词评价值大于“执行阶段”(阶段3),或者在“准备阶段”(阶段2)中,“竞争产品”、“调查”等的关键词评价值大于“建立关系阶段”(阶段1)。另外,有时也按阶段界定不同的关键词。
接下来,数据分析系统通过基于上述按阶段学习到的模式来分析对象数据,由此对多个阶段分别计算指标。并且,数据分析系统针对各阶段判定该指标是否满足预先设定好的预定的判定基准(例如,阈值)(例如,该指标是否超过该阈值),在判定为满足的情况下,增加对应于该阶段的计数值。最后,数据分析系统基于该计数值来确定当前阶段(例如,将具有最大计数值的阶段作为当前阶段)。或者,在判断为按阶段计算出的指标满足对该阶段设定的预定的判定基准的情况下,数据分析系统也可以将该阶段确定为当前阶段。
数据分析系统可以以数据适应的方式对预先设定的预定的判定基准(例如,阈值)进行重新设定。此时,运算部107可以利用将多个对象数据序列化后的结果。运算部107例如针对对象数据的指标与该指标的排名(即,将指标以升序排列的情况中的排名)的关系进行回归分析,并基于该回归分析的结果来决定阈值。
运算部107例如可以使用属于指数型分布族的函数(y=eαx+β(e是自然对数的底,α和β是实数))来进行上述回归分析。运算部107基于对多个对象数据计算出的指标和该指标的排名(例如,通过最小二乘法)来决定上述α和β的值。此外,申请人对利用该上述函数的模型进行使用了决定系数、f检定以及t检定的检证,并确认该模型的可行性和最优性。
图7是表示基于指标和排名进行回归分析而由此获得的指数函数模型的特性例的图表。图8是表示对指数函数模型进行重新评价而获得的上述指数函数模型的特性例的图表。在图7和图8中,横轴表示指标,纵轴用对数刻度表示排名。因此,利用指数函数的拟合曲线(回归曲线)在图7和图8中表示为直线,纵轴越靠下排名越高,越靠上排名越低。
管理者针对排名预先设定好阈值。例如,在图7中,管理者对运算部107设定作为该阈值的1.e-03(=0.001=0.1%)。运算部107可以通过确定对应于该阈值的、用指数函数表示的指标,并将该指标设定为某个阶段中的阈值(预定的判定基准),由此变更对该阶段预先设定好的阈值。这样,数据分析系统通过回归分析来重新评价序列化后的对象数据,由此动态地变更针对按阶段计算出的指标的阈值(预定的判定基准),以使得与基于通过学习获得的模式而评价对象数据后的结果相适合。另外,数据分析系统还可以通过持续监控对象数据的数据影像,来持续监视阶段的进行。
进一步地,数据分析系统在评价对象数据的结果已被评价权限用户检证的情况下,可以基于该检证结果调整学习部105所执行的学习处理。例如,在评价权限用户通过数据分析系统对应给予较高指标的对象数据进行检证,其结果是在判断为不应对该对象数据给予高的指标的情况下,该评价权限用户对该对象数据赋予“非相关”的标签。学习部105将该对象数据反馈为参照数据,例如使该参照数据中所包含的结构要素的评价值增减,或进行结构要素的追加/删除,从而执行重新学习,并更新模式。
并且,学习部105基于已更新的模式重新计算对象数据的指标和排名,并对该计算结果再次进行回归分析(图8)。学习部105基于新的回归分析的结果,来执行与图7中的说明相同的处理,由此设定按阶段修正的阈值。
[利用时序信息的分析]
(1)基于预测模型的阶段进展预测
数据分析系统可以基于能够预测与预定案例相关的预定行为的进展的模型,并根据由评价多个对象数据而决定的指标来预测/提示下一个行为。数据分析系统例如可以假定将针对第一阶段(例如,建立关系阶段)计算出的指标、以及针对第二阶段(例如,准备阶段)计算出的指标设为变量的回归模型,并基于预先最优化的回归系数,预测推进至第三阶段(例如,竞争阶段)的可能性(例如,概率)。
(2)按预定时间的学习
在对随着时间的经过其性质发生变化的数据(例如,对随着时间经过而进行的病状进行记录的电子病历等)进行分析时,数据分析系统可以从按预定时间划分的参照数据(例如,第一区间的对象数据、第二区间的对象数据···)中分别学习模式(即,按该预定时间获取结构要素和评价该结构要素的结果),并分别基于该模式,分析对象数据。
[基于数据结构的分析]
运算部107可以分析对象数据的结构,并将该分析的结果反映至对象数据的评价中。例如,对象数据在至少一部分中包含文件数据的情况下,运算部107可以解析文件数据的语句的表现形式(例如,该语句是肯定形,还是否定形,还是消极形等)并将解析结果反映至对象数据的指标中。此处,肯定形例如是指语句的谓语为“好吃”,否定形是“难吃”或“不好吃”,消极形是“谈不上好吃”或“谈不上难吃”等。
运算部107例如可以对肯定形设定“+α”,对否定形设定“-β”,对消极形设定“+θ”(α、β、θ可以是相同或不同的数值),并利用这些参数来调整针对对象数据分别计算出的指标。或者,运算部107在检测到对象数据中包含的语句为否定型的情况下,例如可以通过取消该语句,从而不以该语句中包含的结构要素作为指标计算的基础(不考虑该结构要素)。由此,由于数据分析系统可以将数据的结构解析结果反映至指标中,因此可以以更高的精度评价数据。
运算部107可以对作为对象数据的结构的语句的句子结构进行解析,并将该解析结果反映至对象数据的指标中。运算部107例如也可以根据词素(结构要素)位于语句的主语、宾语、谓语中的哪个位置来对该词素的评价值设置优劣。词素的句子结构中的位置只要通过向量来控制即可,根据是主语、宾语还是谓语来对词素的评价值标记优劣。运算部107可以在根据词素的出现向量和评价值来计算对象数据的指标时,结合词素的句子结构中的位置的控制向量求出对象数据的指标。
[感情分析]
数据分析系统可以从对象数据中提取用户的感情。通常,在线商品网站或餐厅导向等中,连同用户的评论大多记载有该用户对商品/服务的评价。因此,数据分析系统基于评论和评价生成参照数据,并基于该参照数据来评价对象数据,由此可以推测用户对商品/服务是否抱有好印象。在概念上,由于在针对该评价较高的商品/服务的评论中,大多使用正面的感情的词语(例如,“好”、“开心”等),而在针对该评价较低的商品/服务的评论中,大多使用负面的感情的词语(例如,“差”、“烂”等),因此数据分析系统可以从由评论和评价的组合而成的参照数据中学习模式,并基于该模式,从仅由评论构成的对象数据中提取生成该评论的用户的感情,来作为感情指标。
首先,分类部108基于感情的优劣对参照数据进行分类。例如,分类部108在消费者的评价分五个步骤进行的情况下,根据步骤评价对参照数据设定分类信息(例如,可以是表示“好印象”或“坏印象”的两个分类的标签,或表示“好”、“较好”、“一般”、“较差”、“差”的五个分类的标签)。接下来,学习部105从设定分类信息的参照数据中提取结构要素。尤其,学习部105可以提取表示感情表现的结构要素(例如,对应于形容词、形容动词、副词等的词素)。
并且,学习部105以如下所述的形式生成针对表示感情表现的结构要素的感情标记(表示感情评价信息、用户抱有好印象还是抱有坏印象的指标)。即,学习部105在被分类为好印象的一个以上的参照数据中对表示感情表现的结构要素(结构要素a)出现的次数af进行计数。并且,学习部105计算在该参照数据中出现结构要素a的频率rfp。
[数学式9]
此处,np是被分类为好印象的参照数据中包含的全部结构要素数量。
接下来,学习部105对被分类为坏印象的参照数据中出现结构要素a的次数an进行计数,并计算参照数据中出现结构要素a的频率rfn。
[数学式10]
此处,nn是被分类为坏印象的参照数据中包含的全部结构要素数量。
并且,学习部105对使用上述两个数学式计算出的频率进行利用,以如下方式计算结构要素a的感情标记(感情判定指标值p(a))。
[数学式11]
进一步地,学习部105在感情判定指标值p(a)大于1的情况下,将结构要素a作为多用于抱有好印象的数据的结构要素,并将“+1”指定为其感情标记,并存储至数据库22,在感情判定指标值p(a)小于1的情况下,将结构要素a作为多用于抱有坏印象的数据的结构要素,并将“-1”指定为其感情标记,并存储至数据库22。例如,将形成以下倾向:对“好”、“美”、“好吃”这样的词容易标注“+1”,而对“差”,“脏”、“难吃”这样的词设定“-1”。
运算部107从对象数据中提取设定有感情标记的结构要素,并获取所提取到的结构要素各自的感情标记值。运算部107与结构要素出现于对象数据中的次数相应地加感情标记值。例如,对“好”这样的结构要素设定的感情标记为“+1”,且在未分类数据中出现五次的情况下,将基于未分类数据的结构要素“好”的感情指标设为“5”。另外,例如,在对“差”这样的结构要素设定的感情标记为“-1”,且在未分类数据中出现三次的情况下,将基于未分类数据的“差”这样的结构要素的感情指标设为“-3”。
运算部107一边判定否定表现或夸张表现是否存在于结构要素中,一边计算感情指标。否定表现是指,否定结构要素的表现,例如是“不好”、“不好吃”这样的表现。在有这种表现的情况下,将它们对待为相反的表现,例如,若是“不好”,则作为“差”来对待,若是“不好吃”,则作为来“难吃”对待。此外,这里虽然对待为相反的表现,但是例如这在针对“好”的表现设定“+1”的感情标记的情况下,也可以将其设为负的值。或者,也可以使设定为感情标记的值仅减少预定量(例如,1.5)。另外,还将检测是否存在对否定进行否定、即双重否定表现,在存在双重否定表现的情况下,也可以以肯定的方式判定结构要素。
另外,夸张表现是指,使结构要素更夸张(强调)的表现,例如,“非常”、“极其”、“很”这样的表现。在结构要素涉及这种夸张表现的情况下,将其感情标记值乘以预定倍数(例如,2倍)来计算感情指标。例如,在存在“非常好吃”这样的表现的情况下,当“好吃”的感情标记值为“+1”时,将针对该表现的感情指标设为“+2”(加大)。此外,乘以预定倍数的结构要素仅限涉及夸张表现的结构要素。
这样,运算部107如下面数学式所示,计算基于所有结构要素的感情指标,并进行合计,从而计算对象数据的指标s。
[数学式12]
此处,si是第i个结构要素的感情标记。
运算部107基于感情指标将对象数据序列化。在指标大于0的情况下,判定为容易对对象数据抱有好印象,在指标为不到0的情况下,判定为容易对对象数据抱有坏印象。将序列化后的多个对象数据提示给用户。
[层级区分图的显示]
数据分析系统具备预定的管理功能。该管理功能通过管理计算机12的管理程序来执行。作为管理功能的一例,在有多个评价权限用户的情况下,具有通过管理画面显示每个人的分类的精度。
图9是表示数据分析系统的管理画面的一例的示意图。该管理画面由显示处理部103根据运算部107的数据的指标而生成。显示处理部103向管理计算机12的显示器输出显示画面260。显示画面260例如具有与指标的预先设定好的各个范围分别相关联的多个区划、以及显示比率的显示区域262。比率是指标的范围中所包含的对象数据的总数、与对象数据的总数中作为与预定案例相关并由评价权限用户设定了“相关”的标签的对象数据的数量之比。
区划例如以指标为0~999、1000~1999的形式,以1000为单位划分设定,各区划例如按指标为200进行细分。对各被细分化的小区划中的每一个,通过比率色调等附加信息的形式变化(层级)来进行表现。例如,色调越是冷色系,则表示比率越低,即,由评论者对对象数据设定“相关”的标签的比例越低(非相关的比例高),越是暖色系,则表示由评论者设定“相关”的标签的比例越高。例如,在显示区域262的纵向存在评价权限用户的识别栏266,且按评价权限用户来对相关性指标栏268予以区别。数据分析系统可以使用与已关联预定分类信息(标签)的数据相对于所有数据所占的比例相对应层级,以可视识别的方式显示相对于分别评价多个数据后的结果的该比例的分布。
管理权限用户通过参照显示画面260中显示的各小区划的颜色,易于掌握各评价权限用户的分类精度是否合适。例如,有些评价权限用户对尽管是指标小的区域也设定“相关”的标志的比例较高,另一方面,有些评价权限用户对尽管是指标高的区域也设定“非相关”的标志的比例较高,这表示由这些评价权限用户进行的分类精度较低。
[网络分析]
数据分析系统可以将多个节点(人、组织、计算机)间的相互关系(数据的发送/接收或交换等)可视化。在这种情况下,显示处理部103例如可以基于由运算部107进行的数据序列化的结果,将与预定案例相关的多个人物的关系性以看得出该相关性的程度的方式显示于客户端装置10。
如图10所示,显示处理部103在将各节点以圆形显示的同时,在一个节点与另一节点之间有关系性的情况下,用箭头将该节点与该另一节点之间结合并进行显示。各节点的大小表示节点间的关系性的大小。即,节点的大小越大,则表示与节点30的关系性越高。在图10的例子中,按节点31、节点36、节点35、节点32、节点33、节点34的顺序使节点变小。因此,在图10的例子中,表示按节点31、节点36、节点35、节点32、节点33、节点34的顺序,与节点30的关系性变高。基于关系性的大小、数据的指标的大小或标签的优劣来决定。也可以改变将节点之间结合的箭头或线段的粗度或颜色等,从而取代节点的大小,或者与其相结合。
节点也可以通过url或电子邮件地址来确定。图10是以节点30为中心的相关关系显示,但是显示处理部103也可以变更中心节点。另外,显示处理部也可以在一个画面中将多个节点设定为中心节点。另外,也可以通过看得出节点间的相关关系的方式对数据的时间戳、发送时刻、接收时刻、更新时刻等时间信息进行显示。节点之间的相关关系的发生与当前时刻越近,则只要改变节点之间的连结显示的形式(色调)即可。
另外,数据分析系统判定表示预定的动作的第一结构要素是否包含在数据中,在判定为包含的情况下,确定表示该预定动作的对象的第二结构要素。例如,在“确定规格”这样的文章包含于上述数据中的情况下,从该文章中提取“规格”和“确定”这样的结构要素(词语),并确定表示预定动作“确定”的第一结构要素(动词)的对象即第二构成要素(宾语)“规格”。接下来,上述数据分析系统使包含上述第一结构要素和第二结构要素的数据的属性(性质/特征)的元信息(属性信息)、与该第一结构要素和第二结构要素相关联。此处,上述元信息是表示数据所具有的预定属性的信息,例如,在上述数据为电子邮件的情况下,可以是发送该电子邮件的人物的名字、接收的人物的名字、邮件地址、发送接收的日期时间等。并且,数据分析系统将两个结构要素与元信息相关联,并显示于客户端装置10。
例如,在电子邮件(数据、通信信息)中包含“交流技术”这样的文章,并提取到“技术”(第二结构要素)和“交流”(第一结构要素)这样的词语时,数据分析系统将上述“技术”和“交流”、与发送接收上述电子邮件的人物的名字(例如,“人物a”和“人物b”)相关联并进行显示。由此,可以推测“人物a”和“人物b”正在计划就某一“技术”的“交流”。进一步地,例如,在添加在上述电子邮件中的演示资料中包含“确定规格”这样的文章,并提取到“规格”(第二结构要素)和“确定”(第一结构要素)这样的词语时,数据分析系统使上述“规格”和“确定”、与生成上述演示资料的日期时间(例如,2015年3月30日16时30分)相关联并进行显示。由此,可以推测“人物a”和“人物b”正在计划就某一“技术”的“交流”,并要在2015年3月30日16时30分这一时刻确定该“技术”的“规格”。
通过本发明的数据分析系统,尽管将多个对象数据序列化,但是对所有对象数据的内容过目仍需要时间,毕竟不是容易的事情。因此,数据分析系统可以实现用于使用户能够在短时间内掌握对象数据的内容的支援功能。
[概念的提取]
运算部107执行主题(语境)检测功能。运算部107如图11中的(a)所示,从对象数据中提取包含预先选定的概念的下位概念的结构要素的数据,并以适度的抽象度分别生成提取到的各对象数据(电子邮件等)的内容的摘要,为了能够确认对象数据的内容,基于生成的摘要来对对象数据创建聚类,并将对象数据的聚类的结果以例如图11中的(b)所示的形式提示给用户。
这种主题检测功能通过准备阶段和适用阶段这两个步骤的阶段来实现。准备阶段是用于仅提取由用户预先设定的各对象概念的下位概念的关键词,并生成将与分别对应于所提取到的关键词的对象概念相关联的上述对象概念提取用数据库的阶段。另外,适用阶段是利用在准备阶段生成的对象概念提取用数据库,生成以上位概念来表现相对应的对象数据的内容的摘要,并基于已生成的摘要对相对应的对象数据创建聚类,并根据用户的要求来显示结果的阶段。
在准备阶段中,首先,用户选定与欲从对象数据中检测出的话题(主题)相对应的几个对象概念,并将已选定的对象概念预先登记于数据分析系统。例如,在欲检测的主题为“不法”和“不满”的情况下,如图12所示,将概念的分类分为“行动”、“感情”、“性质或状态”、“风险”以及“金钱”这5个,例如针对“行动”将“报仇”和“轻蔑”等概念设定为对象概念,针对“感情”将“苦恼的”和“生气的”等概念设定为对象概念,针对“性质或状态”将“笨重”和“内心或态度恶劣”等概念设定为对象概念,针对“风险”将“威胁”和“欺骗”等概念设定为对象概念,针对“金钱”将“对人的劳动支付的钱”等概念设定为对象概念。
当这样设定对象概念时,运算部107按已登记的对象概念,在数据库22的词典上检索表示其下位概念的关键词,并生成上述对象概念提取用数据库,其与分别对应于通过该检索检测出的各个关键词的对象概念相关联。
另一方面,在适用阶段中,运算部107利用如上述那样生成的对象概念提取用数据库,从对象数据中提取在文本内包含登记在对象概念提取用数据库的关键词的对象数据。另外,运算部107针对这样提取的对象数据,生成使用当时检测出的关键词的上位概念来表示其文本的内容的摘要。
例如,在图11的情况下,如(a)所示,对于“e-mail_1”,从叫作“监视系统订单”的位置提取“系统”、“销售”以及“进行”这样的对象概念,对于“e-mail_2”,从叫作“会计系统引进”的位置提取“系统”、“销售”以及“进行”这样的上位概念,因此对于这些“e-mail_1”和“e-mail_2”都将生成“系统销售进行”的摘要。
并且,显示处理部103在之后有来自用户的要求的情况下,基于这样生成的相对应的对象数据的摘要,对对象数据创建聚类,并将其结果提示给用户。
例如,在图11的情况下,如上所述,对“e-mail_1”和“e-mail_2”生成“系统销售进行”这样的相同摘要,因此这些“e-mail_1”和e-mail_2”被分类至同一组。并且,该分类结果例如如(b)那样,通过以摘要作为“内容”的形式来进行显示。如此,用户可以掌握对象数据的内容。
[其他结构]
通过分类信息接受部104对多个分类信息分别设定参照数据与分类信息的组合。即,分类信息与参照数据的组合被设定为多个。另外,学习部105例如考虑对参照数据与分类信息的组合贡献的程度,来评价附有相同的分类信息的多个参照数据中共同出现的结构要素,并将评价结果(评价值)为预定以上的结构要素选定为多个参照数据中共同的模式之一。此外,由于存在对参照数据的评价/分类的方针/基准按评价者而有所不同的情况,因此数据分析系统也可以容许多个评价者参加针对参照数据的评价/分类。
数据分析系统可以基于用户的输入,来对序列化后的对象数据设定分类信息。或者,数据分析系统也可以根据针对对象数据的评价结果(例如,在对象数据的指标满足该预定的评价基准(例如,指标是否超过预定的阈值)的情况下),无需用户的输入,就对该对象数据给出分类信息。上述评价基准可以由具有管理权限的用户设定,也可以对参照数据或对象数据的测量结果进行回归分析,并基于结果由数据分析系统来进行设定。另外,数据分析系统例如可以按照预定的分类信息来分类,并从附有相同分类信息的多个对象数据中提取有用的结构要素,并基于该结构要素来解析是否能够将对象数据分类为与参照数据相同。例如可以按由多个分类信息分别分组而成的对象数据来进行结构要素的提取。
如上所述,由学习部105选定的、将词素设为开始的结构要素被存储至数据库22。另外,业务服务器14根据过去的分类处理的结果,只要与预定案例的优劣的相关性高且包含于对象数据中,则也可以将能够分类为“有关系”的结构要素事先登记在数据库22中。
另外,还可以根据过去的分类处理的结果,将与被赋予符号的对象数据的相关性较高的结构要素登记在数据库22,所述符号涉及与预定案例的相关性。曾暂时登记在数据库22的词素除了根据数据分析系统所进行的学习的结果来增减外,也可以通过手动进行追加登记和删除。
数据分析系统可以学习多个模式(数据的结构要素与评价该结构要素的结果的组合),并保持在数据库22。例如,数据分析系统可以按预定的案例的种类保持上述组合。由此,例如,在数据分析系统被实现为犯罪搜查支援系统,并分析能够成为犯罪证据的数据时、以及在数据分析系统被实现为互联网应用系统,并分析网页时,数据分析系统将保持互不相同的多个模式。此时,用户可以输入该预定案例的种类,且数据分析系统可以基于与该种类相对应的模式来处理对象数据。
数据分析系统在计算参照数据中包含的结构要素的评价值时,可以计算所有结构要素的临时的评价值,之后对计算评价值的对象的结构要素的临时的评价值中添加该结构要素以外的结构要素的临时的评价值,从而计算出最终的评价值。具体地,数据分析系统对多个结构要素分别计算评价值(即,对该多个结构要素分别进行评价),为了对该多个结构要素中的一个即第一结构要素计算出评价值,并针对该评价值反映对该多个结构要素中的另一个即第二结构要素计算出的评价值,更新对该第一结构要素计算出的评价值,并将该更新的评价值与该第一结构要素相关联,来作为该第一结构要素的评价值存储至数据库22。由此,由于数据分析系统可以在还考虑了与其他结构要素的相关性的基础上,来计算用于评价数据的结构要素的评价值,因此可以以更高的精度来分析数据。
数据分析系统基于预定的基准(例如,传递信息量)分别评价参照数据中包含的结构要素,并基于该评价的结果,对对象数据分别计算表示与预定案例的相关性的高低的正指标(主指标)。接下来,数据分析系统从上述正指标较低的对象数据(例如,该正指标几乎为零的数据)中选出预定数量的数据(例如,随机地)来作为部分数据,并基于上述预定的基准分别评价该选出的数据中包含的结构要素。并且,数据分析系统基于该评价的结果,针对该对象数据计算表示对象数据与上述预定案例的相关性的弱度的负指标(副指标)。最后,数据分析系统按照上述正指标和负指标,提取对象数据(例如,以从正指标高、负指标低的数据依次排列的方式将数据整体序列化)。
如上,数据分析系统不仅是导出表示与预定案例相关的指标(正指标),还按照该正指标导出表示与该预定案例不相关(与该预定案例的相关性低)的指标(负指标)。由此,数据分析系统可以以更高的精度分析数据。
[数据分析系统的应用程序例]
数据分析系统例如可以被实现为信息资产运用系统(项目评价系统)。即,该数据分析系统根据状况(动态地)提取企业/熟练者所具有的信息资产(数据),由此能够实现为可有效利用该信息资产的系统。由此,例如,(1)为了使期待使开发期间缩短化的开发现场高效化,可以使与过去开发的产品有关的信息根据该开发的必要条件被重新利用,(2)或者可以基于熟练技术人员所具有的专业知识,确定有用的信息资产。即,数据分析系统可以有效地发现用户所需要的信息(过去的信息资产)。
数据分析系统例如可以被实现为互联网应用系统(例如,智能邮件系统、信息聚合(管理)系统、用户监视系统、社交媒体运营系统等)。在这种情况下,该数据分析系统基于预定的评价基准(例如,该用户的嗜好与其他用户的嗜好是否相似、该用户的嗜好与餐厅的属性是否一致等)评价数据(例如,用户向sns投稿的消息、网站中刊登的推荐信息、用户或团体的档案等),由此例如可以阅览显示看起来与该用户合得来的其他用户,或提示符合该用户的嗜好的餐厅的信息、或警告可能会对该用户带来危害的团体。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为驾驶支援系统。在这种情况下,该数据分析系统基于预定的评价基准(例如,是否为在由熟练驾驶人员驾驶过程中该熟练驾驶人员所关注的信息等)来评价数据(例如,从车载传感器/摄像头/麦克风等获取的数据),由此例如可以自动提取能够使驾驶安全/舒适的有用信息。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为金融系统(例如,不法交易监视系统、股价预测系统等)。在这种情况下,该数据分析系统基于预定的评价基准(例如,是否有不法目的的可能性、股价是否上升等)来评价数据(例如,针对银行的申报资料、股价的时价等),由此例如可以揭发具有不法目的的申报,或预测将来的股价。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统可以被实现为医疗应用系统(例如,药物警戒支援系统、治疗效验效率化系统、医疗风险规避系统、跌倒预测(跌倒防止)系统、治疗后预测系统、诊断支援系统等)。在这种情况下,该数据分析系统基于预定的评价基准(例如,患者的是否采取特定的危险行动、某一药剂是否对疾病发挥效力等)来评价数据(例如,电子病历、看护记录、患者的日记等),由此例如可以对患者陷入危险的状态(例如,跌倒等)进行预测、或客观地评价药剂的效力。即,数据分析系统可以有效地发现对用户而言需要的信息。
另外,数据分析系统例如可以被实现为邮件控制系统(智能邮件系统)。在这种情况下,该数据分析系统基于预定的评价基准(例如,是否需要回复该电子邮件等)来评价数据(例如,电子邮件、附件等),由此例如可以从大量的邮件中提取重要的邮件(需要动作的邮件)。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为搜索支援系统。在这种情况下,该数据分析系统基于预定的评价基准(例如,在本案诉讼中的搜索手续中是否应该提交该数据等)来评价数据(例如,文件、电子邮件、表计算数据等),由此例如可以仅将与本案例诉讼相关的文件提交至法庭。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为取证支援系统。在这种情况下,该数据分析系统基于预定的评价基准(例如,该数据是否为能证明犯罪行为的证据等)来评价数据(例如,文件、电子邮件、表计算数据等),由此例如可以提取证明该犯罪行为的证据。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为邮件监视系统(邮件监察支援系统)。在这种情况下,该数据分析系统基于预定的评价基准(例如,发送接收该电子邮件的用户是否要进行不法行为的等)来评价数据(例如,电子邮件、附件等),由此例如可以发现信息泄露和串通等不法行为的预兆。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为知识产权评价系统。在这种情况下,该数据分析系统基于预定的评价基准(例如,该专利公报是否能成为使已授予的专利驳回/无效的证据等)来评价数据(例如,专利公报、发明的摘要、学术论文等),由此例如可以从多份文献(例如,专利公报、学术论文、互联网中刊登的文章)中提取无效资料。此时,数据分析系统例如可以获取成为无效对象的专利的各权利要求与“相关”标签(分类信息)的组合、以及与该专利不同的无关系的专利的各权利要求与“非相关”标签(分类信息)的组合,并将它们作为参照数据,从该参照数据中学习模式,并针对多份文献(对象数据)计算指标(例如,通过按专利公报的段落计算指标,并从该指标的上位对预定数量进行合计,来作为该专利公报的指标),由此可以评价该对象数据。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为呼叫中心升级系统。在这种情况下,该数据分析系统基于预定的评价基准(例如,是否与过去的对应事例类似等)来评价数据(例如,电话的通话记录、录音的语音等),由此例如可以从过去的对应事例中提取最适合当前状况的对应方法。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如被实现为市场营销支援系统。在这种情况下,该数据分析系统基于预定的评价基准(例如,该个人是男性还是女性、消费者是否对产品抱有好感等)来评价数据(例如,企业/个人的档案、产品信息等),由此例如可以提取对某一产品的市场的评价。即,数据分析系统可以有效地发现用户所需要的信息。
另外,数据分析系统例如可以被实现为信用调查系统。在这种情况下,该数据分析系统基于预定的评价基准(例如,该企业是否破产、该企业是否成长等)来评价数据(例如,企业的档案、关于企业业绩的信息、关于股价的信息、新闻发布等),由此例如可以预测企业的成长和破产。即,数据分析系统可以有效地发现用户所需要的信息。
这样,本发明的数据分析系统通过基于预定的评价基准(是否与预定案例相关)来评价搜索支援系统、犯罪搜查支援系统、电子邮件监视系统、医疗应用系统、互联网应用系统、信息资产运用系统、市场营销支援系统、知识产权评价系统、呼叫中心升级系统、信用调查系统、营业支援系统、驾驶支援系统等数据,从而可以作为有效地发现对用户而言需要的信息地任意的系统实现。特别是,本发明的数据分析系统将包括多个数据的数据组作为“基于人类思考及行动的结果的数据集合体”来掌握,例如通过进行与人类的行动相关的分析、预测人类的行动的分析、检测人类的特定的行动的分析、抑制人类的特定行动的分析等,从数据中提取模式,并评价该模式与预定案例的相关性,由此可以有效地发现用户所需要的信息。
此外,可以根据应用本发明的数据分析系统的领域,来考虑该领域所特有的情况,例如,对数据实施前处理(例如,从该数据中挑出重要位置,并仅将该重要位置作为数据分析的对象等),或对显示数据分析的结果的方式进行改变。本领域技术人员可以理解这样的变形例是可以多样化地存在的,且所有变形例均落入本发明的范畴。
[数据分析系统处理文件数据以外的数据的例子]
在上述实施方式中,以数据分析系统分析文件数据的例子为主进行了说明,但该数据分析系统还可以分析文件数据以外的数据(例如,语音数据、图像数据、映像数据等)。
例如,在分析语音数据的情况下,数据分析系统可以将该语音数据本身作为分析的对象,且也可以通过语音识别将该语音数据转换为文件数据,并将转换后的文件数据作为分析的对象。在前一种情况下,数据分析系统例如将语音数据分割为预定长度的部分语音并作为结构要素,并利用任意的语音分析手法(例如,隐马尔可夫模型、卡尔曼滤波器等)来识别该部分语音,由此能够分析该语音数据。在后一种情况下,使用任意的语音识别算法(例如,利用隐马尔可夫模型的识别方法等)来识别语音,并对识别后的数据,按照与在实施方式中说明的顺序相同的顺序进行分析。
另外,在分析图像数据的情况下,数据分析系统例如将图像数据分割为预定大小的部分图像并作为结构要素,利用任意的图像识别手法(例如,模式匹配、支持向量机、神经网络等)来识别该部分图像,由此能够分析该图像数据。
进一步地,在分析映像数据的情况下,数据分析系统例如将映像数据中包括的多帧图像分别分割为预定大小的部分图像并作为结构要素,利用任意的图像识别手法(例如,模式匹配、支持向量机、神经网络等)来识别该部分图像,由此能够解析该映像数据。
[通过软件/硬件的实现例]
数据分析系统的控制框可以由形成为集成电路(ic芯片)等的逻辑电路(硬件)来实现,也可以利用cpu(centralprocessingunit,中央处理机)并通过软件来实现。在后一种情况下,数据分析系统具备对实现各功能的软件即程序(数据分析系统的控制程序)进行执行的cpu、对该程序及各种数据以计算机(或或cpu)可读的方式进行存储的rom(readonlymemory,只读存储器)或存储装置(将这些称为“存储介质”),展开该程序的ram(randomaccessmemory,随机存取存储器)等。并且,计算机(或cpu)从上述存储介质中读取并执行上述程序,由此实现本发明的目的。作为上述存储介质,可以使用“非暂态有形介质”,例如,磁带、磁盘、卡、半导体存储器、可编程逻辑电路等。另外,上述程序也可以经由可传输该程序的任意的传输介质(通信网络或广播波等)供给至上述计算机。本发明也可以通过将上述程序以电子传输的方式具现化的、埋入载波中的数据信号的形式来实现。此外,上述程序可以通过任意的编程语言来实际安装,例如,可以利用python、actionscript、javascript(注册商标)等脚本语言、objective-c、java(注册商标)等面向对象编程语言、html5等标记语言等来实际安装。另外,存储上述程序的任意的存储介质(计算机可读存储介质)均落入本发明的范畴。
[总结]
本发明的第一方式所涉及的数据分析系统是评价对象数据的数据分析系统,所述系统具备:存储器、输入控制装置、以及控制器,所述控制器,评价多个对象数据,该评价对应于各对象数据与预定案例的相关性;能够通过所述评价,生成能够使所述多个对象数据序列化的指标;并且基于用户经由所述输入控制装置给出的输入来改变所述指标,所述存储器对所述控制器所评价的所述多个对象数据至少进行临时存储,所述输入控制装置,对所述用户容许用于所述控制器将所述多个对象数据序列化的输入,其中,该多个对象数据的序列根据基于所述输入而变化的所述指标而变化,所述输入基于该参照数据与所述预定案例的相关性来对与所述多个对象数据不同的参照数据进行分类,该分类是指根据所述参照数据的内容被分为多个分类信息,所述多个分类信息中的至少一个通过所述输入被赋予至所述参照数据;将所述参照数据提示给所述用户;并且通过所述用户的输入,向所述控制器提供对所述提示的参照数据赋予的所述至少一个分类信息与该参照数据的组合,所述控制器,通过评价所述参照数据中包括的多个结构要素分别对由所述输入控制装置提供的组合贡献的程度,由此根据通过所述输入赋予的分类信息,从该参照数据中提取以该参照数据为特征的模式;基于所述提取到的模式来评价所述对象数据与所述预定案例的相关性并决定所述指标;对所述对象数据设定所述决定的指标;根据所述指标将所述多个对象数据序列化;并且将所述序列化的多个对象数据通知给用户。
另外,本发明的第二方式所涉及的数据分析系统,根据上述第一方式,所述控制器对所述指标与预定的阈值进行比较,并基于该比较后的结果,对所述多个对象数据分别设定与所述预定案例相关联的分类信息。
另外,本发明的第三方式所涉及的数据分析系统,根据上述第一至第二方式,所述控制器,判定所述多个对象数据是否满足预定的判定基准;从判定为满足所述预定的判定基准的多个对象数据中选出预定数量的对象数据;基于所述模式分别对所述预定数量的对象数据重新评价;并且基于所述重新评价后的结果,变更所述预定的判定基准。
另外,本发明的第四方式所涉及的数据分析系统,根据上述第一至第三方式,所述控制器,进一步获取新的参照数据与对该新的参照数据赋予的所述分类信息的组合;通过评价所述新的参照数据的至少一部分结构要素对该新的参照数据与分类信息的组合贡献的程度,来更新所述模式;并且基于所述更新的模式来评价所述对象数据与所述预定的案例的相关性,并决定所述指标。
另外,本发明的第五方式所涉及的数据分析系统,根据上述第一至第四方式,所述控制器,基于评价所述多个对象数据后的结果来计算再现率;并且从所述参照数据中重复提取所述模式,以使所述再现率上升。
另外,本发明的第六方式所设涉及的数据分析系统在上述第一至第五方式中,所述控制器在由所述输入控制装置提供所述组合时,通过评价对应于所述分类信息的所述参照数据中的至少一部分结构要素对该组合贡献的程度,来依次更新所述模式。
另外,本发明的第七方式所涉及的数据分析系统,根据上述第一至第六方式,所述控制器,通过参照数据库来提取与所述对象数据中的至少一部分结构要素相对应的概念,该数据库是将该结构要素与该概念对应起来的数据库;并且基于所述提取到的概念输出所述多个对象数据的摘要。
另外,本发明的第八方式所涉及的数据分析系统,根据上述第一至第七方式,所述控制器按所述多个对象数据中共同包含的主题,对该多个对象数据创建聚类。
另外,本发明的第九方式所涉及的数据分析系统在上述第一至第八方式中,所述对象数据至少包含针对所述预定案例的用户评价信息,所述控制器从该对象数据中提取生成所述对象数据的用户的感情即基于所述评价信息生成的针对所述预定案例的感情。
另外,在本发明的第十方式所涉及的数据分析系统,根据上述第一至第九方式,所述控制器使用与所述分类信息所关联的对象数据的、与相对于所有对象数据的比例相对应的层级,以可视确认的方式显示针对分别评价所述多个对象数据的结果的所述比例的分布。
另外,在本发明的第十一方式所涉及的数据分析系统,根据上述第一至第十方式,所述多个对象数据是在多个计算机之间发送接收的信息,所述控制器基于对所述发送接收的信息进行分析后的结果,使所述多个计算机之间的紧密度可视化。
另外,在本发明的第十二方式所涉及数据分析系统,根据上述第一至第十一方式,所述模式能够根据时间的经过而变化,所述控制器,按预定时间获取所述参照数据;从按所述预定时间获取的多个参照数据中分别提取所述模式;并且基于所述模式,按所述预定时间分别评价所述多个对象数据来决定所述指标。
另外,本发明的第十三方式所涉及的数据分析系统,根据上述第一至十二方式,所述控制器,通过分割所述对象数据,生成多个构成该对象数据的至少一部分的部分对象数据;基于所述提取到的模式来分别评价所述多个部分对象数据;对评价所述多个部分对象数据而得到的所述指标进行整合;并且使用所述整合后的指标分别评价所述多个对象数据。
另外,本发明的第十四方式所涉及的数据分析系统,根据上述第一至第十三方式,所述控制器,基于所述结构要素与对包括该结构要素的参照数据进行分类的所述分类信息的关系的强度,计算针对该结构要素的评价值作为评价所述程度的结果;并且基于对所述对象数据的至少一部分结构要素计算出的评价值,决定所述指标,以表示该对象数据与所述预定案例的相关性的高低,由此评价所述多个对象数据。
另外,本发明的第十五方式所涉及的数据分析系统,根据上述第一至第十四方式,所述控制器,基于所述结构要素以及与该结构要素不同的其他结构要素出现在同一参照数据的至少一部分中的频率,评价该结构要素与该其他结构要素的相关度;并且还基于所述相关度来分别评价所述多个对象数据。
另外,本发明的第十六方式所涉及的数据分析系统,根据上述第一至第十五方式,所述控制器基于能够预测与所述预定案例有关的预定行为的进展的模型,从通过评价所述多个对象数据来决定的指标中提示下一个行为。
另外,本发明的第十七方式所涉及的数据分析系统,根据上述第一至十六方式,所述控制器,在每一个表示预定行为所进展的各步骤的指标即阶段,来评价所述多个对象数据;并且从通过评价所述多个对象数据而对每一个所述阶段所决定的指标中,确定当前阶段。
另外,本发明的第十八方式所涉及的数据分析系统,根据上述第一至十七方式,所述对象数据为在至少一部分中包括一句以上的语句的文件数据,所述控制器解析所述语句所具有的结构,并基于该解析的结果对所述对象数据决定所述指标。
另外,本发明的第十九方式所涉及的数据分析系统,根据上述第十八方式,所述控制器基于对所述语句所具有的结构进行解析的结果,判定该语句的表现形式,并基于该判定的结果评价所述对象数据。
另外,本发明的第一方式所涉及的数据分析方法是一种评价对象数据的数据分析方法,包括:第一步骤,基于评价基准分别评价多个对象数据,所述评价基准对应于各对象数据与预定的案例的相关性;第二步骤,能够通过所述评价,生成能够使所述多个对象数据序列化的指标,并根据用户给出的输入改变该指标;第三步骤,对在所述第一步骤中评价的所述多个对象数据至少进行临时存储;第四步骤,对所述用户容许用于将所述多个对象数据序列化的输入,其中,该多个对象数据的序列根据基于所述输入而变化的所述指标而变化,所述输入基于该参照数据与所述预定案例的相关性来对与所述多个对象数据不同的参照数据进行分类,该分类是指根据所述参照数据的内容被分为多个分类信息,所述多个分类信息中的至少一个通过所述输入被赋予至所述参照数据;第五步骤,将所述参照数据提示给所述用户;第六步骤,通过所述用户的输入,提供对所述提示的参照数据给出的所述至少一个分类信息与该参照数据的组合;第七步骤,通过评价该参照数据中包含的多个结构要素分别对所述提供的组合贡献的程度,由此根据通过所述输入而赋予的分类信息,从该参照数据中提取以该参照数据赋予为特征的模式;第八步骤,将该提取到的模式作为所述评价基准,基于该模式评价所述对象数据与所述预定案例的相关性,并决定所述指标;第九步骤,将该决定的指标设定为该对象数据;第十步骤,执行与所述指标相对应的所述多个对象数据的序列化;以及第十一步骤,将所述序列化后的多个对象数据通知给用户。
另外,本发明的第一方式所涉及的数据分析程序使计算机执行上述第一方式所涉及的数据分析方法的各步骤。
另外,本发明的第一方式所涉及的存储介质存储上述第一方式所涉及的数据分析程序。
另外,本发明的其他方式所涉及的数据分析系统具备:存储器;以及一个以上的控制器,其能够执行该存储器中存储的一个以上的程序,该数据分析系统分别评价该存储器中存储的数据组中所包含的多个数据,其中,所述控制器将包含参照数据与对该参照数据进行分类的分类信息的多个组合的数据组作为参照数据组来获取,分别评价构成所述参照数据组的至少一部分的多个结构要素对所述获取的参照数据组中包含的多个组合贡献的程度,由此学习该参照数据中包含的模式,基于所述学习到的模式将多个对象数据序列化,由此分别评价该多个对象数据,并基于分别评价所述多个对象数据后的结果,将该多个对象数据经由预定的显示界面提示给用户。
工业实用性
本发明可以广泛适用于个人电脑、服务器、工作站、主机等任意的计算机。
附图标记说明
10客户端装置
12管理计算机
14业务服务器
18存储系统
22数据库
- 还没有人留言评论。精彩留言会获得点赞!