连接短文本中实体提及与语义知识库中实体的方法和设备与流程
本发明一般地涉及信息处理领域。具体而言,本发明涉及一种能够将短文本中的实体提及与语义知识库中的实体连接的方法和设备。
背景技术:
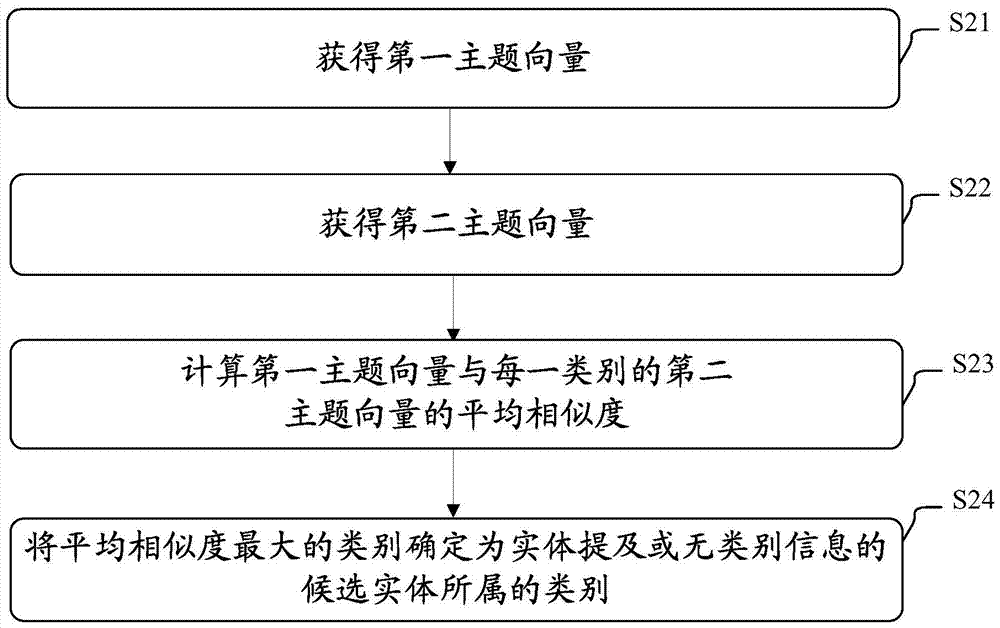
:近年来,随着互联网语义知识库如dbpedia和短文本信息平台如微博、短信等的飞速发展,如何将短文本中的“实体提及(mention)”与互联网语义知识库中的实体(entity)相关联,从而将短文本内容语义化是语言信息处理领域亟待解决的问题之一。将短文本内容语义化使得用户和计算机可以有效地检索和利用短文本的语义信息,同时也为实现短文本数据的语义分析提供必要的基础。另外,还可以对互联网知识库进行实时扩充,提高互联网知识库的动态更新能力。因此,本发明旨在准确地将短文本中的实体提及与语义知识库中的实体连接。技术实现要素:在下文中给出了关于本发明的简要概述,以便提供关于本发明的某些方面的基本理解。应当理解,这个概述并不是关于本发明的穷举性概述。它并不是意图确定本发明的关键或重要部分,也不是意图限定本发明的范围。其目的仅仅是以简化的形式给出某些概念,以此作为稍后论述的更详细描述的前序。本发明的目的是提出一种能够将短文本中的实体提及与语义知识库中 的实体连接的方法和设备。为了实现上述目的,根据本发明的一个方面,提供了一种将短文本中的实体提及与语义知识库中的实体连接的方法,该方法包括:从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体;确定候选实体和实体提及所属的类别;确定实体提及所属的类别的最具区分性的属性集合;基于该属性集合,计算属于该类别的候选实体与实体提及的相似度;以及基于所述相似度,选择候选实体与实体提及连接。根据本发明的另一个方面,提供了一种将短文本中的实体提及与语义知识库中的实体连接的设备,该设备包括:候选实体选择装置,被配置为:从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体;类别确定装置,被配置为:确定候选实体和实体提及所属的类别;属性集合确定装置,被配置为:确定实体提及所属的类别的最具区分性的属性集合;相似度计算装置,被配置为:基于该属性集合,计算属于该类别的候选实体与实体提及的相似度;以及连接装置,被配置为:基于所述相似度,选择候选实体与实体提及连接。另外,根据本发明的另一方面,还提供了一种存储介质。所述存储介质包括机器可读的程序代码,当在信息处理设备上执行所述程序代码时,所述程序代码使得所述信息处理设备执行根据本发明的上述方法。此外,根据本发明的再一方面,还提供了一种程序产品。所述程序产品包括机器可执行的指令,当在信息处理设备上执行所述指令时,所述指令使得所述信息处理设备执行根据本发明的上述方法。附图说明参照下面结合附图对本发明的实施例的说明,会更加容易地理解本发明的以上和其它目的、特点和优点。附图中的部件只是为了示出本发明的原理。在附图中,相同的或类似的技术特征或部件将采用相同或类似的附图标记来表示。附图中:图1示出了根据本发明的实施例的将短文本中的实体提及与语义知识库中的实体连接的方法的流程图;图2示出了确定候选实体和实体提及所属的类别的第一方法的流程图;图3示出了确定候选实体和实体提及所属的类别的第二方法的流程图;图4示出了根据本发明的实施例的将短文本中的实体提及与语义知识库中的实体连接的设备的结构方框图;以及图5示出了可用于实施根据本发明的实施例的方法和设备的计算机的示意性框图。具体实施方式在下文中将结合附图对本发明的示范性实施例进行详细描述。为了清楚和简明起见,在说明书中并未描述实际实施方式的所有特征。然而,应该了解,在开发任何这种实际实施方式的过程中必须做出很多特定于实施方式的决定,以便实现开发人员的具体目标,例如,符合与系统及业务相关的那些限制条件,并且这些限制条件可能会随着实施方式的不同而有所改变。此外,还应该了解,虽然开发工作有可能是非常复杂和费时的,但对得益于本公开内容的本领域技术人员来说,这种开发工作仅仅是例行的任务。在此,还需要说明的一点是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的装置结构和/或处理步骤,而省略了与本发明关系不大的其他细节。另外,还需要指出的是,在本发明的一个附图或一种实施方式中描述的元素和特征可以与一个或更多个其它附图或实施方式中示出的元素和特征相结合。下面将参照图1描述根据本发明的实施例的将短文本中的实体提及与语义知识库中的实体连接的方法的流程。图1示出了根据本发明的实施例的将短文本中的实体提及与语义知识库中的实体连接的方法的流程图。如图1所示,根据本发明的实施例的将短文 本中的实体提及与语义知识库中的实体连接的方法包括如下步骤:从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体(步骤s1);确定候选实体和实体提及所属的类别(步骤s2);确定实体提及所属的类别的最具区分性的属性集合(步骤s3);基于该属性集合,计算属于该类别的候选实体与实体提及的相似度(步骤s4);以及基于所述相似度,选择候选实体与实体提及连接(步骤s5)。在步骤s1中,选择与短文本中的实体提及相关的候选实体。也就是说,先初步选择一些潜在的连接对象,作为候选,然后在后续的步骤中,加以筛选。具体的实现方式有多种。例如,可以将语义知识库中的实体名与实体提及相同的同名实体,选择为候选实体。该知识库包括但不限于与该方法所应用的场景对应的特定知识库,例如互联网语义知识库wikipedia(维基百科)、dbpedia、baidubaike(百度百科)等。例如当实体提及为“apple”时,从互联网语义知识库中可能搜索到“苹果”、“美国苹果公司”等多个候选实体。也可以将语义知识库中的与同名实体存在等价关系的实体,选择为候选实体,其中,等价关系包括重定向关系和别称关系。例如,对于实体提及“ibm”,在知识库中搜索得到的内容中,包括重定向链接“国际商业机器股份有限公司”,该内容可以作为实体提及“ibm”的候选实体。或者,将语义知识库中的、实体提及作为锚文本链接到的实体,选择为候选实体。对于实体提及“华盛顿”,点击网页的锚文本“华盛顿”,链接到百科中的“美国首都华盛顿”、链接到“美国人华盛顿”,则“美国首都华盛顿”、“美国人华盛顿”可以作为实体提及“华盛顿”的候选实体。又或者,将语义知识库中的与实体提及存在百科中的消歧关系的实体,选择为候选实体。例如,对于实体提及“苹果”,在知识库中搜索得到消歧义页面,其中,“苹果公司”、“苹果日报”、“苹果(电影)”等都可以作为实体提及“苹果”的候选实体。再如,将语义知识库中的实体名与实体提及在实体描述文本中具有指代 关系的实体,选择为候选实体。还可以将语义知识库中的实体名与实体提及在实体提及所在的文本中具有指代关系的实体,选择为候选实体。其中,是否具有指代关系根据语义知识库中的实体的实体名与实体提及在该实体的实体描述文本或实体提及所在的文本中是否符合特定指代模式确定。是否具有指代关系也可以依赖于对语义知识库中的该实体的实体描述文本或该实体提及所在的文本进行文本分析来确定。文本分析包括指代消解。例如,短文本“ibm(国际商业机器股份有限公司)”、“agriculturalbankofchina(abc)”中括号前和括号中的内容、“计算机又称为电脑”中“又称为”前后的内容、“北京时间3月12日,2013亚冠联赛小组赛第二轮,广州恒大足球俱乐部客场挑战全北现代,广州恒大首发已经公布”中的“广州恒大”和“广州恒大足球俱乐部”符合特定指代模式,并且可以通过文本分析如指代消解确定具有指代关系。在步骤s2中,确定候选实体和实体提及所属的类别。以下给出两种示例性的实施方式,但本发明不限于此。类别可以是已有知识库中实体的分类体系,例如,类别可以分为组织机构、人物、地名、建筑物等。至少部分实体在知识库中存在类型信息,因此使用该信息确定实体提及或无类型信息的候选实体的类别,例如方式一。另外,可以根据已有类型信息的实体构建训练数据,训练分类器,并利用该分类器对无类型信息的候选实体或实体提及进行分类。例如方式二。方式一:利用主题向量确定实体提及或无类型信息的候选实体所属的类别。图2示出了确定候选实体和实体提及所属的类别的第一方法的流程图。具体地,在步骤s21中,获得实体提及所在的文本或无类型信息的候选实体的实体描述文本(例如,主题subject、注释说明comment、摘要abstract)对应的第一主题向量。可以通过将实体提及所在的文本或无类型信息的候选实体的实体描述文本输入主题模型来获得该向量。在步骤s22中,获得每一类别的实体的实体描述文本对应的第二主题向量。可以通过将每一类别的实体的实体描述文本输入主题模型来获得该向量。在步骤s23中,计算第一主题向量与每一类别的第二主题向量的平均相似度。也就是说,分别计算第一主题向量与每一类别的一个或更多个实体对应的一个或更多个第二主题向量之间的相似度,向量的相似度例如基于余弦夹角计算,然后计算每一类别下的相似度的平均值。在步骤s24中,将平均相似度最大的类别确定为实体提及或无类型信息的候选实体所属的类别。即,比较每一类别的平均相似度的大小,选取其中的最大平均相似度,将与最大平均相似度对应的类别确定为实体提及或无类型信息的候选实体所属的类别。方式二:利用分类器确定候选实体和实体提及所属的类别。图3示出了确定候选实体和实体提及所属的类别的第二方法的流程图。具体地,在步骤s31中,基于如下特征中的至少一个,训练分类器:每一类别的实体的实体描述文本与预定义模板的匹配情况、所述实体描述文本是否包含每一类别相关的关键词、每一类别的实体在百科中对应的主题信息、每一类别的实体关联的属性类型。预定义模板特征:每一类别的实体的实体描述文本与预定义模板的匹配情况是指预定义模板能够匹配每一类别的实体的实体描述文本,则该特征为1,否则为0。预定义模板的示例如下,左侧列出了多个示例类别,右侧列出了与类别分别对应的预定义模板示例。关键词特征:每一类别的实体的实体描述文本是否包含每一类别相关的关键词是指从每一类别的实体的实体描述文本中抽取一些关键词,作为每一类别相关的关键词。判断每一类别的实体的实体描述文本中是否包括这些关键词,如果包含这些关键词中的至少一个,则该特征为1,否则为0。每一类别相关的关键词的示例如下,左侧列出了多个示例类别,右侧列出了与类别分别对应的关键词示例。百科主题特征:每一类别的实体在百科中对应的主题信息例如是实体青龙山在例如百度百科中的主题信息。判断每一类别的实体的实体描述文本中是否包括这些主题信息,如果包含这些主题信息中的至少一个,则该特征为1,否则为0。每一类别相关的主题信息的示例如下,左侧列出了多个示例类别,右侧列出了与类别分别对应的主题信息示例。关联属性类型特征:每一类别的实体关联的属性类型是指每一类别的实体在知识库中具有常见或固有的若干类型的属性。例如,类别为“人”的实体通常包括“出生日期”、“出生地点”、“国籍”等属性。类别为“公司”的实体通常包括“注册地址”、“成立时间”、“经营范围”等属性。判断每一类别的实体是否包括这些属性,如果包含这些属性中的至少一个,则该特征为 1,否则为0。在步骤s32中,利用分类器,对候选实体和实体提及进行分类。进行分类时,预定义模板特征、关键词特征、百科主题特征都是基于候选实体的实体描述文本、实体提及所在的文本,关联属性类型特征基于候选实体和实体提及本身。在步骤s3中,确定实体提及所属的类别的最具区分性的属性集合。将属性区分度大于区分阈值的属性,确定为该类别的最具区分性的属性集合中的属性。下面给出了属性的属性区分度的两种示例性计算方式。方式一:针对语义知识库中每个类别下的每个属性,统计语义知识库中该属性在该类别下出现的第一频率;统计语义知识库中该类别下该属性的每个属性值在该属性下出现次数相关的第二频率;计算第一频率与第二频率之积,作为该类别下的该属性的属性区分度。举例来说,对某一类候选实体集合e,e中的每个候选实体ei具有m(ei)个属性、m(ei)个属性值vj,为了简单起见,这里假设一个属性对应一个属性值,其中i和j是序号。统计e中属性的第一频率pf,以及属性值的第二频率ief。pf为属性p在集合e所有属性中出现的频率,ief计算方法如下,该属性的每个属性值在该属性下出现的次数的倒数进行求和,然后再除以该属性出现的总数。在表1的例子中,p1对应的pf=3,p1对应的属性值有v1,v4,v7,那么p1对应的ief=(1/1+1/1+1/1)/3=1.0。p2对应的pf=3,p2对应的属性值有v2和v5,其中v2出现一次,v5出现2次,那么p2对应的ief=(1/1+1/2)/3=0.5。p3对应的pf=3,p3对应的属性值只有v3,那么p3对应的ief=(1/3)/3=0.11。那么e所对应类别下的p1、p2、p3的属性区分度分别为3*1.0=3.0、3*0.5=1.5、3*0.11=0.33。可以设定区分阈值δ,大于δ的属性构成该类别的最具区分性的属性集合。并且,将该类别的最具区分性的属性集合中的属性的属性区分度归一化。实体属性属性值e1p1v1p2v2p3v3e2p1v4p2v5p3v3p4v6e3p1v7p2v5p3v3表1.候选实体属性及其属性值示例方式二:针对语义知识库中每个类别下的每个属性,计算关于实体与属性值的相关性矩阵;将相关性矩阵的每一列的最大值相加,所得到的和作为该类别下的该属性的属性区分度。例如,对于某一类别下的某一属性p,根据点互信息(pmi,pointwisemutualinformation)函数计算概率p(ei|vj)得到相关性矩阵m,其中ei为实体,vj为属性值。例如,对属性p1、p2、p3分别得到矩阵m1、m2、m3,如下所示。v1v2v3e10.10.20.5e20.20.70.4e30.80.30.1m1v1v2v3e10.10.10.9e20.00.80.0e30.90.10.1m2v1v2v3e10.30.40.3e20.40.30.3e30.30.30.4m3将相关性矩阵m的每一列的最大值相加,所得到的和作为该类别下的该属性p的属性区分度。例如,对于属性p1,属性区分度=0.8+0.7+0.5=2.0。对于属性p2,属性区分度=0.9+0.8+0.9=2.6。对于属性p3,属性区分度=0.4+0.4+0.4=1.2。可以设定区分阈值δ,大于δ的属性构成该类别的最具区分性的属性集合。并且,将该类别的最具区分性的属性集合中的属性的属性区分度归一化。以上两种方式可以分别获得两种属性区分度。既可以使用其中一种方式计算属性区分度,也可以将两种属性区分度合并,以获得最终的属性区分度。合并的方法例如是将两者加权求和,其中权重的总和等于一。在步骤s4中,基于该属性集合,计算属于该类别的候选实体与实体提及的相似度。具体地,从实体提及所在的文本中,利用关系抽取/分类技术,提取实体提及的、该属性集合的属性的属性值;然后,基于属于该类别的候选实体的、该属性集合的属性的属性值与实体提及的对应属性值之间的相似度,计算该候选实体与该实体提及的相似度。也就是说,对于属于同一类别的候选实体与实体提及,基于该类别的最具区分性的属性集合中的属性,比较其属性值的相似度,作为候选实体与实体提及的相似度。例如,候选实体entity与实体提及mention的相似度sim(mention,entity)=∑sim(vi(mention),vi(entity))其中,sim(vi(mention),vi(entity)是实体提及mention和候选实体entity的属性pi对应属性值vi的相似度。此外,在优选实施例中,还基于该候选实体与该实体提及的互指概率和该属性集合的各个属性的属性区分度中的至少一个,计算该候选实体与该实体提及的相似度。例如,候选实体entity与实体提及mention的相似度sim(mention,entity)=∑weight(pi)*sim(vi(mention),vi(entity))其中,weight(pi)是属性pi的属性区分度,sim(vi(mention),vi(entity) 是实体提及mention和候选实体entity的属性pi对应属性值vi的相似度。也就是说,计算候选实体与实体提及的相似度时,还可利用候选实体与实体提及的互指概率、该类别的最具区分性的属性集合中的属性的属性区分度这两方面的信息。其中,实体提及与候选实体的互指概率表明选择该候选实体的过程中所利用的信息的可靠性。也就是说,在之前的步骤s1中,从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体。由于采用多种方式获得候选实体,根据候选实体的来源,可以给出不同的互指概率,表明候选实体被选择时利用的信息的可靠程度。例如,候选实体e、实体提及m的互指概率为p(e|m)。如果候选实体e来源于语义知识库中的同名实体,则互指概率p(e|m)=1/r,r为同名实体的总数。如果候选实体e来源于等价关系(重定向关系、别称关系),则互指概率p(e|m)=1。如果候选实体e来源于特定模式的指代关系,则互指概率p(e|m)=1。如果候选实体e来源于消岐页面,则互指概率p(e|m)=1/k,k为歧义的实体总数。如果候选实体e来源于互联网的锚文本,则互指概率p(e|m)=w/n,w为实体提及与锚文本链接到的实体存在的链接数,n为实体提及与所有实体存在的链接数。在步骤s5中,基于所述相似度,选择候选实体与实体提及连接。具体地,选择相似度大于相似度阈值的候选实体,将其与实体提及连接。另外,在所述相似度均小于相似度阈值的情况下,将实体提及作为新的实体加入到语义知识库中。下面,将参照图4描述根据本发明的实施例的将短文本中的实体提及与语义知识库中的实体连接的设备。图4示出了根据本发明的实施例的将短文本中的实体提及与语义知识库中的实体连接的设备的结构方框图。如图4所示,根据本发明的连接设备400包括:候选实体选择装置41,被配置为:从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体;类别确定装置42,被配置为:确定候选实体和实体提及所属的类别;属性集合确定装置43,被配置为:确定实体提及所属的类别的最具区分性的属性集合;相似度计算装置44,被配置为:基于该属性集合,计算属于该类别的候选实体与实体提及的相似度;以及连接装置45,被配置为:基于所述相似度,选择候选实体与实体提及连接。在一个实施例中,候选实体选择装置41被进一步配置为执行以下操作之一:将语义知识库中的实体名与实体提及相同的同名实体,选择为候选实体;将语义知识库中的与同名实体存在等价关系的实体,选择为候选实体;将语义知识库中的实体名与实体提及在实体描述文本中具有指代关系的实体,选择为候选实体;将语义知识库中的与实体提及存在百科中的消歧关系的实体,选择为候选实体;将语义知识库中的、实体提及作为锚文本链接到的实体,选择为候选实体;将语义知识库中的实体名与实体提及在实体提及所在的文本中具有指代关系的实体,选择为候选实体。在一个实施例中,是否具有指代关系根据如下两者之一确定:语义知识库中的实体的实体名与实体提及在该实体的实体描述文本或实体提及所在的文本中是否符合特定指代模式;或者对语义知识库中的该实体的实体描述文本或该实体提及所在的文本进行文本分析。在一个实施例中,类别确定装置42被进一步配置为:获得与实体提及所在的文本或无类型信息的候选实体的实体描述文本对应的第一主题向量;获得每一类别的实体的实体描述文本对应的第二主题向量;计算第一主题向量与每一类别的第二主题向量的平均相似度;将平均相似度最大的类别确定为实体提及或无类型信息的候选实体所属的类别。在一个实施例中,类别确定装置42被进一步配置为:基于如下特征中的至少一个,训练分类器:每一类别的实体的实体描述文本与预定义模板的匹配情况、所述实体描述文本是否包含每一类别相关的关键词、每一类别的 实体在百科中对应的主题信息、每一类别的实体关联的属性类型;利用分类器,对候选实体和实体提及进行分类。在一个实施例中,相似度计算装置44被进一步配置为:从实体提及所在的文本中,提取实体提及的、该属性集合的属性的属性值;基于属于该类别的候选实体的、该属性集合的属性的属性值与实体提及的对应属性值之间的相似度,计算该候选实体与该实体提及的相似度。在一个实施例中,相似度计算装置44被进一步配置为:还基于该候选实体与该实体提及的互指概率和该属性集合的各个属性的属性区分度中的至少一个,计算该候选实体与该实体提及的相似度。在一个实施例中,属性集合确定装置43被进一步配置为:通过执行如下操作获得属性的属性区分度:针对语义知识库中每个类别下的每个属性,统计语义知识库中该属性在该类别下出现的第一频率;统计语义知识库中该类别下该属性的每个属性值在该属性下出现次数相关的第二频率;计算第一频率与第二频率之积,作为该类别下的该属性的属性区分度;并且将属性区分度大于区分阈值的属性,确定为该类别的最具区分性的属性集合中的属性。在一个实施例中,属性集合确定装置43被进一步配置为:通过执行如下操作获得属性的属性区分度:针对语义知识库中每个类别下的每个属性,计算关于实体与属性值的相关性矩阵;将相关性矩阵的每一列的最大值相加,所得到的和作为该类别下的该属性的属性区分度;并且将属性区分度大于区分阈值的属性,确定为该类别的最具区分性的属性集合中的属性。在一个实施例中,连接装置45被进一步配置为:选择相似度大于相似度阈值的候选实体,将其与实体提及连接;其中,在所述相似度均小于相似度阈值的情况下,连接装置45将实体提及作为新的实体加入到语义知识库中。由于在根据本发明的连接设备400中所包括的各个装置中的处理分别与上面描述的连接方法中所包括的各个步骤中的处理类似,因此为了简洁起 见,在此省略这些装置和单元的详细描述。此外,这里尚需指出的是,上述设备中各个组成装置、单元可以通过软件、固件、硬件或其组合的方式进行配置。配置可使用的具体手段或方式为本领域技术人员所熟知,在此不再赘述。在通过软件或固件实现的情况下,从存储介质或网络向具有专用硬件结构的计算机(例如图5所示的通用计算机500)安装构成该软件的程序,该计算机在安装有各种程序时,能够执行各种功能等。图5示出了可用于实施根据本发明的实施例的方法和设备的计算机的示意性框图。在图5中,中央处理单元(cpu)501根据只读存储器(rom)502中存储的程序或从存储部分508加载到随机存取存储器(ram)503的程序执行各种处理。在ram503中,还根据需要存储当cpu501执行各种处理等等时所需的数据。cpu501、rom502和ram503经由总线504彼此连接。输入/输出接口505也连接到总线504。下述部件连接到输入/输出接口505:输入部分506(包括键盘、鼠标等等)、输出部分507(包括显示器,比如阴极射线管(crt)、液晶显示器(lcd)等,和扬声器等)、存储部分508(包括硬盘等)、通信部分509(包括网络接口卡比如lan卡、调制解调器等)。通信部分509经由网络比如因特网执行通信处理。根据需要,驱动器510也可连接到输入/输出接口505。可拆卸介质511比如磁盘、光盘、磁光盘、半导体存储器等等可以根据需要被安装在驱动器510上,使得从中读出的计算机程序根据需要被安装到存储部分508中。在通过软件实现上述系列处理的情况下,从网络比如因特网或存储介质比如可拆卸介质511安装构成软件的程序。本领域的技术人员应当理解,这种存储介质不局限于图5所示的其中存储有程序、与设备相分离地分发以向用户提供程序的可拆卸介质511。可拆卸介质511的例子包含磁盘(包含软盘(注册商标))、光盘(包含光盘只读存储器(cd-rom)和数字通用盘(dvd))、磁光盘(包含迷你盘(md)(注册商标)) 和半导体存储器。或者,存储介质可以是rom502、存储部分508中包含的硬盘等等,其中存有程序,并且与包含它们的设备一起被分发给用户。本发明还提出一种存储有机器可读取的指令代码的程序产品。所述指令代码由机器读取并执行时,可执行上述根据本发明的实施例的方法。相应地,用于承载上述存储有机器可读取的指令代码的程序产品的存储介质也包括在本发明的公开中。所述存储介质包括但不限于软盘、光盘、磁光盘、存储卡、存储棒等等。在上面对本发明具体实施例的描述中,针对一种实施方式描述和/或示出的特征可以以相同或类似的方式在一个或更多个其它实施方式中使用,与其它实施方式中的特征相组合,或替代其它实施方式中的特征。应该强调,术语“包括/包含”在本文使用时指特征、要素、步骤或组件的存在,但并不排除一个或更多个其它特征、要素、步骤或组件的存在或附加。此外,本发明的方法不限于按照说明书中描述的时间顺序来执行,也可以按照其他的时间顺序地、并行地或独立地执行。因此,本说明书中描述的方法的执行顺序不对本发明的技术范围构成限制。尽管上面已经通过对本发明的具体实施例的描述对本发明进行了披露,但是,应该理解,上述的所有实施例和示例均是示例性的,而非限制性的。本领域的技术人员可在所附权利要求的精神和范围内设计对本发明的各种修改、改进或者等同物。这些修改、改进或者等同物也应当被认为包括在本发明的保护范围内。附记1.一种将短文本中的实体提及与语义知识库中的实体连接的方法,包括:从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体;确定候选实体和实体提及所属的类别;确定实体提及所属的类别的最具区分性的属性集合;基于该属性集合,计算属于该类别的候选实体与实体提及的相似度;以及基于所述相似度,选择候选实体与实体提及连接。2.如附记1所述的方法,从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体包括如下方式之一:将语义知识库中的实体名与实体提及相同的同名实体,选择为候选实体;将语义知识库中的与同名实体存在等价关系的实体,选择为候选实体;将语义知识库中的实体名与实体提及在实体描述文本中具有指代关系的实体,选择为候选实体;将语义知识库中的与实体提及存在百科中的消歧关系的实体,选择为候选实体;将语义知识库中的、实体提及作为锚文本链接到的实体,选择为候选实体;将语义知识库中的实体名与实体提及在实体提及所在的文本中具有指代关系的实体,选择为候选实体。3.如附记2所述的方法,其中是否具有指代关系根据如下两者之一确定:语义知识库中的实体的实体名与实体提及在该实体的实体描述文本或实体提及所在的文本中是否符合特定指代模式;或者对语义知识库中的该实体的实体描述文本或该实体提及所在的文本进行文本分析。4.如附记1所述的方法,其中确定实体提及所属的类别包括:获得与实体提及所在的文本或无类型信息的候选实体的实体描述文本对应的第一主题向量;获得每一类别的实体的实体描述文本对应的第二主题向量;计算第一主题向量与每一类别的第二主题向量的平均相似度;将平均相似度最大的类别确定为实体提及或无类型信息的候选实体所属的类别。5.如附记1所述的方法,其中确定候选实体和实体提及所属的类别包括:基于如下特征中的至少一个,训练分类器:每一类别的实体的实体描述文本与预定义模板的匹配情况、所述实体描述文本是否包含每一类别相关的关键词、每一类别的实体在百科中对应的主题信息、每一类别的实体关联的属性类型;利用分类器,对候选实体和实体提及进行分类。6.如附记1所述的方法,其中基于该属性集合,计算属于该类别的候选实体与实体提及的相似度包括:从实体提及所在的文本中,提取实体提及的、该属性集合的属性的属性值;基于属于该类别的候选实体的、该属性集合的属性的属性值与实体提及的对应属性值之间的相似度,计算该候选实体与该实体提及的相似度。7.如附记6所述的方法,其中基于该属性集合,计算属于该类别的候选实体与实体提及的相似度包括:还基于该候选实体与该实体提及的互指概率和该属性集合的各个属性的属性区分度中的至少一个,计算该候选实体与该实体提及的相似度。8.如附记1所述的方法,确定实体提及所属的类别的最具区分性的属性集合包括:将属性区分度大于区分阈值的属性,确定为该类别的最具区分性的属性集合中的属性;其中属性的属性区分度通过如下方式获得:针对语义知识库中每个类别下的每个属性,统计语义知识库中该属性在该类别下出现的第一频率;统计语义知识库中该类别下该属性的每个属性值在该属性下出现次数相关的第二频率;计算第一频率与第二频率之积,作为该类别下的该属性的属性区分度。9.如附记1所述的方法,其中确定实体提及所属的类别的最具区分性的属性集合包括:将属性区分度大于区分阈值的属性,确定为该类别的最具区分性的属性集合中的属性;属性的属性区分度通过如下方式获得:针对语义知识库中每个类别下的每个属性,计算关于实体与属性值的相关性矩阵;将相关性矩阵的每一列的最大值相加,所得到的和作为该类别下的该属性的属性区分度。10.如附记1所述的方法,其中基于所述相似度,选择候选实体与实体提及连接包括:选择相似度大于相似度阈值的候选实体,将其与实体提及连接;其中,在所述相似度均小于相似度阈值的情况下,将实体提及作为新的实体加入到语义知识库中。11.一种将短文本中的实体提及与语义知识库中的实体连接的设备,包括:候选实体选择装置,被配置为:从语义知识库中的实体中,选择与短文本中的实体提及相关的候选实体;类别确定装置,被配置为:确定候选实体和实体提及所属的类别;属性集合确定装置,被配置为:确定实体提及所属的类别的最具区分性的属性集合;相似度计算装置,被配置为:基于该属性集合,计算属于该类别的候选实体与实体提及的相似度;以及连接装置,被配置为:基于所述相似度,选择候选实体与实体提及连接。12.如附记11所述的设备,候选实体选择装置被进一步配置为执行以下操作之一:将语义知识库中的实体名与实体提及相同的同名实体,选择为候选实体;将语义知识库中的与同名实体存在等价关系的实体,选择为候选实体;将语义知识库中的实体名与实体提及在实体描述文本中具有指代关系的实体,选择为候选实体;将语义知识库中的与实体提及存在百科中的消歧关系的实体,选择为候选实体;将语义知识库中的、实体提及作为锚文本链接到的实体,选择为候选实体;将语义知识库中的实体名与实体提及在实体提及所在的文本中具有指代关系的实体,选择为候选实体。13.如附记12所述的设备,其中是否具有指代关系根据如下两者之一确定:语义知识库中的实体的实体名与实体提及在该实体的实体描述文本或实体提及所在的文本中是否符合特定指代模式;或者对语义知识库中的该实体的实体描述文本或该实体提及所在的文本进行文本分析。14.如附记11所述的设备,其中类别确定装置被进一步配置为:获得与实体提及所在的文本或无类型信息的候选实体的实体描述文本对应的第一主题向量;获得每一类别的实体的实体描述文本对应的第二主题向量;计算第一主题向量与每一类别的第二主题向量的平均相似度;将平均相似度最大的类别确定为实体提及或无类型信息的候选实体所属的类别。15.如附记11所述的设备,其中类别确定装置被进一步配置为:基于如下特征中的至少一个,训练分类器:每一类别的实体的实体描述文本与预定义模板的匹配情况、所述实体描述文本是否包含每一类别相关的关键词、每一类别的实体在百科中对应的主题信息、每一类别的实体关联的属性类型;利用分类器,对候选实体和实体提及进行分类。16.如附记11所述的设备,其中相似度计算装置被进一步配置为:从实体提及所在的文本中,提取实体提及的、该属性集合的属性的属性值;基于属于该类别的候选实体的、该属性集合的属性的属性值与实体提及的对应属性值之间的相似度,计算该候选实体与该实体提及的相似度。17.如附记16所述的设备,其中相似度计算装置被进一步配置为:还基于该候选实体与该实体提及的互指概率和该属性集合的各个属性的属性区分度中的至少一个,计算该候选实体与该实体提及的相似度。18.如附记11所述的设备,其中属性集合确定装置被进一步配置为:通过执行如下操作获得属性的属性区分度:针对语义知识库中每个类别下的每个属性,统计语义知识库中该属性在该类别下出现的第一频率;统计语义知识库中该类别下该属性的每个属性值在该属性下出现次数相关的第二频率;计算第一频率与第二频率之积,作为该类别下的该属性的属性区分度;并且将属性区分度大于区分阈值的属性,确定为该类别的最具区分性的属性集合中的属性。19.如附记11所述的设备,其中属性集合确定装置被进一步配置为:通过执行如下操作获得属性的属性区分度:针对语义知识库中每个类别下的每个属性,计算关于实体与属性值的相关性矩阵;将相关性矩阵的每一列的最大值相加,所得到的和作为该类别下的该属性的属性区分度;并且将属性区分度大于区分阈值的属性,确定为该类别的最具区分性的属性集合中的属性。20.如附记11所述的设备,其中连接装置被进一步配置为:选择相似度大于相似度阈值的候选实体,将其与实体提及连接;其中,在所述相似度均小于相似度阈值的情况下,连接装置将实体提及作为新的实体加入到语义知识库中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1