一种基于GPU计算的干涉数据快速傅里叶变换方法与流程
本发明属于傅里叶变换光谱仪数据处理领域,特别是一种基于GPU计算的干涉数据快速傅里叶变换方法。
背景技术:
干涉数据光谱复原基于傅里叶变换光谱学理论,傅里叶变换光谱学表明,干涉图与光谱图之间是傅里叶变换对关系,由此可通过对干涉数据进行傅里叶变换得到光谱图。目前研究和工程中为提高光谱复原效率,一般采用基于硬件实现的干涉数据处理技术,如中国科学院西安光学精密机械研究所殷世民、相里斌、周锦松等提出了一种基于FPGA的干涉式成像光谱仪实时数据处理系统研究[J](红外与毫米波学报,2007,26(4):274-278),该方法提高了光谱复原效率,但基于FPGA硬件编程实现,配置困难,不易复用。而通用GPU计算(General Purpose Graphics Processing Computing)通过利用GPU的成百上千的计算单元做分布式计算,不仅可以提高数据处理的速率,而且计算任务的实现基于软件算法,便于通用化处理。由于在光谱复原中,干涉图数据中各像素点间关系相对独立,具备像素间并行处理的特点,因此可以将干涉图数据分配给GPU众多的计算单元做分布式FFT计算,以提高干涉图数据进行快速傅里叶变换的效率。
技术实现要素:
本发明的目的在于提供一种基于GPU计算的干涉数据快速傅里叶变换方法,解决了传统基于硬件的实时光谱复原技术实现复杂,难以通用化的问题。
实现本发明目的的技术解决方案为:一种基于GPU计算的干涉数据快速傅里叶变换方法,步骤如下:
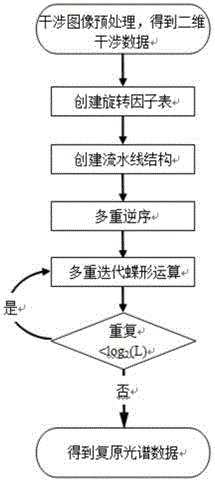
步骤1:对傅里叶变换光谱仪采集到干涉图像进行预处理,得到预处理后的二维干涉数据,根据二维干涉数据的横维像素点数创建一维索引空间,并将一维索引空间映射到GPU,计算快速傅里叶变换所需的旋转因子表:
对于横维为L点的,结构为(n×m)×L的预处理后的二维干涉数据,n为单幅干涉图横向像素点数,m为单幅干涉图横向像素点数,L为依据实际所需光谱分辨率选定的干涉图数目,n为单幅干涉图横向像素点数,m为单幅干涉图纵向 像素点数,需计算拥有L/2个元素的旋转因子表;创建并行一维索引空间NDRange(L/2,1,1),空间大小为L/2,将上述一维索引空间映射到GPU,GPU分配L/2个处理单元用于计算旋转因子,L/2个处理单元计算L/2个元素时,仅需单个处理单元计算一个元素的时间,待处理单元计算完毕,得到旋转因子表。
步骤2:在GPU内部开辟t块缓存并建立流水线结构。
步骤3:将二维干涉数据映射到GPU的二维索引空间进行多重逆序操作:
对于结构为的二维干涉数据,k为干涉数据的分割因子,创建多重逆序二维索引空间其中X维大小为L,Y维大小为将所述多重逆序二维索引空间映射到GPU,GPU分配个处理单元对缓存中的组数据同时进行逆序操作。
步骤4:将干涉数据映射到GPU的二维索引空间进行多重迭代蝶形运算,得到复原光谱数据:
对于结构为的二维干涉数据,创建多重迭代蝶形运算二维索引空间其中X维大小为L/2,Y维大小为将多重迭代蝶形二维索引空间映射到GPU,GPU分配个处理单元,对缓存中的组干涉数据同时进行迭代蝶形运算,得到复原光谱数据。
所述步骤1中,对干涉图像预处理方法如下:对傅里叶变换光谱仪采集到的干涉图像,进行消直流和切趾。
所述步骤2中,建立流水线结构,实现方法如下:
在GPU内部开辟t块缓存,t为大于0的整数,将步骤1中的结构为(n×m)×L的预处理后的二维干涉数据分解为tk个批次,k为干涉数据的分割因子,且k为 大于0的整数;将分解后的结构为的各块二维干涉数据分别送入GPU中开辟的t块缓存中,单块缓存对应结构为的二维干涉数据;按此顺序操作缓存,GPU内第一块缓存读出数据时,正值第二块缓存执行数据处理,同时第三块缓存开始写入数据,以此类推,在t块缓存中形成异步操作。
本发明与现有技术相比,其显著优点在于:(1)能够提高光谱复原中快速傅里叶变换的效率,适用于通用化处理。(2)流水线结构适用于大规模光谱数据的处理。
附图说明
图1为本发明基于GPU计算的干涉数据快速傅里叶变换方法的流程图。
图2为本发明在GPU内部开辟t块缓存并建立流水线结构示意图。
图3为本发明二维索引空间示意图。
具体实施方式
下面结合附图对本发明作进一步详细描述。
结合图1~图3,一种基于GPU计算的干涉数据快速傅里叶变换方法,步骤如下:
步骤1:对傅里叶变换光谱仪采集到干涉图像进行预处理,得到预处理后的二维干涉数据,根据二维干涉数据的横维像素点数创建一维索引空间,并将一维索引空间映射到GPU,计算快速傅里叶变换所需的旋转因子表:
对傅里叶变换光谱仪采集到的干涉图像,进行消直流和切趾得到二维干涉数据,常用的消直流方法有最小二乘法、差分法、低通滤波法等方法,常用的切趾函数有三角窗、矩形窗、Happ-Genzel窗等。
对于横维为L点的,结构为(n×m)×L的预处理后的二维干涉数据,n为单幅干涉图横向像素点数,m为单幅干涉图横向像素点数,L为依据实际所需光谱分辨率选定的干涉图数目,n为单幅干涉图横向像素点数,m为单幅干涉图纵向像素点数,需计算拥有L/2个元素的旋转因子表;创建并行一维索引空间NDRange(L/2,1,1),空间大小为L/2,将上述一维索引空间映射到GPU,GPU 分配L/2个处理单元用于计算旋转因子,L/2个处理单元计算L/2个元素时,仅需单个处理单元计算一个元素的时间,待处理单元计算完毕,得到旋转因子表。
步骤2:在GPU内部开辟t块缓存并建立流水线(overlap)结构:
在GPU内部开辟t块缓存,t为大于0的整数,将步骤1中的结构为(n×m)×L的预处理后的二维干涉数据分解为tk个批次,k为干涉数据的分割因子,且k为大于0的整数;将分解后的结构为的各块二维干涉数据分别送入GPU中开辟的t块缓存中,单块缓存对应结构为的二维干涉数据;按此顺序操作缓存,GPU内第一块缓存读出数据时,正值第二块缓存执行数据处理,同时第三块缓存开始写入数据,以此类推,在t块缓存中形成异步操作,如图2所示。
步骤3:将二维干涉数据映射到GPU的二维索引空间进行多重逆序操作:
对于结构为的二维干涉数据,创建多重逆序二维索引空间 如图3所示,其中X维大小为L,Y维大小为将所述多重逆序二维索引空间映射到GPU,GPU将分配个处理单元对缓存中的组数据同时进行逆序操作。
步骤4:将干涉数据映射到GPU的二维索引空间进行多重迭代蝶形运算,得到复原光谱数据:
对于结构为的二维干涉数据,创建多重迭代蝶形运算二维索引空间如图3所示,其中X维大小为L/2,Y维大小为将多重迭代蝶形二维索引空间映射到GPU,GPU将分配 个处理单元,对缓存中的组干涉数据同时进行迭代蝶形运算, 得到复原光谱数据。
实施例1
以基于Sagnac干涉成像光谱仪采样的干涉数据进行快速傅里叶变换为例,针对单幅干涉图大小512×512像素,取512幅干涉图的情况,处理步骤如下:
步骤1:对傅里叶变换光谱仪采集到干涉图像进行预处理,得到预处理后的二维干涉数据,根据二维干涉数据的横维像素点数创建一维索引空间,并将一维索引空间映射到GPU,计算快速傅里叶变换所需的旋转因子表:
对傅里叶变换光谱仪采集到的干涉图像,用最小二乘法消直流,用三角窗进行切趾。
对于横维为512点的,结构为(512×512)×512的预处理后的二维干涉数据,需计算拥有256个元素的旋转因子表;创建并行一维索引空间NDRange(256,1,1),空间大小为256,将上述一维索引空间映射到GPU,GPU分配256个处理单元用于计算旋转因子,256个处理单元计算256个元素时,仅需单个处理单元计算一个元素的时间,待处理单元计算完毕,得到旋转因子表。
步骤2:在GPU内部开辟3块缓存并建立流水线(overlap)结构:
在GPU内部开辟3块缓存,将步骤1中的结构为(512×512)×512的预处理后的二维干涉数据分解为3×2个批次;将分解后的结构为的各块二维干涉数据分别送入GPU中开辟的3块缓存中,单块缓存对应结构为 的二维干涉数据;按此顺序操作缓存,GPU内第一块缓存读出数据时,正值第二块缓存执行数据处理,同时第三块缓存开始写入数据,以此类推,在t块缓存中形成异步操作,如图2所示。
步骤3:将二维干涉数据映射到GPU的二维索引空间进行多重逆序操作:
对于结构为的二维干涉数据,创建多重逆序二维索引空间如图3所示,其中X维大小512,Y维大小 将所述多重逆序二维索引空间映射到GPU,GPU将分配 个处理单元对缓存中的组数据同时进行逆序操作。
步骤4:将干涉数据映射到GPU的二维索引空间进行多重迭代蝶形运算,得到复原光谱数据:
对于结构为的二维干涉数据,创建多重迭代蝶形运算二维索引空间其中X维大小256,Y维大小 将多重迭代蝶形二维索引空间映射到GPU,GPU将分配 个处理单元,对缓存中的组干涉数据同时进行蝶形运算,计算完毕后得到复原光谱数据。
采用本发明所述的一种基于GPU计算的干涉数据快速傅里叶变换方法,既可有效提高光谱复原中快速傅里叶变换的效率,也能有效处理大规模干涉数据。
- 还没有人留言评论。精彩留言会获得点赞!