一种基于LSM-Tree结构的日志文件系统的构建方法与流程
本发明涉及文件系统技术领域,特别涉及一种基于LSM-Tree结构的日志文件系统的构建方法。
背景技术:
文件系统是操作系统在计算机的磁盘上存储和管理数据的机制。1964年由贝尔实验室、麻省理工学院及北美通用电气公司共同开发研制的Multics分时操作系统,首次提出了目录树结构思想,标志着现代文件系统的起源。
UNIX操作系统将这一树形思想用于自己的文件系统设计中,形成了包含引导块、超级块、索引节点和数据块四个模块的文件系统架构。此后,许许多多文件系统都沿用了这一组织架构。
为了不断提高I/O性能,1984年出现了快速文件系统(Fast File System,简称FFS)。它引入了柱面组(Cylinder Group)的概念,尽可能将同一目录下的若干文件保存在同一组中,将同一个文件的若干数据块保存在同一个组中,这样能够显著减少总寻道时间,提升读写性能。继FFS之后,1989年出现了日志结构文件系统(Log-structured File System),它采用日志追加的思想,以记录日志的形式进行文件的写入,并在日志结构上做索引用于文件的读取,大大提升了写性能,使用这种结构能够实现文件系统崩溃后的快速恢复。
1994年,随着Linux1.0内核的诞生,扩展文件系统(The Extended File System,简称ext)系列开始进入人们视线,ext1是第一个Linux虚拟文件系统(Linux Virtual File System,简称Linux VFS),可管理的最大磁盘空间为2GB,此时ext1各方面还略显简陋。ext2的出现,逐渐开始流行,它具有可管理最大磁盘空间16TB、最大文件大小2TB、最长文件名255字节等诸多优点,但是其在日志管理方面有明显的缺陷,不适合于对安全性要求高的系统。2001年,ext3应运而生,它在ext2基础上加入了健全的日志功能,解决了ext2的致命弱点,使用ext3能够极大提高文件系统数据的可靠性,即使发生非正常宕机,在开机后只需要10秒钟即可恢复数据。为了支持更大的文件、管理更大的磁盘空间、做出若干优化,产生了ext4文件系统,它使用延迟分配、多块分配、无日志模式等来提高性能,并支持无限数量的子目录、在线碎片整理、持久预分配等功能,是对ext3的进一步优化。
ext3是当前最为流行的Linux文件系统,本文挑选ext3作为传统文件系统的代表,将ext3作为研究对象,分析这一类文件系统架构的共同特点。
在ext3等传统文件系统为用户提供高可用性、高存取速度、多日志模式支持等诸多优点的同时,此类传统文件系统架构也有它不足的地方,尤其是对于小文件存储而言,具体来说体现在如下三个方面的缺陷:数据分布随机化、空间浪费和索引节点资源有限。
技术实现要素:
本发明的目的旨在至少解决所述技术缺陷之一。
为此,本发明的目的在于提出一种基于LSM-Tree结构的日志文件系统的构建方法。
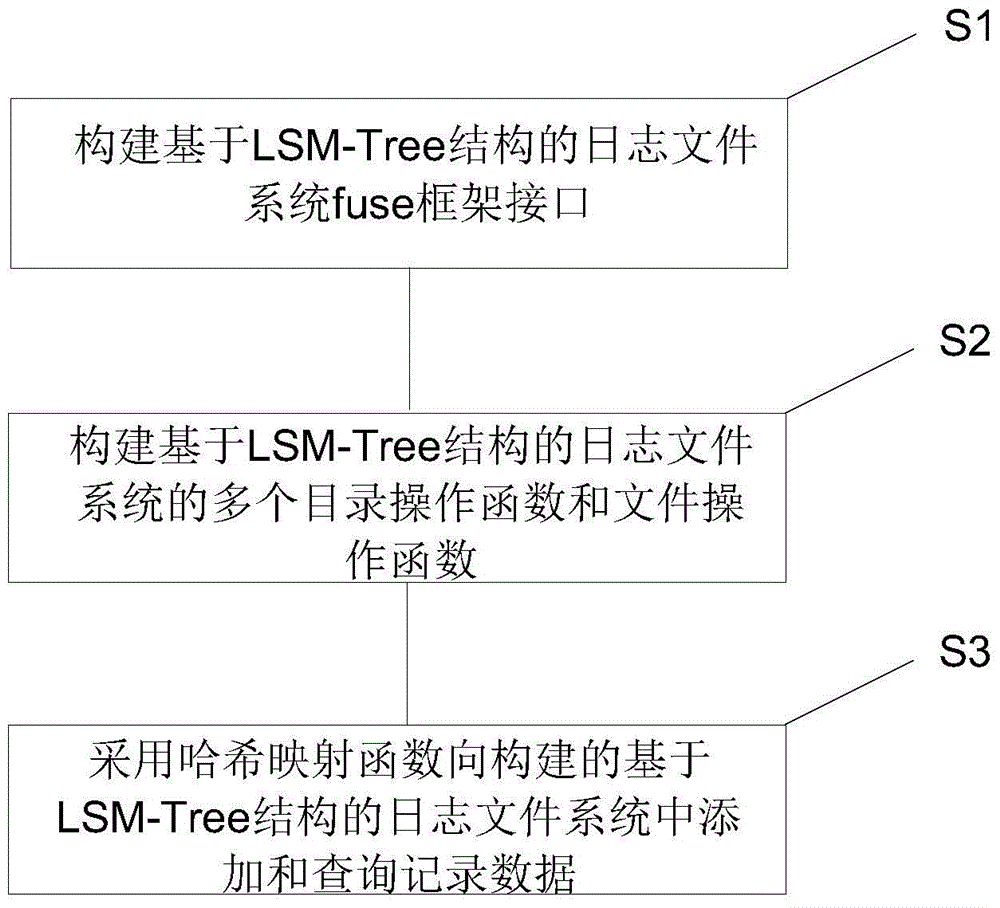
为了实现上述目的,本发明的实施例提供一种基于LSM-Tree结构的日志文件系统的构建方法,包括如下步骤:
步骤S1,构建基于LSM-Tree结构的日志文件系统fuse框架接口,包括如下步骤:
步骤S11,调用fuse_main()函数将fuse文件系统挂载到挂载点上,创建UNIX本地套接字,创建并运行子进程fusermount,然后调用fuse_new()函数为fuse文件系统分配数据存储空间,完成挂载;
步骤S12,完成挂载后,fuse_main()函数调用fuse_loop()开启会话模式,向用户提供会话服务;
步骤S13,采用fusermount-uPATH命令将fuse文件系统卸载,则中断所述会话服务,回收对应的存储空间;
步骤S2,构建基于LSM-Tree结构的日志文件系统的多个目录操作函数和文件操作函数;
步骤S3,采用哈希映射函数向构建的基于LSM-Tree结构的日志文件系统中添加和查询记录数据。
根据本发明实施例的基于LSM-Tree结构的日志文件系统的构建方法,构造的LevelFS文件系统可以在保持大文件读写性能不变的前提下,能够有效地提高目录、小文件的读写性能。
进一步,所述多个目录操作函数包括:目录创建函数fs_mkdir、目录存放列出函数fs_readdi、目录删除函数fs_rmdir;
所述多个文件操作函数包括:文件重命名函数fs_rename、文件打开函数fs_open、文件读取函数fs_read、文件写入函数fs_write、文件大小设置函数fs_truncate、文件权限修改函数fs_chmod、文件账户信息修改函数fs_chown、文件系统信息读取函数fs_statvfs、文件时间戳更新函数fs_utimens、指向target符号链接的文件创建函数fs_symlink、inumber路径获取函数get_disk_path和磁盘文件打开函数open_disk_file。
进一步,在所述步骤S3中,所述采用哈希映射函数向构建的基于LSM-Tree结构的日志文件系统中添加记录数据,包括如下步骤:
设使用k个哈希映射函数,分别将键映射到[0,m-1]之间的k个数,当需要写入一条记录的时候,通过映射找到对应的k个数,然后将字节数组中这k个对应位置中的数都加1,表明系统中存在这样一条记录。
进一步,在所述步骤S3中,所述采用哈希映射函数向构建的基于LSM-Tree结构的日志文件系统中查询记录数据,包括如下步骤:
通过哈希映射函数找到记录数据的对应位置,判断各个位置上的值是否都大于0,如果是,则读取该记录数据。
进一步,在所述步骤S3之后,还包括如下步骤:删除记录数据,则将数组中该条记录对应位置上的数都减1。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的基于LSM-Tree结构的日志文件系统的构建方法的流程图;
图2为根据本发明实施例的构建基于LSM-Tree结构的日志文件系统fuse框架接口的流程图;
图3为根据本发明实施例所述基于LSM-Tree结构的日志文件系统的fuse框架接口的示意图;
图4为根据本发明实施例所述基于LSM-Tree结构的日志文件系统的mkdir命令的数据流程图;
图5为根据本发明实施例所述添加记录x、y数据结构图;
图6为根据本发明实施例所述查询p、q操作流程图;
图7为根据本发明实施例所述删除记录数据结构图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
本发明针对传统的文件系统对于小文件的存取效率低下的不足,提出一种基于LSM-Tree(Log-Structured-Merge Tree)结构的日志文件系统的构建方法,构建基于LSM-Tree结构的日志文件系统,实现了基于上述基本架构的使用日志来构造的文件系统LevelFS,从而可以为小文件设计存取优化的技术方案,提高对大量的小文件存取操作的效率。
本发明提出的基于LSM-Tree结构的日志文件系统的构建方法,包括以下步骤:通过在内存中设置写缓存,将若干小文件的磁盘随机写变成磁盘顺序写以提高写效率,同时在磁盘上减少关联数据的存储距离以提高读效率,从而提高文件系统的读写性能。
如图1所示,本发明实施例的基于LSM-Tree结构的日志文件系统的构建方法,包括如下步骤:
步骤S1,构建基于LSM-Tree结构的日志文件系统fuse框架接口,包括如下步骤:
参考图2和图3所示,fuse框架接口分为三个部分:挂载、回话和卸载。
步骤S11,调用fuse_main()函数将fuse文件系统挂载到挂载点上,创建UNIX本地套接字,创建并运行子进程fusermount,然后调用fuse_new()函数为fuse文件系统分配数据存储空间,完成挂载。
挂载部分:用户运行编译链接后的可执行文件,会调用fuse_main()函数解析挂载点、多线程支持等参数,标志着FUSE文件系统生命周期的开始。fuse_main()函数会调用fuse_mount()函数将fuse文件系统挂载到挂载点上,创建UNIX本地套接字,创建并运行子进程fusermount,然后调用fuse_new()函数为fuse文件系统分配数据存储空间fuse_datastructure,挂载完毕。
步骤S12,完成挂载后,fuse_main()函数调用fuse_loop()开启会话模式,向用户提供会话服务。
会话部分:fuse_main()函数在挂载完成后调用fuse_loop()开启会话模式,为用户提供不断的接收回话(receive session)、处理会话(process session)、返回会话的服务。
步骤S13,采用fusermount-uPATH命令将fuse文件系统卸载,则中断回话服务,回收对应的存储空间。
卸载部分:用户使用fusermount–u PATH命令将fuse文件系统卸载,则会话中断,存储空间回收,标志着FUSE文件系统生命周期的结束。
步骤S2,构建基于LSM-Tree结构的日志文件系统的多个目录操作函数和文件操作函数。
图4是本发明实施例所述基于LSM-Tree结构的日志文件系统的mkdir命令的数据流程图,如图4所示,以linux下的mkdir命令为例,在“/”下创建目录“hi”,通过层层解析后传递给LevelFS的int fs_mkdir(const char*path,mode_t mode)函数。下面具体来介绍一下目录、文件操作相关函数的功能和要点。
在本发明的一个实施例中,多个目录操作函数包括:目录创建函数fs_mkdir、目录存放列出函数fs_readdi、目录删除函数fs_rmdir。
(1)fs_mkdir
功能:在指定路径上创建目录。
要点:首先,将path解析为父目录par_path和子目录文件dir_name,根据par_path找到父节点的编号par_inumber,同时取出的还有父节点的meta信息,结合账户信息判断用户是否具有par_path目录下创建文件的权限,如果没有则返回错误。如果有权限,则为该目录文件分配i_number=cur_inumber+1,创建fs_inode数据结构作为new_dir的元数据信息,填充账户信息、时间戳信息,设置硬链接数为1,设置i_number为++cur_inumber,设置文件类型为目录。最后将{par_inumber}/{dir_name}->{i_number}:{fs_inode}写入LevelDB中。
(2)fs_readdir
功能:列出存放在指定路径上的目录项列表。这条命令对应于linux终端的ls指令。
要点:首先,根据path打开目录文件(具体过程请参考fs_open),如果打开成功则取出目录节点的i_number;然后,使用LevelDB中的Iterator遍历key在range[i_number+“/”,i_number+1)中的key-value记录;最后将各条记录的filename填充入filler列表中,返回。
(3)fs_rmdir
功能:将指定路径上的目录删除。
要点:首先,同样从path中解析出父目录par_path和子目录文件dir_name,根据par_path找到父节点的编号par_inumber、meta,判断删除权限;如果有权限,则只需向LevelDB中写入记录{par_inumber}/{dir_name}->Delete即可。
多个文件操作函数包括:文件重命名函数fs_rename、文件打开函数fs_open、文件读取函数fs_read、文件写入函数fs_write、文件大小设置函数fs_truncate、文件权限修改函数fs_chmod、文件账户信息修改函数fs_chown、文件系统信息读取函数fs_statvfs、文件时间戳更新函数fs_utimens、指向target符号链接的文件创建函数fs_symlink、inumber路径获取函数get_disk_path和磁盘文件打开函数open_disk_file。
(4)fs_rename
功能:将指定路径下的文件改名。
要点:首先,同样是读父目录,判断是否对父目录具有写的权限(这里就不再赘述了),取出了par_inumber;然后,读出{par_path}/{old_name}的Value信息,记为r_value;最后向LevelDB中写入记录{par_inumber}/{old_name}->Delete和{par_inumber}/{old_name}->{r_value}即可。
(5)fs_open
功能:将指定路径上的文件打开。
要点:首先,读父目录,获得par_inumber和par_meta,根据par_meta检查权限;然后将key为{par_inumber}/{filename}的记录项fs_record存入高速缓存中,创建一个fs_openfile数据结构,填充fs_record的地址指针、使用者账户信息等,设置文件当前位置为0,设置文件在r_value中的开始位置,并设置fs_record中的r_count为1,文件成功打开。
(6)fs_read
功能:读取指定路径上的文件的指定位置上的内容。
要点:在读取一个文件的内容前,首先需使用fs_open打开文件,这时文件内容已经在内存中,由于LevelDB每条记录的数据量较小,在取文件meta的同时将文件的data也一并取出。若文件属于大文件,则通过get_disk_path和open_disk_file打开位于本地文件系统中的大文件。无论是大文件还是小文件,最后均通过fs_openfile数据结构中的f_start和f_pos进行数据的读取工作即可。
(7)fs_write
功能:往指定路径上的文件的指定位置写数据。
要点:与fs_read一样,在写文件内容前,首先使用fs_open打开文件;然后将fs_openfile中的f_pos调整到指定的位置,开始数据的写入;随着数据的写入,f_pos也不断往后移动。需要注意的是,在每个写操作之前需要检查写完后文件的总大小,如果文件总大小超出了阈值,则将原本存储于LevelDB中的文件内容迁移到本地文件系统中。
(8)fs_truncate
功能:设定指定路径上的文件的新大小。
要点:获取文件的元数据信息之后,修改相应的size信息,以及文件的时间戳。需要注意的是,若truncate之前文件size小于threshold,而truncate之后文件size大于threshold,则需要将LevelDB中的小文件迁移至本地文件系统中,以大文件的形式进行存储,反之则不然。
(9)fs_chmod
功能:修改指定路径上的文件的新权限标志位。
要点:通过父目录获取文件的元数据信息,读取其中的stat,然后将stat.st_mode更改为新的mode,最后将修改后的记录项写回即可。
(10)fs_chown
功能:修改指定路径上的文件的账户信息。
要点:与fs_chmod类似,首先通过父目录获取文件的元数据信息,读取其中的stat,然后设置stat.st_uid=uid以及stat.st_gid=gid,最后将修改后的纪录项写回即可。
(11)fs_statvfs
功能:读取文件系统信息,如已使用空间、自由空间、空闲block树,存入statvfs中,这是本地文件系统的统计信息,直接调用本地文件系统的statvfs(path,stbuf)接口即可。
(12)fs_utimens
功能:更新指定路径上的文件的时间戳信息。
要点:与fs_chmode类似,首先通过父目录获取文件的元数据信息,读取其中的stat,然后设置新的st_atim、st_mtim,而对于st_ctim,由于创建时间是操作系统管理的,所以不允许用户进行修改。
(13)fs_symlink
功能:在指定路径上创建一个指向target符号链接的文件
要点:首先通过父目录获取文件的fs_inode,将所链接到的target字符串存入value中,设置is_large=false,将生成的path记录写回即可。
(14)get_disk_path
功能:获得inumber所对应的路径
要点:非对外接口,主要是根据inumber计算所对应的索引路径,对于大文件的映射具有重要的作用。具体地,对于大文件的映射规则例如包括:
首先,获得LevelFS为文件分配的64位正整数i_number,需要观察它的特点。虽然i_number范围为64位,但是它是从0开始不断往上增长的,并不像内存地址那样是随机分配的。这也就决定了当文件系统规模比较小时,i_number的可能只有较低的若干位有数据,而大部分高位都为0;当文件系统逐渐增大时,i_number数据也越来越大,有效数据的位数也越来越多。
然后,将这64位正整数从低位开始以13位为一组进行分组,共有5组数字,命名为p0、p1、p2、p3、p4,除p4不满13位外,其余各组数字的范围都是0~2^13–1。
最后,LevelDB使用如下规则进行映射:
(1)如果i_number<226(也即81922),那么映射路径为/{p1}/{p0},例如i_number=9000,那么它所对应的存储路径就为/1/808;
(2)如果i_number>=226,且i_number<239,那么映射路径为/a/{p2}/{p1}/{p0};
(3)如果i_number>=239,且i_number<252,则映射路径为/b/{p3}/{p2}/{p1}/{p0};
(4)如果i_number>=252,且i_number<264,则映射路径为/c/{p4}/{p3}/{p2}/{p1}/{p0}。
需要说明的是,LevelFS之所以采用上述的映射规则,主要有如下几点原因:
首先,当一个目录中的目录项数量过大的时候,对其按文件名进行搜索的速度就会变的很慢。因此,LevelFS采用分级的思想,以13bit为一组,将每个目录节点中的目录项数控制在213数量级以内。
然后,如果直接采用多级索引的方式,每13位建立一级索引,那么检索到一个文件需要5级,即使是在文件系统数据量很小,检索123号文件同样需要5级索引,这样开销比较大,也没有必要。因此,LevelFS采用非平衡的方式,当文件系统规模比较小时,就使用/{p1}/{p0}的两层索引方式,比起直接的多级索引能减少总的索引次数。
最后,当i_number很大了之后,超过了108,说明文件系统的规模已经很大了,这时再根据i_number的规模决定是去搜索/a/路径还是/b/路径还是/c/路径。
采用这种非平衡多级索引的方式,能很好符合inode号顺序增长的特点,使得文件系统无论在较小规模还是较大规模都能有合适的索引级数,尽可能地降低平均索引次数;同时,又充分限制了每个目录中的目录项数量,减少每个目录中的索引时间。
(15)open_disk_file
功能:打开fs_inode_header*iheader对象的磁盘文件。
要点:非对外接口,根据iheader.st_ino调用get_disk_path获取文件路径,然后配合flags调用本地文件系统的open函数,记录打开文件信息。
步骤S3,采用哈希映射函数向构建的基于LSM-Tree结构的日志文件系统中添加和查询记录数据。
采用哈希映射函数向构建的基于LSM-Tree结构的日志文件系统中添加记录数据,包括如下步骤:
设使用k个哈希映射函数,分别将键映射到[0,m-1]之间的k个数,当需要写入一条记录的时候,通过映射找到对应的k个数,然后将字节数组中这k个对应位置中的数都加1,表明系统中存在这样一条记录。
图5是本发明实施例所述添加记录x、y数据结构图,如图5所示:
假设使用k个哈希映射函数,能够分别将键映射到[0,m-1]之间的k个数。当需要写入一条记录的时候,通过映射找到对应的k个数,然后将字节数组中这k个对应位置中的数都加1,表明系统中存在这样一条记录。举例来说,假设k=3,写入记录x和y,hashs(x)=[2,4,7],hashs(y)=[4,8,11],此时的数组变为图5所示。
采用哈希映射函数向构建的基于LSM-Tree结构的日志文件系统中查询记录数据,包括如下步骤:
通过哈希映射函数找到记录数据的对应位置,判断各个位置上的值是否都大于0,如果是,则读取该记录数据。
图6是本发明实施例所述查询p、q操作流程图,如图6所示,当需要读记录时,首先通过hashs找到对应位置,判断各位置上的值是否都大于0。如果hashs(p)=[1,4,11],查数组发现1位置上对应的数为0,则记录p一定不在LevelDB中,不需要继续往下找,返回读失败;如果hashs(q)=[4,8,11],各位置上的数均大于0,则记录q有可能在LevelDB中,q的读取不能被过滤掉。
在步骤S3之后,还包括如下步骤:删除记录数据,则将数组中该条记录对应位置上的数都减1。
图7是本发明实施例所述删除记录数据结构图,如图7所示,当需要删除一条记录时,则将数组中该条记录对应位置上的数都减1,删除记录x之后的数组内容如图7所示。
根据本发明实施例的基于LSM-Tree结构的日志文件系统的构建方法,构造的LevelFS文件系统可以在保持大文件读写性能不变的前提下,能够有效地提高目录、小文件的读写性能。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求极其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!