一种基于时间序列类别的计算机数据分类方法与流程
本发明涉及时间序列的数据分析技巧,特别是涉及一种基于Shapelet时间序列类别的计算机数据分类方法。
背景技术:
近年来,由于时间序列的大量出现在多媒体、医学、金融等应用领域,时间序列分析成为研究人员研究的一大热点。时间序列分类作为其中的一个重要分支,在国内外得到了广泛的研究。
在众多时间序列分析方法中,Ye L,Keogh E等人提出的时间序列Shapelet特征,提供了一个很好的解释性,并且保证了不错的性能。Shapelet特征为衡量两个时间序列的局部相似性提供了一种可能。两个时间序列若存在相似的局部形状,在一定程度上便可认为它们存在相似性,Shapelet特征正是衡量这一相似性的手段。文献:Ye L,Keogh E.Time series shapelets:a new primitive for data mining.Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2009:947-956.
Ye L,Keogh E等人在提出Shapelet特征时,是通过信息增益指标,在所有时间序列的子序列中递归的搜索信息增益最大的子序列作为Shapelet特征,同时构建决策树作为分类器。但由于时间序列的子序列太多,Shapelet的搜索非常慢,通常会配合加速算法,例如:剪枝、SAX、使用GPU加速等,但速度依然比较慢。另一方面,由于决策树是一种比较弱的分类器,使得Ye L,Keogh等人的算法在分类准确率上面效果一般。
为了克服Shapelet在准确率方面的瓶颈,Lines J等人特出通过其它的评价指标选取Shapelet,例如F-statistics、Kruskall-Wallis等统计指标。在选取完Shapelet之后,将时间序列转换到Shapelet空间表示,然后再训练SVM或其它强分类器。这种方法的确提高了分类性能,但速度依然慢,而且在选取Shapelet特征时,没有考虑Shapelet之间的关系。文献:Lines J,Davis L M,Hills J,et al.A shapelet transform for time series classification.Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2012:289-297.
技术实现要素:
发明目的:克服现有Shapelet算法中候选项太多的弱点,引入聚类算法,对候选项子序列进行聚类,大幅降低候选集合复杂度,以加速算法的运行。同时,在Shapelet的选择方面考虑Shapelet之间的关系,使用强分类器,在训练分类器的同时选择Shapelet,以提高分类性能。
为了解决上述技术问题,本发明公开了一种基于Shapelet特征学习的时间序列类别的计算机数据分类方法,该方法可以用于机器环境感知、视频流识别、web流量异常识别、地震监测等应用中,包括以下步骤:
步骤1,生成搜索长度集合;
步骤2,为每一个搜索长度,生成所有时间序列数据的子序列,子序列的长度为L2,并标准化所有子序列,标准化后的所有子序列组成集合S;
步骤3,利用集合S,训练一个SOINN神经网络,将训练好的神经网络的每一个节点,加入到Shapelet候选集合C中;
步骤4,使用Shapelet候选集合C,将所有时间序列转换到Shapelet表示,转换后的数据集合为T;
步骤5,使用特征选取算法,在数据集合T上选取特征,得到特征集合为A,同时训练得到分类器Cls;
步骤6,对于特征集合A中的每一个特征,将其相应的候选Shapelet加入到Shapelet集合中;
步骤7,预测时间序列的类别:使用Shapelet集合中的Shapelet对时间序列进行转换,然后使用分类器Cls对转换后的数据进行分类。
其中,SOINN神经网络是一种自组织增量神经网络,Shapelet是一种衡量两个时间序列数据局部相似性的特征。
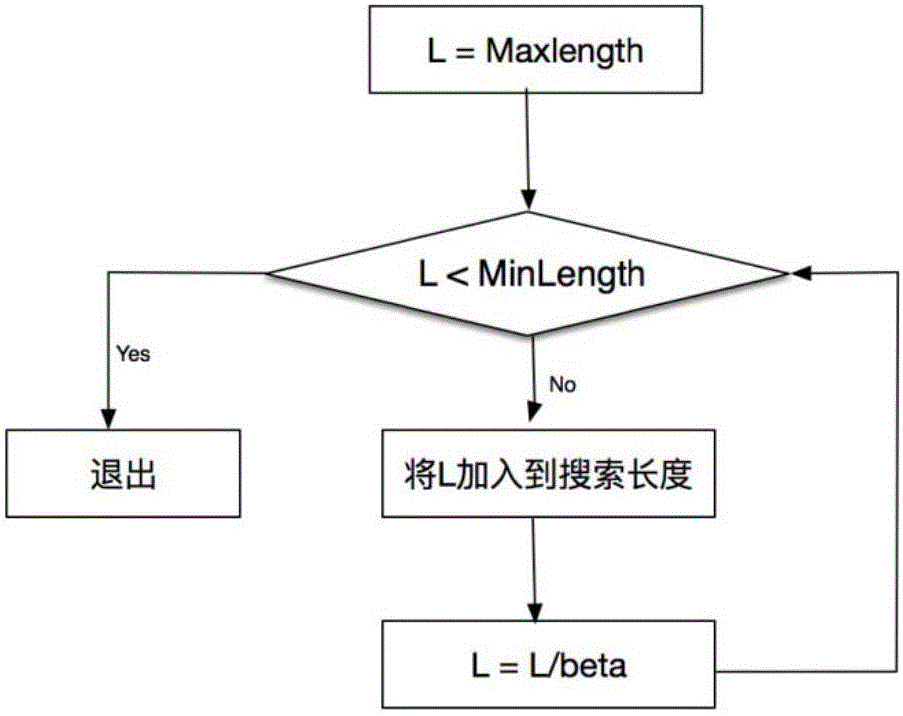
步骤1中,设定最大搜索长度MaxLength,最小搜索长度MinLength和参数beta(取值范围为大于1的实数),令L=MaxLength,将L加入到搜索集合,然后除以beta,重复这一过程直至L小于MinLength。包括如下步骤:
步骤1-1,人工设定参数:最大搜索长度MaxLength,最小搜索长度MinLength和参数beta,跳转至步骤1-2;
步骤1-2,令L=MaxLength,若L<MinLength,则结束步骤1;否则将L加入到搜索长度集合中,跳转至步骤1-3;
步骤1-3,将L更新为L/beta,跳转至步骤1-2。
步骤2中,假设时间序列t的搜索长度为N,则其开始于位置e的长度为L2的子序列集合S为<t(e),t(e+1),…t(e+L2-1)>,采用z-标准化,将该子序列归一化为均值等于0,方差等于1,标准化的方法如下:
mean(S)=(S(1)+S(2)+…+S(L2))/L2,
std(S)=sqrt(((S(1)-mean(S))^2+(S(2)-mean(S))^2+…+(S(L2)-mean(S))^2)/L2),
S=<(S(1)-mean(S))/std(S),(S(2)-mean(S))/std(S),…,(S(L2)-mean(S))/std(S)>,
其中,mean(S)表示子序列集合S中所有数据的平均值,S(e)表示子序列集合S中位置e上的取值,std(S)表示子序列集合S中所有数据的标准差,sqrt表示开方运算。
步骤3中使用的聚类算法为SOINN自组织增量神经网络算法,SOINN神经网络由节点集合和边集合构成,每个节点都有一个权重、阈值和累积值,节点的阈值为该节点的邻居中离该节点最远的节点与该节点的距离,节点的权重为所有属于该节点的类别的数据的平均值,节点的累积值为属于该节点类别的数据的数量。
步骤4中,长度为N的时间序列t和长度为L2的Shapelet sp之间的距离为时间序列t的所有标准化后的长度为L2的子序列与sp的欧式距离中最小的一个,定义如下:
dist(sp,t)=minq EuclideanDistance(sp,S(t,L2,q)),
其中,S(t,L2,q)代表时间序列t起始于位置q的长度为L2的标准化后的子序列,EuclideanDistance代表欧式距离,minq代表位置q变动时后面式子的最小值,dist(sp,t)代表Shapelet sp和时间序列t之间的距离,sp表示一个Shapelet;
时间序列t在Shapelet空间中,对应属性上的属性值如下:
tran(sp,t)=exp(-dist(sp,t)/(sp.threshold*alpha);
其中alpha为设置的参数,dist(sp,t)为Shapelet sp和时间序列t之间的距离,exp为指数函数,sp.threshold为候选Shapelet sp在SOINN神经网络中对应节点的阈值,tran(sp,t)代表转化后的属性值,
给定K1个候选Shapelet<sp1,sp2,…,spK1>,时间序列t转化到Shapelet空间后的数据为:
<tran(sp1,t),tran(sp2,t),…,tran(spK1,t)>;
其中tran(spR,t)为表示时间序列t在Shapelet spR上的取值,R取值范围为1~K1,
根据上述方式将所有时间序列转换到Shapelet空间得到一个新的数据集合T。
步骤5中,使用L1正则化项作为特征选择算法,svm作为分类器,训练过程为最小化以下损失函数L(w):
其中n为时间序列数量,k为候选Shapelet数量,w为svm的权重,wj为权重w第j维上的取值,wT为权重w的转置,xi为第i个时间序列转化到Shapelet空间后的数据,yi为第i个时间序列的类别,C为设置的参数,max(x,y)代表取x,y中的最大值,最小化L(w)后,得到的w即为svm分类器的权重。
步骤6中,使用步骤5中,训练的w,选择Shapelet,方法是:如果一个w在一个特征上的取值不为0,则将其对应的候选Shapelet加入到Shapelet集合中;否则将w在该特征上的取值全部删除。
步骤7中,对于一个新的时间序列,首先使用步骤6中选取的Shapelet集合,将时间序列数据转化到Shapelet空间,然后使用训练好的w对转化后的数据进行分类。对于二类问题,只训练一个w,分类时,若wTx1>0,输出正类,否则,输出负类;对于多类问题,对于每一个类别,训练一个w,分类时,输出wTx1最大的类别,x1表示转化后的数据。
有益效果:本发明的显著优点是大大降低了Shapelet候选项的数量,大幅缩短了算法的运行时间,同时,提高了Shapelet的质量。由于选取Shapelet时,考虑了Shapelet之间的关系,同时使用了强分类器,大大提高了分类器的准确率,从而提升了算法性能。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
图1为本发明学习Shapelet的流程图。
图2为本发明生成搜索长度的流程图。
图3为本发明中SOINN神经网络训练的流程图。
图4为本发明在28个时间序列数据集上进行实例验证时的分类准确率。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚明晰,本章结合附图对发明做更近一步的详细描述。
图1是本发明的学习Shapelet流程图,包括6个步骤。
步骤1中,设定最大搜索长度MaxLength,最小搜索长度MinLength和参数beta(取值范围为大于1的实数),令L=MaxLength,将L加入到搜索集合,然后除以beta,重复这一过程直至L小于MinLength。这一过程流程图见图2,包括如下步骤:
步骤1-1,人工设定参数:最大搜索长度MaxLength,最小搜索长度MinLength和参数beta,跳转至步骤1-2;
步骤1-2,令L=MaxLength,若L<MinLength,则结束步骤1;否则将L加入到搜索长度集合中,跳转至步骤1-3;
步骤1-3,将L更新为L/beta,跳转至步骤1-2。
在第二个步骤中,生成所有时间序列的子序列。子序列的定义为:
给定一个长度L,长度为N的时间序列t=<t(1),t(2),…,t(N)>,起始点q,那么t的起始于q的长度为L的子序列S(t,L,q)=<t(q),t(q+1),…,t(q+L-1)>,其中1<=q<=N-L+1。t的所有长度为L的子序列组成的集合为:S(t,L)={S(t,L,1),S(t,L,2),…,S(t,L,N-L+1)}。对于每个子序列,都将其标准化,标准化的方法为:
mean(S)=(S(1)+S(2)+…+S(L))/L;
std(S)=sqrt(((S(1)-mean(S))^2+(S(2)-mean(S))^2+…+(S(L)-mean(S))^2)/L);
S=<(S(1)-mean(S))/std(S),(S(2)-mean(S))/std(S),…,(S(L)-mean(S))/std(S)>。
对于每一个长度L,为所有子序列,生成所有长度为L的子序列,并标准化。
在第三个步骤中,对于每一个搜索长度L,使用步骤二中得到的长度为L的子序列,训练一个SOINN神经网络,将神经网络的每一个节点,看作一个候选Shapelet。其中SOINN神经网络的训练流程图见图3。
SOINN神经网络为一个单层神经网络,采用竞争学习规则,采用在线学习算法,每次输入一个数据,神经网络自动学出输入数据的结构,并生成能够代表整个数据集的代表点。
SOINN神经网络由节点集合和边集合构成。每个节点都有一个权重,阈值,和累积值。节点的阈值为该节点的邻居中,离该节点最远的节点与该节点的距离。节点的权重为所有属于该节点的类别的数据的平均值。节点的累积值为属于该节点类别的数据的数量。SOINN神经网络初始化时,使用前两个数据初始化两个节点,它们之间初始化为无连接,权重为各自的数据。之后每次输入一个数据x,首先搜索离x最近的两个节点,记为第一获胜节点和第二获胜节点。若x与第一获胜节点的距离大于第一获胜节点的阈值,或x与第二获胜节点的距离小于第二获胜节点的阈值,则使用x创建一个新的节点,否则执行获胜节点更新:若两个获胜节点无边,则连接它们;接着,设置两个节点的边为新边(年龄为1);更新第一获胜节点的阈值,累积值;将第一获胜节点与其它邻居的连接的年龄加1;更新第二节点的阈值;每lamda个数据,对神经网络进行一次除燥,删除孤立的且累积值小于平均累积值的节点,和只有一个邻居并且累积值小于c倍平均值累积值的节点。
在第四个步骤中,将每个时间序列转化为Shapelet空间表示。给定一个长度为N的时间序列t和一个长度为L的Shapelet sp,它们之间的距离为T的所有标准化后的长度为L的子序列中,欧式距离与S最短的子序列与S的欧式距离,定义为
dist(sp,t)=minq EuclideanDistance(sp,S(t,L,q));
其中,S(t,L,q)代表时间序列t起始于位置q的长度为L的标准化后的子序列,EuclideanDistance代表欧式距离,minq代表q变动时后面式子的最小值。dist(sp,t)代表Shapelet sp和时间序列t之间的距离。
给定Shapelet sp时间序列t在Shapelet空间中,对应属性上的属性值为:
tran(sp,t)=exp(-dist(sp,t)/(sp.threshold*alpha);
其中alpha为人工定义的参数,dist(sp,t)为sp和t之间的距离,exp为指数函数,sp.threshold为候选Shapelet sp在SOINN神经网络中对应节点的阈值,tran(sp,t)代表转化后的属性值。
给定K个候选Shapelet<sp1,sp2,…,spK>,时间序列t转化到Shapelet空间后的数据为:
<tran(sp1,t),tran(sp2,t),…,tran(spK,t)>;
将所有时间序列转换到Shapelet空间得到一个新的数据集。
在第五个步骤中,使用带L1正则化项的L2损失函数形式的SVM作为分类器,在转换到Shapelet空间上的数据集上训练。由于L1正则化项能够产生稀疏解,可以删除那些权重全为0的属性,剩下的属性被选择出来。训练过程为最小化以下损失函数:
其中n为时间序列数量,k为候选Shapelet数量,w为svm的权重,wj为w第j维上的取值,wT为w的转置,xi为第i个时间序列转化到Shapelet空间后的数据,yi为第i个时间序列的类别,C为人工定义的参数,max(x,y)代表取x,y中的最大值,L(w)为损失函数。最小化L(w)的方法很多,有牛顿法、随机梯度下降和LBFGS等。本发明使用的是LBFGS算法。
在第6个步骤中,对于每一个候选Shapelet,若其对应的属性,在第五个步骤中,被选择下来,则该候选Shapelet被选出。
训练好模型后,在对新的时间序列进行预测时,使用选出的Shapelet,对新的时间序列进行转换,得到Shapelet空间的数据,然后使用训练好的svm对转换后的数据进行预测。
实施例
为了验证模型的有效性,在28个时间序列的数据集上进行实例验证。每一个数据集包含一个训练集和测试集。对每一个数据集,使用其训练集合中的时间序列,按照图1所示的6个步骤学习Shapelet,同时训练svm分类器,然后使用训练好的Shapelet和分类器预测测试集合中的时间序列,并计算分类准确率。
以这28个数据集中的SonyAIBORobotSurface数据集为例,该数据集由是Sony公司AIBO机器人的X轴的加速度计读数测量的地表数据构成。包含两类数据,分别对应地毯和水泥上测得的数据。该数据的训练集中包含20个时间序列,测试集中包含601个时间序列。利用训练集中的20条时间序列,按照以下步骤学习Shapelet和训练分类器:
1、设定最长长度和最短长度,在这个数据集合上均设定为25,使用图2的方法,生成所有搜索长度,本例中搜索长度只有一个,为25。
2、为每个搜索长度,生成训练集中20个时间序列的所有长度为L的子序列,并标准化它们,得到子序列集合。
3、为每个搜索长度,使用其对应的子序列集合训练一个SOINN神经网络,将训练好的网络中的节点对应的子序列,加入到候选集中,候选集中的每一个子序列都为一个候选Shapelet。
4、使用候选集中的候选Shapelet,将训练集中的20个时间序列转换到Shapelet空间。
5、使用转换后的20个时间序列的数据,训练一个带L1正则化项的svm分类器,并进行属性选择。
6、对于每一个候选Shapelet,若其对应的属性,在步骤5中,被选择下来,则该候选Shapelet被选出。
最终学习得到了16个Shapelet,并训练了一个svm分类器。使用这16个Shapelet,对测试集中601个时间序列进行特征转换,然后使用训练好的svm分类器对转换后的序列进行类别预测,结果达到了97%的正确率,好于LTS,Shapelet Tree等同类方法。在训练时间上,本发明只需要0.02秒,而LTS需要11.415秒,Shaplet Tree需要6.13秒。所以本发明用于这一机器人环境感知的应用时,具备训练时间短、预测准确率高的优点。
图4列出了本发明与其他10种算法在28个数据集上的分类准确率,其中,表的第一行列出了不同的方法,本发明方法为LCS,其余的每一行列出了所有方法在某个数据集合上的分类准确率。结果显示,本发明在分类准确率方面具有优异的表现,平均准确率排名仅略微低于LTS,但是本发明LCS在28个数据集上的训练时间平均比LTS快60.28倍。由于本发明使用了soinn神经网络对时间子序列进行聚类,极大程度上减少了候选集的大小,因此大大缩短了训练时间。另一方面,聚类中心是多个时间子序列的平均,能够更好的代表一个时间序列类别,因此提供了更好的Shapelet候选项,进而提高了分类准确率。
本发明提供了一种基于时间序列类别的计算机数据分类方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!