基于人类视觉感知的图像识别方法与流程
本发明涉及模式识别、人工智能、计算机视觉,堆叠自动编码机。特别涉及基于特征组合的对象特征提取模型HMAX与深度学习模型下的堆叠自动编码机SDA。
背景技术:
对图像进行精确识别,具有非常重要的研究意义,图像识别技术在医药学、航天、军事、工农业等诸多方面发挥着重要的作用。当前图像识别方法大多采用人工提取特征,不仅费时费力,而且提取困难。自从深度学习的复兴以来,它已经成为不同学科的最先进系统的一部分,特别是在计算机视觉方面。目前,深度神经网络的形式已被证明是深度学习结构中几乎是最好的结构。
深度学习是一种非监督学习,学习过程中可以不知道样本的标签值,整个过程无需人工参与也能提取到好的特征。近年来,将深度学习用于图像识别成为了图像识别领域的研究热点,已取得了良好的效果,并且有广阔的研究空间。
Hinton等提出的深度信念网络(DBN)则应用了一种无监督的预训练方法成功解决了这个问题。由限制波兹曼机(RBM)基本模块搭建而成的DBN是一个多层结构的生成式网络模型。通过自下而上的层级训练方式,将模型参数限定在了对下一步学习有利的数值范围内。这种无监督预训练与监督训练学习微调的思想在机器学习领域产生了巨大的影响。
DBN在图像识别领域中得到了广泛的应用,例如人脸识别,手写字体识别,自然场景识别等。但深度信念网络(DBNs)在识别率上和卷积神经网络(CNNs)相比略有下降;由于其参数量大。如果对参数调节不够精细,在训练时间上也不具有优势。
当前基于人类感知的图像识别算法存在以下几点待解决问题:
1,在对图像进行特征提取之前,必须对原始图像进行复杂预先处理流程,包括:滤波,分割和配准等一系列操作,如图1所示。
预处理方式存在以下几方面的问题:
a)任何一种降噪方法势必造成对原始图像中有利信息的损失。
b)不恰当的分割方法会极大的影响图像目标形态,边缘以及纹理特征。这对后续的识别工作造成了困扰。
c)部分分割方法对图像的分辨率要求较高,而这恰恰与现实中大部分图像的成像原理相悖。
d)同一预处理方法应用不同场景不具有通用型,造成同一方法在不同场景中的识别准确率不高。
2,经典的基于人类感知的分类方法(如,DBN)方法训练参数过多。而一个超高维参数的最优结果的寻优过程是一个相当复杂的过程。这增加了方法使用的复杂度,降低了算法的计算性能。
3,目前大部分方法需对原始图像目标区域或背景区域进行标注。这个过程需要大量的计算过程及人工参与操作,实用性不高。
技术实现要素:
由于基于人类视觉的标准模型中采用的特征维数较高,训练图像数目较大,使得计算量非常大且训练时间相当长,对实际应用给出了较强的限制。
鉴于此,本方法力求在保证算法的分类准确率的前提下,简化特征维数,降低计算复杂度,减少训练时间。着力提高算法的计算效率,使算法具有较高的可用性。由于人类视觉感知系统能够对捕捉到大部分图像的关键信息,并将其辨别出来,本方法通过模拟人类判别图像中目标的方式来区分图像内容。
首先,本方法使用HMAX特征,对原始图像进行提取。HMAX模型是一种通用的对象识别模型,它的基础是生物学中对视皮层进行对象识别的机制的研究。HMAX模型模拟灵长类动物在识别物体时视皮层神经活动过程而生成。HMAX模型在模式识别领域主要用于识别对象的特征提取,所提取的特征称为HMAX特征。
HMAX的优势在于:
1)HMAX模拟人类视觉感知机理,能够基于原始图像对其进行特征提取,避免了对图像的预处理操作。
2)HMAX所提取出的关键特征降低图像识别的维度,有利于提高分类判别过程的运算性能。
其次,利用堆叠自动编码机(Stacked Denoising Autoencoder,SDA)SDA对得到的HMAX特征进行训练。SDA是深度学习中的变形结构,与DBN一样具有良好的深度学习数据特征的能力。
SDA的优势在于:
1)SDA训练过程中是无监督学习过程和对数据的破坏过程,这样可以学习到数据集中的特征和数据结构,进一步降低特征维数,学习得到的隐含表示更适用于有监督分类。
2)因为SDA不需要吉布斯采样,在大部分情况下SDA要优于深度置信网络(DBN),并且训练更加容易。
最终,应用FFNN对测试图像中的目标进行识别。
该方法能够实现在检测目标时对原始图像进行预处理,且分类准确率也达到了人类对目标的识别等级。因此,本方法综合应用了人类认识视觉系统提取图像中目标特征;并且利用深度学习中的SDA方法,提高了算法的计算效率和分类准确率,实现对图像的分类、判别。
针对现有方法,本方法的优势包括:
1)HMAX特征能够直接对原始图像进行操作,避免对原始图像进行繁琐的预处理操作,提高了方法的可用性。
2)能够模拟人类视觉,把握图像中目标的本质特征值,对下面的分类操作起到了降维的作用。
3)堆叠去噪自编码器(SDA)是第一个真正多层结构学习算法,它利用空间相对关系减少训练参数数目,以提高一般前向BP的训练性能。SDA已在多个实验中获取了较好性能。
4)正如受限玻尔兹曼机的堆叠形成深度置信网络,去噪自编码器的堆叠可形成堆叠去噪自编码器。用叠加噪声输入训练每层网络的去噪能力,这样训练出来的每层编码器可作为一个具有容错性能的特征提取器,同时学习得到的特征表 示具有更好的健壮性,这也为提高分类的准确率提供了条件。
基于人类视觉感知的图像识别方法,主要分为8个部分。具体步骤如下:
(1)原始训练图像输入
获取原始训练图像(TIF或JPG)。对于尺寸较大的原始图像,需对图像进行简单的分块操作,将一景图像分割分辨率大小为200*200的子图。
(2)应用改进后的HMAX特征模板提取方法生成特征矩阵。
输入:模块训练图片集合
参数:本方法中对经典HMAX参数设置进行部分改进。首先,Gabor滤波器的方向参数数为8个(0,π/4,π/2,3π/4,π,5π/4,,3π/2 7π/4),共16个尺度,得到128个滤波器相应。Gabor函数中高宽比设置为0.7,它决定了视觉感受野的椭圆率;Gaussian因子的标准差与波长的比值设置为0.65,这个参数决定了空间频率的带宽;角度数∈[0,2π),即本方法选取8个方向的朝向;由于8个方向的相位本身具有对称性,因此相位补偿设为0。
HMAX训练阶段模板数量为10。
输出:HMAX特征矩阵
本方法采用了SDA、SVM、DBN四种分类器来进行分类学习,以比较他们的识别分类性能。从结果来看SDA的运算性能是SVM的两倍,是DBN的125倍。采用SDA对识别客体进行训练和识别,具体步骤如下:
(3)SDA训练
输入:由上述HMAX方法得到的图像目标的特征值。使用一定数量的带标签的训练样本通过前向反馈网络进行训练,设SAE(TrainingSet,G1vAll)为训练函数,TrainingSet为测试样本集,G1vAll为类别数。具体参数如下:
SAE的层数为3层(picSize,100)
激励函数为sigma函数
SAE的迭代次数设为2;
训练批量大小为100;
学习率为1
加噪声系数为0.5
输出:经SDA训练得到的网络权值(Net Weight)
(4)初始化FFNN
用经训练得到的网络权重值(Net Weight)做为FFNN网络的初始权
层数为[picsize,100,10]
激励函数为sigma函数
迭代次数:1
批量大小:100
(5)训练FFNN
输入:应用第(2)步的训练样本HMAX特征值对FFNN网络进行训练。
输出:FFNN的训练网络值(FFNN Net Weight)。
(6)测试(验证)图像
获取原始测试(验证)图像(TIF或JPG)。对于尺寸较大的原始图像,需对图像进行简单的切割,将一景图像分割分辨率大小为200*200的子图。
(7)生成测试图像的模块训练子图集合的HMAX特征矩阵,方法同第二步。
(8)FFNN分类
输入:应用训练好的FFNN网络权值,对第七步生成的HMAX特征矩阵进行分类。
输出:得到结果[lable,Score]。lable为类别标签,Score为类别置信度。
附图说明
图1现有知识图像预处理步骤
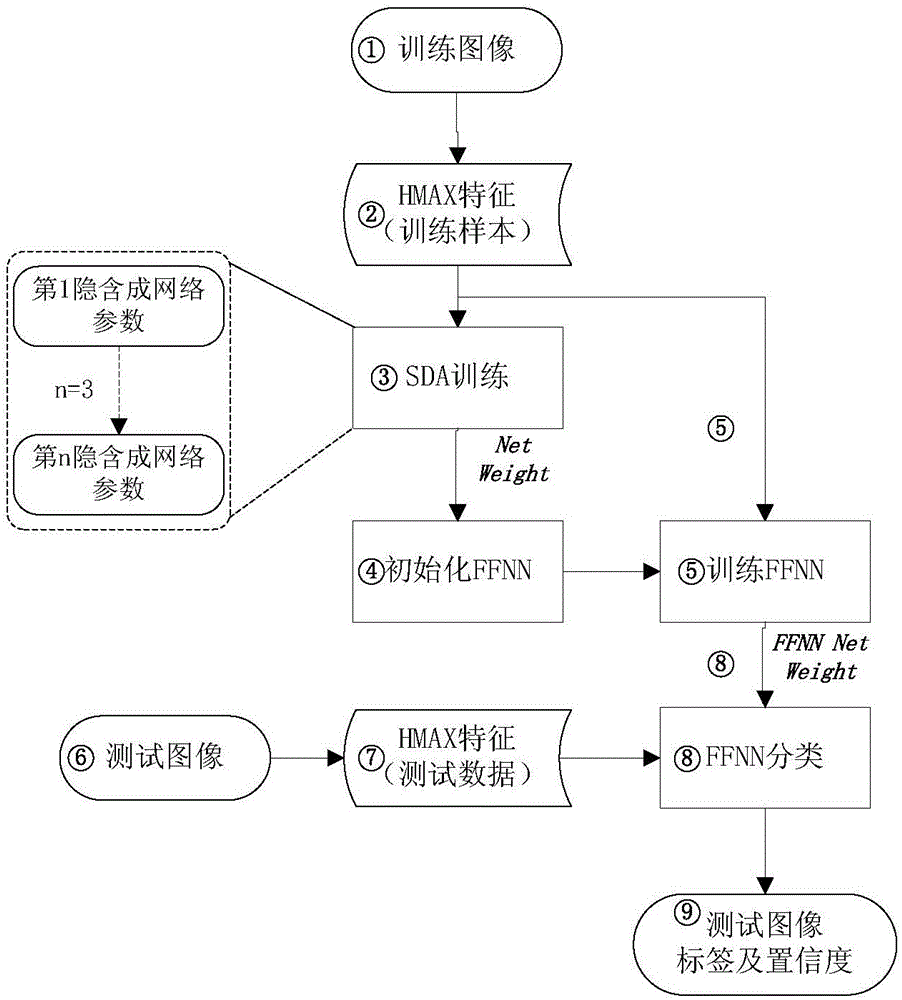
图2基于人类视觉感知的图像识别方法结构图
图3 200×200油膜样本图像
图4 200×200类油膜样本图像
图5 200×200海水样本图像
图6SAR原始图像
图7油膜位置图像
图8类油膜位置
由于SDA本身不具有分类功能,它是一个特征提取器,所以要实现分类功能还需在网络最后添加分类器,通过对比实验前向反馈神经网络的性能要高于SVM与贝叶斯分类器,而分类的准确率基本一致。因此,本方法使用前向反馈神经网络(FFNN)对图像目标进行分类。本方法中SDA使用的隐含层数量为3层。
图2展示了图像目标,背景等,训练与测试分类流程。首先将分类样本的HAMX的视觉特征值组成特征矩阵交给SDA训练得到SDA的网络模型。接着,运用SDA得到的网络参数(Net Weight)初始化FFNN网络权值,对FFNN进行训练。得到训练后的FFNN的网络参数FFNN Net Weight。然后,计算测试图像目标的HMAX特征值,使用FFNN predict函数与训练得到的FFNN Net Weight对该特征值进行判定。最后,给出该测试图像的类别标签及其置信度。
实施例:合成孔径雷达(SAR)海上溢油图像识别
海上溢油影像识别:海上溢油图像是一种形态复杂不易识别的目标。应用本文方法的分类效果超过了人类专家直接识别溢油的准确率。
图3,图4,图5所示为三类样本,既油膜,类油膜及海水。图6,图7为原始图像中油膜与类油膜的位置。首先将HAMX的视觉特征值组成特征矩阵交给SDA训练得到FFNN的网络初始权值。然后,应用三类样本像的HMAX特征值,继续训练FFNN的网络结构参数FFNNStructure。最后,应用该FFNNStructure对测试图像进行检测,得到分类结果。
表1SDA分类结果混淆矩阵,1代表类油膜,2代表油膜,3代表海水
表1中类别1代表类油膜,类别2代表油膜,类别3代表海水。从该混淆矩阵可以看出,总体分类准确率达到100%。虽然测试的样本数不多,但这个结果已经明显高于人类专家所具有的判定水平。从性能上来说SDA只需要2次迭代,分类准确率即能达到90%以上。
- 还没有人留言评论。精彩留言会获得点赞!