一种辅助择校的信息筛选方法和系统与流程
本发明属于数据筛选领域,具体涉及一种辅助择校的信息筛选方法和系统。
背景技术:
学生在高中毕业,面临升学选择时,大量的学校数目、不同的学校分数线、硬件条件、文化氛围等,大量的选择常让学生觉得无所适从,不知道如何选择一所合适自己的学校。
尤其是美国大学的择校,与中国式计划经济的高考择校颇为不同,国内的高考择校,学校以分数线划分招收对象,可以较为容易的缩小选择范围。而美国大学强调教育资源在个性化上的匹配,也强调全面地从经济人文和学术角度的综合考量。
因此,在申报学校前,一个科学的学校筛选方法可以辅助学生更方便的选择更适合自己的学校。
技术内容
本发明的目的在于提供一种辅助择校的信息筛选方法和系统,能综合考虑个体家庭偏好、学生本人学术条件、经济支付能力,更科学、客观的分配权重,考虑学生偏好的同时兼顾个人条件对录取率的影响,优化筛选结果,方便、科学的为学生提供更合适的筛选结果。
为实现上述目的,本发明采用如下技术方案:
一种辅助择校的信息筛选方法,包括:
通过预设题库答题采集学生的个人信息,获取个性化数据;
将所述采集的个人信息通过预设的评分标准,对待筛选的原始学校信息数据库中的学校进行匹配度评分;
根据获取的匹配度评分,对待筛选的原始学校信息数据库的学校进行至少两级筛选,获取筛选结果;
所述至少两级筛选包括:
初级筛选:对获取的匹配度评分集合进行排序,将匹配度评分最高的若干所学校,按照修正的全国排名排序,为初级筛选结果;
二级筛选:以采集的个性化数据中的个人能力项评分的分级为标准,对剩余的学校进行筛选,筛选出的学校与初级筛选获取的结果一并输出,为两级筛选的最终结果;
最后输出筛选结果,供学生查询。
其中,通过预设题库答题采集学生的个人信息,获取个性化数据前,还包括:采集多个不同高校在校生的个人择校偏好信息,根据所获取择校偏好信息数据建立统计数学模型,设计预设题库,统计分析评分方式和权重,构建评分标准;通过大数据测试验证,修正评分标准。
在对待筛选的原始学校信息数据库中的学校进行匹配度评分时,根据所获取的个人信息,进行绝对评分和相对评分;所述绝对评分为,根据个人信息中的排斥条件对原始学校信息数据库进行预筛,过滤原始学校信息数据库,过滤掉的学校信息不再进行评分筛选;将根据绝对评分预筛后的原始学校信息数据库作为待筛选数据库,获取其匹配度评分。
对采集的个人信息进行分类,包括个人条件、学校硬件偏好和文化偏好;所述个人条件包括家庭经济能力、个人成绩;所述学校硬件偏好包括学校运营模式、学校类型、地理位置、经济区域、人数;所述文化偏好包括男女比例、国际学生比例。
所述初级筛选中,修正的全国排名为,如果有全国学校的统一排名,则将统一排名作为修正后的全国排名,作为初级筛选的依据;如果没有全国学校的统一排名,则依据学校的地方排名和综合评分,设计转换因子,将地方排名统一为全国排名,作为修正后的全国排名。
所述初级筛选和二级筛选的结果分别分为三类,分别为:理想类、核心类和保底类。所述理想类为高匹配度学校中,修正后全国排名最高的若干所学校;所述核心类为高匹配度学校中,修正后全国排名中游的若干所学校;所述保底类为高匹配度学校中,修正后全国排名最低的若干所学校。
所述二级筛选中,以采集的个性化数据中的个人能力项评分的分级为标准,所述个人能力项包括至少一项;将所述各项个人能力项的评分根据符合的项数,将总分分类汇总,获取不同的数值结果,设计若干个数值区间,作为次级筛选最终结果的分类标准。
所述二级筛选中,根据所述个人能力项总分落入的数值区间,修正理想类学校、核心类学校和保底类学校的数目,将筛选出的理想类学校,核心类学校,保底类学校和初级筛选中的理想类学校、核心类学校和保底类学校合并,按照修正后的全国排名顺序输出,作为最终筛选结果,供学生查询。
作为本发明的另一目的,本发明还提供了一种辅助择校的信息筛选系统。
为实现上述技术目的,本发明采用如下技术方案:
一种辅助择校的信息筛选系统,包括:
终端和服务器;
所述终端包括数据采集单元、输出单元和终端通讯单元;数据采集单元用于采集学生个人数据;输出单元用于输出筛选结果;终端通讯单元用于和服务器通讯;
所述服务器包括存储单元、数据处理单元和服务器通讯单元;所述存储单元存储预设题库和实时更新的学校数据;服务器通讯单元用于和终端通讯;
所述数据处理单元包括评分模块和筛选模块,评分模块中设置预设的评分标准,用于对采集的个人信息进行处理,将采集的个人信息转化为学校评分;所述筛选模块根据个人数据和学校评分进行排名筛选,并向输出单元输出显示筛选结果供学生查询。
所述筛选模块包括至少两级筛选,输出筛选结果;
所述至少两级筛选包括:
初级筛选:对获取的匹配度评分集合进行排序,将匹配度评分最高的若干所学校,按照修正的全国排名排序,为初级筛选结果;
二级筛选:以采集的个性化数据中的个人能力项评分的分级为标准,对剩余的学校进行筛选,筛选出的学校与初级筛选获取的结果一并输出,为两级筛选的最终结果。
所述初级筛选中,修正的全国排名为,如果有全国学校的统一排名,则将统一排名作为修正后的全国排名,作为初级筛选的依据;如果没有全国学校的统一排名,则依据学校的地方排名和综合评分,设计转换因子,将地方排名统一为全国排名,作为修正后的全国排名。
所述初级筛选和二级筛选的结果分别分为三类,分别为:理想类、核心类和保底类;所述理想类为高匹配度学校中,修正后全国排名最高的若干所学校;所述核心类为高匹配度学校中,修正后全国排名中游的若干所学校;所述保底类为高匹配度学校中,修正后全国排名最低的若干所学校。
所述二级筛选中,以采集的个性化数据中的个人能力项评分的分级为标准,所述个人能力项包括至少一项;将所述各项个人能力项的评分根据符合的项数,将总分分类汇总,获取不同的数值结果,设计若干个数值区间,作为次级筛选最终结果的分类标准;
所述二级筛选中,根据所述个人能力项总分落入的数值区间,修正理想类学校,核心类学校,保底类学校的数目,将筛选出的理想类学校、核心类学校和保底类学校和初级筛选中的理想类学校、核心类学校和保底类学校合并,按照修正后的全国排名顺序输出,作为最终筛选结果,供学生查询。
作为本发明的又一目的,本发明还提供了一种辅助择校的信息筛选服务器。
为实现上述技术目的,本发明采用如下技术方案:
一种辅助择校的信息筛选服务器,其特征在于,包括:
服务器通讯单元,用于和终端通讯连接;
存储单元,存储预设题库和实时更新的学校数据;
数据处理单元,用于处理通过服务器通讯单元从终端获取的个人信息数据;所述数据处理单元包括评分模块和筛选模块,评分模块中设置预设的评分标准,用于对服务器通讯单元从终端获取的个人信息数据进行处理,将个人信息数据转化为学校评分;所述筛选模块根据个人信息数据和学校评分进行排名筛选,并向通过服务器通讯单元向终端输出显示筛选结果供学生查询。
所述筛选模块包括至少两级筛选,输出筛选结果;
所述至少两级筛选包括:
初级筛选:对获取的匹配度评分集合进行排序,将匹配度评分最高的若干所学校,按照修正的全国排名排序,为初级筛选结果;
二级筛选:以采集的个性化数据中的个人能力项评分的分级为标准,对剩余的学校进行筛选,筛选出的学校与初级筛选获取的结果一并输出,为两级筛选的最终结果。
本发明的技术方案具有如下技术效果:
(1)综合考虑个体家庭偏好、学生本人学术条件、经济支付能力,更科学、客观的分配权重,考虑学生偏好的同时兼顾个人条件对录取率的影响,优化筛选结果,快速、方便、科学的为学生提供更合适的筛选结果;
(2)考虑文化因素和家庭因素的影响,采集的个人数据更全面,获取的筛选结果更周全,更人性化;
(3)在评分标准中设置绝对评分和相对评分,用绝对评分预筛选过滤数据库,降低运算量;用相对评分模拟择校过程的智能化,克服一般的搜索漏斗式择校方式中模糊匹配,增强筛选结果的合理性;
(4)采用大数据测试验证,调整评分标准,优化筛选结果,最大限度的减少人为因素的干扰,实现筛选的智能化。
附图说明
图1为本发明信息筛选方法的流程框图。
图2为本发明信息筛选系统结构框图。
图3为本发明信息筛选服务器结构框图。
具体实施方式
下面结合附图说明和具体实施方式对本发明的技术方案做进一步描述。应当理解,所述具体实施例仅用于解释本发明,而不应当理解为对本发明的限定。
实施例1
如图1所示,本发明信息筛选方法的流程包括:
步骤S101:通过预设题库答题采集学生的个人信息;
即通过采集学生个人信息,获取个性化数据。
步骤S102:将所述采集的个人信息通过预设的评分标准,对待筛选的原始学校信息数据库中的学校进行匹配度评分。
步骤S103:根据获取的匹配度评分,对待筛选的原始学校信息数据库的学校进行至少两级筛选,获取筛选结果;
其中,本实施例采用初级筛选和二级筛选(精筛)进行两级筛选,获取筛选结果;
初级筛选:对获取的匹配度评分集合进行排序,将匹配度评分最高的若干所学校,按照修正的全国排名排序,为初级筛选结果;
初级筛选中,修正的全国排名为,如果有全国学校的统一排名,则将统一排名作为修正后的全国排名,作为初级筛选的依据;如果没有全国学校的统一排名,则依据学校的地方排名和综合评分,设计转换因子,将地方排名统一为全国排名,作为修正后的全国排名。将根据初级筛选获取的结果分为理想类、核心类和保底类三类学校,理想类为高匹配度学校中,修正后全国排名最高的若干所学校;核心类为高匹配度学校中,修正后全国排名中游的若干所学校;保底类为高匹配度学校中,修正后全国排名最低的若干所学校。
二级筛选:以采集的个性化数据中的个人能力项评分的分级为标准,对剩余的学校进行筛选,筛选出的学校与初级筛选获取的结果一并输出,为筛选的最终结果。
二级筛选中,以采集的个性化数据中的个人能力项评分的分级为标准,如:以中国的加分标准为例,个人能力项可包括体育特长、艺术特长、竞赛等级等,每有一个个人能力项加1分;将所述各项个人能力项的评分根据符合的项数,将总分分类汇总,获取不同的数值结果,设计若干个数值区间,作为次级筛选最终结果的分类标准,即有4个个人能力项,每个1分,分为0~1分,1~2分,2~3分,3~4分四个区间,根据所述个人能力项总分落入的数值区间,修正理想类学校、核心类学校和保底类学校的数目,即:个人能力项分高的时候,学生被录取的可能性增加,则提高理想类、核心类学校的数目,减少保底类学校的数目。
最后将筛选出的理想类学校,核心类学校,保底类学校和初级筛选中的理想类学校、核心类学校和保底类学校合并,按照修正后的全国排名顺序输出,作为最终筛选结果,供学生查询。
步骤S104:输出筛选结果。
本实施例中预设题库和评分标准的确定方式为:采集多个不同高校在校生的个人择校偏好信息,根据所获取择校偏好信息数据建立统计数学模型,设计预设题库,统计分析评分方式和权重,构建评分标准;通过大数据测试验证,修正评分标准。
首先确定需要采集的学生信息样本组,比如,随机选择多个学校入校新生作为采集样本组,所述样本应当有足够大的样本容量,并具有代表性。收集样本组中学生的个性化数据、实际学校,对学校的满意度信息,建立数据库模型,对数学建模进行统计分析,设计预设题库,统计分析评分方式和权重,构建评分标准。其中个性化数据包括,学生个人条件和择校偏好(包括学校的硬件条件和人文条件)。预构建评分标准后,利用大数据验证评分标准,并进行修正。
为简化筛选流程,降低筛选的运算量,在对待筛选的原始学校信息数据库中的学校进行匹配度评分时,根据所获取的个人信息,进行绝对评分和相对评分;所述绝对评分为,根据个人信息中的排斥条件对原始学校信息数据库进行预筛,过滤原始学校信息数据库,即:将题库中的题分为非加权选择题和加权选择题,或选择题的评分标准中包括加权项和不加权项,即,对于不进入评分加权的选项,针对题目的答案,直接删除学校信息数据库中的部分学校,不再进行评分筛选。如:在题目中设置地域选择,列举出各大省,学生在学校的地域选择中,仅选择了部分省,则直接删除数据库中其余省份的学校,缩小筛选范围。
所述相对评分为,影响加权的评分,对各个选项进行匹配度评分。比如:根据各学校硬件条件的不同(如学费),从个人数据中获取学生对学费的承担上限,例如为3000元。但当某个学校学费为3010元时,不将学校从数据库中排除,而且是差异化地对待,即:在支付这个纬度上,两所学校的匹配程度有所不同,则根据各个问题的权重来判断这两所学校的吸引力匹配度。
原始数据库中的学校信息根据绝对评分进行预筛选,过滤掉的学校信息不再进行评分筛选;预筛后的原始学校信息数据库作为待筛选数据库,获取其匹配度评分。
本实施例中,对采集的个人信息进行分类,包括个人条件、学校硬件偏好和文化偏好;所述个人条件包括家庭经济能力、个人成绩;所述学校硬件偏好包括学校运营模式、学校类型、地理位置、经济区域、人数;所述文化偏好包括男女比例、国际学生比例。采集的各类个人信息均对应有相应的题目和评分标准、权重。
实施例2
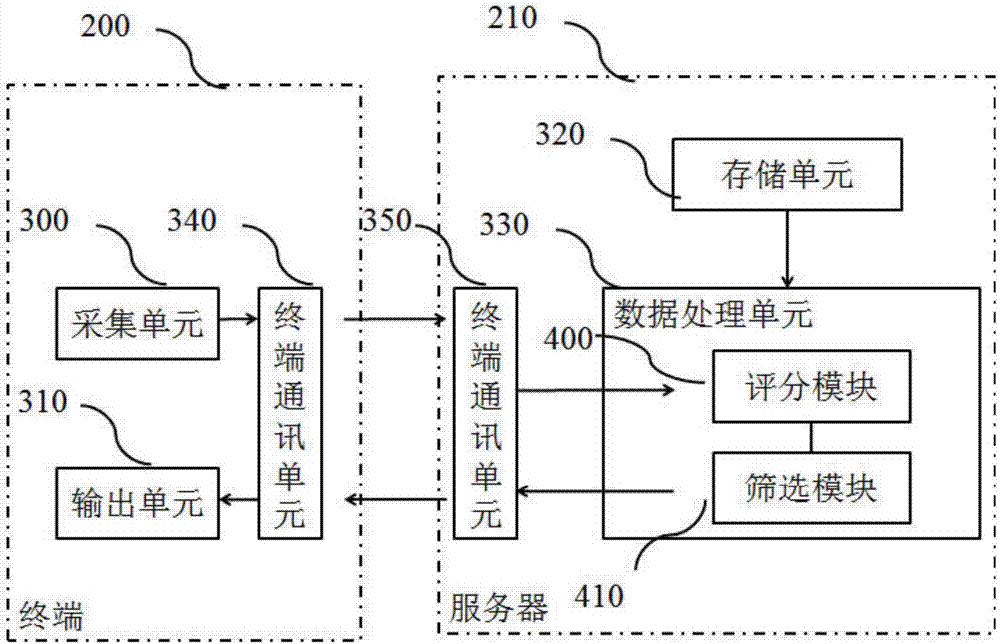
如图2所示为本发明信息筛选系统的框图,包括:终端200和服务器210;
所述终端200包括数据采集单元300、输出单元310和终端通讯单元340;数据采集单元300用于采集学生个人数据;输出单元310用于输出筛选结果;终端通讯单元340;用于和服务器210通讯;
所述服务器210包括存储单元320、数据处理单元330和服务器通讯单元350;所述存储单元320存储预设题库和实时更新的学校数据;所述服务器通讯单元350用于和终端200通讯;
所述数据处理单元330包括评分模块400和筛选模块410,评分模块400中设置预设的评分标准,用于对采集的个人信息进行处理,将采集的个人信息转化为学校评分;所述筛选模块410根据个人数据和学校评分进行排名筛选,并向输出单元输出显示筛选结果供学生查询。
所述预设的评分标准设定方法为:采集多个不同高校在校生的个人择校偏好信息,根据所获取择校偏好信息数据建立统计数学模型,设计预设题库,统计分析评分方式和权重,构建评分标准;通过大数据测试验证,修正评分标准。
对采集的个人信息进行处理,对存储单元320中的原始学校信息数据库进行匹配度评分时,根据所获取的个人信息,进行绝对评分和相对评分;所述绝对评分为,根据个人信息中的排斥条件对原始学校信息数据库进行预筛,过滤原始学校信息数据库,过滤掉的学校信息不再进行评分筛选;将根据绝对评分预筛后的原始学校信息数据库作为待筛选数据库,获取其匹配度评分。
对采集的个人信息进行分类,包括个人条件、学校硬件偏好和文化偏好;所述个人条件包括家庭经济能力、个人成绩;所述学校硬件偏好包括学校运营模式、学校类型、地理位置、经济区域、人数;所述文化偏好包括男女比例、国际学生比例。
所述筛选模块410包括至少两级筛选,输出筛选结果;
所述至少两级筛选包括:
初级筛选:对获取的匹配度评分集合进行排序,将匹配度评分最高的若干所学校,按照修正的全国排名排序,为初级筛选结果;
二级筛选:以采集的个性化数据中的个人能力项评分的分级为标准,对剩余的学校进行筛选,筛选出的学校与初级筛选获取的结果一并输出,为两级筛选的最终结果。
所述初级筛选中,修正的全国排名为,如果有全国学校的统一排名,则将统一排名作为修正后的全国排名,作为初级筛选的依据;
如果没有全国学校的统一排名,则依据学校的地方排名和综合评分,设计转换因子,将地方排名统一为全国排名,作为修正后的全国排名。
所述初级筛选和二级筛选的结果分别分为三类,分别为:理想类、核心类和保底类;所述理想类为高匹配度学校中,修正后全国排名最高的若干所学校;所述核心类为高匹配度学校中,修正后全国排名中游的若干所学校;所述保底类为高匹配度学校中,修正后全国排名最低的若干所学校。
所述二级筛选中,以采集的个性化数据中的个人能力项评分的分级为标准,所述个人能力项包括至少一项;
将所述各项个人能力项的评分根据符合的项数,将总分分类汇总,获取不同的数值结果,设计若干个数值区间,作为次级筛选最终结果的分类标准;
所述二级筛选中,根据所述个人能力项总分落入的数值区间,修正理想类学校,核心类学校,保底类学校的数目,将筛选出的理想类学校、核心类学校和保底类学校和初级筛选中的理想类学校、核心类学校和保底类学校合并,按照修正后的全国排名顺序列出,从输出单元310输出,作为最终筛选结果,供学生查询。
实施例3
如图3所示为本发明信息筛选服务器的框图,
包括:服务器通讯单元350,用于和终端通讯连接;
存储单元320,用于存储预设题库和实时更新的学校数据;
数据处理单元330,用于处理通过服务器通讯单元350从终端获取的个人信息数据;所述数据处理单元330包括评分模块400和筛选模块410,评分模块400中设置预设的评分标准,用于对服务器通讯单元350从终端获取的个人信息数据进行处理,将个人信息数据转化为学校评分;所述筛选模块410根据个人信息数据和学校评分进行排名筛选,并向通过服务器通讯单元350向终端输出显示筛选结果供学生查询。
所述预设的评分标准设定方法为:采集多个不同高校在校生的个人择校偏好信息,根据所获取择校偏好信息数据建立统计数学模型,设计预设题库,统计分析评分方式和权重,构建评分标准;通过大数据测试验证,修正评分标准。
通过服务器通讯单元350从终端获取个人信息,对所述个人信息进行处理,对存储单元320中的原始学校信息数据库进行匹配度评分时,根据从终端获取的个人信息,进行绝对评分和相对评分;所述绝对评分为,根据个人信息中的排斥条件对原始学校信息数据库进行预筛,过滤原始学校信息数据库,过滤掉的学校信息不再进行评分筛选;将根据绝对评分预筛后的原始学校信息数据库作为待筛选数据库,获取其匹配度评分。
通过服务器通讯单元350从终端获取的个人信息进行分类,包括个人条件、学校硬件偏好和文化偏好;所述个人条件包括家庭经济能力、个人成绩;所述学校硬件偏好包括学校运营模式、学校类型、地理位置、经济区域、人数;所述文化偏好包括男女比例、国际学生比例。
所述筛选模块410包括至少两级筛选,输出筛选结果;
所述至少两级筛选包括:
初级筛选:对获取的匹配度评分集合进行排序,将匹配度评分最高的若干所学校,按照修正的全国排名排序,为初级筛选结果;
二级筛选:以采集的个性化数据中的个人能力项评分的分级为标准,对剩余的学校进行筛选,筛选出的学校与初级筛选获取的结果一并通过通讯单元350输出到终端,为两级筛选的最终结果。
实施例4
本实施例以一套完善的美国学校择校方法流程为例,对本发明的方法进行进一步描述。
步骤1:通过预设题库答题采集学生的个人信息;
预设题库和评分标准的确定方式为:采集多个不同高校在校生的个人择校偏好信息,根据所获取择校偏好信息数据建立统计数学模型,设计预设题库,统计分析评分方式和权重,构建评分标准;通过大数据测试验证,修正评分标准。
其学校数据来源为open door policy 公开的官方数据,较为完整地涵盖了美国的四类大学,包括全国性大学、文理学院、地区性大学和地区性文理学院。
本实施例的择校预设题库包括20个题目,每个题目设置不同的评分算法和加权标准。通过20个题目所采集的个人信息包括个人条件、学校硬件偏好和文化偏好;
其中学校硬件偏好项用6题,采集的学校硬件偏好信息包括:学校运营模式(包括公立和私立)、学校类型(包括全国性大学、文理学院、地区性大学和地区性文理学院)、地理位置(包括东、南、西、北)、经济区域(包括城、乡、镇、村)、所处州和人数(自行设置上下限);
其中,所处州项设置为绝对评分题,即:对未选择的州,直接删除数据库中所有地理位置位于未选择的州的学校;
学校类型项设为包括绝对评分的选项,将对每类学校根据意向打分,共分六个分数级0~5,分数越高,愿意去的意向越大。对于选择了0分选项的学校类型,直接将此类型下属的学校从数据库中删除。
个人条件项用8题,包括预估或实际的ACT/SAT标化考试的成绩、学校录取率偏好、学费、平均GPA、学院偏好、TOEFL最低分、早申意向、个人能力(特殊荣誉)。
其中,在学院偏好中,对每个学院按照意向打分,共分五个分数级1~5,分数越高,愿意去的意向越大。对于选择了5分选项的学院类型,删除数据库中未设有该学院的学校。
对于TOEFL最低分,有些学校设有TOEFL的最低录取分数线,低于这个分数的国际生不被录取。对于设有最低分数线的学校,如果学生答题所选分数低于该学校分数线,则将该学校从数据库中移除。
文化偏好6题,包括教室人数、学习风格、男女比例、国际学生比例、亚裔比例、犯罪率。
随着美国的各种犯罪率的增加,家长们越来越在意安全性,根据美国教育部公开的校园案件的数据,设计安全性方面的择校步骤。
步骤2:将所述采集的个人信息通过预设的评分标准,对待筛选的原始学校信息数据库中的学校进行匹配度评分。
步骤3:根据获取的匹配度评分,对待筛选的原始学校信息数据库的学校进行两级筛选,获取筛选结果;
初级筛选:对于有早申意向的学生,在匹配度评分最高的40所学校中,按照匹配度评分排名从高到低,在其中排名前20的学校中,排名从高到低挑出第一所有早申截止日期的学校。如果还没有扩大到最匹配的所学校,按照排名从高到低,在其中排名前40的学校中,排名从高到低挑出第一所有早申截止日期的学校。如果没有,不再输出早申学校,进入正常初级筛选流程。
选择8所学校。对获取的匹配度评分集合进行排序,将匹配度评分最高1~8名学校,按照修正的US news排名排序从高到低输出,为初级筛选结果;
对US news提供的分类排名,全国性大学、文理学院、地区性大学和地区性文理学院四项排名,根据学校的综合评分,设计转换因子,将分类排名统一为全国排名,作为修正后的US news全国排名。
初筛的8所学校按照排名顺序,从高到低选择为2所理想类学校、4所核心类学校和2所保底类学校。平衡匹配度以及排名,保证申请者拿到至少一个录取的几率。
二级筛选:以采集的个性化数据中的个人能力项评分的分级为标准,对剩余的学校进行筛选,筛选出的学校与初级筛选获取的结果一并输出,为筛选的最终结果。
对于美国学校,考虑名人推荐,个人素质加分等地方特点的存在,选择特殊荣誉项作为二级筛选的评分标准,所述特殊荣誉包括:多门荣誉课或AP课程并成绩优秀(0.5分)、获得全国竞赛奖项(0.5分)、获得过国际竞赛奖项(1.5分)、有超过500小时以上公益活动或对社区他人有杰出贡献(0.5分)。累计总分。
特殊荣誉项得分高,意味着被录取的概率增加,可以增加学校的选择范围,调整增加理想、核心类学校的数目。
如:对于特殊荣誉项总分≥2.5分,从除去初筛获取的8个学校名额,剩余学校中按照匹配度评分高低获取前292个学校;两级筛选最终筛选出11个理想类学校、6个核心类学校和3个保底类学校;
对于特殊荣誉项总分2分或1.5分,从除去初筛获取的8个学校名额,剩余学校中按照匹配度评分高低获取前192个学校;两级筛选最终筛选出10个理想类学校、7个核心类学校和3个保底类学校;
对于特殊荣誉项总分1分或0.5分,从除去初筛获取的8个学校名额,剩余学校中按照匹配度评分高低获取前142个学校;两级筛选最终筛选出8个理想类学校、8个核心类学校和4个保底类学校;
对于特殊荣誉项总分0分,从除去初筛获取的8个学校名额,剩余学校中按照匹配度评分高低获取前92个学校;两级筛选最终筛选出5个理想类学校、10个核心类学校和5个保底类学校;
以特殊荣誉项总分0分为例,两级筛选最终筛选出5个理想类学校、10个核心类学校和5个保底类学校,除去初筛的2所理想类学校、4所核心类学校和2所保底类学校,二级筛选需要再取3所理想类学校、6所核心类学校和3所保底类学校。
从除去初筛获取的8个学校名额,剩余学校中按照匹配度评分高低获取前92个学校A1~A92,对应修正后US news排名为r1~r92,设y为排名中间值,即学校A46对应的US news排名,设计距离参考量,计算公式如下:
第一步:在A1~A92中分数由高到低依次查找Ai(1≤i≤92),如果,则保留Ai学校,共保留3个Ai,即3个理想类学校;
第二步:在剩下的89所学校中,如果,则保留Ai学校,共保留6个Ai,即6个核心类学校。
第三步:在剩下的83所学校中,如果,则保留Ai学校,共保留3个Ai,即3个保底类学校。
最后将筛选出的理想类学校,核心类学校,保底类学校和初级筛选中的理想类学校、核心类学校和保底类学校合并,按照修正后的US news排名顺序输出,作为最终筛选结果,供学生查询。
步骤4:输出筛选结果。
- 还没有人留言评论。精彩留言会获得点赞!