一种基于激活力模型的图片中文本识别纠错方法与流程
本发明利用概率统计以及数据挖掘,构建激活力词典,结合贝叶斯理论解决图片中文本识别出现的识别错误问题。
背景技术:
图片识别在智能识别领域具有相当重要的意义,随着社会的不断发展各种信息急剧膨胀,图片因其便捷性且不易篡改性成为十分通用的信息保存手段,在此背景下,图片中的文字识别显得格外重要。
目前虽然已经存在大量的图片文字识别方法,例如传统的OCR技术或者现在流行的各种深度学习衍生识别方法,这些方法都需要的高识别率都建立在高分辨的基础上,但总是存在大量分辨率不高的图片文本需要进行识别,而对于这些分辨率不高的PDF图片或者模糊的相机照片,已存在的方法都不能保证对整个文档的完全识别正确,而对于大段的文档如果使用人工校正无疑会耗费大量的人力物力。现存的方法都注重对汉字字形的识别,而忽略了汉字的联系关系,即汉字只有通过一定的排列顺序才能构成可供人理解的语句,而对于需进行文字识别的绝大部分文档无疑都是具有连贯语义的;除此之外,由于汉字特有的文字结构,只要图片的清晰程度达到一定的要求,总有一部分简单文字可以被准确的识别出来。通过上述两个特点,我们就可以利用汉字间的相互关联关系对识别相似度不高的部分文字进行再选择。
技术实现要素:
针对现有图片文字识别技术存在部分文字识别错误的问题,本发明的目的是提供一种文字识别纠错技术对识别相似度较低的文字进行自动再识别处理,最大限度的减少图片文本的识别错误问题。
为达到上述目的,本发明提出的文字识别自动纠错方法包括以下步骤:
字典构建步骤:构建激活力字典,旨在挖掘汉字间的潜在语义关系,进而获得汉字间的相互影响关系,从而获得各个汉字前方以及后方可能出现的其他汉字;
不确定字纠正步骤:使用通用方法获取识别出的字符以及对应的识别相似度,若其中存在某一字符的相似度高于某一θ值的,认为其对应的字符为正确识别结果;若不存在,则将这些字符以及相似度作为参考先验概率,利用步骤一中构建的字典并结合贝叶斯公式筛选出最佳字。
字典构建步骤中,对选定字进行建模,此步骤具体过程如下:
1)、利用汉语语料库获取包含选定字的语料数据,并定义分隔符,将所有标点符号都设定为分隔符;
2)、统计用于建立词典的字i在语料库中的出现频率fi;
3)、统计任意两个距离小于等于ε的字i和j(区分先后)共同出现的频率fij并记录所有的距离出现的次数dijk(1≤k≤ε),并计算出这两个字i和j共同出现的平均距离dij,计算公式定义如下
值得说明的是,如果在规定距离内出现分割符,则此时不对分隔符两端的字统计共现频率。
4)、根据前面三个步骤获取的数据计算出任意两个字i和j之间的激活力afij
5)、设定阈值t,将第4)所得的激活力数据中低于t的数据全部滤除,将选定字i对应的afxi和afix取出并按大小顺序排序作为i前面(afxi)和后面(afix)最可能出现的字x。值得说明的是,由于已经滤除了一部分数据,当i影响字不存在时,以空值表示。
不确定字纠正步骤,此步骤的具体过程如下:
1)、假定已经通过通用方法获取了字符i的识别结果wi和对应的相似度λi,其中wi=[wi1,wi2,…,win]T,wix为识别出的可能的字符,λi=[λi1,λi2,…,λin]T,λix为对应的相似度。当存在λix大于θ时,认为wix即为正确识别结果;当不存在时,首先滤除λix小于对应的字符,将剩下的作为候选字符。
2)、对于一段待识别文字,必然存在某些字符可认为识别正确,则可以以这些字符为中心进行扩散识别。对于不满足相似度条件的字符i,将上一步处理后的w′i=[wi1,wi2,…,wim]T作为字符i候选识别结果,对于前后都存在已确定相邻字的字符i的候选识别字wij的后验概率ηij可以定义如下
其中,A为字符i前面的相邻字,B为字符i后面的相邻字,α为平滑因子,同理,对于只存在一边相邻字的后验概率ηij可以定义为
ηij=lg(afAwij+1)或者ηij=lg(afwijB+1)
利用贝叶斯公式
则选择最大的ψij作为字符i的识别结果,即
本发明的有益效果在于,相对于现有文字识别技术而言,本发明挖掘文字之间的语义关系,在一般图片文字识别的基础上,利用文字相关性并结合贝叶斯理论得出更为精准可靠的识别结果,具有很大的实用价值。
附图说明
图1为本发明一种基于图片文本识别的纠错方法的步骤流程图;
图2为构建字典的步骤流程图;
图3为不确定字纠正的步骤流程图。
具体实施方式
下面将结合附图对本发明具体实施方式进行详细说明。
图1是本发明的流程图,包括以下步骤:
步骤S1:构建字典步骤;
步骤S2:基于获取的一般识别结果并结合字典获取最佳识别结果步骤。
下面将对每个步骤进行具体的说明:
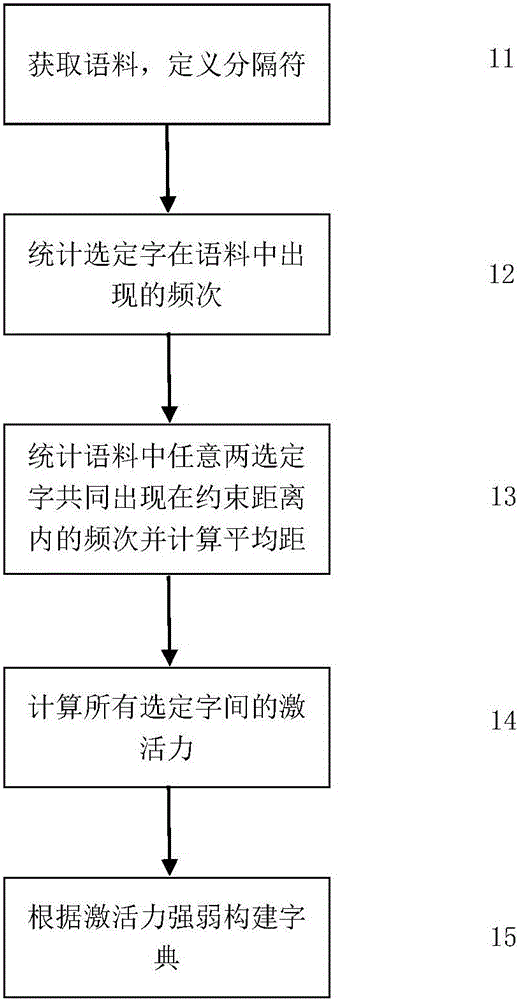
步骤S1挖掘汉字之间的关联关系,根据此关系的强烈程度构建字典。图2给出了该方法的具体实施流程:
1)、步骤11中,对选定字(如选定《现代汉语常用字表》中的约3500常用字)进行建模,利用汉语语料库(如CCL)获取海量的语料数据,并将所有标点符号都定义为分隔符;
2)、步骤12中,根据步骤11获取的大量语料数据,将《现代汉语常用字表》中的约3500常用字作为字典对象,统计字i出现的频次fi;
3)、步骤13中,统计任意两个距离小于等于ε(一般来说ε取5)的字i和j(区分先后)共同出现的频率fij并记录所有的距离出现的次数dijk(1≤k≤ε),若i和j之间出现分隔符则不计入统计,并计算出这两个字i和j共同出现的平均距离dij,dij的计算公式定义如下:
4)、步骤14中,计算字典中所有字之间的激活力,对于任意两字i和j的激活力afij定义如下:
5)、步骤15中,设定阈值t(一般来说t取值10-5),将步骤14所得的激活力数据中低于t的数据全部滤除,将选定字i对应的afxi和afix取出并按大小顺序排序作为i前面(afxi)和后面(afix)最可能出现的字x。这样便构成一个完整的激活力字典。
步骤S2,以普通识别方法获取的识别字和相似度为基础,结合步骤S1中构建的字典获得最佳识别结果。图3给出了该方法的具体实施流程:
1)、输入:
a)通用识别方法(如OCR等)获取的某一字符i的识别候选字集合wi和对应的相似度集合λi,wi=[wi1,wi2,…,win]T,λi=[λi1,λi2,…,λin]T;
2)、步骤21中,首先判断λi是否存在大于θ(θ一般取0.8)的值,如果存在某一λij满足条件,则其对应的wij即可以被认为是对字符i的正确识别结果;如果不存在满足这一条件的值,则将wi作为候选字集合,同时将λi中低于(一般取0.1)的值对应的候选字在集合中去除;
3)步骤22中,由于是对一段文本的识别,所以假定至少存在一部分字符识别相似度达到θ是完全合理的,所以对于待识别的字符i,若此字符的前后相邻字都是已确定识别准确的字符A和B(假定A在前,B在后),则对于某一候选字wij的后验概率定义ηij为
其中,α为平滑因子(一般取值10-6)。对于只存在一边的相邻字被确定情况的后验概率ηij可以定义为
ηij=lg(afAwij+1)或者ηij=lg(afwijB+1)
此时,利用贝叶斯公式
最大的ψij可以认定作为字符i的识别结果,即
以上结合附图对所提出的一种基于图片文本识别的纠错方法及各模块的具体实施方式进行了阐述。通过以上实施方式的描述,所属领域的一般技术人员可以清楚的了解到本发明可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件实现,但前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以计算机软件产品的形式体现,该软件产品存储在一个存储介质中,包括若干指令用以使得一台或多台计算机设备执行本发明各个实施例所述的方法。
依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
以上所述的本发明实施方式,并不构成对发明保护范围的限定。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!