基于Pitman‑Yor过程的新闻热点发现方法与流程
本发明涉及计算机技术领域,尤其是一种基于Pitman-Yor过程的新闻热点发现方法。
背景技术:
大多数分类算法与少部分聚类算法都只是对数据层干预,例如采用欠采样或是过采样等方法。另一个,多数聚类算法面临的问题是:类簇个数是提前假设的。实际上,现实中很难设定具体的类簇个数。
如今,在热点发现这个领域,已有国内外一些大学或科研机构对网络舆情热点发现进行了大量的研究,也相应的取得丰硕的结果。其中以美国的TDT(Topic Detection and Tracking)研究项目最为引人关注。这个项目可以实现从数据流中归纳重要信息。在国内,研究比较晚,但也有引起了大量机构在这方向的关注,比如方正公司、人民日报系统等,但他们关注的侧重点略有不同。但大都都是从热点个数是假定的角度出发,对热点进行挖掘,而不能处理好热点个数随着数据集的增加而增加的情况;其二,没有考虑到真实的数据集是存在极端不平衡的,特别是对于这种新的热点类别,往往相对于已存在的类别是个极小类别,所以给新热点的识别带来了更大的困难。
技术实现要素:
本发明所要解决的技术问题是:提供一种基于Pitman-Yor过程的新闻热点发现方法,它能快速、准确的发现网络环境中所关注的新闻热点,避免了在无监督聚类分析问题中,对存在高度不平衡数据集的文本数据下,对极小类簇的低效识别问题。
本发明是这样实现的:基于Pitman-Yor过程的新闻热点发现方法,包括如下步骤:
1)根据从互联网中抓取新闻文本原始数据集,利用数据预处理工具处理抓取到的原始数据集,去除不在正常值内的文档背景词项,该正常值的范围为1≤词频≤5000,统计文本中出现的每个词项次数,最终生成相应的词汇字典和合成一个含有全部数据的语料库数据矩阵;
2)根据词汇字典和合成的语料库数据矩阵,对语料库的数据矩阵进行初始化,即每个文本为一个类簇,则初始的类簇个数为N;
3)利用基于PYP模型的新闻热点发现聚类算法,则聚类分析的类簇个数为[1,N];
4)对聚类分析结果采用NMI聚类评价方法进行评估结果;若NMI接近于1,则是本文需要的实验结果;此时得到聚类结果中的极小类簇,就是发现的新闻热点。
所述的数据预处理工具为分词器。
步骤3)中所述的聚类处理的算法为:基于PYP模型改进的、折扣参数取值从数据中自动学习的非参数贝叶斯模型。
所述的聚类算法为:,初始化,每个文本为一个类簇;
2)随机选取其中一个文本进行采样,剩余的N-1篇作为观察量;计算这个文本在已存在的K个类簇中分布概率和分配为新类簇K+1的分布概率,进一步找出K+1中分布概率最大的类簇,最后计算出最大类簇与剩下K个类簇的文本数的比值;
3)依据上一步的比值对相应类簇的大小进行惩罚,获得这个文本分配到K+1类簇的最终生成概率;
4)同理对剩下的文本,重复2)、3)两步骤,直至全部样本采样完成,最后计算全部更新后的语料库的目标函数,以判断是否可以收敛;
5)在5000次之内进行迭代之后,输出目标函数达到最优的聚类分析结果。
所述的步骤1)的数据矩阵中,数据样本集的两个类别所含样本数量的不平衡比为1:1、10:1、100:1、1000:1实验组。
与现有技术相比,本发明基于现有技术存在的技术难点,首先选取去了非参数贝叶斯模型,解决热点个数需要人为假定的问题;然后基于Pitman-Yor Process模型的改进,克服基础模型的“富人越富”问题,从而解决真实的数据集不平衡下的热点识别问题。最终达到高效地识别出新闻热点和相关的热点爆发预测。首先,本发明可以自动从新闻数据集中自动挖掘热点个数,而不需要人为的设定吗,也就是新闻热点的个数随着随着数据集大小而变化;然后,在现实的新闻数据集中,一个新的热点往往是处于新闻样本个数少量的类别中,另一方面,大多数已存在的、过时的新闻主题的类别的样本个数巨大,从而造成新热点的样本难以有效的识别出来。所以,本发明的另一个贡献在于新热点可以从这种极端不平衡的数据集中识别出新的热点样本。最终实现了新闻热点在这种真实存在的数据分布情况下的有效识别。
附图说明
图1为本发明本发明的新闻热点发现流程图;
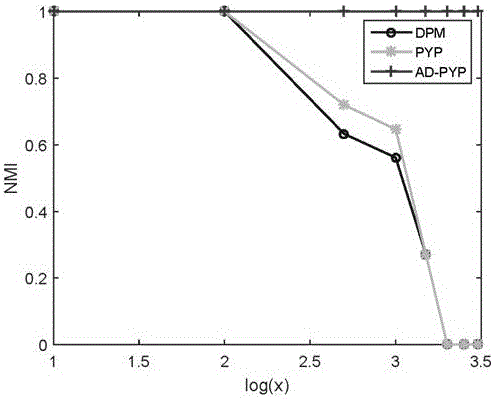
图2为本发明的方案与现有技术的方案具体实验效果的NMI对比图;
图3为本发明的方案与现有技术的方案的类别个数在聚类过程中的迭代图。
具体实施方式
本发明的实施例1:基于Pitman-Yor过程的新闻热点发现方法:包括如下步骤:
1)从原始网页中收集的原始新闻文本的原始数据集,利用分词器对采集的原始数据集进行进一步预处理,再利用本发明的新闻热点发现模型之后,得到图2的实验结果分析图,其中蓝、绿和红三条直线分别代表狄利克雷过程混合模型(Dirichlet process model,DPM)、皮特曼过程混合模型(PYPM)和自动调整折扣的皮特曼过程混合模型(AD-PYP)的实验对比结果分析图;
2)人造数据集假定是2个类,极大类与极小类之比为1:1、10:1、50:1、100:1、1000:1等几组不平衡比例数据集;
3)经聚类分析后,得到实验结果;
4)采用NMI进行评估,得到图2所示结果,AD-PYP可以完美分出在各个不平衡比例下的那个极小类簇,即是新闻热点。
- 还没有人留言评论。精彩留言会获得点赞!