一种基于结构概要模型的有向标签图自适应索引构建方法与流程
本发明属于图数据管理的技术领域。
背景技术:
图是计算机科学中最常用的一类抽象数据结构,在结构和语义方面比线性表和树更为复杂,更具有一般性表示能力。现实世界中的许多应用场景都需要用图结构表示,与图相关的处理和应用几乎无所不在。
大规模图数据通常包含百万个以上顶点,其存储、更新、查找等处理的时间开销和空间开销远远超出了传统图数据管理的承受能力。针对大规模图数据的高效管理,如存储、索引、更新、查询、搜索等,已成为急需解决的问题,特别是与大规模图数据应用密切相关的问题,如大规模图数据的子图查询问题,以及该问题涉及到的索引模型构建、查询算法等问题,具有重要的研究意义和应用价值。
为了提高对图数据的处理效率,可以为图数据构建索引,这也是加速查询的重要手段之一。索引是传统关系数据库中的关键技术,包括B+树索引、Hash索引、位图索引等,技术较为成熟。目前,图数据索引主要有以下几类:基于邻接顶点的索引、边索引、路径索引以及频繁子结构索引。然而当数据规模较大时,构建以上几类索引的时间复杂度极高,至多可达到O(|V|4)级别,空间复杂度通常也会超出内存的限制。因此,如何构建出结构简单、复杂度低的索引成为一个难题。
技术实现要素:
本发明目的是解决大规模图数据的查询这一问题,提供一种基于结构概要模型的有向标签图自适应索引构建方法。本发明通过将数据图进行压缩,使得在进行子图匹配查询时,直接从压缩了的结构概要中进行匹配,进而通过索引查询数据图,从而能够提高查询匹配的效率。
本发明提供的基于结构概要模型的有向标签图自适应索引构建方法,以有向标签图的结构概要模型为基础,构建出的索引可以帮助快速访问图数据,同时由于索引的自适应性,可以增加子图查询的查找效率;具体步骤如下:
第1、对图顶点进行等价类划分
图数据的结构较为复杂,没有相匹配的数据模式,为了构建图的结构概要,可以将图数据分为许多个等价类,这需要首先利用顶点等价类的概念对图顶点进行划分,而后依据顶点的标签和结构特征就可以进行结构概要的构造。
第1.1、将有向循环图转换为无环图
针对研究的有向标签图,为了计算顶点的结构特征,可以采用自底向上的策略,从数据图的叶节点逐层向上进行计算,这就要求数据图是具有叶节点的无环图,而真实的数据往往都是带有方向的循环图,所有第一步需要利用强联通分量把循环图转换为无环图。
转换方法:
给定一个有向循环标签图G=(V,E,L),以及G的强连通分量集合C={c1,c2,...,cm},用函数c(v)=ci描述顶点v属于某个强连通分量ci,那么,使用Tarjan算法可以得到G转换成的有向无环标签图GSCC=(VSCC,ESCC,LSCC),其中:
(1)VSCC是顶点的集合,满足:
(2)ESCC是边的集合,满足:
ESCC={(v1,v2)|{(v1,v2)∈E}-{(v1,v2)∈E∩v1,v2∈ci}}
(3)LSCC是顶点标签的集合,对于由强连通分量构成的顶点,其标签值给一个特殊标记
第1.2、计算图中顶点的rank值
对于无环标签图GSCC,根据其顶点的可达子图,计算顶点的结构特征rank值,即可作为划分顶点等价类的重要依据。无环图保证了其中每一个非叶节点顶点可以用其与叶节点之间的距离值rank来描述其结构特征,rank值的计算方法为:
(1)如果v是G的叶节点,则
rank(v)=0
(2)如果v不是G的叶节点,c(v)是GSCC的叶节点,则
rank(v)=-∞
(3)如果v不是G的叶节点,c(v)也不是GSCC的叶节点,则
rank(v)=max{(1+rank(v'))|(c(v),c(v'))∈ESCC}
第1.3、将具有相同标签和rank值的顶点划为一类
顶点等价类是指数据图中,具有相同标签和rank值的顶点集合。对于有向标签图G中的顶点集合V,可以将其表示为若干等价类的集合:
Par={P1,P2,...,Pr}
其中,属于同一个等价类Pi的任意两个顶点u和v之间满足:
L(v)=L(u);rank(v)=rank(u)
第2、根据结构概要模型构建索引
通过划分的顶点等价类能够建立出图数据的结构概要模型,这实现了对图数据的最大程度压缩,接下来将要在模型的基础上构建索引,索引包括两方面,对于顶点的索引和对于边的索引,在这一部分我们将详细描述索引的构建过程。
第2.1、建立结构概要模型
基于顶点等价类,可以很容易定义出有向标签图G的结构概要模型,这个模型可以表示为四元组:Gs=(VS,ES,LS,RS),其中:
(1)VS={vS1,vS2,...}是结构概要中顶点的集合,且
(2)Es是结构概要中边的集合,设vsi,vsj∈Vs,图G中存在一条边(u,v)∈E,S(v)=vsi,S(u)=vsj,则在Gs中存在边(vsi,vsj)∈ES
(3)LS是结构概要中顶点标签的映射函数集合L(vsi)=li
(4)Rs是结构概要中顶点的rank值映射函数集合R(vsi)=ri
第2.2、生成关于顶点的索引
基于结构概要模型,将模型中顶点集合的每一项作为一个索引条目,生成一种关于数据图顶点的倒排索引。这里的倒排索引即是一个全体倒排记录表,每一条倒排记录由一个结构概要顶点和一系列数据图顶点构成,这里由于顶点集合已经划分好,所以构建倒排索引的步骤已经得到简化,只需将顶点集合转化成一条条倒排记录即可。
对每一条倒排记录,需要在记录中对图顶点进行排序,这里为图顶点进行编号,维护一个图顶点和序号的对应关系表,可以减小排序的内存开销。
第2.3、生成关于边的索引
边的索引同样是基于结构概要模型,根据模型中边的集合,生成关于数据图边的索引。边的索引中使用顶点来表示边,具体构成是,每一条索引记录的索引条目是结构概要中的一条边,使用边连接的两个顶点来表示,索引项是数据图中的一些边,每一项使用边连接的两个顶点来表示。
第3、结构概要索引的自适应更新
本发明中的索引不是以数据为中心,而是以查询为中心,建立索引的目的更多的是为了增加数据查询的效率,因此,索引的更新是依赖于查询图的。
在对数据图进行子图匹配查询时,利用结构概要模型和结构概要索引可以大大提高查询速度,然而结构概要模型只是粗糙的模型可能无法得到精确的匹配子图集合,这就需要根据查询图对模型进行细化,同时对索引进行更新。根据索引的生成过程知,索引完全基于结构概要模型来构建,因此,结构概要细化完成后,索引很容易完成更新。
第3.1、结构概要顶点细化
结构概要的细化依赖于查询图的结构,在细化数据图的顶点等价类时,基于的是数据图顶点的局部双拟关系。对于给定的查询图
Gq=(Vq,Eq,Lq)
双拟关系B=V×V满足下列条件:
局部双拟关系是指数据图上的一个二元关系:
为了满足查询图顶点的局部双拟关系,就会对数据图顶点等价类进行一次细化。
第3.2、结构概要模型更新
由于数据图及其结构概要通常比较复杂,结构概要的某一个顶点细化后,可能会导致该顶点的前驱或后继顶点不再满足双拟关系,从而需要进行反复的细化,因此这是一个迭代更新的过程,细化的标准来自于集合划分的稳定性理论:对于两个数据图顶点集合X和Y,如果X是Y的后继顶点集合的子集,或者X与Y的后继顶点集合不相交,则X相对于Y是稳定的。在进行子图匹配查询时,首先根据查询图的顶点标签寻找结构概要中相关的顶点,然后再根据数据图顶点的连接关系进行分裂,直到达到稳定状态即完成结构概要的一次更新。不断重复这个更新过程,就会不断细化结构概要,以覆盖多样化的子图匹配查询。
第3.3、结构概要索引更新
每一次结构概要的细化后,索引相应地进行自适应更新,这是在原来索引的基础上进行扩充的过程,具体流程如下:
(1)比较新的等价类与旧的等价类,找出被重新划分的顶点集合。
(2)定位到这些顶点所在的顶点索引,删除关联的索引条目,用新划分的集合建立新的索引条目。
(3)定位到这些顶点所在的边索引,删除关联的索引条目,根据新的结构概要模型图创建新的边索引条目。
通过这一流程,即可达到快速更新索引的目的。
本发明的优点和积极效果:
本发明提出的图结构概要模型,实现了对图数据的最大程度压缩,在此基础上构建的索引,存储一种图数据与压缩图的简洁的映射关系,以简单的结构和较小的空间存储了图数据,提高了数据访问的效率,而且,索引构建的过程完全基于结构概要模型,建立索引的时间复杂度也不高。
同时,本发明考虑到了数据索引的自适应更新,发明中的索引以查询为中心,对于不同的查询子图,能够适时将结构概要细化,从而达到更新索引的目的。基于这样的自适应索引,在进行子图匹配查询时,无需高代价的数据预处理过程,能够兼顾查询匹配的效率和查询子图结构的相似性。
附图说明
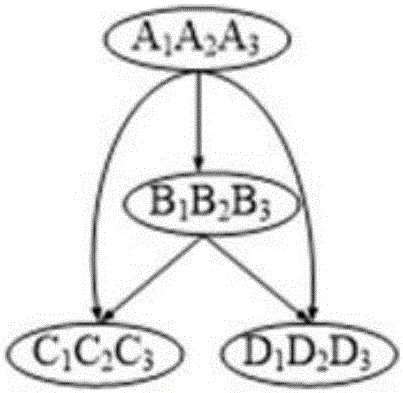
图1是有向标签图。
图2是顶点等价类划分图。
图3是顶点索引图。
图4是边索引图。
图5是查询图。
图6是模型细化图。
图7是顶点索引更新图。
图8是边索引更新图。
图9是方法的流程图
具体实施方式
实施例1:基于结构概要模型的有向标签图自适应索引构建方法
一、对数据图进行顶点等价类划分
我们对如下图1的有向标签图,按照本发明的方法进行划分,计算每个节点的rank值,然后将标签相同和rank值相同的顶点划分一类,由于
rank(C1)=rank(C2)=rank(C3)=0
因此顶点C1、C2、C3被划分为一个等价类,同理
rank(A1)=rank(A2)=rank(A3)=2
顶点A1、A2、A3也被划分为同一等价类,得到如图2所示的顶点等价类划分图。
二、根据结构概要模型分别构建顶点和边的索引
先将数据图中的顶点映射到一组序号上,排序按照rank值大小进行,接着根据结构概要图,从中抽出所有顶点和边,构成索引的词项,而数据图中的顶点构成索引项,得到如图3和图4所示的顶点索引图和边索引图。
三、结构概要索引根据查询图自适应更新
结构概要索引是以查询为中心而进行更新的,对于图5所示查询图Q1,Q2,当执行查询Q1时,由于查询图可能匹配的顶点B包含了数据图顶点B1、B2和B3满足双拟关系(邻接点都为C和D),因此无需细化结构概要模型,无需更新索引,即可得到正确的匹配子图。当执行查询Q2时,由于Q2中包含顶点A,A由数据图的三个顶点A1、A2和A3压缩而成,但三者的后继关系不同(A1的邻接点B和C,A2的邻接点B、C、D,A3的邻接点B和D),不满足双拟关系,需要对模型进行细化,得到图6的模型细化图。接着根据细化后的模型,对顶点和边的索引进行更新。更新后的索引结构如图7和图8所示。
- 还没有人留言评论。精彩留言会获得点赞!