基于多摄像机监控网络的行人识别与跟踪方法与流程
本发明涉及一种基于多摄像机监控网络的行人识别与跟踪方法,属于视频监控网络的
技术领域:
。
背景技术:
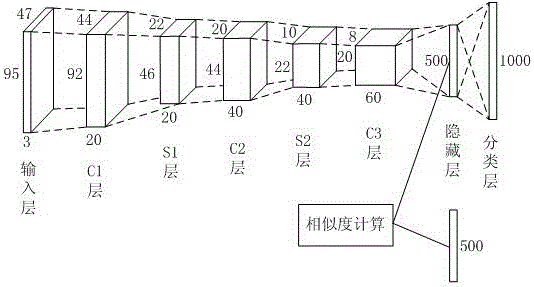
:随着智慧城市建设的推进和智能安防技术的革新,在视频监控系统中引入智能视频分析技术,成为节省人力物力、提高监控安全等级的有效手段。其中,行人目标是监控系统的重点关注目标,对其进行检测、识别、跟踪是智能视频分析技术的重要任务。监控系统中的摄像机视频质量参差不齐,拍摄角度和光照条件各异,出现在其中的行人有姿态、遮挡程度多变等特点。因此,对行人目标的跨摄像机连续、长期的识别和跟踪是智能视频监控领域的一大难题。目前的多摄像机联合监控技术中,主要有两大着眼点。一是行人再识别技术,致力于解决摄像机非重叠场景下目标的识别问题,致力于使用鲁棒性特征、距离度量学习等手段提高在数据集上的识别率。一方面,目前流行的深度学习技术在这方面的成功应用甚少;另一方面,实际场景中常常能获取到可疑行人目标的图像、视频、外观特征的描述等多种线索,而现有方法大多难以同时有效利用这些信息。二是多摄像机网络的时空信息运用,致力于从多摄像机网络的拓扑结构、场景关联中提取出时空信息,提高目标跨摄像机识别与跟踪的准确率。目前这一研究集中在时空信息的自动学习、跨摄像机的数据关联算法等方面,然而对计算资源有限的情况下,如何将不同摄像机组织起来,利用时空信息对视频分析任务进行连续而有效切换的研究甚少。因此,现有的多摄像机监控网络下,无法智能化地对目标进行识别和持续跟踪,及在跟踪过程中实现高效的监控切换,降低监控效率。技术实现要素:本发明所要解决的技术问题在于克服现有技术的不足,提供一种基于多摄像机监控网络的行人识别与跟踪方法,解决现有的多摄像机监控网络下无法智能化地对目标进行识别和持续跟踪,及在跟踪过程中实现高效的监控切换的问题。本发明具体采用以下技术方案解决上述技术问题:基于多摄像机监控网络的行人识别与跟踪方法,包括以下步骤:步骤1、根据设置的视频包围圈标定准则将多摄像机监控网络中摄像机划分至若干个视频包围圈中;步骤2、对目标行人的特征进行特征提取并存储至目标行人特征库;步骤3设置其中一个视频包围圈为初始视频包围圈,及对该视频包围圈下启动行人跟踪与识别任务;步骤4、调取步骤3的视频包围圈中各摄像机的监控画面,利用多目标跟踪算法对所有监控画面中每帧的行人进行跟踪获得多张待识别行人图像,对每张待识别行人图像进行特征提取;步骤5、利用光照监控算法检测步骤4所调取视频包围圈中各个摄像机在每帧的监控画面亮度,计算获得各摄像机在每帧所对应的监控画面亮度指数;步骤6、根据所提取每张待识别行人图像中特征与所得目标行人特征、及所得各摄像机在每帧的监控画面亮度指数计算得到待识别行人与目标行人的相似度;根据所得相似度判断待识别行人是否为目标行人,当判断待识别行人为目标行人时,生成用于目标行人识别成功的报警信号,且根据设置的视频包围圈切换准则进行视频包围圈切换,以实现在视频包围圈中对该目标行人进行锁定和跟踪;步骤7、重复执行所述步骤4至6,以实现对目标行人进行连续识别与跟踪。进一步地,作为本发明的一种优选技术方案:所述步骤1中每个视频包围圈由一个中心摄像机和若干个边缘摄像机组成。进一步地,作为本发明的一种优选技术方案:所述步骤2采用基于卷积神经网络的特征提取算法提取获得目标行人特征。进一步地,作为本发明的一种优选技术方案:所述步骤2中目标行人特征包括目标行人脸部特征或上下半身颜色特征或上下半身纹理特征。进一步地,作为本发明的一种优选技术方案:所述步骤2中目标行人特征由输入的视频或图像提取,或根据直接输入的特征得到。进一步地,作为本发明的一种优选技术方案:所述步骤4中所利用的多目标跟踪算法,包括:步骤41、针对视频包围圈中各摄像机在每帧的监控画面采用基于积分通道特征的行人检测器对行人进行实时检测;步骤42、利用卡尔曼滤波器对所检测到的每个行人进行实时跟踪;步骤43、利用JPDA联合概率数据互联算法对每个行人进行前后时刻的数据关联;步骤44、返回执行步骤41至步骤43,以达成对视频包围圈中各摄像机在每帧的监控画面中行人连续跟踪。进一步地,作为本发明的一种优选技术方案:所述步骤5中所利用的光照监控算法,包括:步骤51、将视频包围圈中各个摄像机在每帧的监控画面转换至HSV颜色空间图像;步骤52、计算所转换HSV颜色空间图像的V通道归一化平均亮度值;步骤53、将步骤52所得平均亮度值作为该摄像机在每帧所对应的监控画面亮度指数。进一步地,作为本发明的一种优选技术方案:所以步骤6还包括设置权重以计算获得待识别行人与目标行人的相似度。进一步地,作为本发明的一种优选技术方案:所述步骤6还包括设置用于控制生成报警信号和用于控制视频包围圈切换的阈值。本发明采用上述技术方案,能产生如下技术效果:本发明所提供的一种基于多摄像机监控网络的行人识别与跟踪方法,该方法在多摄像机监控网络基础上设置多个视频包围圈,用以组织多摄像机网络中的摄像机,完成算法分析任务的联动切换,实现了在计算资源有限的情况下,有效利用时空信息辅助跟踪和识别任务,具有良好的实际应用价值。采用所述方法能够有效利用可疑行人的图片、视频、外观特征描述等多种输入线索,进行实时、鲁棒的目标识别与跟踪,符合实际应用中处理多种输入信息的需求。所述的方法中融合了基于深度学习的图像识别技术,避免了手动设计特征的盲目性和复杂性。附图说明图1为本发明基于多摄像机监控网络的行人识别与跟踪方法的流程图。图2为本发明中卷积神经网络结构的示意图。图3为本发明中视频包围圈的结构示意图。具体实施方式下面结合说明书附图对本发明的实施方式进行描述。如图1所示,本发明设计了基于多摄像机监控网络的行人识别与跟踪方法,该方法结合多摄像机监控网络,以组织多摄像机网络中的摄像机完成算法分析任务的联动切换,具体包括以下步骤:步骤1、根据设置的视频包围圈标定准则将多摄像机监控网络中摄像机划分至若干个视频包围圈中;其中,用户根据需要设置多摄像机监控网络下监控现场的摄像机位置和角度,及根据设置视频包围圈的标定准则,将多摄像机网络中的摄像机划分到多个视频包围圈中,各视频包围圈之间的摄像机可以重叠,且标定每个摄像机存在对应的监控分析区域。步骤2、对目标行人的特征进行特征提取并存储至目标行人特征库。步骤3、设置其中一个视频包围圈为初始视频包围圈,及对该视频包围圈下启动行人跟踪与识别任务;通常可以将视频包围圈所在场景的初始位置设置摄像机,以该摄像机设置为所在视频包围圈的初始位置。步骤4、调取步骤3的视频包围圈中各摄像机的监控画面,利用多目标跟踪算法对所有监控画面中每帧的行人进行跟踪获得多张待识别行人图像,对每张待识别行人图像进行特征提取。步骤5、利用光照监控算法检测步骤4所调取视频包围圈中各个摄像机在每帧的监控画面亮度,计算获得各摄像机在每帧所对应的监控画面亮度指数。步骤6、根据所提取每张待识别行人图像中特征与所得目标行人特征、及所得各摄像机在每帧的监控画面亮度指数计算得到待识别行人与目标行人的相似度;根据所得相似度判断待识别行人是否为目标行人,当判断待识别行人为目标行人时,生成用于目标行人识别成功的报警信号,且根据设置的视频包围圈切换准则进行视频包围圈切换,以实现在视频包围圈中对该目标行人进行锁定和跟踪。步骤7、重复执行所述步骤4至6,以实现对目标行人进行连续识别与跟踪,直至用户操作至结束。对于上述步骤1中所述的视频包围圈标定准则,具体如下:a),如图3所示,本发明的一个视频包围圈由一个中心摄像机和周围的2-4个边缘摄像机组成的摄像机组,其监控画面可以在多屏监控软件中同时展示;b),一个视频包围圈中的多台摄像机需按照实际布放情况位置和角度,参照视频包围圈的标定准则,尽数划分到不同视频包围圈中;其中,视频包围圈的标定准则具体还包括:b1),同一摄像机只能充当一个视频包围圈的中心摄像机,但可以充当不同视频包围圈的边缘摄像机;b2),标定出的视频包围圈需覆盖整个监控场景,即每一个摄像机都要有从属的视频包围圈,无论是充当中心摄像机还是边缘摄像机;b3),每一个视频包围圈中的摄像机需要满足物理位置相邻、监控场景相邻的条件;b4),每一个视频包围圈中,应尽可能多的使边缘摄像头作为其它视频包围圈的中心摄像机,以保证切换能够连续;c),每一个摄像机都对应各自的跟踪识别算法,在摄像机所对应的监控分析区域中执行行人多目标跟踪和识别的分析任务。算法运行过程中,只执行满足条件的在线摄像机所对应的分析任务;视频包围圈切换时,开启、关闭对应摄像机的算法任务。由该标定准则,形成如图3所示的多摄像机监控网络,但本发明不限于该种结构,其他架构下形成的多摄像机监控网络同样适用于本发明中。本发明中,优选地,所述步骤2中目标行人特征可以采用由输入的视频或图像提取,或直接输入特征得到,进一步地,其目标行人特征可以包括目标行人脸部特征或上下半身颜色特征或上下半身纹理特征,用户可以根据需要选取任一种或多种特征作为线索进行行人识别和跟踪过程,其过程如下:2.1),若选择目标行人特征由输入一张或多张目标行人的图片方式获得,则采用基于卷积神经网络的特征提取算法,提取每张图片的卷积特征描述子,存入目标行人的卷积特征库中。在所述步骤2.1中采用基于卷积神经网络的行人卷积特征提取算法,具体过程如下:2.1a),该算法使用8层卷积神经网络,如图2所示,包括1个输入层,6个隐藏层和1个分类层。其中,第2、4、6层为卷积层,第3、5层为采样层;第7层为生成卷积特征描述子的隐藏层,第8层为分类层。若输入层为47×95×3的RGB三通道彩色图像,则卷积过程如下:第1个隐藏层为卷积层C1,卷积核的大小为4×4,卷积核的数目为20个。经过第一个隐藏层,图像被卷积成20个92×44的特征图。第2个隐藏层为采样层S1,采用max-pooling下采样,每层输入的每个2×2的特征块被下采样为1×1的输出。经过第2个隐藏层,图像被采样成20个46×22的特征图。第3个隐藏层为卷积层C2,卷积核的大小为3×3,卷积核的数目为40个。经过第3个隐藏层,图像被卷积成40个20×44的特征图。第4个隐藏层为采样层S2,采用max-pooling下采样,每层输入的每个2×2的特征块被下采样为1×1的输出。经过第4个隐藏层,图像被采样成40个10×22的特征图。第5个隐藏层为卷积层C3,卷积核的大小为3×3,卷积核的数目为60个。经过第5个隐藏层,图像被卷积成60个8×20的特征图。第6个隐藏层为生成卷积特征描述子的隐含层,输入为第5层的60个8×20的特征图拉直后串联而成的9600维的特征向量,输出为一个500维的特征向量,层内采用全连接的方式。最后一层为分类层,该层采用softmax分类器进行分类输出,分类层的节点数与训练集的类别数相等。2.1b),使用自建行人图像样本库NUPTPR作为训练样本,建立行人图像样本库主要用于训练卷积神经网络,以及用于颜色和纹理特征提取时,从中挑选能够代表可疑目标特征的上下半身图像。自建行人图像样本库NUPTBR共包含1000个不同行人的图像,每个行人包含8张图像,共8000张样本图像;NUPTPR样本库有两个来源:其一,是利用宽带无线通信技术下公安智能图像云平台采集得到的路面上的行人图像;其二,是互联网上搜集得到的行人的图像;训练卷积神经网络时,在每个行人的8张样本图像中随机选取6张做训练,2张做测试。2.1c),使用较小的随机值初始化各层参数,使用softmax分类模型训练生成卷积特征描述子的隐含层,使用适用于卷积神经网络的BP算法训练该卷积神经网络的各层参数。2.1d),使用该卷积神经网络的前7层进行行人图像的特征提取,将第7层输出的500维特征向量作为该行人图像的卷积特征描述子。2.1e),定义两张行人图片所对应卷积特征描述子fi、fj的相似度为:S(fi,fj)=0.5(cos(fi,fj)+1)(1-1)其中cos(fi,fj)为描述子fi、fj之间的余弦相似度。定义建立的卷积特征集为C={f1,f2,...,fn};定义某行人样本图片与卷积特征库的相似度为:SI(f,C)=maxfi∈CS(f,fi)---(1-2)]]>2.2),若选择目标行人特征由输入一段或多段含有目标行人的视频方式获得,则对视频逐一采用目标跟踪算法对该行人进行跟踪。跟踪过程中,采用基于卷积神经网络的行人特征提取算法,提取被跟踪行人的卷积特征描述子,对描述子采用特征筛选算法,用特征筛选算法的目的是为了处理视频输入,从中筛选出有效的特征,经筛选出有效的描述子,扩充目标行人的卷积特征库。其中,所述步骤中采用的多目标跟踪算法,其具体步骤如下:2.2a),针对视频包围圈中各摄像机在每帧的监控画面采用基于积分通道特征的行人检测器对行人进行实时检测;2.2b),对于每个检测到的行人,使用卡尔曼滤波器进行实时跟踪;具体步骤为:b1),使用卡尔曼滤波器对行人矩形包围框的中心点坐标进行位置预测;b2),取检测到的矩形包围框的中心点坐标作为行人位置的量测值,输入卡尔曼滤波器进行滤波器更新。2.2c),在多目标行人跟踪环境中,多个目标之间的距离可能较小,而每个跟踪门相对较大,会发生一个目标落入多个跟踪门中和多个目标轨迹交叉的情况。在这样的复杂场景下,采用JPDA联合概率数据互联算法对每个行人进行前后时刻的数据关联,将前一时刻的目标运动轨迹与当前时刻的量测一一匹配。2.2d),返回执行步骤2.2a)至2.2c),以达成对视频包围圈中摄像机在每帧的监控画面中行人连续跟踪。该目标跟踪算法可以有效对目标行人进行连续跟踪,并且该方法同样适用于步骤4中多目标的跟踪。进一步地,本发明利用基于卷积神经网络的行人特征提取算法,提取被跟踪行人的卷积特征描述子时,采用的特征筛选算法,具体步骤为:采用目标跟踪算法对行人进行跟踪。跟踪过程中,将行人的第一张图像所对应的卷积特征描述子直接加入目标行人的卷积特征库中,此处是将目标行人的第一张图像设定为有效,直接提取特征加入卷积特征库,后续图像则用该方法判断是否有效;对跟踪过程中的后续行人样本图像,计算图像对应的卷积特征描述子与目标行人的卷积特征库的相似度SI,若SI小于阈值θ,则说明该描述子相对于卷积特征库是有效特征,将其加入卷积特征库中;其中θ取值根据实际需要而定,取值范围为0-1之间。θ越大,卷积特征库扩充的速度越快。2.3),若选择目标行人特征由直接提供的目标行人上、下半身的颜色信息方式获得,则需要在自建行人图像样本库中选取相应的颜色图案,存储对应的颜色特征描述子。其中,所述步骤2.3)中所采用的颜色特征提取算法,具体步骤如下:2.3a),使用自建行人图像样本库NUPTPR作为操作人员选取行人颜色图案的参考。对于每幅行人图像,以(xu1,yu1)为矩形左上角坐标、(xu2,yu2)为矩形右下角坐标,取出行人上半身图像;以(xd1,yd1)为矩形左上角坐标、(xd2,yd2)为矩形右下角坐标,取出行人下半身图像。根据经验可取xu1=0.15w,xu2=0.85w,yu1=0.15h,yu2=0.5h;xd1=0.15w,xd2=0.85w,yd1=0.5h,yd2=0.85h。操作人员需从中选取与待识别行人颜色特征最相似的上下半身图案作为颜色特征提取的图像。2.3b),对操作人员挑选的行人上下半身图像,分别使用24-bins模糊过滤器提取出24维颜色直方图。具体步骤为:b1),将上下半身图像分别转换到HSV颜色空间。b2),将各通道图像输入10-bins模糊过滤器,输出一个10维的特征向量。b3),将所得10维特征向量和S、V通道输入24bin模糊过滤器,得到24维颜色直方图。2.3c),将上下半身图像对应的直方图串联,再进行归一化操作,得到48维颜色特征描述子,存入目标行人的颜色特征库中。2.3d),对于当前行人样本图像采用相同的方法计算颜色特征描述子,将其与目标行人颜色特征库中的颜色特征描述子之间的Bhattacharyya距离作为目标颜色特征之间的相似度,取其中的最大相似度作为行人样本图像与目标行人的颜色特征库之间的相似度Sc。2.4),若选择目标行人特征由直接提供的目标上、下半身的纹理信息方式获得,则需要在自建行人图像样本库中选取对应的纹理图案,存储对应的纹理特征描述子到目标行人的纹理特征库中。其中,所述步骤2.4)中采用的纹理特征提取算法,具体步骤如下:2.4a),使用自建行人图像样本库NUPTPR作为操作人员选取行人颜色图案的参考。对于每幅行人图像,使用与步骤2.3.1)相同的方法,按一定比例分割出行人的上下半身图案。操作人员从中选取与待识别行人纹理特征最相似的上下半身图案作为纹理特征提取的图像;2.4b),对操作人员挑选的行人上下半身图像,分别计算LBP旋转不变纹理特征直方图。具体步骤为:b1),将行人上下半身图像分别转换到灰度空间;b2),分别计算旋转不变LBP特征。求旋转不变LBP特征的公式如下:s(x)=1,x≥00,x<0---(2-1)]]>U(LBPP,R)=|s(gp-1-gc)-s(g0-gc)|+Σp=1P-1|s(gp-gc)-s(gp-1-gc)|---(2-2)]]>LBPP,Rriu2=Σp=0P-1s(gp-gc),U(LBPP,R)≤2P+1,U(LBPP,R)>2---(2-3)]]>其中,P为LBP特征采样点个数;R为圆形邻域的采样半径,这里可以取1;gc为LBP采样邻域中心像素的灰度值;gp(p=1,2,…,P-1)为半径为R的邻域内采样点的像素灰度值;U(LBPP,R)为LBP圆形邻域采样点间0-1变化的次数;s(x)为一个函数。b3),对上下半身的旋转不变LBP进行直方图统计,得出9维纹理直方图。2.4c),将上下半身图像对应的纹理直方图串联,再进行归一化操作,得到18维纹理特征描述子,存入目标行人的纹理特征库中。2.4d),取行人样本图像的纹理特征述子与目标行人纹理特征库中的纹理特征描述子之间的Bhattacharyya距离作为目标纹理特征之间的相似度;取其中的最大相似度作为行人样本图像与目标行人纹理特征库之间的相似度St。本发明在结合监控中的光照情况时,所述步骤5中采用的光照监控算法具体可以包括:步骤51、将视频包围圈中各个摄像机在每帧的监控画面转换至HSV颜色空间图像。步骤52、计算所转换HSV颜色空间图像的V通道归一化平均亮度值。步骤53、将步骤52所得平均亮度值作为该摄像机在每帧所对应的监控画面亮度指数。在上述步骤6中,结合步骤2所提取的目标行人特征和步骤4所提取的任一张待识别行人图像中待识别行人特征计算特征之间相似度,及由特征之间相似度结合步骤5所得各待识别行人图像的亮度指数计算得到待识别行人与目标行人的相似度,其中优选对所输入的参数分别设置权重,具体步骤如下:6.1),计算出所述步骤2的3种目标行人特征包括卷积特征、颜色特征、纹理特征,与各自的特征库之间的相似度;6.2),使用步骤5中的光照监控算法计算出各摄像机在每帧所对应的监控画面亮度指数L;6.3),使用综合评估公式计算出某一摄像机下行人样本图像与待识别行人特征库的相似度Ss,即:Ss=aI(L)×SI+ac(L)×Sc+at(L)×St(3)其中aI(L)、ac(L)、at(L)分别为3种特征对应的权重函数,函数取值与亮度指数L有关;SI、Sc、St分别为3种特征对应的相似度。本步骤中,还根据计算所得相似度判断待识别行人是否为目标行人,当判断待识别行人为目标行人时,生成用于目标行人识别成功的报警信号,且在视频包围圈中对该目标行人进行锁定和跟踪。在此过程中,还可以包括设置用于控制生成报警信号和用于控制视频包围圈切换的阈值T,当Ss>T时算法识别出行人目标,触发行人目标识别报警,且控制视频包围圈切换。在执行切换过程中,视频包围圈的切换方法为:对于触发包围圈切换的摄像机,若其为当前处理的视频包围圈的中心摄像机,则放弃切换;若其为当前处理的视频包围圈的边缘摄像机,且为另一新的视频包围圈的中心摄像机,则关闭当前视频包围圈中的其它摄像机的算法任务,开启新的视频包围圈中的其它摄像机的算法任务,由此切换到新的视频包围圈。最后,如步骤7所述,重复执行所述步骤4至6,以实现对目标行人进行连续识别与跟踪,直至用户操作至结束。在多摄像机监控网络中的其他视频包围圈,同样地按照上述步骤进行目标行人的识别和连续跟踪。由此,本发明可以组织多摄像机监控网络中的摄像机,完成监控分析任务的联动切换,实现了在计算资源有限的情况下,有效利用时空信息辅助跟踪和识别任务,提高识别效率。采用所述方法能够有效利用可疑行人的图片、视频、外观特征描述等多种输入线索,进行实时、鲁棒的目标识别与跟踪,符合实际应用中处理多种输入信息的需求。上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1