一种基于HMM的含错LFSR序列生成多项式估计方法与流程
本发明属于通信领域,尤其涉及信号处理技术和机器学习中的隐形马尔科夫模型(Hidden Markov Model,HMM)技术,适用于通信领域中常用的线性反馈移位寄存器(Linear Feedback Shift Register,LFSR)序列生成多项式的估计。
背景技术:
伪随机序列在扩频通信、伪码测距以及密码学等领域有着广泛的应用,生成多项式是伪随机序列的重要参数,是完成扩频通信侦查、信息解密等信号处理后续工作的基础。扩频通信中常采用m序列、Gold序列等LFSR序列,因此LFSR序列的生成多项式估计是序列分析的重难点内容。特别是在仅知道部分码序列和存在误码的情况下,如何估计其生成多项式一直以来都是本领域的研究热点。
针对LFSR序列的生成多项式估计,目前主要的方法有BM算法、欧几里得算法、征服攻击法(DC)、组合枚举求优势法和基于统计特性的分析方法等。BM算法和欧几里得算法的效率很高,但要求序列是无误的,这限制了其在高误码的信息对抗领域的应用;征服攻击法、组合枚举求优势法和基于统计特性的方法均是基于信源的不平衡性,通过遍历阶数和可能的抽头位置来获取生成多项式,因此计算量相当大。
由此可以看出,已有的含错LFSR序列生成多项式的估计仍存在不足。为了能够有效获取LFSR序列的生成多项式,需要提出新的有效的估计方法,以满足实际工程实践的需要。
技术实现要素:
本发明针对现有技术的不足,提出一种基于HMM的含错LFSR序列生成多项式估计方法。该方法可以较好的满足非合作通信信号处理中对扩频序列分析的需求,大大提高生成多项式估计对误码的适应能力。
本发明既可以应用于扩频通信信号处理系统,也可以用于密码分析等其他应用LFSR序列的系统。
本发明的技术方案位:将含错LFSR序列建模为HMM并构建状态样本向量和输出向量,通过前向后向算法估计出HMM的状态转移矩阵和系统输出矩阵,进而建立二进制线性方程组,利用高斯消元法求解得到序列生成多项式的估计。
一种基于HMM的含错LFSR序列生成多项式估计方法,具体步骤如下:
S1、建立HMM,构造状态样本向量S和输出样本向量Y,所述构造状态样本向量S和输出样本向量Y的具体步骤为:
S11、将含错LFSR序列建模为HMM,将LFSR中L个寄存器组成的二进制向量作为HMM的隐藏状态,将LFSR的输出作为HMM的输出,其中,所述L为生成多项式阶数,L为不为零的自然数,所述HMM的状态集合为除全零向量之外的所有L维二进制向量,这些向量对应十进制数即为状态编号,输出集合为{0,1},分别编号为1,2;
S12、初始化两个长度为N-L+1的全零向量S和Y,其中,N为S11所述含错LFSR序列的长度;
S13、设置一个长度为M的窗w,将窗w内的二进制向量转化为十进制数,将所述十进制数作为HMM状态的标号并存入S12所述S中,若窗w内二进制向量全零,则随机选取一个位置设置为1再继续;
S14、从S11所述含错LFSR序列的第一位开始滑动S13所述窗w,对整条序列完成相同处理,统计出状态样本向量S,直接截取序列第L+1位到最后一位即为输出样本向量Y;
S2、利用S1所述状态样本向量S和输出样本向量Y估计出HMM的状态转移矩阵A与输出矩阵B,构造长度为H的连续状态转移链及对应输出,具体步骤为:
S21、利用S1所述状态样本向量S和输出样本向量Y,通过前向后向算法估计出HMM的状态转移矩阵A和输出矩阵B,所述状态转移矩阵A中的元素aij表示状态i的下一个状态为状态j的概率,1≤i,j≤2L-1;
S22、从S21所述状态矩阵A编号为1的状态开始,取矩阵A第一行元素最大值对应的列数k1为状态1的下一个状态并记录,同时取S21所述输出矩阵B第一行最大元素对应的列数减1作为LFSR在所述状态1下的输出值并记录,其中,状态矩阵A的第一行即为状态矩阵A编号为1的状态;
S23、转到S21所述状态转移矩阵A的第k1行,取该行元素最大值对应列数k2作为状态k1的下一个状态并记录,同时取S21所述输出矩阵B第k1行最大值元素对应列数减1作为LFSR在状态k1下的输出值并记录;
S24、重复步骤S22-S23Q次,得到LFSR的长度为H的连续状态转移链以及对应长度为H的输出向量,其中,Q为经验值;
S3、建立二进制线性方程组并求解,具体步骤为:
S31、初始化T×T的方程组系数矩阵C,将长度为H的连续状态转移链中第l个状态编号转化为对应T维二进制向量,作为C的第l行,其中,1≤l≤T且l为自然数,T=L;
S32、将S24所述输出向量作为方程组常数项b,建立二进制方程组Cx=b并构造增广矩阵D=[C|b];
S33、判断S32所述增广矩阵D的秩是否等于L,若不等,则返回步骤S1,若相等,则用高斯消元法求解S32所述Cx=b的最小非零解,该解即为所要求的生成多项式系数。
本发明的有益效果是:
本发明方法通过将含错LFSR序列建模为HMM,利用前向后向算法估计出HMM的状态转移矩阵与系统输出矩阵,并在此基础上建立二进制线性方程组,利用高斯消元法求解得到序列生成多项式的估计。本发明可以对含错LFSR序列进行精确估计,计算机仿真结果表明本发明具有良好的估计效果。
附图说明
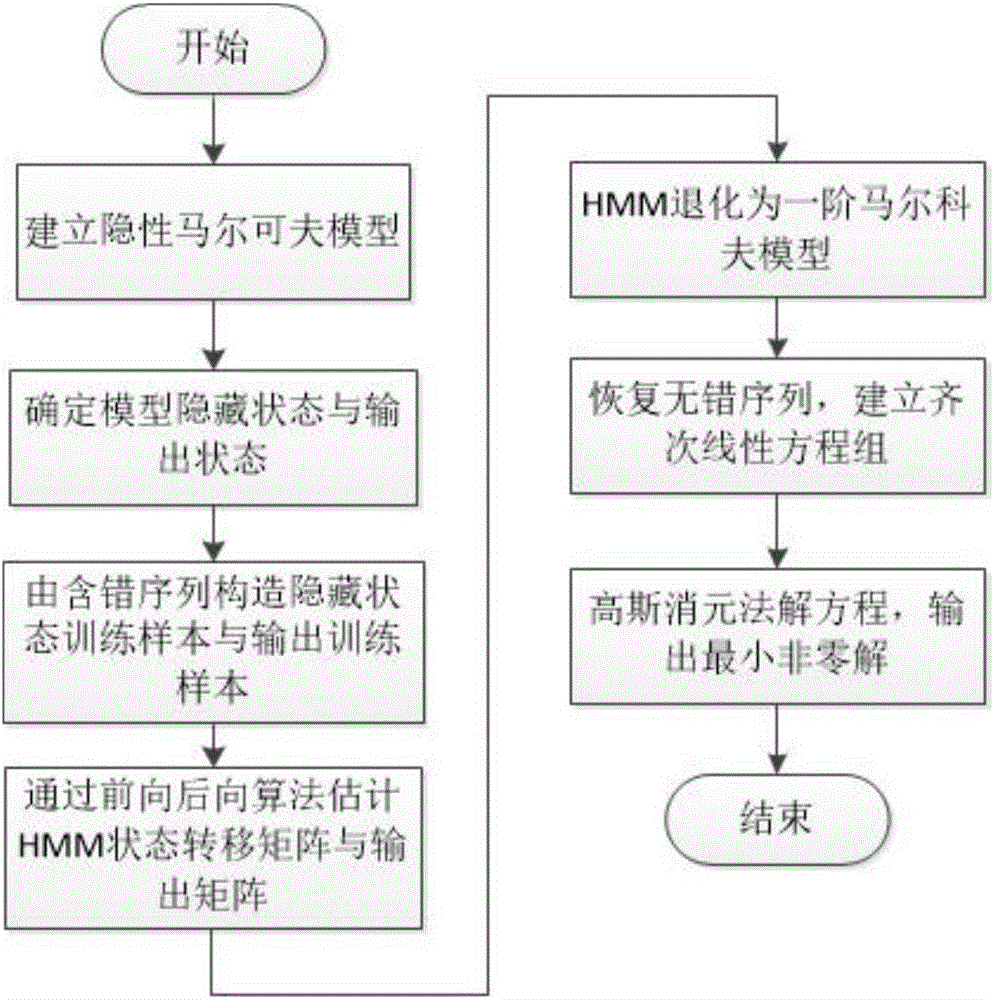
图1是本发明基于HMM的含错LFSR序列生成多项式估计方法的具体实施方式流程图。
图2是本发明具体实施,不同阶数生成多项式估计平均错误率随误码率变化曲线示意图。
具体实施方式
下面结合附图,对本发明作进一步地详细描述。
本实施的目的是对不同阶数生成多项式估计错误率随随SNR(Signal Noise Rate,信噪比)变化进行仿真。
图1是本发明基于HMM的含错LFSR序列生成多项式估计方法的具体实施方式流程图。
如图1所示,以m序列为例,说明本发明的具体实施方法:
第一步,建立HMM,并构造状态样本向量和输出样本向量:
m序列阶数L分别设为5、6、7,序列周期个数M=50,序列总长度为N=Tp*M,其中,Tp=2L-1为序列周期。误码率范围设置为0.01到0.2,随机产生二进制误码与无错序列做异或,得到含错LFSR序列。
将HMM的隐藏状态集合设为所有L维二进制向量(全零向量除外),这些向量对应十进制数1~2L-1作为状态编号,输出集合为{0,1};
初始化两个长度为N-L+1的全零向量S和Y(N为序列长度);设置一个长度为M的窗,将窗内的二进制向量转化为十进制数,将该十进制数作为HMM状态的标号并存入S,若窗内二进制向量全零,则随机选取一位置为1再继续;从序列第一位开始滑动该窗,对整条序列完成相同处理,统计出状态样本向量S;直接截取序列第L+1位到最后一位即为输出样本向量Y。
第二步,利用状态样本向量和输出样本向量估计HMM的状态转移矩阵与输出矩阵,构造长度为H的连续状态转移链及对应输出:
利用统计出的样本向量S和Y,通过前向后向算法估计出HMM的状态转移矩阵A和输出矩阵B;
A中的元素aij代表状态i的下一个为状态j的概率,1≤i,j≤2L-1;从矩阵A的第一行,即编号为1的状态开始,取其中最大值对应的列数k1作为状态1的下一个状态并记录,同时取矩阵B第一行最大值元素对应列数减1作为LFSR在状态1下的输出值并记录;转到A的第k1行,取其最大值对应列数k2作为状态k1的下一个状态并记录,同时取矩阵B第k1行最大值元素对应列数减1作为LFSR在状态k1下的输出值并记录;以此类推H次,得到LFSR的长度为H的连续状态转移链以及对应长度为H的输出向量。
第三步,建立二进制线性方程组并求解:
判断D的秩是否等于L;若不等,则重新构造状态样本向量S与输出样本向量Y并进行余下过程;若相等,直接用高斯消元法求解该二进制方程组的最小非零解,该解即为呈现降幂形式的生成多项式系数(不包含反馈系数,通常默认反馈系数为1)。
进行100次蒙特卡洛实验,最终得到生成多项式估计正确率随误码率变化曲线图,如图2所示。从图中可以看出本发明提出的估计方法在误码率0.12以下时性能非常良好,在误码率0.2时依然达到正确率70%,且在不同阶数下估计效果差异不大。
- 还没有人留言评论。精彩留言会获得点赞!