基于迭代批量删点框架的SimRank前k个最相似点对计算方法与流程
本发明涉及SimRank计算领域,尤其涉及一种SimRank前k个最相似点对计算方法。
背景技术:
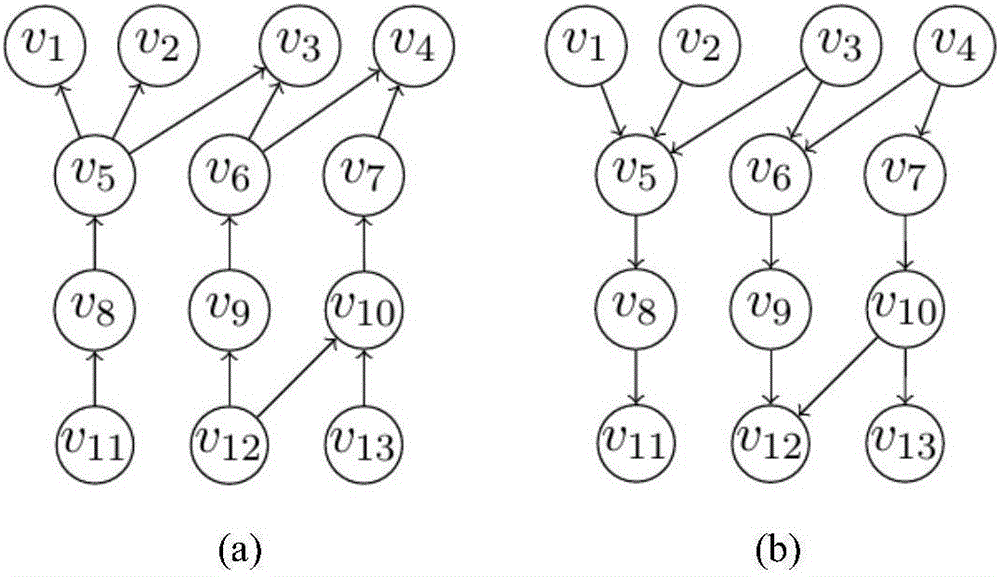
:SimRank是一种普适的网络节点结构相似度度量模型,广泛应用于竞价搜索排名、网络垃圾监测和模式匹配等领域。其基本思想可以概括为两个节点的邻居越相似,这两个节点越相似;即两个节点的相似度由其邻居节点的相似度决定。SimRank可以被广泛应用于具有一定关联的、可以被抽象化为网络模型的领域中:例如在社交网络中,SimRank可以被用于相似用户识别和朋友推荐,进而辅助链路预测和跟踪信息传播等。因其重要的作用,SimRank的计算一直是研究的热点问题之一。起初的研究焦点集中在SimRank的全匹配问题。给定一个含有n个节点,平均度为d的网络G,SimRank全匹配问题需要计算出网络中所有点对,即n×n对的SimRank值。SimRank的提出者GlenJeh和JenniferWidom教授设计了首个基于迭代的SimRank全匹配算法(文献:G.JehandJ.Widom.SimRank:ameasureofstructural-contextsimilarity.InProceedingsoftheEighthACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining,July23-26,2002,Edmonton,Alberta,Canada,pages538–543,2002)。该算法在处理SimRank全匹配问题上的时空开销分别为O(kd2n2)和O(n2),其中k是迭代次数。D.Lizorkin等人通过部分中间值记录的方式改进了算法,其时间开销为O(kdn2)(文献:D.Lizorkin,P.Velikhov,M.N.Grinev,andD.Turdakov.AccuracyestimateandoptimizationtechniquesforSimRankcomputation.VeryLargeDataBasesJournal,19(1):45–66,2010)。(文献W.Yu,X.Lin,andW.Zhang.TowardsefficientSimRankcomputationonlargenetworks.In29thIEEEInternationalConferenceonDataEngineering,2013,Brisbane,Australia,April8-12,2013,pages601–612,2013)利用更精细的记录进一步加快了计算速度。然而随着现实世界数据量的激增,SimRank的全匹配计算在时间和空间上的开销都过于巨大而无法满足现实应用。因此,对SimRank的研究转移到了计算前K个最相似的点对上来,即Top-k匹配问题。大部分Top-k匹配算法首先需要用户自定义阈值,然后将SimRank值大于该阈值的点对作为结果返回。然而现实中选定一个合适的、满足尽可能包含所需最相似点对,又最大程度排除非相似点对的阈值是非常困难的。文献W.Tao,M.Yu,andG.Li.Efficienttop-kSimRank-basedsimilarityjoin.TheProceedingsoftheVLDBEndowment,8(3):317–328,2014提出了一种不需要阈值的Top-k算法SRK-JOIN。该算法首先定义了二次相遇概率:从某点同时出发的两条随机路径再次相遇的概率。利用二次相遇概率,每个点可以被编码成一个多维的向量,而两点之间的SimRank值即为相应的两个向量的点积。为了得到Top-k点对,SRK-JOIN需要对相应点的所有路径进行两次扫描:第一次筛选出含有2k个不同候选点的点集,第二次得到Top-k点对。尽管SRK-JOIN比原先的算法在效率上优化了许多,我们仍然发现了很多尚未完善、有待改进的地方:(1)为了将每个点编码为向量,SRK-JOIN需要对每个点都计算二次相遇概率,然而在实验中我们发现对具有较高入度的点计算二次相遇概率是非常耗时的,因为这一过程的时间复杂度和点入度的k指数幂程正比关系;(2)在得到了候选点后,SRK-JOIN需要对候选点的所有路径再次进行扫描,两次扫描之间含有较大的计算冗余,一些在第一次扫描中计算出的中间量可以被用于辅助第二次扫描。技术实现要素:根据SimRank的随机游走模型我们知道SimRank可以通过遍历从两点出发的、长度为ξ的双行路径得到;然而该遍历是非常耗时的。因此,SRK-JOIN提出了通过相遇双行路径和多次相遇双行路径之差来计算SimRank的方法,但是通过实验发现该方法非常耗时的缺点。为了克服这点不足,本发明提出了一种SimRank的迭代批量删点框架,本框架将SimRank的计算过程以不同步数拆分,并在每步计算中找出每个点可达的最大上界的估计值,以此来判断非候选点。该框架的特点在于每次针对单点进行判断,而非点对,这样做的好处是一旦某点被判定为非候选点后,由该点组成的所有点对即可终止计算,节省了时间。通过建立迭代批量删点框架,来快速计算SimRank前k个最相似点对。本发明方法称为KsimJoin。一种基于迭代批量删点框架的SimRank前k个最相似点对计算方法,其特征在于:构建迭代批量删点框架,每次迭代中首先判断出非候选点,在精确计算前删除非候选点来得到前k个最相似点对。具体的,所述构建迭代批量删点框架包括以下步骤:(1)初始化各变量,并将步长控制变量i设为0;(2)开始迭代,首先判断i是否达到规定步数;若没有,则i增加1,计算每个点与其它点的i步内SimRank值;(3)当所有点的i步内SimRank值完成计算后,保存前k个i步内SimRank值及其对应点对,选取第k个i步内SimRank值作为阈值;(4)计算每个点的上界,并与阈值比较:若小于或等于阈值,则作为非候选点删除,反之,进入下一轮迭代;其中,每个点的上界计算公式为:UB(v)=max{Sl(v,*)}+Σi=lξci]]>其中UB(v)代表了点v的上界,*代表除点v以外的点,max{Sl(v,*)}代表了到当前迭代为止,包含有点v的点对的最大相似度的值,l为当前迭代次数,ξ和c分别最大步长和衰减因子;(5)重复(2)至(4)步,直到i达到要求步数;(6)返回前k个点对。与现有技术相比,本发明的优点在于:通过计算出每个点的SimRank上界,提前删除非候选点,避免了非候选点精确的计算出SimRank值,极大的降低了时间开销,可以快速得到SimRank前k个最相似点对。附图说明图1为本发明的迭代批量删点框架算法流程图;图2为有向网络和它的反向网络图;图3为KSimJoin与SRK-Join的比较图。具体实施方式一、有关概念及定义给定一个含有n个节点的有向网络G(V,E),我们称从点v至点u的边<v,u>∈E为点u的一条入边,点v为点u的一个入邻居;I(u)为点u的入邻居集合。SimRank的迭代模型:给定一个有向无环网络G(V,E),点v和点u(v,u∈V)的SimRank值可以表示为:S(v,u)=1v=uC|I(v)||I(u)|Σi=1|I(v)|Σj=1|I(u)|S(I(v)i,I(u)j)v≠u---(1)]]>其中,I(v)i,I(u)j代表了v,u的第i,j个入邻居。从等式(1)可以看出,若点v和点u相等,其SimRank值等于1;否则,点v和点u的SimRank值等于其入邻居之间SimRank值的均值。在现实世界中,网络不都是无环的;针对这种情况,SimRank可以表示为:Sl+1(v,u)=C|I(v)||I(u)|Σi=1|I(v)|Σj=1|I(u)|Sl(I(v)i,I(u)j)---(2)]]>其中若点v和点u相等,S0(v,u)=1,否则S0(v,u)=0,且liml→∞Sl(v,u)=S(v,u)。SimRank的迭代模型可以快速收敛。一般来说,5轮迭代后其排名先后顺序基本确定,即l≤5。除了该数值模型,SimRank还可以被具象化为形象模型:SimRank还可以表示同时从两点出发的两条随机路径,在规定步数内随机沿着入边方向前进,首次相遇的概率。入边方向又可以称为反方向,即路径可以从点u到点v当且仅当边边<v,u>∈E存在。SimRank也可以被具象化为如下随机游走模型:给定一个有向无环网络G(V,E),点v和点u(v,u∈V)的SimRank值可以表示为:其中ξ代表了随机游走路径的最大步数。本发明主要采用SimRank的随机游走模型。基于SimRank的Top-k相似度匹配问题:给定一个有向网络G(V,E)和一个整数k,基于SimRank的Top-k相似度匹配问题需要求解出一个含有k对点对的集合K,使得对于均有S(v,u)≥S(v′,u′)。本发明就是要解决基于SimRank的Top-k相似度匹配问题,因此发明了一种基于迭代批量删点框架的SimRank前k个最相似点对计算方法,通过构建迭代批量删点框架,每次迭代中首先判断出非候选点,在精确计算前删除非候选点来得到前k个最相似点。所述的迭代批量删点框架,包括以下步骤:(1)初始化各变量,并将步长控制变量i设为0;(2)开始迭代,首先判断i是否达到规定步数;若没有,则i增加1,计算每个点与其它点的i步内SimRank值;(3)当所有点的i步内SimRank值完成计算后,保存前k个i步内SimRank值及其对应点对,选取第k个i步内SimRank值作为阈值;(4)计算每个点的上界,并与阈值比较:若小于或等于阈值,则作为非候选点删除,反之,进入下一轮迭代;其中,每个点的上界计算公式为:UB(v)=max{Sl(v,*)}+Σi=lξci]]>其中UB(v)代表了点v的上界,*代表除点v以外的点,max{Sl(v,*)}代表了到当前迭代为止,包含有点v的点对的最大相似度的值,l为当前迭代次数,ξ和c分别最大步长和衰减因;(5)重复(2)至(4)步,直到i达到要求步数;(6)返回前k个点对。下面结合附图和实际数据对本发明做进一步详细说明。二、实施例考虑图2(a)展示了有向网络G(V,E),图2(b)是它的反向网络。我们设定k=1,ξ=3,c=0.010,即我们需要找出图中SimRank相似度最高的节点对。首先,我们以点v3,v4为例,阐明SimRank的计算方法。首先由示例网络,构建其反向网络,得到图2(b)。在反向网络上,v3,v4的SimRank等于分别从两点出发的随机游走路径在规定最大步长ξ(由人工定义,此例中ξ=3)内首次相遇的概率之和。这里从点v出发走一步概率的定义为其中I(v)代表了从点v出发走一步可达的所有点,|I(v)|代表了其数量,c为衰减因子(由人工定义,此例中c=0.010)。由反向图可知,点v3,v4在3步内相遇的路径有3条:PT1={(v3,v4)→(v6,v6)},PT2={(v3,v4)→(v6,v7)→(v9,v10)→(v12,v12)}和PT3={(v3,v4)→(v6,v6)→(v9,v9)→(v12,v12)}。而其中首次相遇的有两条,即PT1和PT2。所以,点v3,v4的SimRank相似度为S(v3,v4)=P(PT1)+P(PT2)=c/4+c3/8=0.002500125。当我们设定k=1,我们需要找出该图中SimRank相似度最大的点对。我们设计的迭代删点框架来提前删除非候选点的过程如下(仅关注点v1,v3):(1)初始化各变量,并将步长控制变量i设为0;(2)开始迭代,i没有达到最大步长3;因此i加1变为1,即首先计算点v1,v3分别和其他点1步首次相遇的概率,我们可以得到此时:S(v1,v2)=0.01,S(v1,v3)=S(v2,v3)=0.005,S(v3,v4)=0.0025。(3)此时点对(v1,v2)最相似,也就是说相似度最大的点对的相似度值也至少为0.01。阈值设定为0.01。(4)此时,我们可以评估点对v3可能达到的最大相似度值,即用其目前达到的最大1步首次相遇概率加上其可能的2、3步首次相遇的最大概率。所以,其可能的最大相似度为S(v3,v4)=0.005+c2+c3=0.005101。由于其可能的最大相似度都比0.01小,因此我们可以确定点v3一定在最大相似点对中,因此可以删除点v3不再计算。(5)重复以上过程,直到达到规定最大步数为止。最后得到最相似点对为(v1,v2)。三、实验评估在现实数据和合成数据上测试了KSimJoin的时间,在本节中,我们对本发明的算法KsimJoin与现有技术的最新算法SRK-Join进行了速度评估。表1.实验数据集实验环境:实验算法的撰写语言是C++,编译器为GCC,优化选项为–O3.实验机器为Ubuntu系统,64GRAM.现实数:Adolhealth展示了在一次真实实验中实验对象所形成朋友关系。节点代表实验对象,节点v指向节点u的边代表实验中v选择了u为朋友。Wordnet3是一个词汇网络,其中节点代表词,节点v指向节点u的边代表词v是u的一个上位词。Cora是一个引文网络,节点代表论文,节点v指向节点u的边代表论文v引用了论文u。三个网络的具体细节展示在表1。合成数据:我们人工合成了一些网络,这些网络的度在2至5之间,点的数目从500,000至3,000,000。参数设定:我们设定衰减因子c=0.360,ξ=5。我们在三个现实数据上进行了系列实验。令k的取值从5至2000,并比较了其速度,相关结果展示在图3中。从图3可以看到,当k取值较小时,SRK-Join的速度非常快,这是因为其收集候选点和一些提前终止策略都非常依赖与k;但是随着k变大,SRK-Join的效率就下降了。相比之下,KSimJoin基本上在每种情况下都比SRK-Join快一个数量级。总的来说,当k=5时,KSimJoin比SRK-Join快63.33%;当k=2000时,KSimJoin比SRK-Join快92.42%。其中的主要原因在于:(1)SRK-Join的第一阶段需要将每个点都编码成向量:这一过程需要计算全部的二次相遇概率.对于度比较大点来说,计算二次相遇概率是非常耗时的。而KSimJoin则会识别并删除非候选点,避免了大量的二次相遇概率的计算。(2)SRK-Join确定其2k个候选点后,需要重新扫描这些候选点进行精确计算;而KSimJoin只需要进行第五次迭代,即前进一步,就可以得到精确值。特别对于Adolhealth这一比Wordmet3小许多的网络,SRK-Join要比其在Wordnet3上要慢许多。这是因为SRK-Join的时间复杂度为O(ndξ),极受平均度的影响;相比之下,KSimJoin则平均度的影响较小。当k<100时,KSimJoin非常快;当k>100时,尽管其渐渐慢下来,但依然比SRK-Join快。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1