基于随机树的心电信号快速身份识别方法与流程
本发明涉及身份识别
技术领域:
,具体涉及一种基于随机树的心电信号快速身份识别方法。
背景技术:
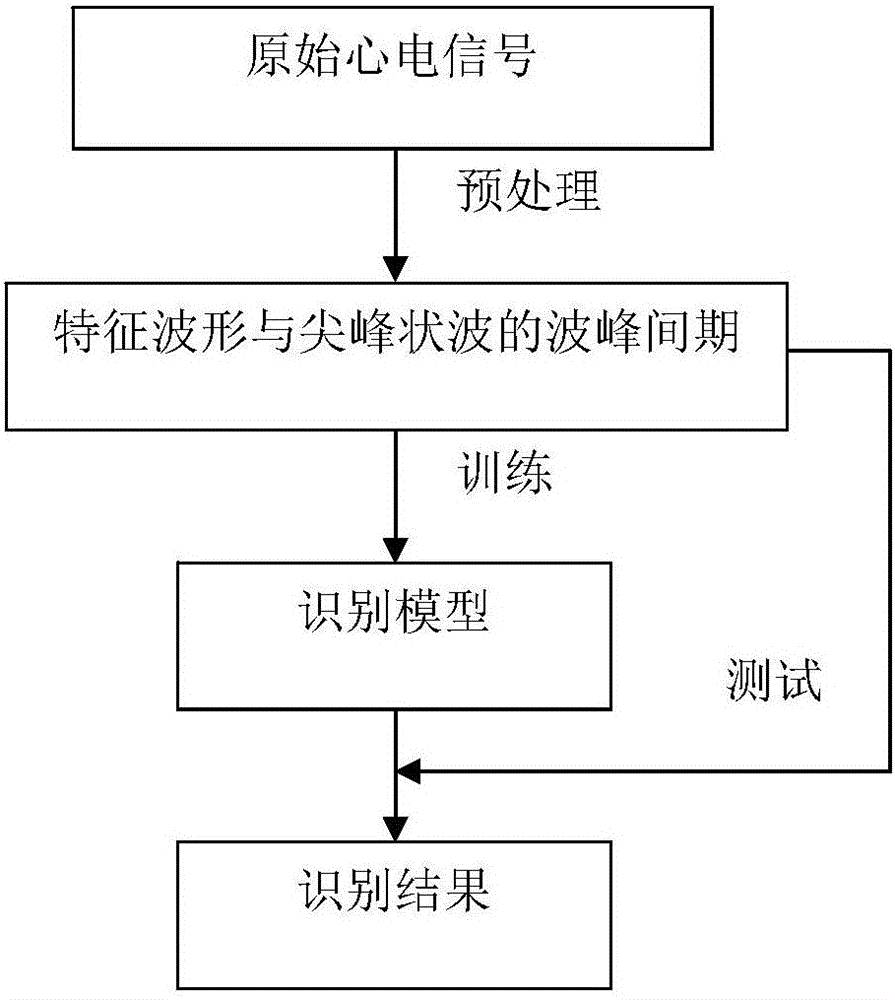
:传统的身份识别方法,比如秘钥、口令等方法,需要用户对秘钥进行记录,上述的身份识别方法需要记录秘钥、口令信息,不仅操作繁琐,而且还会存在秘钥、口令遗忘或者丢失的可能性。而常用生物身份识别方法,比如虹膜识别、指纹识别等,虽然无需用户记忆秘钥且识别率很高,但是有着许多破解的方法。比如通过佩戴特制的隐形眼镜可以骗过虹膜识别;通过特制的乳胶手指可以骗过指纹识别等。传统的生物身份识别逐渐转向心电信号等生物特征的识别。心电信号作为普世性的生物特征信号,且因人的身体、心脏状况不同,因人而异,且在静息状态具有长期稳定性,非常适合用于身份识别。目前,心电识别方法处于发展阶段。复杂度低的算法,往往识别率不够高;而精度高的方法往往计算量很大,无法很好的用在各种平台上。因此,本文提出一种精度高、识别率高且计算复杂度低的心电身份识别方法。技术实现要素:本发明的目的是:提供一种基于随机树的心电信号快速身份识别方法,方法精度高、识别率高且计算复杂度低。为实现上述目的,本方法发明采用的技术方案是:基于随机树的心电信号快速身份识别方法,包括如下步骤:S100、心电信号预处理步骤,对采集的心电信号进行滤波、去噪处理,提取心电信号的瞬时频率,在瞬时频率上寻找极大值点,再在极大值附近寻找尖峰状波的波峰。截取出每次尖峰状波的波峰间期的波形,调整每个波形的长度,将每个波形变为固定长度;S101、识别模型的计算步骤,把截取好的心跳数据分为属于用户的一类及不属于用户的一类,使用固定长度后的单次尖峰状波的波峰间期波形数据,以及该次心跳的时间长度作为特征来分类;S102、构建二叉树状分类器对心跳数据进行分类,树的根节点对应所有的数据,以根节点为例,随机选取特征维度和阈值,把该节点对应的数据分为两类,用分裂后信息熵最小的一次作为实际分裂阈值;S103、从根节点开始,对数据进行分裂,当节点的深度到达预设值16层时,或者当节点对应的数据量小于10个时,或者当节点对应的数据全属于用户或全不属于用户时,停止分裂;S104、识别模型的使用,对于需要判断身份的心电信号,先对其进行预处理操作,然后将提取到的一次心跳数据输入到建立好的二叉树状模型中,从根节点开始,利用根节点记录的特征维度与阈值,查找到叶子节点为止,判断心跳数据位于子节点的位置,若该叶子节点属于该用户,则认为输入的心跳数据属于该用户,反之则不属于。本方法发明还存在以下附加特征:所述步骤S100中,对采集的心电信号采用FIR带通滤波器滤波,使用Fstop1=1Hz,Fpass1=2Hz,Fpass2=99Hz,Fstop2=100Hz的带通Equiripple滤波器对原始心电信号进行滤波,将滤波后信号的幅值调整到[1,2]区间,将该信号进行希尔波特变换,提取瞬时频率,将调整后的信号与进行卷积,得到对应的对偶信号,以对偶信号为虚部,调整后的信号为实部,计算该信号对应的瞬时相位,对相位求导,得到瞬时频率。取瞬时频率信号最大值的二分之一作为阈值,寻找所有幅值大于阈值的极大值点,方法如下:对瞬时频率信号进行差分,若差分信号某个点幅值其大于零,后一个采样点幅值小于零,且其差分前信号的幅值大于阈值,则其为所需的极大值点,在检测到极致点的时间位置的附近,寻找经过滤波后的原始波形的极值点,找到了尖峰状波的波峰。对尖峰状波的波峰间期时间长度进行提取,该提取方法为:设采样率为Fs,则一个尖峰状波的波峰间期的采样间隔数量除以采样率即为尖峰状波的波峰间期时间长度;对于尖峰状波的波峰波形数据的长度放缩,其方法为:设尖峰状波的波峰间期的波形数据为yi,其长度为N,构造以1/(N-1)为步长,从0到1的数组xi,设波形固定的长度为M,构造从0到1,步长为1/(M-1)的数组xii,xi与yi一一对应,以xi、yi为标准,寻找xii对应的yii,M的值为20,计算yii每个元素的详细步骤如下:对于xii里每个元素,寻找其在xi的区间,设xii的元素为x,其对应带求的yii的元素为y,x所在区间为[x1,x2],x1与x2相邻,且属于xi,x1与yi里的元素y1对应,x2与yi里的元素y2对应,则y=y1+(x-x1)*(y1-y2)/(x1-x2)对xii里的所有元素执行上述操作,即可计算出yii,yii即为固定长度后的尖峰状波的波峰间期波形数据,其长度为20。所述步骤S101中,识别模型为二值分类器,在预处理中得到了固定长度后的尖峰状波的波峰间期数据,和该尖峰状波的波峰间期的时间长度,固定长度的波形数据为20维,时间长度为1维,以21维作为特征,构建树状模型;记录一名用户的5分钟静息状态下的心电数据,得到该名用户的每次尖峰状波的波峰间期波形和每次尖峰状波的波峰间期波形对应的时间长度,再记录多名用户的心电数据,并做同样处理,记属于用户的数据的类别为1,不属于的类别为0,设一个尖峰状波的波峰间期波形数据、以及对应的尖峰状波的波峰时间长度,和该尖峰状波的波峰间期的类别构成一个样本。构建二叉树状分类模型中,包括:用于记录节点编号字段Node_ID,节点深度的字段Depth,用于记录左子节点编号的字段L_child,用于记录右子节点编号的字段R_child,选取维度的字段Dim,阈值的字段Thrs,节点类别的字段Label,和节点属性的字段Is_leaf。所述步骤c中,信息熵计算方法如下:统计一个数据集里,每类数据出现的概率pi,i为类别标号,信息熵=Σ-pilog2(pi)属于用户类数据的概率为p,则信息熵计算公式变为:信息熵=p·log2(p)+(1-p)log2(1-p)在计算识别模型前,先计算出当p为0,0.1,0.2,0.3...,1时对应的信息熵,将其存储在计算机内存里,之后在计算识别模型时,使用预先计算好的信息熵做二次样条插值。所述步骤S104中,对于待识别身份的心电数据,先对其进行预处理,取出1次尖峰状波的波峰间期固定后的波形数据,以及对应的尖峰状波的波峰间期时间长度,组成21维的特征样本。与现有技术相比,本发明具备的技术效果为:该方法在计算识别模型时,更加快捷有效,且不损失识别精度;另外,在建立识别模型后,相比于其他方法,仅需一次心跳的数据,就可判断身份,简单,快速,方便。另外,该方法计算量低,有较好的可实施性,结果也更为精确。除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。附图说明构成本申请的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:图1是基于随机树的心电信号快速身份识别方法的逻辑框图;图2是基于随机树的心电信号快速身份识别方法的流程图;图3是基于随机树的心电信号快速身份识别方法中的原始的心电信号图;图4是基于随机树的心电信号快速身份识别方法中的原始的心电信号图滤波处理后的示意图;图5是基于随机树的心电信号快速身份识别方法中的经过滤波处理后的瞬时频率提取到的瞬时相位图;图6是基于随机树的心电信号快速身份识别方法中提取到的极大值点的示意图;图7是基于随机树的心电信号快速身份识别方法中,在检测到极致点的时间位置的附近,寻找经过滤波后的原始波形的极值点,找到的尖峰状波的波峰图。具体实施方式结合图1至图7,对本发明作进一步地说明:基于随机树的心电信号快速身份识别方法,包括如下步骤:S100、心电信号预处理步骤,对采集的心电信号进行滤波、去噪处理,提取心电信号的瞬时频率,在瞬时频率上寻找极大值点,再在极大值附近寻找尖峰状波的波峰。截取出每次尖峰状波的波峰间期的波形,调整每个波形的长度,将每个波形变为固定长度;S101、识别模型的计算步骤,把截取好的心跳数据分为属于用户的一类及不属于用户的一类,使用固定长度后的单次尖峰状波的波峰间期波形数据,以及该次心跳的时间长度作为特征来分类;S102、构建二叉树状分类器对心跳数据进行分类,树的根节点对应所有的数据,以根节点为例,随机选取特征维度和阈值,把该节点对应的数据分为两类,用分裂后信息熵最小的一次作为实际分裂阈值;S103、从根节点开始,对数据进行分裂,当节点的深度到达预设值16层时,或者当节点对应的数据量小于10个时,或者当节点对应的数据全属于用户或全不属于用户时,停止分裂;S104、识别模型的使用,对于需要判断身份的心电信号,先对其进行预处理操作,然后将提取到的一次心跳数据输入到建立好的二叉树状模型中,从根节点开始,利用根节点记录的特征维度与阈值,查找到叶子节点为止,判断心跳数据位于子节点的位置,若该叶子节点属于该用户,则认为输入的心跳数据属于该用户,反之则不属于。所述步骤S100中,通常情况下,原始的心电信号如图3所示,对采集的心电信号采用FIR带通滤波器滤波,使用Fstop1=1Hz,Fpass1=2Hz,Fpass2=99Hz,Fstop2=100Hz的带通Equiripple滤波器对原始心电信号进行滤波,结合图4,虽然这种方法会去除一些心电的有效信号,但是其去除绝大多数其它与心电混合在一起的信号的干扰,能有效提高后续识别的精度;将滤波后信号的幅值调整到[1,2]区间,将该信号进行希尔波特变换,提取瞬时频率,将调整后的信号与进行卷积,得到对应的对偶信号,以对偶信号为虚部,调整后的信号为实部,计算该信号对应的瞬时相位,对相位求导,得到瞬时频率。提取到的瞬时相位如图5所示;取瞬时频率信号最大值的二分之一作为阈值,寻找所有幅值大于阈值的极大值点,提取到的极大值点如图6所示,方法如下:对瞬时频率信号进行差分,若差分信号某个点幅值其大于零,后一个采样点幅值小于零,且其差分前信号的幅值大于阈值,则其为所需的极大值点,在检测到极致点的时间位置的附近,寻找经过滤波后的原始波形的极值点,找到了尖峰状波的波峰。结合图7所示;对尖峰状波的波峰间期时间长度进行提取,该提取方法为:设采样率为Fs,则一个尖峰状波的波峰间期的采样间隔数量除以采样率即为尖峰状波的波峰间期时间长度;对于尖峰状波的波峰波形数据的长度放缩,其方法为:设尖峰状波的波峰间期的波形数据为yi,其长度为N,构造以1/(N-1)为步长,从0到1的数组xi,设波形固定的长度为M,构造从0到1,步长为1/(M-1)的数组xii,xi与yi一一对应,以xi、yi为标准,寻找xii对应的yii,M的值为20,计算yii每个元素的详细步骤如下:对于xii里每个元素,寻找其在xi的区间,设xii的元素为x,其对应带求的yii的元素为y,x所在区间为[x1,x2],x1与x2相邻,且属于xi,x1与yi里的元素y1对应,x2与yi里的元素y2对应,则y=y1+(x-x1)*(y1-y2)/(x1-x2)对xii里的所有元素执行上述操作,即可计算出yii,yii即为固定长度后的尖峰状波的波峰间期波形数据,其长度为20。所述步骤S101中,识别模型为二值分类器,其可分辨输入的数据是否属于某用户,利用机器学习的方法,建立以树状的识别模型,在预处理中得到了固定长度后的尖峰状波的波峰间期数据,和该尖峰状波的波峰间期的时间长度。固定长度的波形数据为20维,时间长度为1维,以这21维作为特征,构建树状模型。记录一名用户的5分钟静息状态下的心电数据,利用前面预处理的方法,得到该名用户的每次尖峰状波的波峰间期波形(长度固定后的)和每次尖峰状波的波峰间期波形对应的时间长度,再记录多名用户的心电数据,并做同样处理,记属于用户的数据的类别为1,不属于的类别为0,设一个尖峰状波的波峰间期波形数据、以及对应的尖峰状波的波峰时间长度,和该尖峰状波的波峰间期的类别构成一个样本。构建二叉树状分类模型中,包括:用于记录节点编号字段Node_ID,节点深度的字段Depth,用于记录左子节点编号的字段L_child,用于记录右子节点编号的字段R_child,选取维度的字段Dim,阈值的字段Thrs,节点类别的字段Label,和节点属性的字段Is_leaf;样本的属性如下表所示:Wave与Time构成一个样本的特征,特征为21维。设所有的样本存储于线性的存储结构中,构建该结构的存储索引。索引为一整型数据。树状结构由节点构成,为二叉树。节点的所有属性如下:构建二叉树状分类模型的步骤如下:a、设置模型训练参数:最大深度值为16、节点数据最少量值为10、随机次数N=10;b、构建存储树的空链表,链表里的元素均为节点,链表下表从1开始;构建整形变量Point,用以标记当前处理节点的下表;构建整形变量Count,用以标记链表的长度;c、构建根节点,将所有的数据分配给该节点,将其深度设置为0;将所有数据配置给该节点:令节点对应样本的索引的开始下标Data_start=1,节点对应样本的数量Data_length=所有样本数量,节点的属性Is_leaf=0;提取该节点对应的所有样本的Type,计算信息熵;令该节点的数据的类别Label,为其对应样本的Type的众数;d、将根节点插入链表的后部,令Point=1,Count=1;e、当Point>Count时,识别模型构建完成;f、检验下标为Point的节点深度是否大于最大深度,且节点数据量小于节点数据最少量,如果是,则认为该节点为叶子节点,把节点的属性Is_leaf配置为1,Point=Point+1;并跳转到步骤d;g、取出Point对应节点的对应的样本下标,再取出下标对应的样本;在这些样本上随机N次维数,每次选取维度时,在该维度上随机取N次阈值,阈值在该维度数据的最大值与最小值之间;尝试以每组维度与特征对样本,进行分割,分为两份,分别计算两类的信息熵,把两类信息熵按照数据量大小加权起来,在这N2次尝试中,取出加权信息熵最小时对应的阈值与维度,如果最小的加权信息熵比分裂前信息熵小,就对该节点分裂,把Point对应节点所选用于分裂数据的维度Dim配置为选取的维度,把选取维度对应的阈值Thrs配置为选取的阈值;否则,认为该节点为叶子节点,把节点的属性Is_leaf配置为1,Point=Point+1;并跳转到步骤d;h、把Point对应的样本,按照前面提取的维度与阈值分裂为两份,第一份为小于阈值的样本,第二份与大于等于阈值的样本,建立新的两个节点,把这两个节点插入到存储树的链表的后面。对于第一个插入的节点、也就是下标为Count+1的节点,将其Depth配置为Point节点的深度Depth的值加1,检验下标为Count+1节点深度是否大于最大深度,且节点数据量是否小于节点数据最少量,如果是,就将其节点的属性Is_leaf属性配置为1,否则配置为0;将该节点对应样本的索引的开始下标Data_start属性配置为Point节点对应样本的索引的开始下标Data_start值,并将该节点对应样本的数量Data_length属性配置为分裂后第一份数据的长度,将节点数据的类别Label属性配置为第一份数据Tpye的众数;对于Count+1的节点,将节点的深度Depth配置为Point对应节点的深度Depth的值加1,检验其深度是否大于最大深度,且节点数据量是否小于节点数据最少量,如果是,就将节点的属性Is_leaf属性配置为1,否则配置为0;将节点对应样本的索引的开始下标Data_start属性配置为Point对应节点对应样本的索引的开始下标Data_start值加第一份数据的长度,并将该节点对应样本的数量Data_length属性配置为分裂后第二份数据的长度,将节点数据的类别Label属性配置为第二份数据Tpye的众数,将下标为Point的节点的记录左子节点编号L_child配置为Count+1;记录右子节点编号R_child配置为Count+2,将取出样本在下标数据里对应位置的下标进行重排序;将第一份数据的下标排在前面,第二份数据的下标排在后面,令Count=Count+2;令Point=Point+1;并跳转到步骤d。所述步骤c中,信息熵计算方法如下:统计一个数据集里,每类数据出现的概率pi,i为类别标号,信息熵=Σ-pilog2(pi)属于用户类数据的概率为p,则信息熵计算公式变为:信息熵=p·log2(p)+(1-p)log2(1-p)在计算识别模型前,先计算出当p为0,0.1,0.2,0.3...,1时对应的信息熵,将其存储在计算机内存里,之后在计算识别模型时,使用预先计算好的信息熵做二次样条插值。所述步骤S104中,对于待识别身份的心电数据,先对其进行预处理,取出1次尖峰状波的波峰间期固定后的波形数据,以及对应的尖峰状波的波峰间期时间长度,组成21维的特征样本。构建Point,令Point=1;按照下标为Point的节点里的属性用于分裂数据的维度Dim,选取21维数据中用于分裂数据的维度Dim维的数据,并将其与节点的属性选取维度对应的阈值Thrs比较,如果小于选取维度对应的阈值Thrs,则令Point等于节点用于记录左子节点编号L_child属性,否则令其等于用于记录右子节点编号R_child属性,重复这一过程,直到下标为Point的节点是叶子节点位置;提取下标为Point的节点数据的类别Label属性,如果节点数据的类别Label等于1,则认为这一次心跳的数据属于该模型对应的用户,否则不属于,以此判定识别结果。现有的尖峰状波的波峰,就是R波的检测方法多种多样,包括小波变换法、差分阈值法、神经网络法、线性自适应白噪声滤波及带通滤波器法等,采用本发明的R波的检测方法的识别率更高,R波检测方法识别率对:现有的心电身份之别方法较多,包括奇异度相似度法、DTW模板匹配法、FFT-匹配算法、BP神经网络法及距离判别法等,采用本发明的心电身份识别方法识别率更高,而且识别时间更短,心电身份识别方法对比:方法识别率识别时间本文方法99.9%1.8s奇异度相似度法97.82%8sDTW模板匹配法97.3%4.4sFFT-匹配算法97.1%10sBP神经网络法96.3%未提及距离判别法95%未提及当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1