一种基于分布式神经元的RNNLM系统及其设计方法与流程
本发明属于基于统计的自然语言处理领域,具体涉及基于神经网络语言模型,设计了一种基于分布式神经元的RNNLM系统。主要改变RNNLM结构,通过分布式训练的方法,减少RNNLM系统的训练时间开销,从而在保证减少训练时间开销的前提下能增加RNNLM中神经元数量和训练样本,提高RNNLM的实用性。
背景技术:
Recurrent neural network(RNN)是一种特殊的神经网络,与传统深层神经网络中单向输入数据和处理不同,使用循环连接的隐藏层代替固定的多个层次的隐藏层,这使得RNN可以保存所有的历史信息,构建了理论上近乎完美的神经网络。当前RNN已经广泛应用与非线性任务应用领域,如语音识别、文本检查与生成、SQL攻击检测等,其中RNNLM是当前基于神经网络语言模型领域中的研究热点。但由于需要保存大量历史信息和完成大量矩阵运算,增加隐藏层节点数或训练数据量,均会导致训练时间开销的爆炸性增长,从而难以构建有效的RNNLM;此外当前的神经网络还仅模拟生物神经系统的功能,没有真正具备生物神经元并行的特性,从而导致了增加隐藏层节点数量后训练开销急剧增加的问题。因此提高训练效率是当前RNNLM研究中的关键问题。
随着计算机系统结构和高性能计算计算的发展,出现了各类新型计算硬件和平台,如GPU、高性能计算集群、Hadoop和Spark等。RNN在每次训练过程中均需要大量规模与隐藏层节点数密切相关的的矩阵运算,同时需要通过大量训练和多次迭代不断优化模型,因此矩阵计算量、训练数据量和迭代次数是影响RNN训练开销的主要因素;增加隐藏层节点数量能有效提高RNN的准确率,但在训练时会导致更大规模的矩阵运算;增加训练数据量同样能提高RNN的准确率,但在训练时会导致更多的矩阵运算和增加迭代次数;这两者均会导致RNN训练时间过长而无法实用。GPU具有很强的矩阵计算能力,但适应矩阵变化能力很弱,矩阵较大后需要进行切割进行多次计算,同时数据在GPU和主机之间的传输效率也较低;传统的高性能计算集群能将计算任务分布到计算节点中,但以计算为中心的结构,在处理大量训练数据集和隐藏层节点间参数传输时效率较低;Hadoop具有处理海量数据的能力,但由于基于磁盘,完成迭代计算任务时效率较低;Spark是一个分布式内存计算平台,具有实时性强和适合迭代计算等优势,能为构建高效的RNNLM提供支撑。
技术实现要素:
本发明的目的在于提供一种基于分布式神经元的RNNLM系统及其设计方法,以解决神经元并发训练的问题,提高RNNLM的训练效率,从而在保证减少训练时间开销的前提下能增加RNNLM中神经元数量和训练样本,提高RNNLM的实用性。
一种基于分布式神经元的RNNLM系统设计方法,其特征在于:通过以能并发运行的分布式神经元为中心改变RNNLM系统的结构,设计基于分布式神经元的RNNLM系统来工作;所述设计方法还包括基于分布式神经元的结构设计、分布式神经元自主训练方法和分布式神经元协调方法。
所述的分布式神经元自主训练方法包括以下过程:
过程一,获取参数;
分布式神经元模块从神经元交互节点模块获取与该分布式神经元模块相关的参数,包括输入词在输入层中的位置m,该分布式神经元模块与输入层之间的连接U、分布式神经元模块与输出层之间的连接V、分布式神经元模块与神经元模块之间的连接W、前一次迭代分布式神经元模块的准确率S’.ac、输入层节点的准确率S.ac和输出层节点的错误率Y.er;所述m∈[1,M],M是输入和输出层节点的数量;
过程二,计算分布式神经元正确率;
第i个分布式神经元模块使用计算正确率,i(i∈[1,I],I是分布式神经元的数量)表示该分布式神经元的序号,f是一个sigmoid函数。过程三,计算分布式神经元错误率;
第i个分布式神经元模块使用计算错误率;
过程四,更新与输出层的连接;
第i个分布式神经元模块判断连接更新间隔,如不足连接更新阈值num(num∈N+),使用Vim=V'im+Ym.er*Si.ac*α更新分布式神经元模块与输出层之间的连接,其中α(α∈(0,1))表示连接调节率;相反使用Vim=V'im+Ym.er*Si.ac*α-V'im*β更新分布式神经元模块与输出层之间的连接,其中β(β∈(0,1))表示连接修正率。
过程五,更新与上一次隐藏层的连接;
第i个分布式神经元模块判断连接更新间隔,如不足连接更新阈值num,使用Wni=W'ni+α*Si.er*S'n.ac更新分布式神经元模块与前一次迭代隐藏层之间的连接,n(n∈[1,I])是前一次迭代隐藏层中节点的位置;相反使用Wni=W'ni+α*Si.er*S'n.ac-W'ni*β更新分布式神经元模块与前一次迭代隐藏层之间的连接;
过程六,更新与输入层的连接;
第i个分布式神经元模块判断连接更新间隔,如不足连接更新阈值num,使用Umi=U'mi+α*Si.er*Xm.ac更新分布式神经元模块与输入层之间的连接;相反使用Umi=U'mi+α*Si.er*Xm.ac-U'mi*β更新分布式神经元模块与输入层之间的连接。
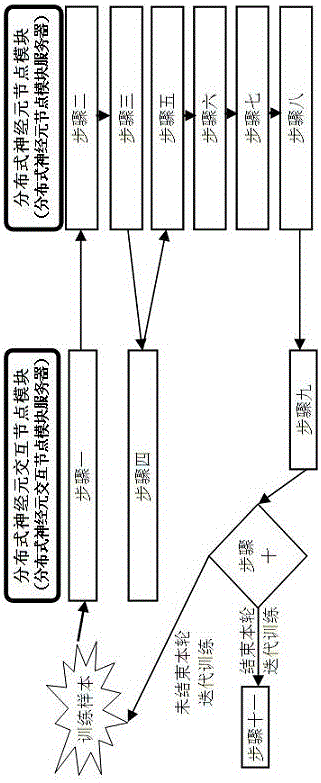
所述分布式神经元协调方法包括下列步骤:
步骤一,分布式神经元交互节点模块提取训练样本中的一个单词,计算输入词在输入层中的位置m;
步骤二,分布式神经元节点模块执行过程一;
步骤三,分布式神经元节点模块执行过程二;
步骤四,分布式神经元交互节点模块使用计算输出层中节点的正确率,其中g是一个softmax函数,所述k是输出层中节点的位置,k∈[1,M];
步骤五,分布式神经元交互节点模块使用Yk.er=1-Yk.ac计算出层中节点的错误率;
步骤六,分布式神经元节点模块执行过程三;
步骤七,分布式神经元节点模块执行过程四;
步骤八,分布式神经元节点模块执行过程五;
步骤九,分布式神经元节点模块执行过程六;
步骤十,分布式神经元交互节点模块收集所有分布式神经元模块发送回的正确率、错误率、U、V、W,进行汇总更新,并构建上一次隐藏层;
步骤十一,如训练样本中还有未处理的单词,则读取下一个单词,返回步骤一;否则结束本轮迭代训练,转到步骤十二;
步骤十二,判断本轮迭代训练结束后神经元的准确率与上一论的差值是否达到系统设定,如达到则结束RNNLM训练,返回训练样本中的第一个单词,转到步骤一,开始下一轮迭代训练。
基于分布式神经元的结构设计具体包括分布式神经元节点模块和分布式神经元交互节点模块的设计;
所述分布式神经元节点模块负责维护该神经元的状态、以及与输入层、输出层和之间的连接,包括获取参数、计算正确率、计算错误率、更新与输入层连接、更新与上一次隐藏层连接、更新与输出层连接等功能;
所述分布式神经元交互节点模块实现分布式神经元之间的协调,完成初始化、输入训练语料、维护输入与输出层状态等,包括参数分布、参数收集和参数汇聚更新等功能。
一种基于分布式神经元的RNNLM系统,包括一个分布式神经元交互节点模块服务器和多个分布式神经元节点模块服务器,其特征在于:分布式神经元交互节点模块服务器和分布式神经元节点模块服务器之间用Infiniband进行连接,分布式神经元节点模块服务器和分布式神经元交互节点模块服务器之间的交互使用RDMA协议。训练样本由多个分布式神经元节点模块服务器和一个分布式神经元交互节点模块服务器共同完成处理,合作完成RNNLM的训练过程,并共同对外提供服务。
本发明具有有益效果。本发明出于提高RNNLM训练效率的考虑,以能并发执行的神经元为中心,改变RNNLM结构,通过分布式训练的方法,减少RNNLM系统的训练时间开销。本发明针对RNNLM的训练过程和特点,引入分布式技术,改变RNNLM结构,以能并发执行的神经元为中心,使用分布式训练的方法,设计了基于分布式神经元的结构、分布式神经元自主训练方法和分布式神经元协调方法,减少RNNLM系统的训练时间开销,从而在保证减少训练时间开销的前提下能增加RNNLM中神经元数量和训练样本,提高RNNLM的实用性。
附图说明
图1是本发明的结构图;
图2是本发明的工作流程图;
图3是分布式神经元数不同时的训练时间开销测试结果图;
图4是首次和后续迭代的训练时间开销测试结果图;
图5是准确率的测试结果图。
具体实施方式
实施例1
如图1所示,一种基于分布式神经元的RNNLM系统,包括一个分布式神经元交互节点模块服务器和多个分布式神经元节点模块服务器,其中分布着获取参数、计算正确率、计算错误率、更新与输入层连接、更新与上一次隐藏层连接、更新与输出层连接、训练初始与分布、更新输出层、结果汇聚与更新等模块,模块在两类服务器中的分布和功能说明如表1所示。
表1基于分布式神经元的RNNLM系统中各类型服务器和各功能模块
一种基于分布式神经元的RNNLM系统中其,分布式神经元交互节点模块服务器和分布式神经元节点模块服务器之间的交互过程如图2所示。
实施例2
依据RNNLM开源的代码,使用Scala在Spark中实现了基于分布式神经元的RNNLM系统,用三台服务器搭建了测试环境,每台服务器配有Intel(R)Xeon(R)E5606 2.13GHz处理器2个,64G内存,操作系统是Centos6.7,Spark版本是RDMA-Spark-0.9.1,网络是40GB的Infiniband,通信协议是RDMA;Driver节点作为分布式神经元交互节点模块服务器,Worker节点作为分布式神经元节点模块服务器,一个Worker节点运行多个分布式神经元节点模块从而支持大量的分布式神经元。同时在1台服务器中使用RNNLM开源的代码,搭建了单机RNNLM系统,工作与一台服务器中,服务器配置与运行基于分布式神经元RNNLM系统的服务器相同。
测试训练样本包括:Microsoft公布的ptb.train(4M),RNNLM Toolkit中的word_projections 80(64M)、swb.rnn.model(87M)和word_projections 640(500M)。
设置不同的分布式神经元数(基于分布式神经元的RNNLM系统)和隐藏层节点数(单机RNNLM系统),测试和比较完成10次迭代训练所需的时间开销。神经元数分别设置为200、500和1000,训练的迭代次数均设置为10次,结果如表2所示。
表2改变布式神经元数和隐藏层节点数的训练时间开销
改变训练语料的大小,分别使用4M、87M和500M的训练样本,将神经元数量分别设置为200、500和100,训练的迭代次数仍然设置为10次,测试基于分布式神经元RNNLM系统的训练时间开销,结果如图3所示。
测试基于分布式神经元RNNLM系,分别试用4M和87M训练样本时,首次迭代和后续迭代所需的时间开销,不同训练迭代次数时,训练的时间开销,结果如图4所示。
RNNLM Toolkit中word_projections 80(64M)训练样本,分布式神经元数分别设置为200、500和1000个,迭代次数为10次,测试基于分布式神经元RNNLM系统的准确率结果如图5所示。
- 还没有人留言评论。精彩留言会获得点赞!